一种面向软件特征定位问题的语义相似度集成方法
2019-02-20何云李彤,王炜,李响兰微
何 云 李 彤, 王 炜, 李 响 兰 微
1(云南大学软件学院 昆明 650091)2 (云南省软件工程重点实验室(云南大学) 昆明 650091)
特征(feature)指软件系统中可识别的功能属性.特征定位(feature location)旨在建立特征与源代码之间的映射关系,是一切软件演化活动得以顺利实施的先决条件之一[1].软件特征定位是一种面向软件维护的智能推荐技术,可为开发人员在庞大的源代码数据中找到软件维护任务对应的起始位置.Wilde等人[2]于1992年提出了最早的特征定位方法——软件侦测(software reconnaissance),经过20多年的发展,成为波及效应分析[3]、软件复用[4]、需求可追踪性分析[5]等领域的支柱性技术.当前软件特征定位技术根据输入数据的不同大致分为4类[6]:静态方法[7-8](static method)、动态方法[9-10](dynamic method)、文本方法[11-12](textual method)和混合方法[13-14](hybrid method).文本方法由于具有高易用性、强扩展性和低开销等优点,成为了当前特征定位领域研究的热点.现有文本特征定位方法可分为3类:基于自然语言处理[12]、基于信息检索[1,15-16]或基于模式匹配[17]实现.近年来,机器学习特别是深度学习的发展促进了信息检索研究,同时也使基于信息检索的特征定位方法成为了当前研究的热点.
基于信息检索的特征定位方法有2个难点:
1) 减少代码语料中噪声数据.除蕴含功能语义信息的关键词外,源代码中还存在大量的无语义词汇噪声,例如代码的关键词new,public等.噪声数据导致经过索引的代码向量维度高、稀疏性强,使代码与查询语句间相似度计算准确率下降,整体影响特征定位的性能.以仅含有531个类的jEdit为例[14],在共计含有10 915个不重复源代码关键词的情况下,其单个类(class)内含有的关键词仅为几十至几百个单词不等.现有基于信息检索的特征定位方法通过人为设定停用词表对源代码的噪声数据进行过滤.由于源代码在预处理阶段会产生大量的未在停词表中定义的无实际语义的关键词,降低了停词表对关键词的过滤作用.
2) 基于信息检索的特征定位方法假设“源代码中的标识符、注释等关键词蕴含了与软件功能相关的语义信息”.开发人员使用记录了功能特征的自然语言作为查询语句.通过计算查询语句与源代码之间的语义相似度,实现特征与源代码之间的映射关系识别.上述计算需要将代码和查询语句转化为向量.当前研究大多采用信息检索方法实现源代码到索引空间内向量的转化.索引方法可以分为2类:基于“词袋”模型(bag of word)[18]的索引方法和基于词嵌入模型(word embedding)[19-20]的索引方法.基于“词袋”模型的方法优点在于计算简单、对单独词汇信息保持较完整,但其假设源代码中关键词是独立同分布的,没有上下文信息.文献[16]指出代码同样具有上下文信息.词嵌入模型能够有效刻画源代码关键词的上下文信息,同时能够有效地选择关键词.但该方法涉及大规模参数调优,参数取值对该方法的性能优劣起到决定性作用,参数的选择严重依赖于开发人员的领域知识和经验知识.同时,词嵌入模型非常强调词汇上下文关系,但源代码数据格式的特殊性导致其语法结构并不十分严格,因此在特征定位问题中单纯依赖词汇上下文关系刻画源代码之间的相似度也是不完备的.现有特征定位方法均是基于单一索引方法实现的,导致性能上各有优劣,均不能精确刻画源代码与查询之间的相似度.
为解决以上2个难点问题,本文提出了一种面向软件特征定位问题的语义相似度集成方法.本文主要贡献有3个方面:
1) 提出基于词性标注的源代码语料降噪方法.引入词性过滤对源代码关键词进行预处理,并讨论了源代码关键词中的词性问题.通过过滤特定词性词汇,在缩减索引空间内向量稀疏性的同时,提高了相似度计算的准确性,提升了特征定位性能.
2) 提出了一种集成“词袋”模型与词嵌入模型的语义相似度计算方法.该方法以源代码自身结构的“内聚度”和“耦合度”作为评价指标,将“词袋”模型索引方法与词嵌入模型索引方法所计算出的相似度进行集成,获得了更为精确的相似性度量.
3) 基于公开的数据集设计了完整的实验,详细报告了实验过程和结果,表明本文方法与现有信息检索软件特征定位方法[15-16,21]相比,具有更高的定位性能.
1 相关工作
如图1所示,现有基于信息检索的特征定位方法基本流程大致相似,包含3个基本步骤:预处理、索引、获取结果.
Step1. 预处理.包含提取关键词、分词、词根还原和去除停用词4部分.根据不同的粒度(类、方法等),提取源代码实体中的关键词,为源代码中每一个实体建立一个代码文档.分词操作将连续的字符串按照一定的特殊字符(例如驼峰命名法)或规则拆分成若干独立的单词.词根还原将意义相近的同源词和同一个关键词的不同形态进行归并,例如:inserting还原成insert.去除停用词操作删除代码中停词表记录的词.例如源代码中的数字、定冠词、不定冠词、单个字母等.预处理的好坏将决定源代码语料中关键词的多寡,并最终影响索引算法输出向量维度的大小以及稀疏性等.
Step2. 索引.将经过预处理的语料转换为索引空间内的数值化向量形式,即将语料转化为矩阵M,第i个代码文档对应矩阵中第i个列向量mi.用户提交描述特征的查询语句Q,将预处理后的Q转化为索引空间内向量q.
Step3. 获取结果.计算源代码向量mi与查询语句向量q之间的相似度,并按照相似度进行降序排列.相似度通常使用距离的形式进行表达.距离越近则相似度越高,认为该源代码具有查询语句描述的特征可能性越大.设定阈值h,将与查询向量q之间相似度大于h的源代码向量m1,m2,…,mn作为特征定位算法的输出结果,即检索结果.
