基于改进的K-means聚类算法的汽车市场竞争情报分析
2019-02-20,,,,
,,,,
(1.山东科技大学 计算机科学与工程学院,山东 青岛 266590;2.山东科技大学 信息工程系,山东 泰安 271019)
在激烈的市场竞争中,企业只有找准自己的定位及竞争优势,才能实时地制定产品战略,以期更好地发展。社会网络分析(social network analysis,SNA)对社会个体进行网络化的分析,建立联系、比较差异,是目前将数据挖掘技术与社会生活密切联系起来的最优方法之一,同时也给竞争情报工作带来了新的方向[1-2]。近年来,社会网络在竞争情报获取和分析上的应用逐步推广,张玥等[3]以图书馆、情报学专业领域博客交流网络为例,进行中心度、凝聚子群以及小世界效应分析,对促进科研人员之间的信息沟通与交流具有指导性。裴雷等[4]探讨了社会网络在情报学领域的研究现状、典型应用以及计量分析理论,完善了社会网络分析与竞争情报的理论性结合基础。徐振宇[5]分析了社会网络在经济学领域诸如在网络结构、网络效应、网络形成等方面的应用,客观评价了社会网络分析与经济学结合的优势与困境。唐晓波等[6]则将社会网络分析应用于企业竞争市场,以手机市场为例构建竞争网络,从宏观和微观角度得出企业竞争状况,具有较强实践意义。
选择目前在中国轿车市场中最为广泛使用的A级车为例,首先运用层次分析法(AHP)和熵权法(EWM)对车辆指标数据进行量化处理,提出竞争威胁概念并设计该数据指标,改进K-means聚类算法,应用该算法对其进行聚类分析,最后通过竞争矩阵和竞争网络的建立对企业品牌以及车辆本身做中间中心度和凝聚子群分析,从而使得汽车企业了解其品牌在A级车市场中的竞争地位,同时为用户选购车辆提供依据。

表1 判断标度及其定义表Tab.1 The scale of judgment and its definition table
1 数据的标准化处理
1.1 数据采集与基于AHP的文本数据处理
样本数据是通过Python从汽车之家、搜狐汽车和网上车市等网站爬取得到。选取了目前中国A级轿车市场的几乎所有最新款车辆,由于同款汽车存在配置差异导致价格区间过大,同一车型高低版本太多,所以统一选取各样本对象同款车型中的最高配作为衡量标准,以便进行比较分析。统计样本数据包括88辆目前主流A级轿车,选取了最能代表汽车性能的16个指标:价格、最大马力、最大扭矩、变速箱、百公里油耗、轴距等。考虑到在中国A级轿车市场中,国产制造与合资车辆存在明显的品牌效应差异,对用户选择存在差异性影响,所以将汽车品牌也作为一项重要指标,并赋予不同权重值[7]。
汽车属性指标中存在比如品牌、变速箱、座椅材质等文本型指标,因此采用AHP方法来确定权重系数。将属性中每一个指标值作为一个评估因素,建立评估因素集U={u1,u2,…,un},ui的取值选择1-9标度方法[8],如表1所示。根据AHP方法定义表,文本属性数据化后处理结果如表2所示。

表2 文本属性数据化后处理结果(部分数据)表Tab.2 Text attribute data post-processing result (partial data) table
1.2 基于熵权法EWM的数据归一化处理
熵最先由香农引入信息论,已经在工程技术、社会经济等领域得到了广泛应用。熵权法的基本思路是根据指标变异性的大小来确定客观权重。在表示汽车性能属性的指标中,各个指标对一辆车的影响程度是不同的,用户选择车辆时的指标侧重点同样存在差异。因此采用主观性较小的熵权法对车辆数据进行归一化处理并求出权重,最后对数据赋权求出标准化数据。
1) 数据归一化处理


表3 指标数据归一化后结果(部分数据)表Tab.3 Normalized index data (partial data) table
2) 确定指标信息熵及权重

表4 信息熵和权重结果表Tab.4 Information entropy and weight result table
因此,在对指标归一化后数据赋权重使之标准化的过程中,可以根据归一化后车辆指标数据首先得到一个88×16的原始矩阵(1)。
(1)
其中:n为车辆个数,值为88;m为性能指标,值为16。将权重代入,可得到矩阵表达式(2),详细数据如表5所示。
(2)

