低速率流淘汰与d-Left散列相结合的大流检测算法
2019-02-20李春强董永强吴国新
李春强 董永强, 吴国新,
1(东南大学计算机科学与工程学院 南京 211189)2 (计算机网络和信息集成教育部重点实验室(东南大学) 南京 211189)
大量研究[1-4]表明:网络中少数具有较大数据量的数据流生成了网络的大部分流量,而其他大量的数据流的数据量总和仅占小部分的网络流量;数据流在带宽占用上也表现出不均衡性,其中少量具有较高速率的数据流消耗了大量的网络带宽[4].网络中数据流的这种分布特征严重影响了网络传输的有效性[4-6],导致了数据流传输带宽占用上的不公平性,对报文的传输时延产生了较大影响[7],严重时甚至发生拥塞导致报文丢失.在网络设备上,有效检测出这些数据流,进行适当的管理与控制[8-11],可以改善网络传输的有效性:比如缓解网络拥塞[12]、增加网络的有效吞吐率、降低报文传输时延及报文丢失率、改善网络传输的公平性[13]等.
目前的研究根据数据流的统计特征定义了大流(elephant flow)与小流(mice flow).文献[7-9,12]将数据量超过一定门限(如64 KB,1 MB,100 MB等)的流定义为大流,这一定义主要关注的是数据流的数据量;文献[14]将数据传输速率达到链路容量的一定比例(如链路容量的1%,0.1%)的流定义为大流,这一定义重点关注的是数据流的传输速率.
由于网络的可用带宽是动态变化的,通常各数据流源端根据探测到的网络状况总是不断尝试以尽可能高的速率发送数据,这使得共享同一瓶颈链路的多个数据流的数据传输速率之和会超出链路的带宽容量而导致拥塞.由于链路的带宽容量是以数据传输速率衡量的,因此准确及时地检测出具有高传输速率的数据流是实施流量的管理与控制、改善网络传输有效性的关键.然而对具有较高的传输速率但仅有少量数据的数据流而言,其生存期短,对网络传输的有效性不会产生持续性影响,因此在进行传输控制时可以将其忽略.对于具有较高的传输速率和较大数据量的数据流,由于不断竞争网络的可用带宽而对网络传输的有效性产生持续性影响,成为网络传输控制的主要对象.综上所述,本文将具有较高传输速率和较大数据量的数据流定义为大流.由于网络中传输的数据报文大小并不统一,大报文的数据量甚至相当于小报文的几十倍,数据流的报文发送频率与数据流的传输速率并不是完全等价的,为了确保检测的准确性,将数据流的传输速率而不是报文的发送频率作为大流检测的重要依据.
随着网络技术的发展,传输链路的带宽容量和数据流的传输速率越来越高.目前,支持100 Gbps链路的网络设备[15-16]已经可以商用;高速网络的转发能力对数据流检测算法的处理提出了高的性能要求.Hash表具有良好的平均查找性能且易于实现,将Hash表应用到网络报文处理上得到了广泛的研究.然而对于普通的Hash表,当待查找的条目存在Hash冲突时,需要多次存储器访问才能获得查找结果,无法确保最差情形下的处理性能.如何有效处理Hash冲突、降低存储器的访问次数,是Hash表实现高效查找的关键.d-Left散列通过使用多个子表,可以有效改进Hash表的处理性能,因此本文针对高速网络中,以流量管理与控制为主要目标的大流检测,为了高效识别出速率和数据量均超过一定门限的大流,将低于速率门限的数据流的淘汰与d-Left散列表的存储结构相结合,提出了基于d-Left散列的低速流淘汰检测方案(lowest rate flow eviction integrated withd-Left Hash, LRE-DH),论文的主要贡献包括:
1) 对来自实际网络中流量数据的分布特征进行分析,为基于速率与数据量的双门限检测方案提供现实依据;
2) 使用d-Left散列[17]表存储流检测的数据结构,将d-Left散列表的存储结构与基于流速率的流缓存替换算法相结合以实现高效的大流检测,通过适当配置d-Left散列的子表数,确保算法的准确性及最差情形下的处理性能;
3) 对算法的准确性与存储开销等进行了理论分析;
4) 通过真实网络数据对提出的算法进行了仿真测试,结果表明:在相近的存储开销下,保持高的处理性能的同时,本文算法的准确性优于LRU派生算法S-LRU[5]和L-LRU[18-19],以及CSS[20]与WCSS[20]算法.
1 网络流量特征
网络的流量特征是进行大流检测、实施网络传输控制的基础与依据.不失一般性,分析了6组流量数据的特征.这些流量数据分别是:来自WIDE项目中MAWI(measurement and analysis on the WIDE Internet)工作组[21]的跨太平洋骨干链路的流量数据T2014,T2015,T2016,T2017,还有WAND网络研究组[22]提供的网络边缘链路的流量数据T2011,以及某高校数据中心[23]的流量数据UNV.流量数据的概要信息如表1所示:
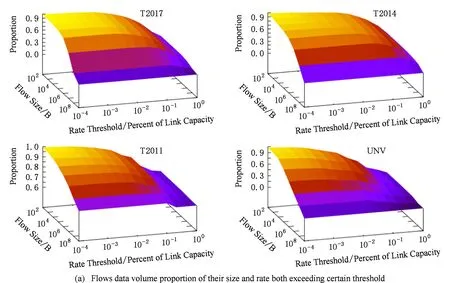
数据流基于速率与数据量的分布特征是双门限大流检测的实现依据,图1给出了速率与数据量2个维度下数据流的联合分布特征,由于T2015,T2016与T2017的分布特征相似,因此在图1中没有提供.图1(a)给出了超过给定速率门限和字节数的数据流的数据量占总数据量的比例,图1(b)给出的是超过给定速率门限和字节数的数据流的流数目占总流数目的比例.从图1可以看出:网络中的主要数据流量集中在少量的具有较高速率和较大数据量的数据流数目中,即少量具有较高的速率和较大数据量的数据流消耗了大量的网络带宽.比如:在T2017的数据中,数据量超过100 KB、传输速率超过0.01%链路带宽容量的数据流的数据量之和超过了总数据量的89%以上,而相应的流数目不到总流数的1%.
