信息资源语义组织与语义服务模式探究*
——以芬兰语义计算研究小组(SeCo)项目实践为例
2019-02-25陈金菊欧石燕林泽斐
陈金菊 欧石燕 林泽斐
(1.南京大学信息管理学院 江苏南京 210023)
1 引言
知识组织是按照知识的内在逻辑, 对知识进行整理、加工、引导、揭示、控制等一系列序化的操作过程。 早期的知识组织方法主要是分类、元数据描述和主题标引等,通常采用DC、MARC、XML 等非语义化格式对信息资源外部特征进行描述和揭示, 这些格式计算机可读但不可理解, 因而无法为人类提供深层次的知识服务,具有很大的局限性。语义网和关联数据技术的提出使得信息资源的组织和服务开始朝着语义化的方向发展。 采用语义网技术可以实现对信息资源的语义描述和语义组织, 并在此基础上提供语义检索、语义集成、语义共享等语义服务,有效地解决了传统知识组织与服务方式缺少语义化的问题。
国内信息资源语义组织的研究以理论研究和应用研究层面的探讨为主,实践较少,且规模较小。 上海图书馆开放数据平台是国内语义组织与服务的典型实践, 该平台以关联数据的方式发布其数字人文项目基础知识库(人、地、时)、文献知识库(家谱、古籍、手稿)和本体词表等。该平台的研究对象以人文学科信息资源为主,自然科学涉及很少,此外该平台提供的语义服务不够全面,只提供语义浏览和检索服务,但是缺少语义集成、可视化等多样化知识服务。翟姗姗采用语义网和关联数据技术开发了一个基于关联数据的非物质文化遗产资源聚合与服务平台,对楚剧这一非物质文化遗产资源进行语义描述、标注和聚合研究,并提供语义服务;欧石燕采用语义网和关联数据技术提出了语义数字图书馆资源描述框架,对图书馆信息资源进行整合,实现了面向关联数据的自动问答。此外,还有以档案信息、多媒体资源、社会舆情信息等信息资 源为 研究对象的语义组织和服务研究。总体而言,这些研究的研究对象为单一类型信息资源, 关注的语义服务类型也相对单一, 对其他类型信息资源的语义组织和服务不具有广泛的适用性。
目前,涉及多个领域、提供多样化语义服务的大型信息资源语义组织实践项目国内仍较少, 而国外部分研究和服务机构已经积极开展了此类实践,如欧洲数字图书馆项目Europeana,采用语义网技术对文化遗产资源进行整合, 并提供统一的网络访问平台;美国国家人文研究基金和德国科学基金共同支持的“关联人文项目”(Linked Humanities),开发了关联数据组织与发布平台; 欧洲数字手稿项目DM2E(Digital Manuscripts to Europeana),采用关联数据技术对历史资源进行整合和利用;芬兰语义计算研究小组SeCo(Semantic Computing Research Group)创建了语义组织与语义服务项目平台,采用本体和关联数据等语义技术对跨领域、 多类型的信息资源进行语义组织, 并在此基础上提供多样化的语义服务。 在这些语义组织与服务实践中,以SeCo 开展的实践项目成效最为显著,其特点和优势主要表现在:(1)该项目兼具研究广度和研究深度。SeCo 研究团队自2002 年至今, 针对不同领域的特点,已开发的28 个项目涉及人文学科和自然科学的多个研究领域,信息资源种类丰富,研究范围广泛。