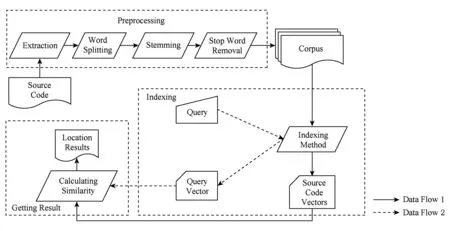
Fig. 1 The basic flow of existing information retrieval feature location methods图1 现有基于信息检索的特征定位方法基本流程
1.1 信息检索特征定位国内外研究综述
围绕基于信息检索的特征定位方法基本步骤,各国学者开了很多研究工作:
预处理大多使用成熟的自然语言处理技术[15-16,22]实现.分词采用Lucene①Lucene分词:https:lucene.apache.orgcore5_4_0coreorgapacheluceneanalysisTokenizer.html,NLTK②NLTK分词:http:www.nltk.orgapinltk.tokenize.html等工具实现;停用词表大多使用自然语言处理成熟的停词表,例如NLTK③NLTK停词表:https:gist.github.comsebleier554280或者Lucene④Lucene停词表:https:lucene.apache.orgcore6_1_0analyzers-commonorgapacheluceneanalysiscoreStopFilter.html提供的停词表;词根还原大多采用Poter Stemmer⑤Poter Stemmer:https:www.drupal.orgprojectporterstemmer,Lovins Stemmer⑥Lovins Stemmer:http:snowball.tartarus.orgalgorithmslovinsstemmer.html,Lancaster Stemmer⑦Lancaster Stemmer:https:github.comwooormlancaster-stemmer.上述工作均假设分词、词根还原、去除停用词3种操作能够提高特征定位算法的准确性.当前基于信息检索的特征定位方法通过停用词表方式过滤噪声词汇,均直接引用自然语言处理领域中的停用词表.但停用词表对噪声的过滤性能有限,主要原因在于停用词表中的词汇是人为指定的,极易出现误差,尤其是大规模语料库中,编制停用词表时极易造成停用词汇的遗漏.
语料中关键字的多寡将影响后续索引代码语料和查询语句向量的维度和稀疏性,维度和稀疏性对特征定位问题中语义相似度的计算具有重要意义.现有特征定位方法直接引用传统信息检索领域中的预处理方式,在经过预处理后语料库仍保留了数量庞大的关键词.例如,文献[14]对仅有531个类的jEdit4.3进行预处理后的不重复关键词仍多达10 915个.这使得后续索引步骤生成的代码向量维度和稀疏性都很高.
语料库及查询语句的索引是基于信息检索的特征定位方法中最为关键的步骤,同时也是研究成果最为集中的部分.自2004年Marcus等人[21]使用LSI(latent semantic indexing)实现特征定位以来,研究成果相继涌现.Poshyvanyk等人[23]提出了形式化概念分析方法(formal concept analysis),Cleary等人[24]将错误报告(bug issues)、邮件列表(mailing lists)、外部文档等非代码数据与代码数据同时作为输入,在某些环境下提升了定位的准确性.Biggers等人[15]应用LDA(latent Dirichlet allocation)进行索引,且与基于LSI的特征定位方法进行了比对.
LSI是一种有效的代码索引工具.由于代码是一种特殊的自然语言,LSI基于矩阵分解技术,具有识别同义词和压缩向量维数的能力.同时,LSI可在不知道代码的语法规则的前提下实现索引.LDA与LSI具有相似功能,但LDA具有更为复杂的数学模型,其定位性能在部分数据集上略优于LSI.无论LSI还是LDA,均是一种基于“词袋”模型的索引方法.该类模型的优点在于计算简单,无需太多领域知识协助.但“词袋”模型建立于无序性假设(exchange-ability)基础上,认为源代码中的关键词是独立同分布,关键词的上下文对其不产生影响.
2015年Corley等人[16]基于词嵌入模型,应用深度学习方法Doc2vec进行了特征定位研究,并在实验中取得了优于LDA的定位效果.基于词嵌入模型的索引方法,不但压缩了源代码向量的维数,并且记录了关键词之间的上下文关系.该类模型对文本进行索引时,以词汇共现关系为主要依据,最为经典的例子是可根据词汇共现关系推测出“king-queen=man-woman”.但此类模型涉及大规模的参数调优问题,如向量维数、训练窗口数、采样阈值、学习速率、聚类个数等,均对程序员有较高的领域知识和经验知识要求.同时,与自然语言文本不同,源代码文本格式较为特殊,其构成并不遵循严格的语法结构,词汇共现关系并不完全等价于语义上的相似.因此,词嵌入模型完全依赖词共现关系刻画源代码关键词之间的相似度也是具有其局限性的.
“词袋”模型等价于一种上下文无关文法,擅长于建模代码间关键词的差异信息(例如LSI关注于代码关键词词频的差异,LDA关注于代码主题概率分布的差异);词嵌入模型等价于一种上下文相关模型,擅长于建模代码内关键词的上下文信息.这种倾向性导致不同模型对源代码语料的索引必然存在不同方面的信息损失,且这种损失是存在互补关系的.
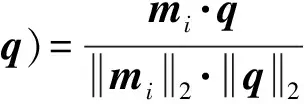
基于信息检索的特征定位方法建立在语义相似度计算基础之上,当前研究中对相似性计算结果影响较大的2个待解决问题可总结为:噪声问题和索引方法的选择问题.
1) 噪声问题.现有方法预处理步骤虽然可过滤一部分噪声数据,但这种过滤是不完全的.索引步骤中,LSI借助奇异值分解实现索引,但该方法仅将词频矩阵通过坐标变换方法实现空间转换,当变换空间维数小于原空间维数时,实现降维但无法识别哪些关键词是噪声;LDA认为代码是由具有多个主题的概率分布混合而成,同样不具备识别哪个分布式噪声的能力;Doc2vec使用深度网络实现词频向量的非线性变换与特征选择,也不具备噪声识别的能力.本文第1个研究目的是寻找适合于源代码数据特性的噪声过滤方式,进一步提升信息检索特征定位方法预处理步骤的噪声过滤性能,间接提高语义相似度计算的精确度,以期获得更为准确的特征定位结果.
2) 索引方法的选择问题.当前基于信息检索的特征定位方法,索引步骤均直接引用了传统信息检索领域的索引方法.不同索引方法,在性能上存在其特定优势与局限性.以单一索引方法为基础建立起来的相似性度量,必然存在失准问题.本文第2个研究目的是寻找一种语义相似度集成方法.该方法应契合源代码数据自身特性,可将不同索引方法计算出的语义相似度进行集成,从而实现优势互补,提高相似性计算的精确度,进一步提高基于信息检索的特征定位方法性能.
1.2 “词袋”模型和词嵌入模型索引算法的互补性
“词袋”模型索引方法生成形如(1,0,2,0,…,0,0,1)的长稀疏向量,该向量每个维度代表一个单词的出现频度.该模型假设每个单词均为独立同分布的,只以每个词汇的出现频度刻画源代码文本,并未记录任何词汇间的共现或上下文信息.因此,该模型索引方法可完整记录每个独立词汇信息,却无任何词汇上下文信息.