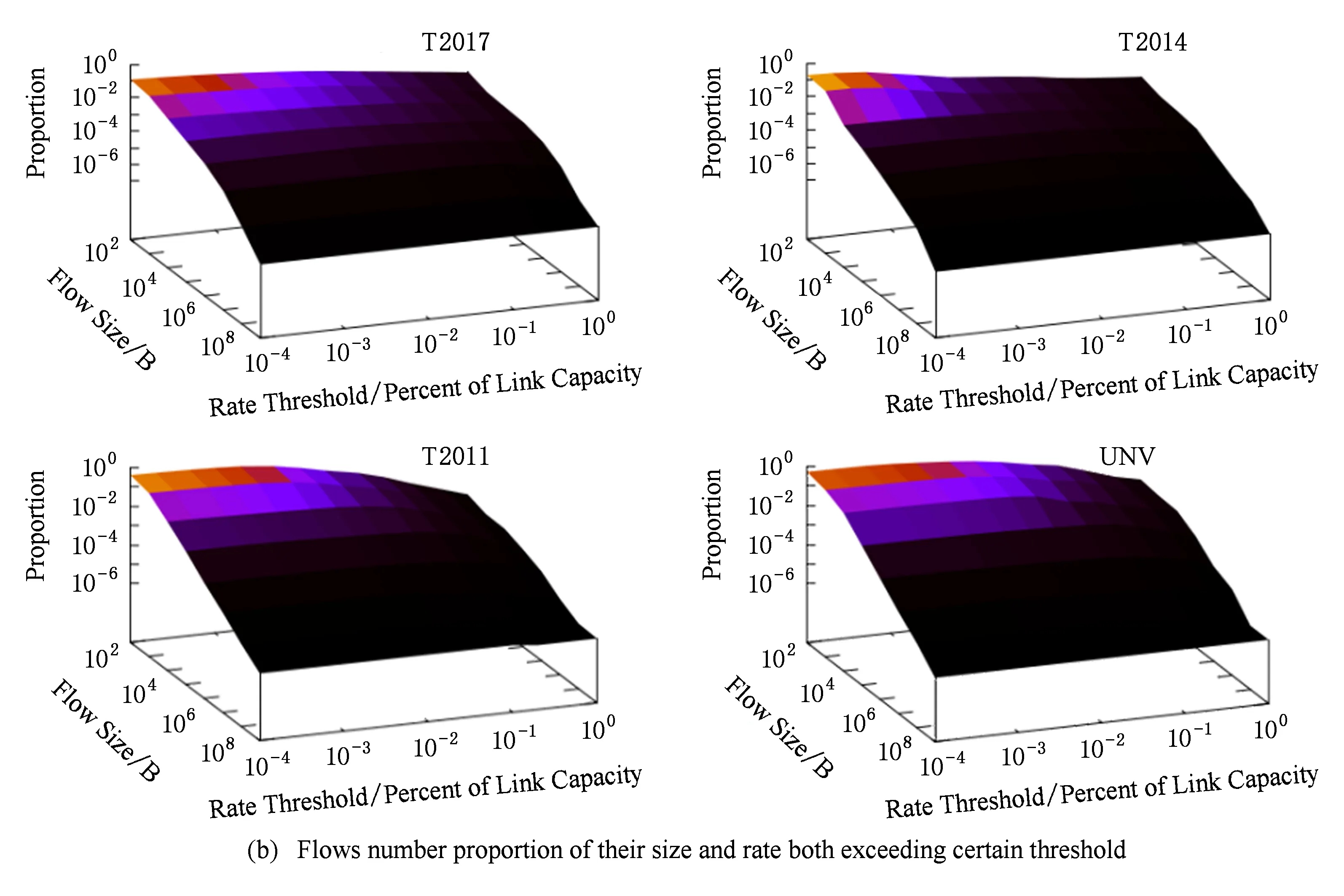
Fig. 1 Flows distribution features of their size and rate both exceeding certain threshold图1 速率与数据量超出各门限的数据流的分布特征
从图1(b)可以看出:一部分数据流的速率超过了一定门限但仅发送了少量的数据,即网络中一部分数据流属于高速短流,结合图1(a)可以看出这部分数据流的流量少,对于流量管理而言可以忽略;而另一部分数据流以较低的传输速率发送了较多的数据,即网络中一部分数据流是低速长流,结合图1(a)可知这部分数据流占用的网络带宽份额非常低,对于流量管理而言也可以忽略.
2 相关研究
对于网络中的大流检测而言,一种简单直观的方法就是对网络中所有的数据流进行统计,这一思路虽然非常简单,但对存储技术提出了非常高的挑战;这是因为随着网络带宽的增加,并发传输的数据流数目非常大(如表1中的T2014,T2015,T2016,T2017所示,15 min的网络流量的数据流数目超过了300万条),报文到达的速率非常高,需要存储器具有大的存储容量与高的访问速度.DRAM(dynamic random access memory)具有大的容量但访问速度难以满足高速网络大流检测的要求;SRAM(static random access memory)虽然具有高的访问速度但其容量有限.因此,受存储技术的限制,难以通过维护全部数据流的统计信息来检测大流.大流检测在网络管理等领域的应用,引起了研究人员的大量关注.尤其是随着应用场景的拓展,网络链路带宽的增加,不断涌现出新的研究成果;这些新成果从准确性、性能、存储开销等方面对已有的研究进行了改进.根据存储结构中是否维护数据流的标识符信息可分为无状态流统计检测方案与基于部分流统计的检测方案.
2.1 无状态流统计检测方案
在该类方案中不必存储数据流标识符,而是通过Hash函数将数据流的统计信息与一组计数器关联,当与之关联的所有计数器都超过所设定的门限后将其标识为大流.由于存在Hash冲突,因此一个计数器会与多个数据流相关.这类方案的代表有多阶段过滤器(multi-stage filter, MSF)[14]、Count-Min[24]、基于CBF(count Bloom filter)[25]的检测算法等.这类方案本质上是基于概率的检测方案,具有较小的存储开销;但会导致将速率和数据量都非常小的流误识别为大流,误识别率与总的流数目及存储开销密切相关;总的流数目越大,误识别率也越高.虽然可以通过增加存储开销来降低误识别率,然而,对网络数据流而言,随着检测时间的推移,进入系统中的数据流数目越来越多,Hash冲突率随之增加,从而导致检测的误报率增加;由于网络设备连续工作的时间非常长,数据流的数目可以看作无限多,而存储空间是有限的;为了降低这种错误率则需要对部分低于一定门限的计数进行清理,清理时需要扫描整个存储结构,由于报文是连续到达的,清理操作可能会导致部分到达的报文来不及处理,以至于检测性能下降.尤其是误识别的小流对以改善网络传输为主要功能的大流识别是难以接受的.λ-HCount[26],FDCMSS(forward decay count-min and space saving)[27]给出了基于时间衰减模型的流检测方案,在新报文到达进行计数统计时,对已经存储的统计值乘以衰减值(衰减值等于λt,t是已存储统计值的生存时间,0<λ<1)后加上新报文的权重,这相当于对新到达的报文给予更高的计数权重,可以起到清理过期信息的作用;这类方案可以实现常数级的清理操作,但其检测的准确性跟衰减参数的设置密切相关;而且其中的统计数值缺乏实际的物理意义.