同时, 这些项目开展的语义组织不仅包括外部表层元数据,还深入到内容语义层面,展开深层次语义描述;(2)该项目坚持理论与应用研究相结合。 SeCo研究团队不仅关注语义组织的相关理论研究, 根据各类信息资源的特点进行语义建模, 还基于语义化描述和组织的数据提供多样化语义服务。由此可见,SeCo 在资源语义组织和语义服务方面取得了良好的进展, 已使其成为语义组织和语义服务的代表性实践项目。本文通过梳理SeCo 研究团队开发的语义组织和语义服务项目的主要内容, 从资源类型与标注深度、语义模型、语义数据构建与集成、语义服务这四个方面剖析其研究和实践现状,总结项目特点。
2 项目概况
芬兰赫尔辛基大学(University of Helsinki)和阿尔托大学(Aalto University)发起的SeCo 开发了许多语义组织与语义服务项目。目前,该项目组位于芬兰赫尔辛基大学艺术学院数字人文中心 (HELDIGHelsinki Centre for Digital Humanities, University of Helsinki, Faculty of Arts) 和阿尔托大学理工学院计算机科学系(Aalto University, School of Science, Department of Computer Science),项目组成员主要也来自这两所大学。 SeCo 的目标是对各领域的信息资源进行语义化组织和描述, 并在此基础上提供语义化服务,实现资源的互操作。 除了相关研究论文和出版物,该项目还创建了原型应用程序,用于展示语义技术的可能性应用,譬如为终端用户提供语义门户,以及用于创建语义应用程序的本体和工具。
SeCo 开发的语义组织与语义服务项目的应用领域非常广泛,包括数字人文、健康、学习、政府、商业和生物等领域,且跨学科特征显著。 SeCo 早期开发的项目主要关注图书馆领域, 涉及的内容主要是语义标注和语义检索等。 自关联数据出现后,SeCo创建的项目涉及的领域范围变广, 不仅包括人文社科领域(如历史、传记、法律、文化遗产等),个别项目还涉及自然科学领域(如医学、健康等),但目前SeCo的主要研究仍以人文学科为主。 从研究内容来看,SeCo 研究团队在早期, 即2006 年关联数据提出之前, 主要关注如何采用元数据和本体进行信息资源的语义标注。 从2006 年开始,该项目开始关注关联数据的应用,基于关联数据开展各种应用服务,如语义门户、可视化、应用程序等。
SeCo 研究团队自2002 年至今共开发了28 个项目,各项目周期从一年到九年不等。这些项目大致可以分为四类:(1)以信息资源语义标注与组织为主要目的的项目;(2) 以提供语义服务为主要目的的项目;(3)以提供语义基础设施为主要目的的项目,包括语义模型构建和语义工具开发等。 目前已开发的语义工具包括语义搜索引擎、语义标注编辑器、语义信息抽取工具、语义门户创建工具等;(4)其他项目,以语义计算居多, 如探索语义计算在移动5G 网络管理中的应用等。 前三类项目大致共有17 个(见表1),本文主要针对这些项目进行探讨。
3 研究现状分析
3.1 资源类型与标注深度