词嵌入模型生成形如(0.723,0.051,…,0.231,0.321,0.4231,0.448)的短实值向量,其记录的是映射于低维空间内的词之间的共现关系,即词汇的上下文关系.该模型以词汇间的共现刻画源代码文本,由于这种刻画是通过训练词汇间的共现关系并映射于一个低维空间内,映射过程会造成大量独立词汇信息的损失.因此,该模型索引方法优势在于可有效记录词汇上下文信息,却以损失独立词汇信息为代价.
综上,2种模型索引方法之间存在极强的互补关系,因此可通过合理集成实现优势互补,提高相似性计算的精确度,进一步提高基于信息检索的特征定位方法性能.
2 面向软件特征定位的语义相似度集成
在现有基于信息检索的特征定位方法基础上,本文主要工作如图2中深色四边形所示.预处理步骤,引入词性过滤,进一步过滤源代码关键词中的噪声信息,提高后续相似度计算的准确性.构建语料库后,索引步骤分别使用基于“词袋”模型的索引方法和基于词嵌入模型的索引方法对源代码进行索引,并在各自索引空间内计算语义相似度.然后,以软件源代码内部模块的“内聚度”和“耦合度”作为评价指标,将2种索引空间内所计算的相似度进行集成,获取最终语义相似度.最后,以集成的语义相似度作为源代码与特征之间的相似性度量,生成定位结果.
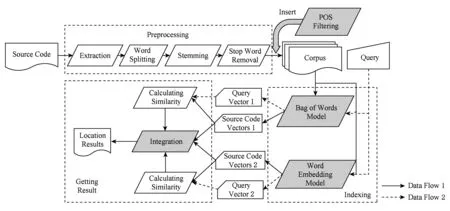
Fig. 2 Semantic similarity integration method for software feature location problem图2 面向软件特征定位问题的语义相似度集成方法
2.1 词性过滤
在自然语言处理领域,词性标注有助于充分利用英语词汇以及句子中所蕴含的语义知识[25].文献[25]专门讨论过源代码中的词性问题,认为词性对源代码文本相关研究具有重要意义.针对源代码中噪声过滤不完整导致的相似度计算困难问题,本文方法在预处理步骤引入词性过滤,仅保留语料库中的名词、名词性词组、动词、动词性词组、形容词、形容词性词组、副词及副词词组成分作为关键词,建立基于词性的关键词筛选方法,降低关键词的数量.
为提高源代码的可读性,源代码的变量名、类名、方法名等均由有意义的实词充当.这里所指的“有意义”即蕴含“语义知识”的意思.源代码中语义知识通常是通过名词、动词、形容词和副词4种词性的关键词表达的.作为功能实体被执行时,源代码中的名词表述了对应的功能实体在执行过程中被调用的“对象”(变量、类、方法等),动词表述了对这些“对象”执行的“动作”,形容词表述了这些“对象”有什么样的“特点”,而副词表述了“如何”对这些“对象”进行“动作”.因此,这4类词性词汇在源代码关键词中可被认为是源代码语义知识的主要载体,故在词性过滤算法中只予以保留这4类词汇.
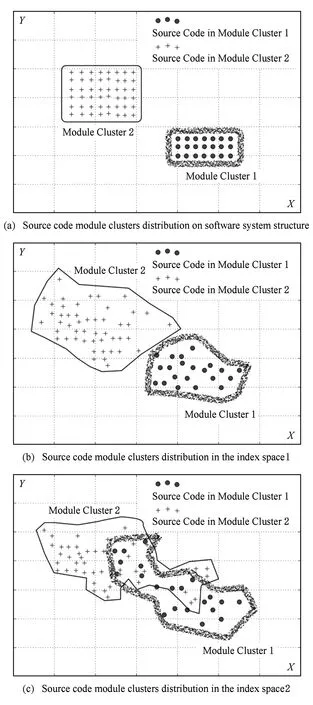
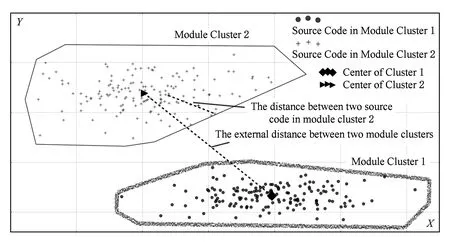
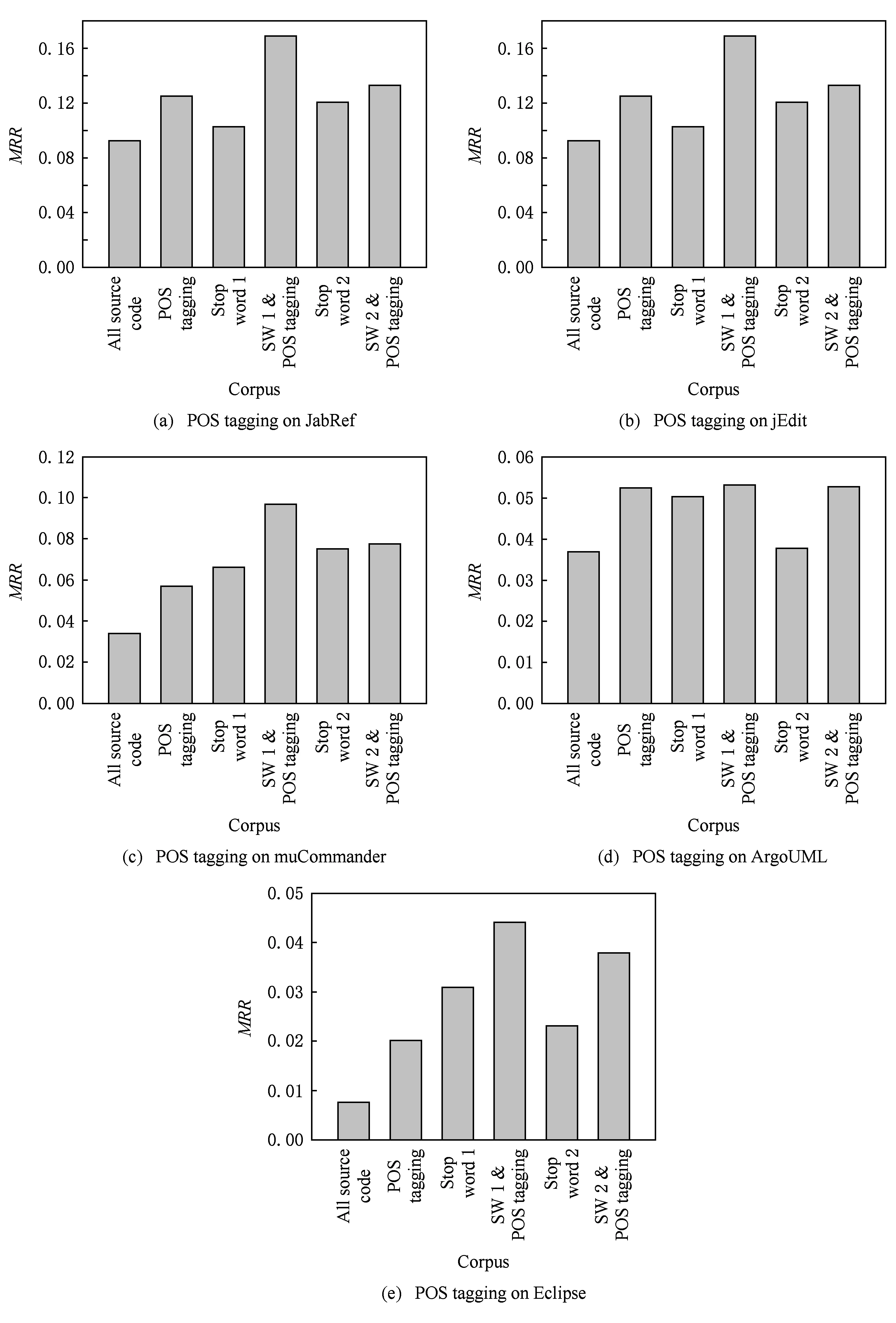
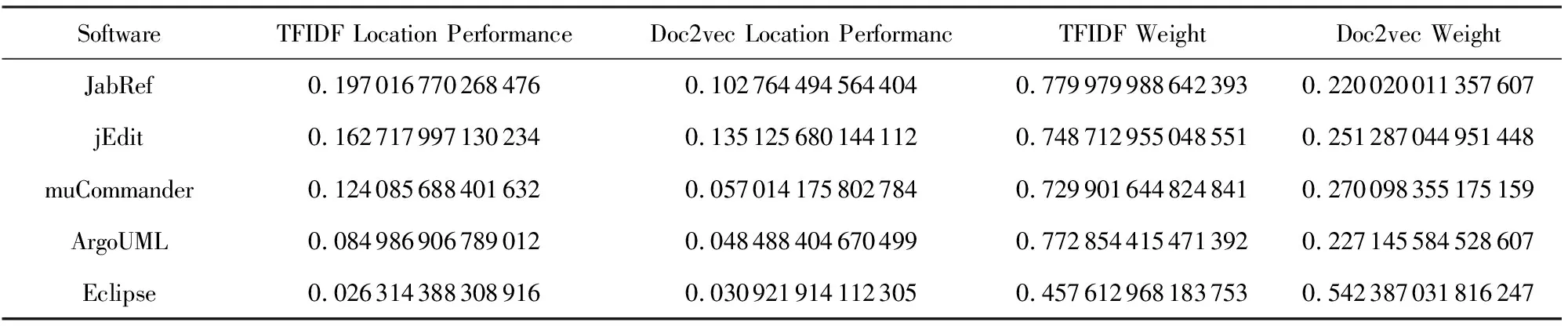
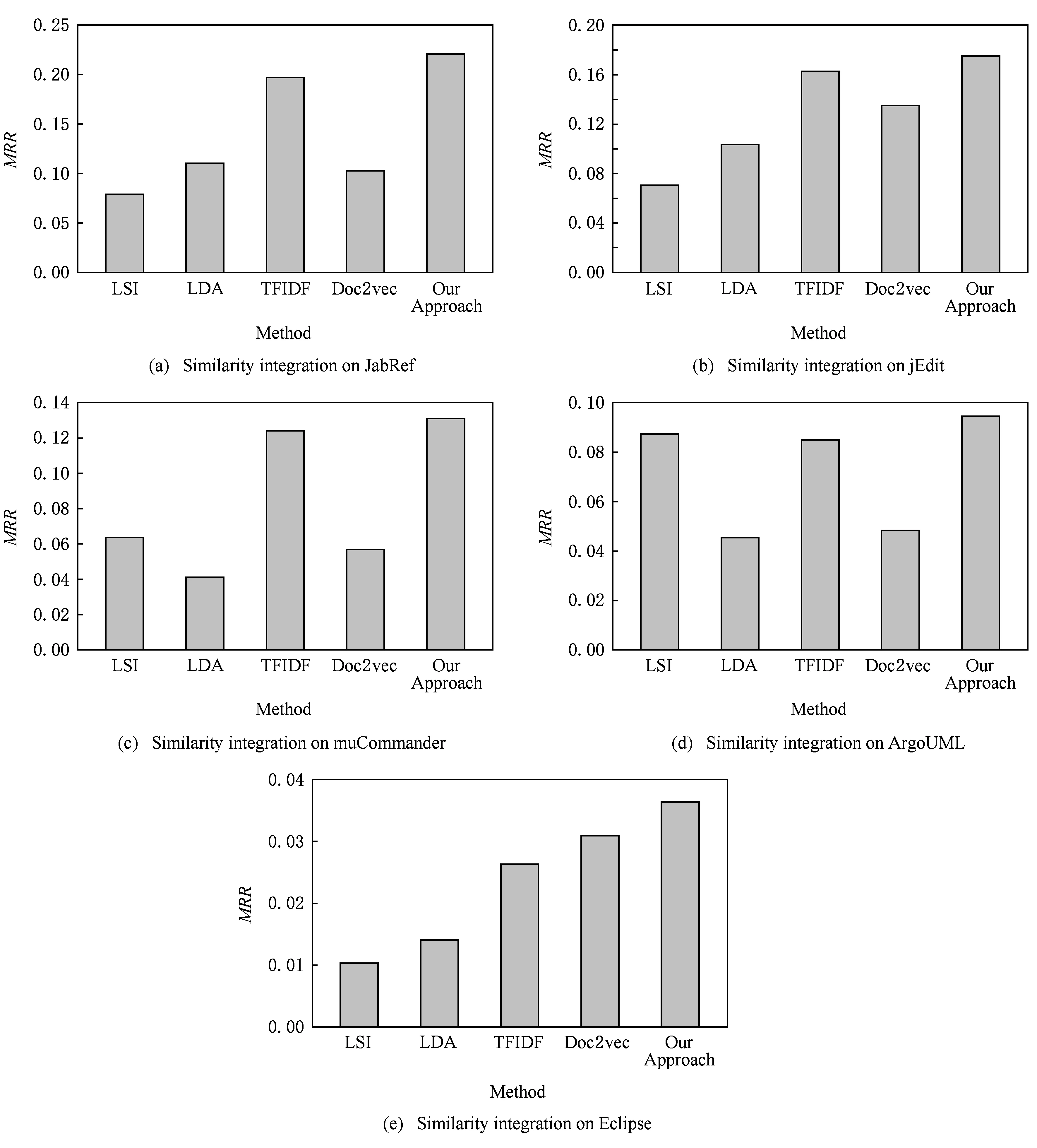
假设存在由3个源代码文本向量所组成的语料库D={Class1,Class2,Class3},其中每个向量对应于源代码中的1个类(class).图3表示了该语料库在词性过滤前后进行文本向量化,向量在空间中的分布情况.有色圆代表蕴含功能语义信息的词性单词,无底色圆代表不含功能语义信息的词性词.向量Class1与向量Class2间的夹角为α,向量Class2与向量Class3间的夹角为β.从图3(a)中可看出,由于不含功能语义信息词性单词的干扰,导致向量重心的偏移,此时α>β,以余弦距离作为向量间相似度定义,则有Sim((Class1,Class2)>Sim(Class2,Class3).对源代码进行词性过滤后,其向量化表示如图3(b)所示,因不含功能语义信息单词被过滤,向量重心发生变化,从而有Sim(Class1,Class2) Fig. 3 The vectors distribution in the indexing space before and after POS filtering图3 词性过滤前后向量在索引空间中的分布 定义1. 源代码语料库.Da是所有源代码关键词w的集合,即Da={w1,w2,…,wi,…,wn},其中wi代表语料库中的第i个源代码关键词,该语料库共由n个源代码关键词组成. 定义2. 词性.