2.2 基于部分流统计的检测方案
这类方案需要存储流的标识符及相应的统计信息,由于存储空间是有限的,因此只能维护一部分流的信息,而且需要根据一定的策略对检测缓存中的条目进行淘汰.根据检测缓存条目的淘汰方式可分为:集中式淘汰与分散式淘汰.
在集中式淘汰的部分流统计方案中,每次进行缓存条目淘汰时,需要扫描整个缓存空间,按照预先设定的规则淘汰非大流缓存条目.这类方案的代表有基于采样保持S&H(sample and hold)的检测算法[14]、有损计数LC(lossy counting)检测算法[28]、概率型有损计数PLC(possibility lossy counting)检测算法[29]、加权有损计数WLC(weight lossy counting)检测算法[30]、IM-SUM[31](iterative median summing) 算法等.这类方案中,将网络流量划分为多个片段(按照时间或数据量、报文数),在每个片段的末尾淘汰部分非大流信息.这类方案存在的问题是:在淘汰非大流信息时,新到达的报文可能来不及处理而影响报文的转发性能.
计数类(LC,PLC,WLC等)检测算法以及IM-SUM算法,在数据流量有限的前提下可以确保检测的准确性,然而这与网络中的数据流量应该近似的看成是无限的情况是不相符的.
分散式淘汰每次只要淘汰一个缓存条目.基于最近最少使用[7](least recently used, LRU)的流检测算法属于分散式淘汰,该算法根据大流通常具有较高的报文到达频率,因此使用队列维护流条目被淘汰的顺序,根据数据流报文的到达情况修改流在队列中位置;然而大量突发到达的小流会严重影响算法的准确性.为了缓解突发小流对准确性的影响,文献[18-19] 提出了基于界标的LRU(landmark-LRU,L-LRU)算法,该算法的基本思路是:为了避免候选的大流条目被突发到达的小流淘汰,使用界标将存储器分成至少2个片段,不同存储器片段存储的流条目具有不同的淘汰优先级.新创建的流条目首先放在最低优先级的存储器片段,当报文到达频率超过一定门限后,则放到更高优先级的存储器片段中,而当高优先级的存储器片段满后,并不直接淘汰相应的流条目而是先放到低优先存储器片段中.LRU类的检测算法对于任意到达的报文的处理复杂度都是常数级,能够满足高速网络的性能需求,但其准确性易受存储开销及数据流到达分布特征等因素的影响.
SS(space saving)算法[32]同样是一种基于分散式淘汰的部分流统计检测方案,该算法将数据流包含的报文数作为大流检测依据,在流检测缓存中维护与数据流的报文数密切相关的统计计数,该统计计数值等于数据流收到的报文数与一个误差值的和.每当新流到达且无可用存储空间时,将统计计数值最小的流条目淘汰,并将这一统计计数作为误差值.SS算法实现常数级的淘汰与报文处理操作,但需要动态分配存储空间并维护大量的指针,不利于硬件实现.CSS(compact space-saving)算法[20]对SS算法进行了改进,虽然实现了静态存储空间分配,但其处理操作仍然比较复杂.在CSS算法的基础上,文献[20]提出了基于滑动窗口模型的WCSS(window compact space-saving)大流检测算法.对于报文的到达和流的淘汰,CSS及WCSS算法虽然可以常数级的操作,但处理的过程较为复杂.
2.3 大流检测的其他相关方案
通常,为了降低系统的资源开销,减少单位时间处理的报文数以及流数目,将采样技术[33]应用于高速网络的大流检测中.文献[34]提出了通过周期性报文采样实现大流检测的方案,该方案根据大流检测的误报率和漏报率的折中使用贝叶斯理论计算出采样率,方案存在较大的检测误差且无法避免误报率.采样还可以用于减少突发小流的到达对大流检测的干扰,比如在S-LRU(sample LRU)检测[5]算法中,报文到达后,在检测缓存中查找报文所属的流,若已存储相应的流条目,则调整流在排序队列中的位置,若未存储新到达报文所属的流,则通过采样的方法确定新到报文所属的流是否进入检测缓存中的.对基于采样的方案而言,采样率的设置以及数据流的分布特征对大流检测的准确性有着较大的影响.
文献[35-37]提出了基于滑动窗口的大流检测方案,这种类型的方案只根据最近所发送网络流量的统计信息来检测大流,使用数据窗口维护最近发生的报文信息,当新的报文到达,则将窗口中最旧的报文信息及所属流的相应统计信息删除;其中窗口大小的设置对大流检测的效果有着很大影响.
为了改善大流检测算法的准确性、性能、存储开销,还出现了将几种检测技术组合进行大流检测的方案:比如TCBF-LRU[38],LRU-BF[39-40]等.其中TCBF -LRU使用TBF(time Bloom filter)和CBF根据到达报文的时间间隔与统计计数过滤小流,使用LRU结构检测大流;其中的CBF结构中小流的统计信息无法被有效清理,随着流数目的增加会导致过滤效果越来越弱.LRU-BF算法使用BF(bloom filter)存储已识别出的大流、判断到达的报文是否属于已识别出的大流,通过LRU算法过滤小流;该方案主要的问题是,随着检测出的大流数目的增加导致大流识别的误报率增加.
针对无限的流数目与数据量,在存储空间有限的条件下,不管何种检测算法,及时有效地清理小流的统计信息,对改善高速大流检测的性能与准确性都是至关重要的.基于Hash映射的无状态检测方案,如果不能及时有效地清理与小流相关的统计信息,随着检测时间的推移,进入系统中数据流数目的增多,检测的准确性会逐步下降;如果按照数据流片段的方式消除与小流相关的统计信息,需要扫描整个数据结构,而报文的到达是连续的,这会影响报文处理的实时性与性能.LRU类检测算法根据数据流中最近的报文相对命中频率而不是流的传输速率,淘汰系统中的流条目,易受突发到达的小流的干扰而影响算法的准确性.