SeCo 开发的语义组织与语义服务项目涉及范围广,因而其所研究的资源类型、资源内容、标注内容和标注深度也呈现多样化的特征。 SeCo 开发的项目创建了许多相应的应用,本文选取目前仍然提供服务的应用, 特别是包含大量语义数据的语义门户作为调研对象,按照应用开发的大致时间先后顺序,对各项目的应用涉及的资源类型和内容, 以及标注内容和深度进行归纳总结(见表2),并分析其特点。(1)从资源类型上看, 语义组织的研究对象已不再局限于传统的书目信息,而是扩展到非书目信息,如文物、雕塑、照片、视频、音频、广告和地图等多模态信息资源。语义组织的资源类型逐步由单一向多类型过渡,种类日益丰富;(2)从资源内容上看,主要可以归纳为两种:一种是研究对象仅涉及单一主题内容,如商业、历史和传记;另一种是研究对象涉及多主题内容,如文化遗产,但前者更具有领域针对性,目前大多数项目研究的资源内容以前者为主;(3) 从标注内容和深度上看,SeCo 开发的早期项目的语义标注内容主要停留在浅层外部特征,如关键词、创建者和发布者等,没有深入到资源内容层面。 近几年,SeCo 的语义组织开始出现向内容层面(如实体和关系)深入的趋势,标注内容以人、事、物、地、时等要素为主,标注深度逐步从浅层粗粒度标注向深层细粒度标注过渡。

表1 SeCo 开展的语义组织与语义服务项目概况[12]

表2 SeCo 项目涉及的资源类型与标注深度
3.2 语义模型
SeCo 开发的语义组织项目的数据来源多样,数据格式难以统一,给数据资源的互操作带来了困难。因此,需要采用统一的标准和模型解决这一问题。目前,SeCo 创建的应用主要涉及数字文化、数字健康、在线学习、电子政府、数字生物等领域,下面对这些领域中仍提供服务的应用涉及的主要语义模型(见表3)进行总结和分析。 可以看出,SeCo 开发的应用中采用的语义模型主要包括元数据方案和本体。SeCo 侧重于采用目前较通用、 成熟的语义模型,并基于对现有本体的复用和扩展, 构建了一系列适用于不同领域的领域本体。
SeCo 采用了一些目前较通用、成熟的模型进行语义组织实践:(1)在文化领域,由于SeCo 的文化遗产项目庞大, 因此文化遗产领域的通用顶层本体CIDOC CRM 概念参考模型得到了广泛的应用。该模型是国际文献工作委员会开发的一个概念参考模型,提供了一个描述文化遗产的通用框架,致力于实现文化遗产信息的语义共享和互操作, 充分发挥文化遗产的价值。 目前,CIDOC CRM 已成为ISO 标准, 使其得到了更为广泛地应用。 Bio CRM 则是对CIDOC CRM 模型进行扩展得到的模型。该模型用于表示传记信息,将传记看成是事件,每个事件包含参与者、地点、时间和事件类型,同时引入角色信息,用于表示参与者在事件中扮演的角色信息。 为了规范本体中类和属性的取值,还采用了一些受控词表,如艺术与图像分类系统ICONCLASS、 联盟艺术家名单ULAN、 艺术与建筑叙词表AAT 和地理信息词表WGS84 等;(2)在健康领域,主要采用了都柏林核心元数据元素集(DC)和DCMI Terms,前者是描述跨领域信息资源国际标准, 包含15 个核心元数据,后者则是在前者的基础上扩展了一些其他元素和元素修饰,两者可以对健康信息的创建者、发布者、主题等进行描述。采用的词表主要包括DCMI 类型词表(DCMI Type)和两个医学健康领域的词表,即国际医学主题词表MeSH 和欧洲多语种健康促进词表HPMULTI;(3)在教育领域,主要采用了学习对象元数据(LOM),是IEEE 的学习技术标准委员会(LTSC)制定的一个描述教育资源的元数据标准, 其目的是为了支持学习对象重用、发现和互操作。LOM 包含九大类不同的教育资源类, 采用该元数据可以对教育资源的关键词、格式、结构等信息进行描述。