词性是由10个元所组成的集合post={tn,tpron,tadj,tnum,tv,tadv,tart,tprep,tconj,tinterj},其中tn,tpron,tadj,tnum,tv,tadv,tart,tprep,tconj,tinterj分别代表词性:名词、代词、形容词、数词、副词、冠词、介词、连词和感叹词.Da与post存在映射关系o′: (w1,w2,…,wn)→t=o′(Da),t为集合post中的元.蕴含语义知识的词性为集合postin={tn,tadj,tv,tadv}. 算法1详细描述了词性过滤的计算过程. 算法1. 词性过滤算法. 输入:Da,postin; 输出:Dc. ①Dc=∅,T={tag1,tag2,…,tagn}; ② for eachtagi∈T ③tagi=null; ④ end for ⑤ for eachwi∈Da ⑥tagi=posTaging(wi); ⑦ end for ⑧ for eachtagi∈T ⑨ iftagi∈postin ⑩ insertwitoDc; 算法1输入为所有源代码关键词集合Da以及蕴含语义知识的词性集合postin,输出为过滤掉不蕴含语义知识词性关键词后的语料库Dc.行①初始化存储结果用的集合Dc=∅,同时定义另一个集合T={tag1,tag2,…,tagn}用于标记每个关键词的词性.T中的元素与Da中的元素存在一一对应关系,即Da中关键词wi对应于T中的tagi,由于Da中共有n个源代码关键词,因此T的元素个数也为n.行②~④先对T中的所有元素进行初始化,将其初始值设为null.行⑤~⑦识别Da中每个源代码关键词wi的词性,并将识别的结果存储于对应的tagi,这里函数posTaging(wi)的返回值为集合post={tn,tpron,tadj,tnum,tv,tadv,tart,tprep,tconj,tinterj}中的1个元素.行⑧~⑨检查T中的每一个元素tagi,若tagi∈postin={tn,tadj,tv,tadv},则将对应的wi插入到结果集合Dc中.行返回结果Dc. 基于信息检索的特征定位方法,核心在于量化地计算源代码与查询间的语义相似性.相似性问题均可通过向量空间内距离的方式进行定义、度量或推导.现有基于信息检索的特征定位方法在将源代码语料库和查询语句进行向量化索引后,以索引空间内源代码向量与查询向量之间的距离作为度量,刻画两者的相似度.由于不同模型的索引方法在进行向量转化时,具有其特定优势和局限性,在此基础上计算出的向量间距离并不能充分刻画向量间的相似度.至此,比较自然的想法是将不同索引空间内的相似度(即距离)进行集成,充分利用不同索引方法的优势特性,获得更为精确的相似度计算结果.关键问题在于:如何将不同索引空间内的距离信息在适当尺度内进行合理有效集成. 文献[26-27]已经证明若干距离的线性组合依然是一个距离,因此针对任意一对源代码向量mi和查询语句向量q,两者间相似度可以描述成为不同索引空间中距离的线性组合,即 其中dk(mi,q)表示第k种距离计算方法.该问题的核心是寻找参数ωk,使相似性刻画最优.显然直接计算最优参数ωk是困难的,因此本文方法将距离计算中的参数设置问题转化为求源代码结构最优问题.具体来说,由于代码中的每一个类是按照“高内聚低耦合”的原则进行组织,即位于同一个类(class)中的各个方法(method)间具有高内聚度,而功能模块间具有较低耦合度.故而,最优的距离计算方法一定是最能反映源代码“高内聚低耦合”属性的计算方法. 定义3. 模块类簇.在按“高内聚低耦合”方式构建的软件系统内,是指具有相似或相关功能的源代码被放置在同一个模块内,每个模块称为一个模块类簇.一个软件系统是由多个模块类簇组成的. 例如,在面向对象软件系统中,一个类(class)是由其内部的多个方法(method)组成的模块类簇.在结构化软件系统中,一个源代码文件可以理解为是由一群函数(function)组成的模块类簇. 假设有一个软件系统,该软件系统由2个源代码模块类簇内的多个源代码组成.软件系统结构上的模块类簇分布应为图4(a)所示,实心圆点代表模块类簇1中的源代码,十字符号代表模块类簇2中的源代码.不同模块的源代码根据“高内聚低耦合”原则,被规整地置于2个模块类簇中.分别使用2种不同的索引方法对图4(a)中源代码进行索引,其向量在相应索引空间内的分布分别如图4(b)和图4(c)所示.对比图4(b)与图4(c)可发现,图4(b)索引空间1内源代码向量分布更接近于图4(a)源代码原始结构上的分布,其内所有源代码均被明显地分隔于2个模块类簇内.而图4(c)索引空间2内的源代码则分布相对较为混沌,2个模块类簇内源代码分布出现了较大重叠区域.