3 低速流淘汰与d-Left散列相结合的大流检测算法
定义1. 网络中传输速率超过一定门限的数据流定义为高速流;所有高速率构成的集合称为高速流集合.
定义2. 网络中数据量超过一定门限的数据流定义为长流;所有长流构成的集合称为长流集合.
定义3. 网络中同时满足高速流和长流特征的数据流定义为大流;所有的大流构成的集合称为大流集合.
为了改善网络传输的有效性,需要对网络中大流进行控制.为了有效检测出网络中的大流,避免将小流误识别为大流,本文采用了部分流统计的检测方案.该方案的基本思路为:当已存储的数据流有新报文到达时,计算出数据流的传输速率与数据量,若数据流的传输速率与数据量均达到给定门限时,将其标识为大流.当淘汰缓存中一条数据流为新数据流分配存储条目时,根据缓存中已存储数据流的传输速率选出需要淘汰的数据流条目.
3.1 基于传输速率的流条目淘汰
当到达的报文属于新的数据流但无可用的存储空间时,需要依据流的传输速率淘汰一个流条目.流的传输速率等于流传输的数据量除以流的生存时间,流的生存时间为从流的创建时间与当前时刻之差,因此系统中所有流的传输速率随着时间的推移而不断变化,需要动态地计算.这一方法的优势在于:对于存储结构中已过期的流,由于不再有报文到达,随着时间的推移,其生存时间越长,计算出的传输速率会越来越小,自然会被淘汰;尤其对于仅包含单个报文的流,可以较快地将其从存储结构中淘汰掉,有效缓解了大量单报文流的突发到达对检测效果的干扰.
当报文到达时,需要在存储器中查找当前报文所属的数据流;如果未发现所属的数据流,且无可用存储空间时,则还需要进一步扫描存储器,根据数据流的传输速率淘汰一条数据流.对于存储器的查找而言,内容可寻址存储器(content addressable memory, CAM)具有优异的查找性能可以满足高速网络中报文处理的查找需求;然而若选择一条流淘汰,则需要扫描已存储的多个流条目才能确定出要淘汰的流,导致检测算法处理性能的急剧下降,难以满足高速网络的处理要求.Hash表具有良好的平均查找性能且易于实现,将Hash表应用到网络报文处理上得到了广泛的研究.然而对于普通的Hash表,当待查找的条目存在Hash冲突时,需要多次存储器访问才能获得查找结果,无法确保最差情形下的查找性能.而且,当新流的报文到达,不存在空闲条目时,流条目的淘汰是大流检测方案的关键点.
3.2 LRE-DH检测算法及分析
使用普通Hash表存储大流检测流条目的主要问题是Hash冲突的存在导致流条目的查找与淘汰的处理难以满足高速网络中大流检测的性能要求.为了确保大流检测的性能,采用了d-Left散列表[17]存储大流检测的流条目.基于流的大小与传输速率的双门限检测算法的具体描述见算法1.