表3 SeCo 项目语义组织中涉及的主要语义模型
除了上述通用本体模型外,SeCo 还根据自身需要自建了一些语义模型进行不同领域的语义组织实践。 不同领域的本体由不同领域的专家合作并以分布式方式开发, 同时被映射在一起形成一个包含所有领域的大型国家本体家族KOKO。 KOKO 包含一个通用顶层本体YSO 和14 个基于YSO 构建的领域本体(如音乐、健康、商业、文学等)。YSO 是由芬兰国家图书馆维护的芬兰通用叙词表YSA 转换而来,采用SKOS 表示, 包括30465 个通用概念, 提供芬兰语、英语和瑞典语三个版本。除了KOKO 本体家族外,SeCo 还开发了人物本体 (Actor)、 地点本体(Place)、时间本体(Time)、事件本体(Event)和生物本体(Biological),在其项目中都得到了广泛的使用。除了上述常用的本体外, 还有一些使用频率相对较低的本体和词表, 本体主要包括名胜古迹地点本体POIO、 世界鸟类本体AVIO、 芬兰健康元数据模型(HealthFinland Metadata Schema)、 地 名 注 册 模 型(PNR)、名称档案模型(NA)、表示地球上的区域和地点的本体Location、馆藏本体Collection、基于描述文化内容的叙词表构建的Artifact、Material 和Situation本体等, 词表主要包括学科类别词表School Subject Ontology、主题词表Theme Ontology、表示不同媒体类型的词表Medium Ontology、表示人物类别的观众词表Audience Ontology、 描述数据集的词表voiD(Vocabulary of Interlinked Datasets)等。
3.3 语义数据构建与集成
SeCo 的语义数据构建主要是实现将非语义化格式的数据(如结构化数据库表和非结构化文本数据)转换为语义化格式的数据,SeCo 通常采用语义映射或创建语义转换器的方式完成语义数据构建。 譬如,MuseumFinland 项目的不同博物馆的馆藏数据以数据库表的方式存储,SeCo 采用XML Schema 将这些数据库表转换为XML 数据, 再采用RDF Schema将XML 数据转换为RDF 数据,然后将这些数据映射在一起,集中存储到一个全局数据库中。