此时,可认为索引方法1对于源代码的转换更为贴近源代码本身结构,则其所计算出的相似度(距离)更为合理,在线性组合集成时应予以较高权值.而索引方法2则反之.基于这种思想,本文认为可以用模块类簇的外距和内距对不同索引方法生成的向量空间进行合理性度量,从而计算出优化的距离加权参数ωk. 在此基础之上,本文提出了一种面向特征定位问题的语义相似度集成方法,该方法能够将不同索引空间内的相似度(距离)进行线性组合集成,根据索引空间内向量分布与源代码本身结构的一致性程度,计算出集成时的加权参数,从而获得能够充分刻画源代码与特征之间相似度的距离表达.下面将对本文方法进行详细介绍: 定义4. 内距.若某软件源代码是由m个模块类簇构成的,分别计算位于同一个模块类簇内所有源代码间距离的均值,将计算出的m个均值相加即为该软件源代码的内距interDis.内距interDis的计算公式为 Fig. 4 Source code module clusters distribution in different index space图4 源代码模块模块类簇在不同向量空间内的分布 图5示例了一个由2个模块类簇组成的软件系统,图5中圆点和十字符号分别代表2个模块类簇内的源代码数据点.每个数据点对应于1个方法(method),每个多边形框内所有的数据点构成1个模块类簇,这样的1个模块类簇可以是1个类(class),也可以是1个文件夹.模块类簇2中虚线标示了模块类簇内2个源代码之间的距离.分别计算出所有位于模块类簇2内源代码间的距离,然后取均值,再以同样方式求出模块类簇1内所有源代码间的距离均值,这2个均值相加即为该软件系统的内距;实心三角和实心正方形分别代表了2个模块类簇的重心,其间的距离即为软件系统的外距. Fig. 5 Distance definitions about module cluster图5 与模块类簇相关距离定义 在此基础之上,本文提出相似性算法的详细计算过程如下: 算法2. 语义相似度集成方法. 输入:Sim1,Sim2,D1,D2; 输出:查询语句与各源代码的相似度集合Simint. ④ end for ⑥interDis2=interDis2+calculateInter- ⑦ end for ⑩ end for interDis1)+(exterDis1interDis1)), ω2=(exterDis2interDis2)((exterDis2 interDis2)+(exterDis2interDis2)); 算法2行①对本中所使用变量进行初始化.行②~⑦分别计算2种索引空间内软件源代码的内距,行⑧~分别计算2种索引空间内软件源代码的外距.行分别计算距离进行线性组合时所用参数ω1和ω2.行~使用参数对2个索引空间内计算出的相似度距离进行线性组合,并求出最终相似度.行返回结果. 为验证本文方法的性能,词性过滤步骤将最新基于词嵌入模型Doc2vec的信息检索特征定位方法[16]作为基线方法,相似度集成步骤将LSI[21],LDA[15],Doc2vec[16]作为基线方法,通过公开基准数据集进行对比实验测试.本文实验,主要围绕以下研究问题(research questions)展开: 研究问题1. 词性过滤步骤是否能够在现有方法基础上提升特征定位性能?能够提升多少性能? 研究问题2. 本文提出的语义相似度集成算法是否能够在现有方法基础上提升定位性能?能够提升多少性能? 本文方法的有效性建立在“软件的源代码是高质量的”基础上,高质量的源代码有2个标准:语料库内的关键词有意义和源代码以“高内聚低耦合”结构进行组织.语料库内关键词的质量,可通过统计无意义词汇在源代码中的占比进行评估,具体将在3.1节讨论.源代码是否以“高内聚低耦合”结构组织,则可通过以下方式验证:若源代码的结构是“高内聚低耦合”的,则通过索引方法的外距与内距之商可以有效评估出相应索引方法的特征定位性能.将A和B这2种索引方法进行相似度集成,假如软件系统源代码组织是“高内聚低耦合”的,当通过A方法计算出的源代码外距与内距之商(即加权时的权值)高于B方法时,可认为A方法更符合源代码的分布.此时,单独使用A方法进行定位,定位性能应高于单独使用B方法.反之,则B方法的定位性能应高于A方法.通过验证这种一致性,可以验证软件系统的源代码是否具有“高内聚低耦合”特性.因此,本文实验部分还需验证以下问题: 研究问题3. 索引方法对源代码内聚耦合性的符合程度是否与索引方法定位性能的分布一致? 为保证实验的客观性,选择已有的基准数据集(benckmark)进行实验.