d-Left散列表中包含d个子表,为了便于分析与说明,对d个子表从0到d-1进行编号.网络中新的报文达到时,提取报文的头部字段生成流标识符,以待查的流标识符为输入使用d个不同的Hash函数生成d个索引,分别在d个子表中相应的Hash桶进行查找;若找到对应的流条目,则进行字节数的累加,并判断数据量是否达到大流的数据量门限,若达到数据量门限则再计算流速率是否达到大流的速率门限.若未发现新收到报文对应的流条目,从编号最小子表的Hash桶开始判断是否存在空闲的存储空间,若存在空闲的存储空间,则将新流的条目插入到其中.若没有可用的存储空间,则在当前新流Flow对应的d个子表的Hash桶中找出传输速率最小的流minFlow,如果该数据流的传输速率小于淘汰门限,则将该流淘汰,释放后的空间分配给当前的新流Flow,记录新流Flow的生成时间及其字节数;如果minFlow的速率超过了淘汰门限,则忽略当前到达的新流Flow.这样的处理可能会导致大流的漏检,下面对该方案的漏检率进行分析.
算法1. 基于d-Left散列的低速流淘汰检测算法(LRE-DH).
①Receive(Packet);*报文Packet到达提取报文Packet的头部字段,生成所属的流Flow的标识符Flow.Id*
②Flow.ID=GetFlowID(Packet);
③Found=false,k=0;
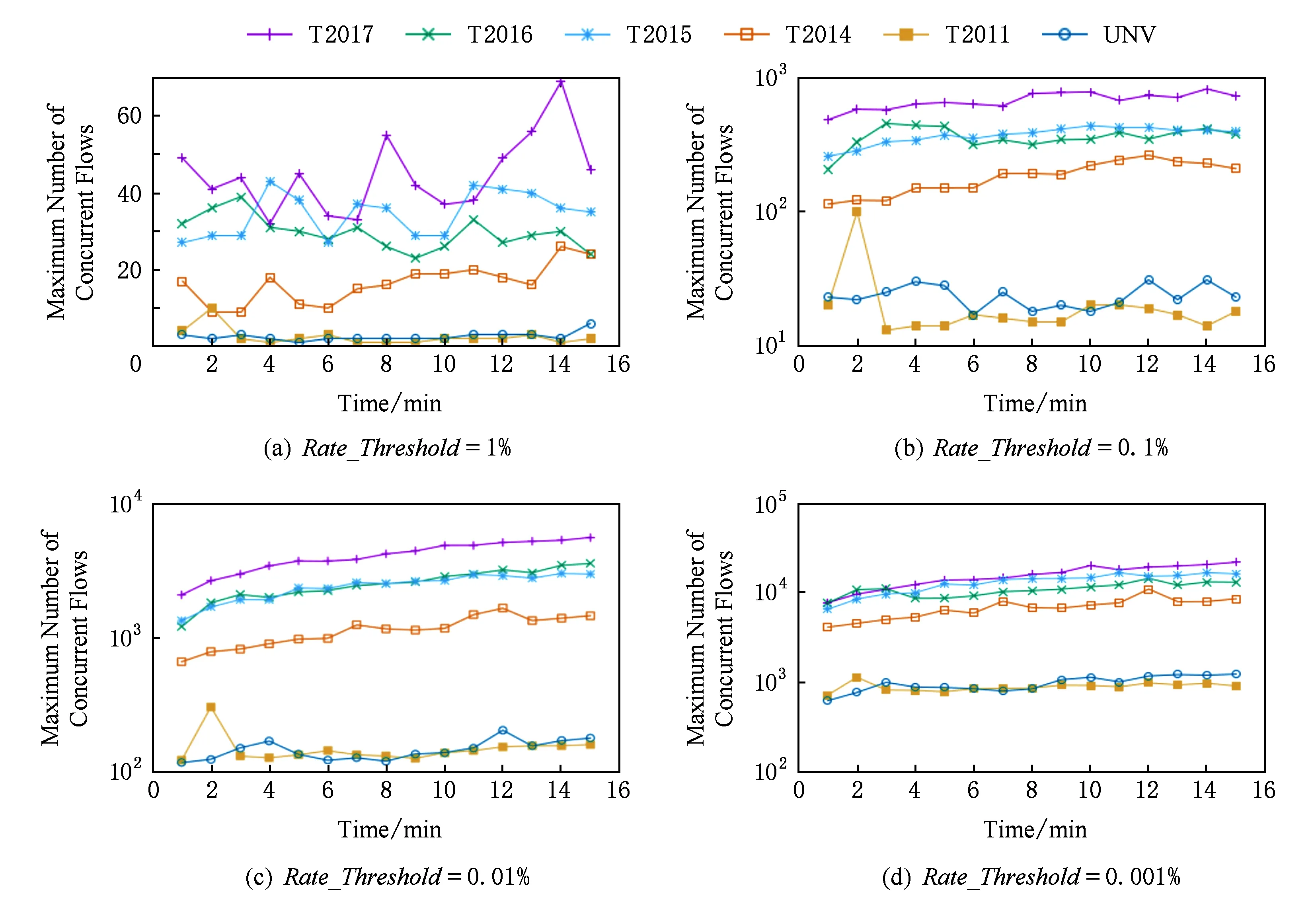
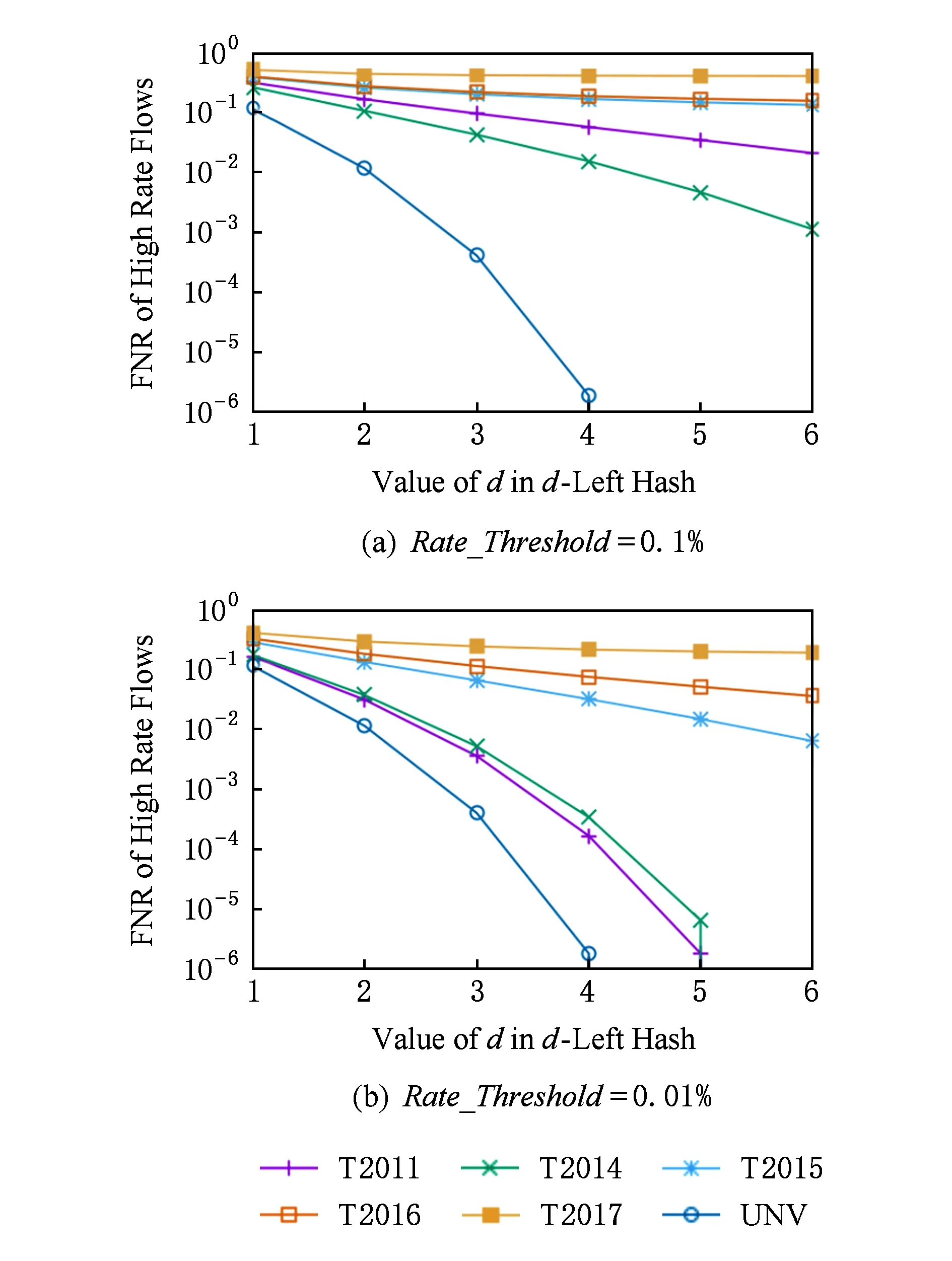
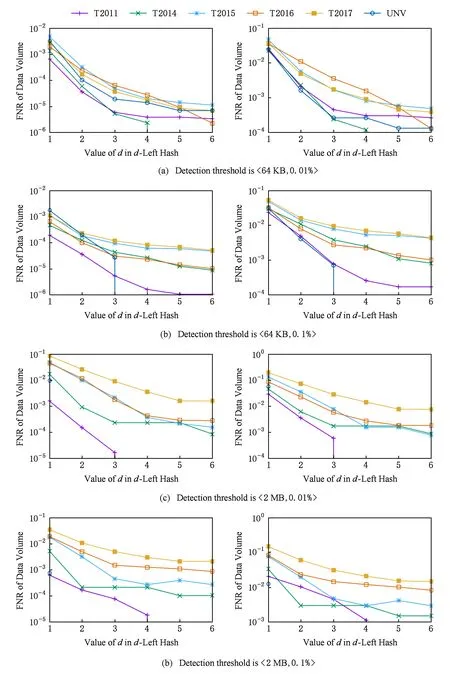
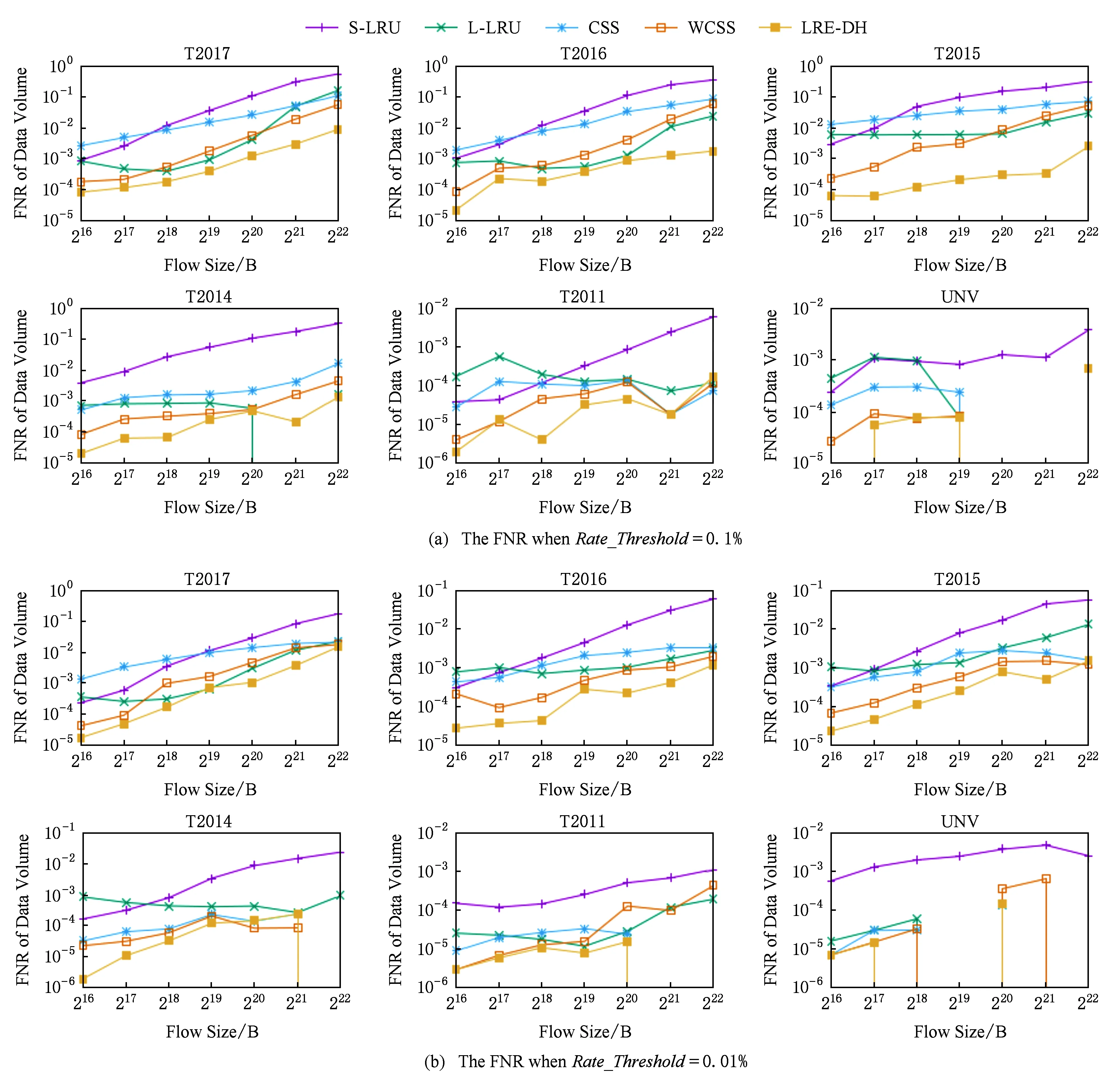
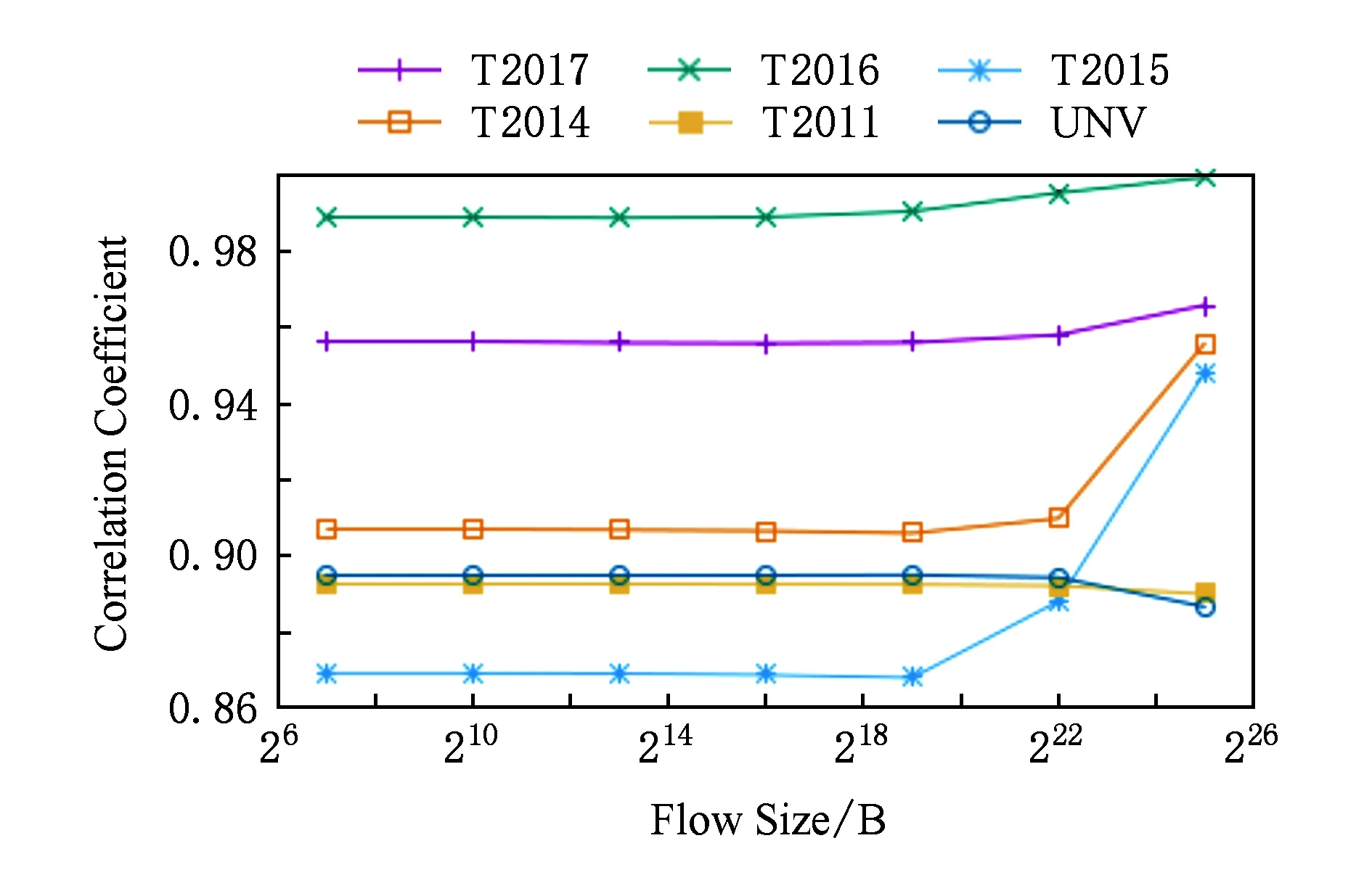
④ While (k ⑤Index[k]=Hash[k](Flow.Id); ⑥ If (在子表k的Index[k]对应的Hash桶中找到Flow对应的条目) ⑦Flow.Size+=Packet.Size; ⑧ If (Flow.Size≥Size_Threshold) ⑩Flow.Rate=CalcFlowRate(Flow); 中国目前执行固定上网电价制度,给予可再生能源一定补贴,但补贴缺口不断在增加,截至2016年年底补贴缺口超过700亿元。随着新增装机规模的进一步扩大,补贴资金缺口将会越来越大。虽然中国暂未实施强制性的可再生能源绿色电力证书交易制度,但是中国在2017年初,发布了《关于试行可再生能源绿色电力证书核发及自愿认购交易制度的通知》,我国已实行绿色电力证书核发和自愿认购,这标志着我国实施绿色电力证书交易制度已进入倒计时。 设d-Left散列各子表Hash桶的数目均为Hd,在插入t×H个元素后,第k个子表恰好包含i个元素的Hash桶的概率为Pk(i),记xk,i=Pk(≥i);根据文献[41]的分析可得出: (1) 取d-Left散列的每个子表的Hash桶只存储一个流条目,则任一条新流被插入到d-Left散列表的概率为 (2) 因此,新流被漏检的概率为 (3) 由于大流一定是高速流,因此大流的数目不超过高速流的数目,大流的条目数漏检率期望值小于等于L. 定理1. 以C表示数据链路的带宽容量,数据流淘汰的速率门限为Cm,则缓存中并发高速流的数目H≤(m-1)[ln(m-1)+ln(S1Pmin)]+2,其中Pmin是最小报文的字节数,S1是流检测结构中创建最早的高速流的字节数. 证明. 