SeCo 的语义集成实践大致可分为两类:语义关联和语义数据集中管理。 前者分为内容语义关联和外部语义关联,后者旨在对语义数据进行集中管理,提供统一浏览和检索。 在内容语义关联方面,SeCo创建的项目提供了一些语义信息抽取和语义标注工具,如Poka 和SAHA 等。 Poka 提供了一个自动标注框架,为本体概念的自动化抽取提供了基础。 SAHA 是一个语义内容创建工具,用于支持基于浏览器的语义标注。 在外部语义关联方面,通过RDF 链接将不同数据源的数据链接在一起。如SeCo 开发的Hipla 项目通过分布式SPARQL 查询对不同来源的芬兰古代历史地理信息进行集成,实现古地图和现代地图的映射。在语义数据集中管理方面,SeCo 主要通过构建语义集成平台的方式,实现对语义数据和语义模型的集中管理。 SeCo 首先开发了一个网站对其开发的所有项目、语义模型和语义数据集进行集中访问和共享,但该网站内容繁杂,需要用户自行逐级浏览,不支持检索,不利于用户快速获取所需语义信息。此外,SeCo 还开发了一些专门的语义集成管理数据库和平台,如ONKI 和LDF。ONKI 是一个本体集成管理数据库,用于对其开发的本体进行集中管理,使其更易于维护、发现和使用。 LDF.fi是SeCo 创建的一个关联数据平台, 该平台对相关的语义数据集、研究数据和元数据模型等进行集成管理,为网络上的结构化数据的发布者和消费者提供服务。
3.4 语义服务
SeCo 旨在以机器能够理解的方式表示数据和知识,并基于此创建智能应用,为人类提供更加智能的知识服务。 SeCo 为用户提供免费开源的资源共享平台,使得资源的获取不受时空的限制,极大地提高了资源的利用率。 本文从SeCo 的主要应用领域着手,对其提供的服务类型进行探索。通过对当前仍然提供服务的SeCo 项目进行调研, 发现SeCo 主要通过语义门户和移动应用两种服务模式为用户提供语义服务,前者通过信息资源的集成、整合、分类和再组织,为用户提供一个一揽子用户服务界面,是当前主要的语义服务模式;后者则是以APP 为代表的移动应用服务,使用更加便捷,但目前此类应用较少。这两种语义服务模式提供的语义服务类型主要包括以下几种:
(1)多视角访问。 SeCo 的项目开发的一些语义系统, 在用户进行访问时, 可为其提供多个访问视角,用户可根据自身的信息需求,选择合适的访问视角。 如CultureSampo 是一个将文化遗产资源进行语义组织,并提供语义服务的语义门户。该门户支持从地图搜索与浏览、关系搜索、搜索与组织、集合、芬兰历史、技能与文化叙事、传记、语义Kalevala(芬兰国家史诗)、Karelia(芬兰的一个地区)等九个视角进行访问;WarSampo 是一个将芬兰二战历史数据发布为关联数据,并提供语义服务的语义门户。该门户在其主页和菜单栏,按照资源类型提供从事件、人物、军队、地点、照片、伤亡者、杂志文章、战争墓地等八个视角对资源进行浏览和检索(见图1)。
(2)支持多语言。 SeCo 虽然是一个针对芬兰的语义组织与语义服务项目, 但是为了方便全球更多的用户利用其资源,SeCo 的许多系统都支持多语言访问,常见的语言包括芬兰语、瑞典语和英语,用户可以选择其熟悉的语言界面, 进行语义浏览和检索等操作,极大地增强了用户友好性。如BookSampo 是一个将芬兰公共图书馆包含的芬兰小说文献元数据进行语义化,并提供语义服务的语义门户。该门户在其右上角提供芬兰语、 瑞典语和英语三种语言供用户选择;WarSampo 语义门户则在其左上角提供了芬兰语和英语两种语言, 用户可方便地切换用户界面语言进行系统访问。