表5 指标数据标准化后结果(部分数据)表Tab.5 Normalized results of indicator data (partial data) table
2 改进K-means算法的聚类分析
K-means算法是典型的空间聚类方法,基于欧式距离作相似度测试,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,把得到紧凑且独立的簇作为最终目标[9]。本文样本数据属于多维的空间数据,因此应用空间聚类的代表K-means算法可以得到更精确高效的数值。在典型的K-means算法中聚类数K必须是事先给定的确定值,但在实际中K很难被确定,因此会产生随机误差。考虑到如果能精确地选取K值和初始聚类中心,K-means算法就能更确切地划分类簇[10-13],所以对典型的K-means算法进行了改进。

2.1 改进的K-means算法
1) 类间距离
令K={X,R}为空间聚类的聚类空间,其中,X={x11,x12,…,xij,xnm},i表示样本,j表示样本对象维数(1≤i≤n,1≤j≤m)。假设n个空间对象被聚类为K个簇,定义类间距离为所有聚类中心(簇内样本每一维的均值)到全域中心(全体样本每一维的均值)的距离之和:
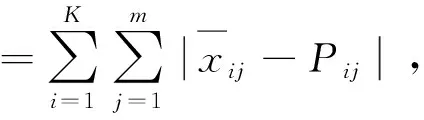
(3)

2) 类内距离
类内距离为所有聚类簇内部距离的总和,即每个簇的内部距离为簇内样本的每一维到簇内样本每一维的均值之和:
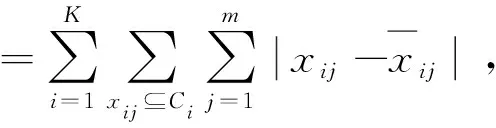
(4)
3) 距离代价函数
距离代价函数S(U,K)为类间距离与类内距离之和,即

(5)
式中变量的含义与式(3)、(4)中相同。
此K-means聚类改进算法以距离代价最小为基准,即当距离代价函数的值达到最小时,空间聚类结果为最优,K的取值由下式给出:

(6)

表6 聚类类簇确定表Tab.6 Clustering class cluster determination table
2.2 聚类分析
根据改进的K-means算法,可得聚类K=3。将初始聚类簇值与标准化样本数据导入SPSS建立聚类模型,具体步骤如下:
1) 对样本元素集合(其中每个元素具有n个可观察属性)建立输入数据矩阵;
2) 对数据进行归一化处理,得到指标矩阵;
3) 将指标数据矩阵导入模型中,建立K-means模型,根据已确定的K值对数据进行聚类,得到最终聚类结果。
对于88个A级轿车,依据上面确定的聚类数以及在完整数据建模流程运算下得到的聚类结果如表7所示。
2.3 实验对比和分析
将本文样本数据分别代入杨善林等[14]构造的距离代价函数与本文改进的新距离代价函数中,通过对比两种算法聚类后样本点到其所在类簇聚类中心的欧氏距离,比较两种算法的优劣。将样本数据应用到改进后距离代价函数并进行聚类分析得到结果(表7),K值为3。将数据代入改进前的距离代价函数得到K值为4,其聚类结果如表8所示。

表7 最终聚类结果表Tab.7 Final cluster result table

表8 改进前算法的聚类结果表Tab.8 Clustering result table of the previous algorithm
对于样本数据集S={X1,X2,…,Xi…,Xn},任意两个样本数据Xi和Xj间的欧式距离为:

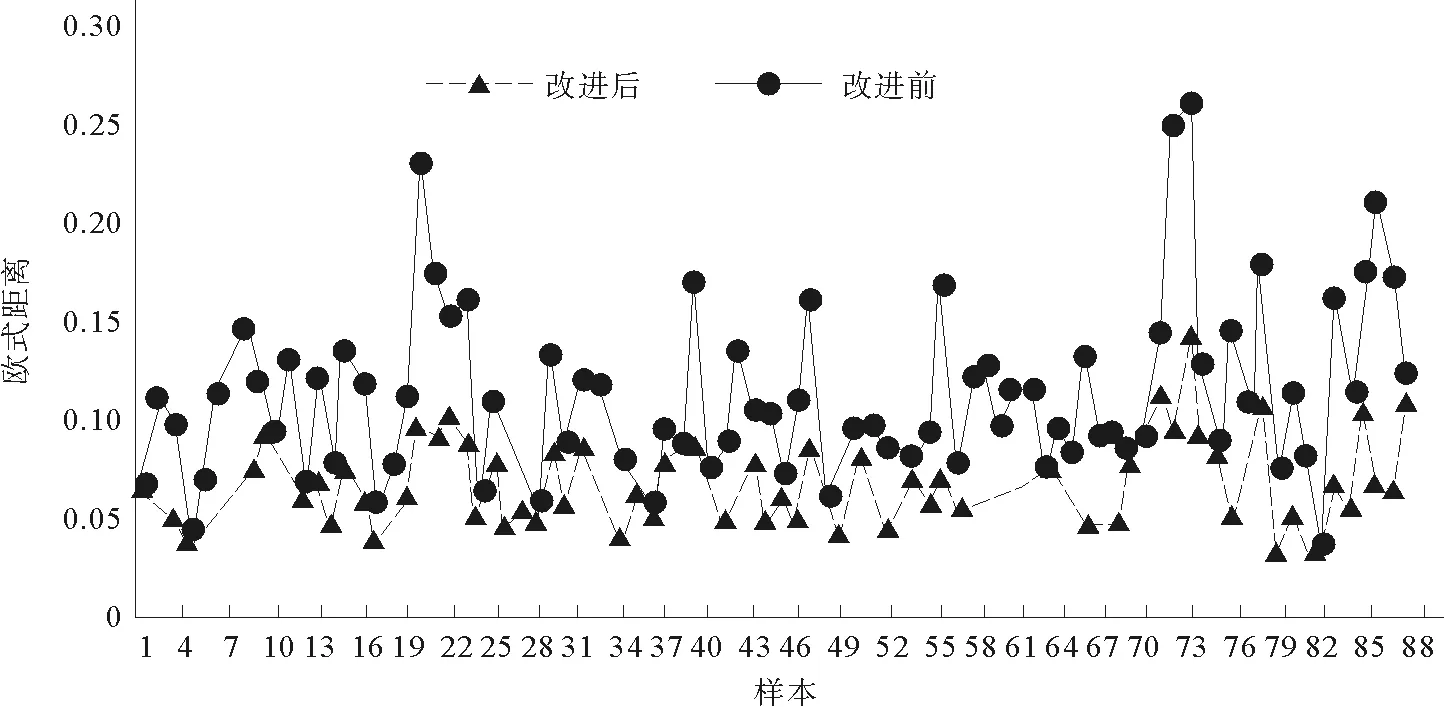
图1 算法模型改进前后样本欧式距离分布图Fig.1 Improved Euclidean distance distribution of sample before and after algorithm model
由图1中的折线分布状况,可知改进后算法聚类得到的各产品对象到其类簇聚类中心的欧式距离基本都小于产品对象使用改进前算法得到的欧式距离。因此根据K-means算法的定义属性,类簇内对象到其聚类中心的距离越小则相似度越高,类簇内对象关系越紧密,聚类效果越好。因此改进后算法更适用于本文的样本对象,得到更为准确的聚类效果。
3 SNA数值实验结果与分析
3.1 社会网络分析
将数据挖掘与社会网络分析相结合,可以在海量数据中寻找到有价值的信息并加以整合处理。通过数据挖掘对数据规整聚类,使得类簇之间不相关性达到最大。根据簇内样本分布及类族个数K,对每一类族和整体分别完成品牌竞争威胁的量化并构建竞争矩阵,对企业竞争力完成量化并构建竞争矩阵,然后通过社会网络分析软件进行中间中心度和凝聚子群等分析,形成数据挖掘在社会网络分析中的社会和商业应用价值。
1) 单类簇内品牌竞争威胁

2) 整体品牌竞争威胁

由表7中聚类结果,将同一类簇中相同品牌的产品规整为一体,根据上述竞争威胁数据指标定义,建立品牌间的竞争矩阵,如表9所示。

表9 品牌间竞争矩阵数据(部分)表Tab.9 Brand competition matrix data (partial data) table
将竞争矩阵与指标数据标准化后,导入社会网络分析软件UCINET(主要用于网络分析集成)生成企业竞争图,进行社会网络分析。首先分析产品性能数据,用UCINET可得到各个产品对于16个属性指标的侧重程度,如图2所示。