流检测结构AF中的n-1个数据流记为fi(1≤i≤n-1),其生存期为Ti(1≤i≤n-1)且Ti>Ti-1(2≤i≤n-1),字节数为Si(1≤i≤n-1),显然Si≥Pmin.若新收到的报文属于已存储在AF中的流,则AF中的流数目不会增加,假设新收到的报文不属于已存储在AF中的流,其大小为Sn,Tn为接收该报文花的时间,记新创建的数据流为fn.设流fn创建后,存储在AF中的流fi(1≤i≤n-1)仍然为活动高速率,则 (4) 成立,由式(4)可得出: (5) 由式(5)可得出式(6)(7): (6) (7) 由式(6)得出: (8) 由式(8)得出: (9) 将式(7)带入式(9)得出: (10) 由式(5)(10)得出: (11) 由式(11)得出: (12) 由于Sn≥Pmin,结合式(12)得出: (13) 由式(13)得出: (14) 当m≫1时,ln[m(m-1)]≈1(m-1),结合式(14)得出: n≤(m-1)[ln(m-1)+ln(S1Pmin)]+2. (15) 证毕. 定理1给出的是最大并发高速流的理论上限,这一上限在下面3个条件同时成立时才能取得.这3个条件是:1)网络设备以线速速率从链路上接收报文;2)数据流按照数据量从大到小的顺序依次创建;3)不同数据流的报文传输过程中不存在交叉.实际上,网络链路不会长时间持续工作在线速速率状态下;而且任何类型的网络链路都会对最小报文的大小有限制;此外链路上不同数据流的报文通常是交替传输的,不存在交叉的概率极低.因此网络中最大并发流的数目通常远小于理论上限. 证明. 一条数据量为V的大流,其报文数Np≈V.由于Hash冲突的存在,新流到达的报文以φ的概率被存储到流检测缓存中;设收到第X个报文,该大流被存储到流检测缓存中;随机变量X服从几何分布,即X~G(φ),φ=1-ε.当大流条目在检测缓存中被创建,其数据量的统计值少于门限值Eth被漏检,即当V-(X-1)×时该大流被漏检,因此当X>1+(V-Eth)时,大流被漏检,漏检概率 (16) 由式(16)得出: (17) 证毕. 由于报文是网络设备收发与处理的基本单位,所以定理2从报文而不是字节数的角度出发分析了大流的漏检率,这一分析的准确性是建立在大流的报文数与字节数线性相关的基础上的.从定理2可以看出:随着大流数据量的增加,任一大流被漏检的概率逐渐降低. 对于大流检测算法的评价需要从存储开销、时间复杂度、准确性等方面综合考虑.在高速网络中,常数级的时间复杂度是对报文处理算法的基本要求.S-LRU,L-LRU,CSS,WCSS等大流检测算法在进行流条目的淘汰或更新上都可以通过常数级的操作实现.在进行报文处理时,频繁的存储器访问是制约报文处理性能的关键因素,因此表2从存储器访问的角度对各算法处理的时间复杂对进行了对比.对于LRE-DH算法而言,无论是执行流条目的统计更新还是缓存替换,最差情形下,需要每个子表都访问一次,即需要d次存储器的访问. Table 2 The Comparison of Detection Algorithm Complexity表2 检测算法基本操作复杂度对比 在满足一定的处理性能和存储开销的前提下,大流检测算法的准确性一直是研究与关注的重点.