(3)语义浏览与语义检索。 SeCo 允许用户浏览其发布的关联数据,并对这些关联数据进行检索。由于RDF 查询语言SPARQL 对于检索能力的要求较高, 主要面向掌握SPARQL 的专业检索人员, 因此SeCo 的大多数项目都为用户提供基于自然语言的关键词检索, 或者提供标准查询模板的方式引导用户构建检索策略, 使得普通用户可以在不掌握SPARQL 查询语言的情况下,也能进行语义检索。 如CultureSampo 的“检索与组织”界面提供了一个查询模板“TELL ME ABOUT <Resource Type>WHICH <Condation1><Condation2>…”, 帮助用户构建检索式;WarSampo 的Places 界面提供了对芬兰二战战区覆盖的地点检索,以芬兰首都赫尔辛基(Helsinki)为例进行地点检索得到的检索结果(见图2)。
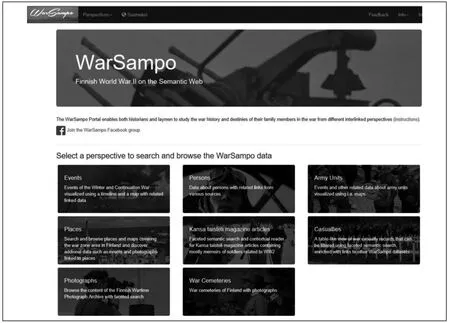
图1 WarSampo 提供的八个访问视角和多语言服务
(4)知识发现。 知识发现是采用某种序化方式(如表、地图和时间序列等)对检索结果及其相关资源进行再组织, 为用户提供了新的视角来发现信息资源中隐含的新知识。如通过CultureSampo 的“检索与组织” 界面提供的查询模板检索得到的结果可以以列表、地图、时间轴三种形式呈现,帮助用户发现事物随时间演变的规律、 空间分布规律等知识;WarSampo 的Places 界面在地图上展示相关地点,并提供与该地点相关事件、 文章和照片的链接。本文以芬兰首都赫尔辛基(Helsinki)进行地点检索得到相关战争文章,这些文章按照时间顺序进行排列,可以发现与该战争地相关的文章数量随时间变化的规律。
(5)可视化分析。可视化技术有助于帮助用户更好地理解信息资源包含的语义信息, 发现其中隐含的规律。 SeCo 为用户提供多种可视化方式,借助地图、时间轴、网状关系图、柱状图、饼图等方式实现时空语义信息、社会关系和统计信息的可视化。 如Culture-Sampo 提供人物和机构间多种社会关系(如教学关系和亲属关系等)的可视化服务;以WarSampo 的战争墓地访问视角提供的英雄公墓中死亡者的年龄统计为例,可以发现该公墓中的死亡者年龄范围在15 岁到39 岁,其中22 岁的死亡者最多。 此外,还可以通过地图对死亡地点进行可视化, 借助饼图对死亡人员的军衔等级进行可视化统计等。
4 特点与启示
SeCo 创建的语义组织与语义服务项目发展较成熟,且具有综合性、跨领域的特征,在信息资源语义整合、应用与服务方面取得了重要进展,其在语义组织和语义服务方面的成功实践可以为我国相关研究与实践提供一定的启示和借鉴。

图2 WarSampo 的地点访问视角提供的语义检索和知识发现服务
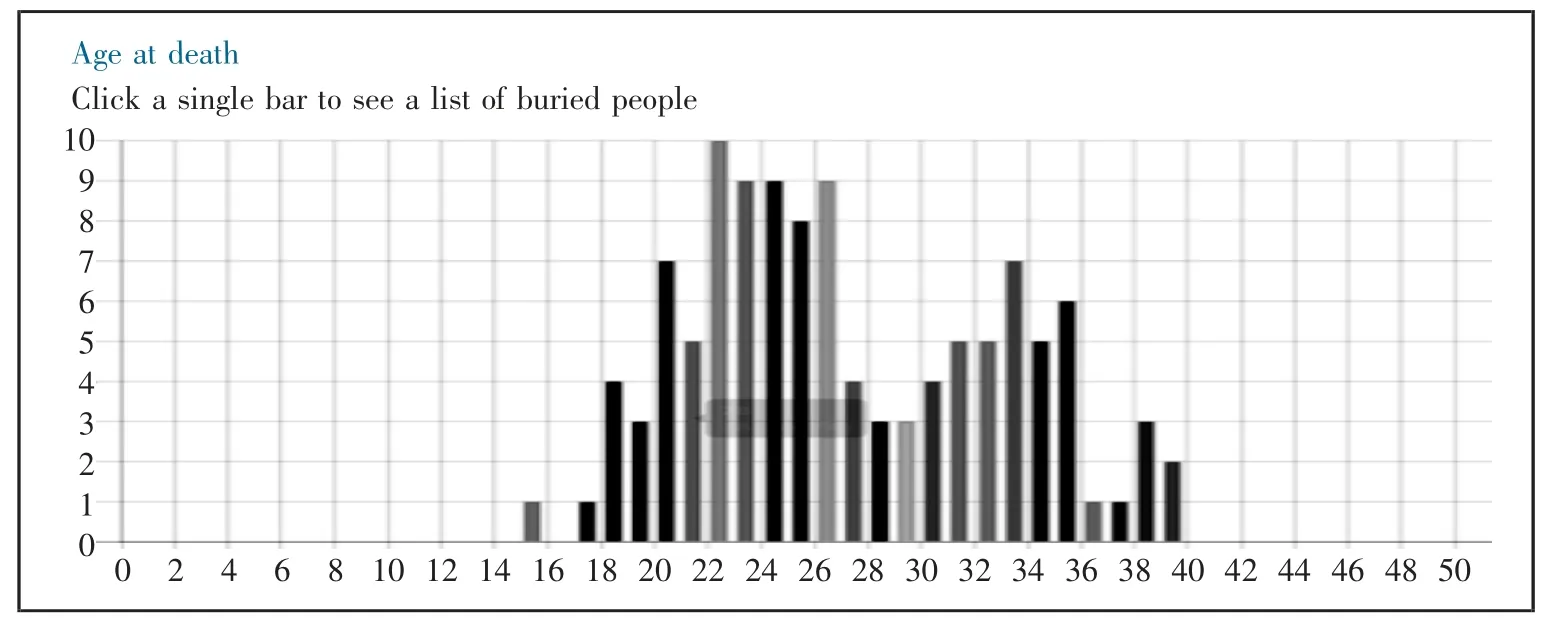
图3 WarSampo 的战争墓地访问视角提供的某英雄公墓中死亡者的年龄统计
(1)语义组织的对象从书目向非书目信息资源扩展。在资源类型方面,随着数字技术和信息技术的迅猛发展,信息资源的类型日益增多,语义组织的对象也开始变得丰富多样。 以往以书目信息资源为中心的语义组织已无法完全满足需求, 目前语义组织的资源类型已出现从传统的书目信息扩展到非书目信息的趋势,因此应多关注对文物、雕塑、照片、视频、音频、广告和地图等多模态非书目信息资源的研究。目前, 国内对非书信息资源的关注度仍不够高。 今后, 国内语义组织的研究对象的选择应多关注非书目信息资源。