图2 企业产品对于属性指标的偏重程度图Fig.2 The degree of weight of enterprise product to attribute index
根据图2的链接路线及相关系数分析可得:
1) 以产品8、9、11…为代表的日系车在价格方面稍贵,马力、变速箱偏重较高,但是其扭矩和升功率都不高,因此动力性能一般,但其油耗低,内饰及安全性高于平均水平;
2) 以产品1、2、22…为代表的德系车价格相对要高,其性能侧重在变速箱、扭矩与升功率,因此动力较强,加速体验与驾驶乐趣较好,但其油耗稍微偏高;
3) 14、39、40…为代表的美系车,动力性能侧重较强,但油耗和价格都高于平均水平,内饰与安全性系数较为一般;
4) 以4、5、7…为代表的国产车在动力性能、内饰及安全方面的系数都要低于平均值,但价格相对较低,且加速性能不错,由图2可以看出国产品牌现已占据我国A级车市场的半壁江山;
5) 以3、45、48…为代表的韩系车动力方面侧重不足,内饰及安全系数略显一般,且毫无价格优势。
据此,用户可根据自己的偏重喜好选择适合自己的产品。
根据定义的企业竞争关系,导入品牌竞争矩阵生成品牌竞争关系1模网络图(显示品牌之间竞争力强弱),如图3所示。
根据结点中心度、紧密中心度,从图中分析可得:东风日产、上汽大众、上汽集团和吉利汽车等处于该图中心位置,与其他品牌联系紧密,因此这几个品牌目前在中国A级车市场中竞争力较强,对其他品牌造成有力威胁及冲击。边缘位置的力帆、北京汽车和广汽菲亚特等竞争力较差,对其他品牌威胁较小。综合之前聚类结果发现,同一品牌在三个类簇中分布的广泛程度与其品牌竞争力成正相关,表明品牌效应与企业底蕴在汽车市场同样影响巨大,因此汽车行业往往容易出现大鱼吃小鱼的企业兼并行为。
3.2 中间中心度分析
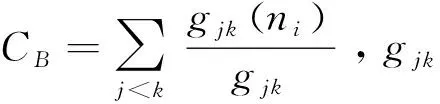