通常流检测算法的准确性包含漏检率(false negative rate, FNR)与误报率(false positive rate, FPR)2个方面;由于LRE-DH算法的检测门限是同时根据速率和数据量识别活动大流,不存在误报问题,因此我们只对LRE-DH算法的漏检率进行测试与分析.对于流量管理与控制类应用,主要关注的是所检测出大流的总数据流量;因此漏检率的测试包含流条目数的漏检率与数据量的漏检率2个方面;记算法检测出的大流条目数为Nf,网络流量中实际的大流条目数为Nr,则流条目数的漏检率FN=(Nr-Nf)Nr;记算法检出的大流数据量为Vr,网络流量中实际的大流总数据量为Vr,则数据量的漏检率FV=(Vr-Vr)Vr. 为了便于硬件实现,LRE-DH算法采用固定存储空间分配的方案.对于固定存储空间分配,最大并发高速流的数目是其存储空间的分配依据.图2分别给出了15 min各时间段内速率门限为带宽容量1%,0.1%,0.01%,0.001%的最大并发高速流的数目. Fig. 2 Maximum number of concurrent flows under different time and rate threshold图2 不同速率门限下各时间段的最大并发高速流的数目 从第3节中定理1的证明过程可以看出,链路的传输速率、不同字节数的数据流的创建顺序、不同数据流间报文的到达顺序等因素都会影响最大并发高速流的数目.因此图2中不同时刻的最大并发高速流的数目存在很大的变化;T2017,T2016,T2015,T2014的平均传输速率比T2011,UNV高出一个数量级,其最大并发高速流的数目也比T2011,UNV高一个数量级. 图3给出了15 min内最大并发高速流的数目与理论上限的对比,其中最大并发流数目的理论上限是根据定理1计算出的.实际上,网络上不同数据流的报文是交替传输的,当多个高速流轮流传输数据时,通常超过速率门限Cm的并发高速流数目不超过m个. Fig. 3 Maximum number of concurrent flows under different rate threshold图3 不同速率门限下最大并发高速流的数目 根据第2节的网络流量特征分析,选取0.01%和0.1%链路容量作为大流检测的速率门限.使用0.01%作为速率门限时,对于网络流量数据T2014,T2015,T2016,T2017分别分配4 000个流条目空间;对于网络流量T2011,UNV分别分配800个流条目空间.当使用0.1%链路容量作为速率门限时,针对T2014,T2015,T2016,T2017分别分配了400个流条目空间;为T2011,UNV分别分配了120个流条目的存储空间. 通过限制d-Left散列的子表数目,可以确保LRE-DH处理算法最差情形下的处理性能,但这也导致了数据流的漏检,根据3.2节中的理论分析及4.1节中测出的最大并发高速流数目,图4给出了高速流漏检率理论期望值.从图4可以看出随着d-Left散列子表数的增加,高速流漏检率逐渐下降,尤其是在Hash表的负载较轻的情况下,漏检率的下降趋势非常明显. Fig. 4 The theoretical FNR of high rate flows图4 高速流漏检率的理论值 本节通过真实网络数据通过仿真实验测试了d-Left散列的子表数对LRE-DH检测算法漏检率的影响.