(2)语义标注的深度从外部特征向内容语义深入。 在标注深度方面,早期的语义标注的粒度较粗,主要关注资源的外部特征, 缺少对内容层面的语义挖掘。当前语义标注逐步深入到内容层面,标注粒度变细,呈现从外部元数据向内容语义深入的趋势,有助于更加充分地发掘资源的有用语义信息, 提高资源的利用率。目前,国内对语义组织的研究深度尚显不足。今后,国内语义组织的研究视角的选择应多关注深度内容语义标注。
(3)信息资源的覆盖范围从单一领域向多领域扩展。在研究领域方面,SeCo 研究团队至今已开发了28 个项目,这些项目涉及人文学科和自然科学的诸多研究领域,研究范围广泛。其中,以人文社科居多,如历史战争、人物传记、图书、旅游、法律等领域;自然科学领域相对较少,如健康医学领域等。 目前,国内相关研究和实践仍以人文社科为主, 自然科学甚少,且总体而言,人文社科领域的实践数量较之国外相对较少。今后,国内语义组织的研究领域的选取可以采取横纵结合的方式,在纵向上,进一步深入探索人文社科可能的研究领域, 在横向上向自然科学相关领域扩展。
(4)语义服务从文本向图像可视化发展。可视化技术可以更加生动、形象地展示语义信息,使用户的理解更加深刻, 同时还可以挖掘其中隐含的规律。SeCo 为用户提供多种可视化方式,借助地图、时间轴、网状关系图、柱状图、饼图等方式可以实现时空语义信息、社会关系和统计信息的可视化。 目前,国内相关研究和实践仍以平面化服务方式(页面浏览或逐级浏览)为主,内容多以文字方式呈现,很少提供可视化服务。今后,国内应尝试提供多种图像可视化语义服务,使研究更加立体、易懂。
(5)语义服务从单一向多样化发展。语义技术最大的优势在于机器可读可理解,在此基础上为人类智能地处理信息,提供智能化知识服务。 SeCo 创建的语义服务模式主要包括语义门户和移动应用, 这两种模式符合当前互联网时代的用户需求。 SeCo 提供的语义服务类型主要包括: 多视角访问、 支持多语言、语义浏览和语义检索、知识发现、可视化分析等。其中,支持多语言为其它服务提供了重要的基础,特别是国际通用的英语,有助于提高用户友好性。语义服务类型和服务视角应具有多样性, 以满足不同类型用户的多样化需求。目前,国内提供的语义服务以网站为主,移动应用甚少。此外,国内提供的语义服务方式较少,鲜有支持多语言、可视化分析、知识发现等语义服务。 未来,国内语义服务应朝多样化方向发展。
5 结语
SeCo 项目实践作为当今国际上语义组织与语义服务的一个典型实践, 展现了语义组织与语义服务的新思路和新方法, 对我国语义组织与语义服务实践具有重要的借鉴意义。 本文从资源类型与标注深度、语义模型、语义数据构建与集成、语义服务四个方面对SeCo 开发的项目进行了梳理和分析,重点对SeCo 语义组织与语义服务的特点进行总结,精炼了其对我国开展相关实践的几点重要启示。目前,我国仍缺乏大型语义组织与语义服务实践项目, 在这一研究领域仍有较大的可研究和探索空间, 希望本文的探讨可以为国内开展相关实践提供一些参考。