图3 品牌竞争关系1模网络图Fig.3 Brand competition relationship 1 model network diagram

品牌标号品牌1 Betweenness2 nBetweenness13上汽大众27.8552.80812上汽集团27.8552.80811吉利20.6322.0802比亚迪20.6322.0801北京现代20.6322.0806东风悦达起亚20.6322.0804东风日产20.6322.08010海马20.6322.08014神龙汽车20.6322.08025上汽通用10.2991.03820东风雪铁龙10.2991.038
由表10可知,上汽大众和上汽集团具有较高中间中心度,表明这两个品牌处于行业领先位置,是大多数品牌的竞争目标,同时也证实了在聚类类别中这两个品牌产品的高性能。紧随其后的是国产车代表吉利和比亚迪,表明中国国产车虽然产品性能还需加强,但因其低廉的价格优势在中国小型轿车市场中所占份额及市场竞争力越来越大。其他中心度为零的品牌说明在市场竞争中处于十分劣势地位,品牌所属企业需要制定措施积极整改,增强技术投入与产品营销水平,以免被市场淘汰。
3.3 凝聚子群分析
凝聚子群分析是社会网络分析学科对社会结构的网络研究,是对社会行动者之间实际存在的或者潜在关系的研究,简单来说“凝聚子群是满足如下条件的一个行动者子集合,即在此集合中的行动者之间具有相对较强的、直接的、紧密的、经常的或积极的关系。”派系是建立在互惠性基础上的凝聚子群,是指一个图中至少包含三个节点的最大完备子图,显示小团体之间的竞争关系,如图4所示。
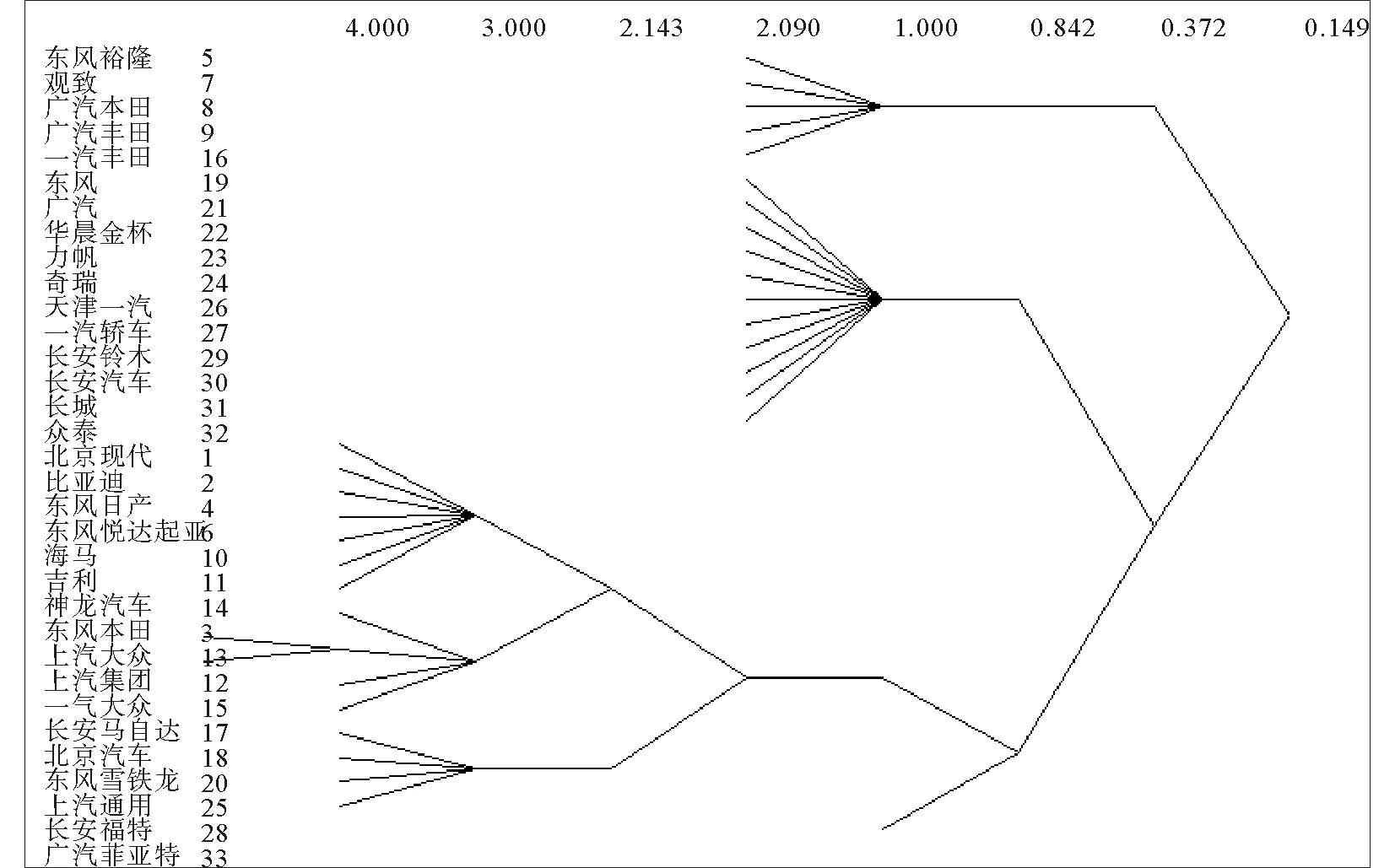
图4 派系分析图Fig.4 Factional analysis chart
通过派系分析图可知,东风裕隆、观致和广汽本田等处于第一个小团体,东风、华晨金杯和奇瑞等处于第二个小团体。以此类推,表明处于同一小团体中的品牌具有更为紧密的联系和直接竞争力,之间具有较强的竞争关系。上汽与上汽大众联系紧密,表明其同处于上海汽车集团旗下,只不过一个是合资品牌一个是国产品牌,在密切联系下二者也具有直接竞争关系。孤点的菲亚特则说明其竞争力不强,在中国市场处于淘汰边缘。
4 结论
应用AHP(层次分析法)和EWM(熵权法),对中国A级轿车市场数据进行了分析量化处理,设计了竞争威胁数据指标,基于改进的K-means聚类算法对该市场进行了社会网络分析;通过品牌间竞争矩阵构建了中间中心度及凝聚子群,分析了产品性能指标偏重程度和品牌所在市场的竞争地位,对用户选择合适的产品以及为品牌所属企业提供精准的市场竞争优势具有重要意义。数值实验表明:改进的K-means聚类算法对于文中样本对象,得到了更为精确的聚类效果。对中国A级轿车市场的社会网络分析准确有效。