实验的核心目的在于对比本文方法与基线方法性能差异,基准数据集能够为整个对比过程提供无偏差数据和评价基础,从而保证实验的客观性. 本文选择Dit等人[6]公布的软件维护任务测试数据集进行实验.该数据集共由5款开源软件的源代码和特征数据组成,具体数据规模如表1所示: Table 1 Data Sets表1 本文实验数据集 数据集内所有特征均为相应软件的官方问题追踪系统(issue tracking system)内真实存在的数据.每个特征以ID作为标识,由2部分组成: 1) Description[ID].问题描述,关于特征的文本描述,本文实验将该文件作为查询语句(query)使用. 2) GoldSet[ID].正确答案集,记录了与特征真正相关的源代码,用于验证特征定位的结果. 数据集中的5款软件均为较成熟的开源软件,源代码的维护及更新均有其独立的问题追踪系统,并由专门的团队进行管理,保证了数据集内软件源代码的质量.同时,本文统计了数据集内所有软件源代码中无意义词汇的数量及其占比,如表1所示.这里指的无意义词汇是指用单个字母命名的变量,以及形如“c2”,“m2”等的非常规词汇,在统计时以前者居多.从表1中可以看出,无意义词汇在5个软件源代码中的占比在4.56%~7.43%之间.即对于该数据集而言,源代码中的关键词逾90%以上都是有意义的词汇.从该角度可认为数据集内的软件源代码是属于高质量源代码范畴的. 对本文方法性能进行定量评估,需使用一定度量标准对实验结果进行度量和对比.软件特征定位本质上是信息检索问题,因此适用于信息检索的度量标准.度量特征定位方法的性能,应衡量第1个与特征真正相关的源代码在结果列表(ranking list)中出现的位置,越靠前则定位性能越高[16,22,28-29].因此,特征定位研究[16,22,28-29]多使用平均排序倒数(mean reciprocal rank,MRR)作为度量标准,本文实验也采用该标准.MRR的具体计算公式如下: 其中,Q为实验中所使用所有查询语句(query)的集合;|Q|代表Q中查询个数;ei为在第i个查询中,第1个与查询语句正确相关的源代码位于结果列表中的排名.MRR数值越大,代表特征定位性能越好. 3.3.1 预处理 提取源代码中的关键词,以方法(method)为粒度,建立语料库,提取出源代码关键词数量见表1.然后,依次进行分词、词根还原及去停用词处理.去停用词步骤,本文选取2个不同的停用词表进行实验,停用词表1由自然语言处理领域公开的3个常用英文停用词表(含SMART停用词表)合并而成,共有887个词条;停用词表2来源于Wikipedia,共有119个词条①https:en.wikipedia.orgwikiStop_words.使用Python环境下自然语言处理包NLTK对语料进行词性标注,标注后对词性为名词、动词、形容词和副词外的其他单词及词组进行过滤.分别测试预处理步骤仅使用词性过滤、仅使用停用词、既使用停用词又使用词性过滤情况下的定位性能,具体结果将在3.4节进行讨论. 3.3.2 源代码语料索引 为单独分别讨论本文方法提出的2个步骤对于特征定位问题的改进意义,验证本文提出的相似度集成方法时,索引步骤使用的为未进行词性过滤的语料库.索引步骤选择了2种索引方法:基于“词袋”模型的索引方法TF-IDF(term frequency-inverse document frequency)和基于词嵌入模型的索引方法Doc2vec.TF-IDF是最为基础的 “词袋”模型索引方法,使用长稀疏向量对文本进行索引,LSI和LDA均是在TF-IDF基础上建立的.由于TF-IDF生成的向量未做任何降维处理,最大程度地保留了语料库中的词汇信息,故本文实验中选择其作为“词袋”模型代表进行集成.Doc2vec是新兴的一种文本索引方法,该方法基于词嵌入模型和深度学习技术,以短实值向量对文本进行索引,该方法是当前自然语言处理和信息检索领域最热的文本索引方法. 分别使用TF-IDF和Doc2vec,将语料库转化为向量表示,生成的向量集分用Dtfidf和Dd2v表示.本文实验中,使用Python环境下Gensim②http:radimrehurek.comgensim库对源代码语料进行索引. 3.3.3 查询语句索引 查询语句同样需要分别转化为TF-IDF和Doc2vec索引空间内的向量表示.在TF-IDF索引空间内,查询语句直接进行转化即可.由于Doc2vec基于多层神经网络实现,可划分为词向量层和文本向量层.该模型首先训练生成词向量,在词向量的基础上训练生成文本向量.2种方式将查询语句转化为向量:1)将查询语句视为文本,与源代码文本共同进行训练,将生成的文本向量作为查询向量;2)计算查询语句中每个单词的词向量,取平均向量作为查询向量.文献[16]对2种方式生成的查询语句进行了实验讨论,结论认为方式2)定位性能在普遍情况下明显优于方式1).因此,本文实验中采用方式2)计算查询向量. 定义6. Doc2vec索引空间查询向量.用户提交查询语句为Q,Q是由m个单词w组成的集合Q={w1,w2,…,wm}.对于任意wi∈Q,通过模型M对wi进行训练,生成wi所对应的词向量wvi.则对于用户所提交的查询语句Q,其相应的Doc2vec索引方式生成的查询向量qd2v为 分别在TF-IDF和Doc2vec的索引空间中使用余弦相似度计算源代码向量与查询向量间的相似度,生成2个索引空间内的相似度(距离)集合,分别用Simtfidf和Simd2v表示. 3.3.4 获取结果 至此共计生成2种索引方法的语料库向量集和相似度集合:Dtfidf,Dd2v,Simtfidf,Simd2v.划分每个软件系统中的源代码.位于同一个类(class)中的所有方法(method)被划分为同一个模块类簇,模块类簇数量见表1,以此模块类簇为依据计算代码间的内距与外距. 使用2.2节介绍的相似度计算方法,将TFIDF与Doc2vec索引空间内的相似度集合进行加权集成,生成最终的相似度集合Simint.最后,将源代码中所有的方法(method)以Simint中对应的相似度大小为依据进行降序排列.从排列好的源代码队列顶端开始逐个检查源代码,记录特征对应的GoldSet在队列中出现的首个位置,该位置即为定位结果性能ei. 分别计算数据集内所有特征的定位结果性能ei.至此,实验结束,统计结果. 3.4.1 研究问题1讨论 词性过滤步骤是否能够在现有方法基础上提升特征定位性能?能够提升多少性能? Fig. 6 Location performance with POS filtering图6 词性过滤前后定位性能对比 图6记录了应用深度学习模型Doc2vec作为索引方法进行词性过滤实验的结果.All source code为未做去停用词,也未进行词性过滤的结果,POS tagging为只进行词性标注的结果,Stop word1和Stop word2分别为只使用停用词表1和停用词表2的结果.SW 1 & POS tagging为在停用词表1的基础上进行词性过滤的结果,SW 2 & POS tagging为在停用词表2的基础上进行词性过滤的结果.从图6可以看出,只进行词性过滤或只进行去停用词,性能均无法达到最优.性能最优的定位结果均出现于既进行去停用词,又进行词性过滤时.对于实验中的5个数据集,词性标注在停用词表1基础上可获得平均34.21%的性能提升,在停用词表2基础上可以获得平均27.55%的定位性能提升.综合词性过滤在实验中5个数据集2个停用词表上的表现,可回答研究问题1:本文提出的词性过滤步骤可有效提升信息检索特征定位方法的性能,词性过滤步骤在实验中为文本特征定位方法平均带来了30.88%的定位性能提升.由于Eclipse具有最大规模的源代码语料库,因此从图6(e)中可以看出词性过滤对于Eclipse软件系统的定位性能提升是最为明显的. Table 2 Location Performance and Integration Weight Distribution表2 定位性能与权值分布 Fig. 7 MRR performance with different similarity calculation method图7 不同相似度计算方法定位结果MRR性能 3.4.2 研究问题2讨论 本文提出的语义相似度集成算法是否能够在现有方法基础上提升定位性能?能够提升多少性能? 图7记录了使用不同相似度计算方法定位时的MRR性能.其中,LSI为文献[21]方法,LDA为文献[15]方法,Doc2vec为文献[16]方法.从图7可以看出,这3种方法在不同数据集上定位性能不尽相同,但本文方法在所有数据集上均能保持定位性能最优.JabRef数据集上,本文方法比次优的TFIDF方法定位性能提高了12.03%;jEdit数据集上,本文方法比次优的TFIDF方法提高了7.56%;muCommander数据集上,本文方法比次优的TFIDF方法提高了5.64%;ArgoUML数据集上,本文方法比次优的LSI方法提高了8.36%;Eclipse数据集上,本文方法比次优的Doc2vec方法提高了17.80%.综上,可以回答研究问题2:本文提出的相似度集成方法可以有效提高信息检索特征定位方法的性能.在实验中,相似度集成步骤为信息检索特征定位方法平均带来了10.28%的定位性能提升. 3.4.3 研究问题3讨论 索引方法对源代码内聚耦合性的符合程度是否与索引方法定位性能的分布一致? 实验中集成的2种索引方法定位性能及其相应的加权权值分布如表2所示.表2中所示定位性能为图7中相应定位方法的性能,加权权值也为图7中本文方法计算相似度时的权值.从表2中可以看出:在JabRef,jEdit,muCommander,ArgoUML这4个软件数据集上,TFIDF的定位性能优于Doc2vec方法.此时,通过本文方法计算出的权值(即外距与内距比)TFIDF要高于Doc2vec;然而在Eclipse数据集上,Doc2vec方法定位性能要高于TFIDF.此时,本文方法计算出的加权权值Doc2vec高于TFIDF.至此,可回答研究问题3:索引方法对源代码内聚耦合性的符合程度与索引方法定位性能分布是一致的.从该角度可以证明:对于本文方法中使用的数据集,源代码的内聚耦合程度有助于评估索引方法对源代码刻画的合理性. 因此,可以得出结论,本文方法的加权不是偶然获得的结果.本文方法基于2个前提条件:1)软件的源代码是按照“高内聚低耦合”进行组织;2)源代码向量的内聚耦合性可用于评估出相应索引方法的特征定位性能.表2的数据证明了在实验的5个数据集中,本文方法的前提是成立的,否则不会保持内聚耦合程度与定位性能分布的一致性. 本文研究是词性过滤与语义相似度集成在特征特征定位领域的初步探索,其实际应用势必会存在一些问题.本文研究还存在以下适用前提: 1) 本文实验是建立在面向对象语言Java所编写的软件数据集上的,故本文方法对其他语言编写的软件特征定位问题适用性还有待验证. 2) 本文未讨论参数问题,所有参数使用的均是Gensim的默认参数.这是由于参数调优问题涉及大量的领域知识支撑,且较为复杂,有专门的相关研究进行讨论.限于文章篇幅,本文中只讨论与软件工程相关的问题. 3) 本文方法是建立在软件源代码本身是高质量代码基础上的,即变量名的命名是规范且有语义的,同时源代码以较为严格的“高内聚低耦合”标准进行结构组织. 基于信息检索的软件特征定位方法,一直是软件特征定位领域研究的热点.针对现有方法中的噪声和索引模型选择导致的语义相似度计算失准问题,本文提出了一种面向软件特征定位问题的语义相似度集成方法,并开发出了一整套本文方法所使用的定位工具.通过对5款开源软件组成的基准数据集进行实验,验证了本文方法的有效性. 基于信息检索的软件特征定位方法,本质是将信息检索技术应用于源代码,既有传统信息检索技术的通用特性,又具有因源代码格式导致的特殊性.本文方法基于源代码数据自身特性,通过语义相似度集成的方式计算源代码与特征之间的相似性,提高了基于信息检索的特征定位方法性能.通过实验验证了本文方法的有效性,但也存在一些有待探讨的问题,这些问题为将来的研究指出了方向.为进一步验证本文方法的有效性,也为提高本文方法的普适性,将对本文方法在更多的项目上进行验证,并继续研究本文方法是否能够应用于信息检索或计算机其他研究领域.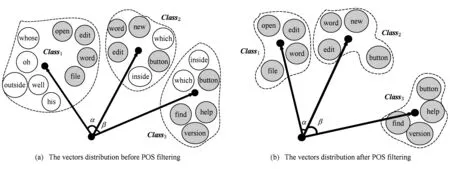
2.2 语义相似度集成方法
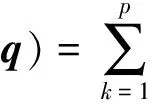
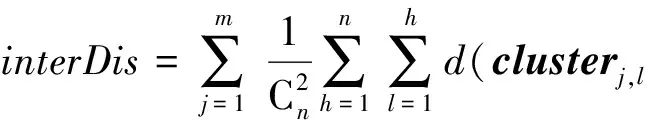
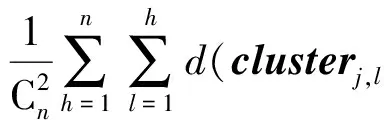
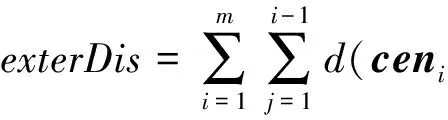
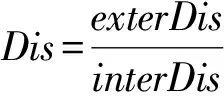
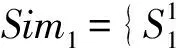
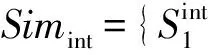
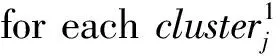
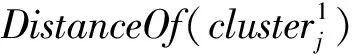
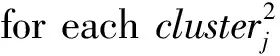
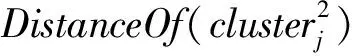
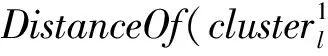
3 实 验
3.1 实验数据
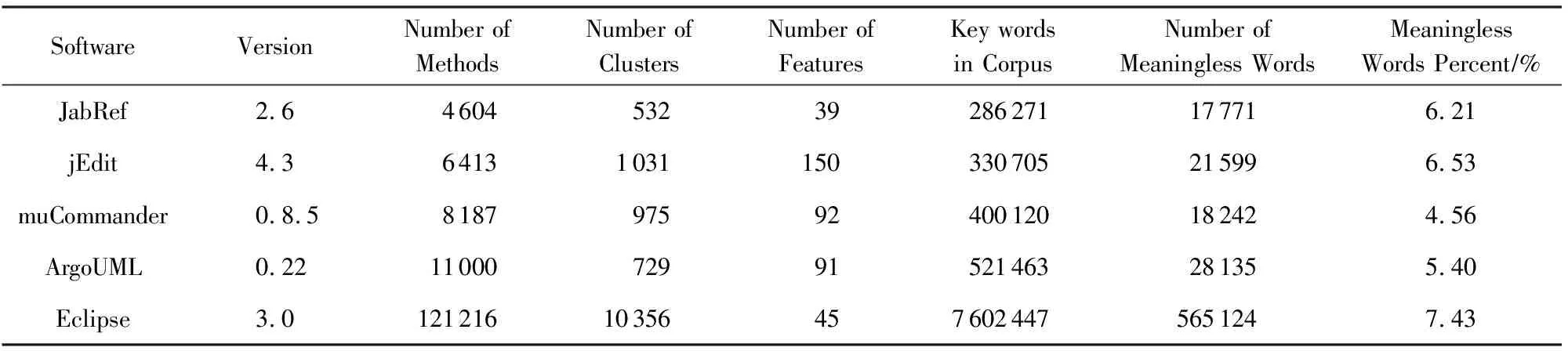
3.2 评价标准
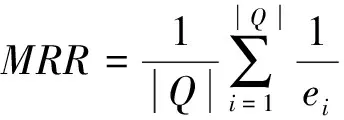
3.3 实验过程
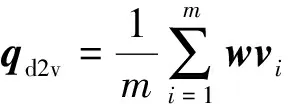
3.4 实验结果
4 本方法适用性
5 总 结