通常一个数据流至少包含一个满窗口尺寸的数据量时,才值得去进行流量的管理与控制,因此选取64 KB作为一个大流检测的数据量门限值;另外根据第3节的网络流量特征分析,少量的数据流超过了2 MB,因此还选择2 MB作为大流检测的一个数据量门限. 图5给出了在相同存储开销的条件下,随Hash桶容量增加LRE-DH算法流条目数漏检率的变化趋势.通过图4与图5对比可以看出:根据网络数据测试得到的大流漏检率低于高速流漏检率的理论值,尤其是T2017,T2016,T2015的大流漏检率明显低于其理论值,这是因为T2017,T2016,T2015的大部分高速流只含有较少的数据量.从图5可以看出,随Hash桶容量的增加,无论是LRE-DH算法流数目的漏检率还是数据量的漏检率均逐渐降低.其中图5分别给出了检测门限为64 KB,0.01%,64 KB,0.1%,2 MB,0.01%,2 MB,0.1%时流数目与数据量漏检率的变化趋势.从图5可以看出,在Hash桶容量不小于4的情况下,数据量的漏检率均低于0.3%. 定理2对漏检率的分析是建立在大流的报文数与字节数线性相关的基础上的,从图6可以看出大流的报文数与字节数高度线性相关,因此定理2的理论分析具有较高的准确性. Fig. 5 The variation trend of the FNR of identifying algorithm with the increase of Hash capacity图5 检测算法的漏检率随Hash桶容量增加的变化趋势 本节选取了S-LRU,L-LRU,CSS,WCSS等算法与LRE-DH算法在检测的准确性上进行比较.由于LRU派生算法主要依据流的数据量作为评价指标,而未考虑数据流的速率,即LRE-DH与S-LRU,L-LRU,CSS,WCSS算法的检测标准不完全一致,因此只进行大流漏检率的比较.对于LRU及其派生算法,每当报文到达,至少需要4次以上的存储器访问;因此选取子表数为4的LRE-DH算法与S-LRU,L-LRU,CSS,WCSS算法进行漏检率的比较. 使用网络流量数据T2011,T2014,T2015,T2016,T2017,UNV测试了不同数据量门限(64 KB,128 KB,256 KB,512 KB,1 MB,2 MB,4 MB)和速率门限(0.01%,0.1%)组合下的5种算法的漏检率(见图7). 其中图7(a)是速率门限为0.1%的带宽容量下得出的测试结果;图7(b)是速率门限为0.01%的带宽容量下得出的测试结果. 从图7可以看出,LRE-DH算法流数目的漏检率和数据量的漏检率比S-LRU,L-LRU,CSS,WCSS等算法要低.S-LRU算法漏检率高的主要原因在于:这类算法主要根据短时期内报文的命中率,而不是数据量的字节传输速率进行流的淘汰,同时报文大小并不是一致的,通常报文大小从几十到1 500 B变化,所以在存储空间不大的情形下,即使数据流具有较高的传输速率但单位时间内的报文数相对较低时也会被淘汰,导致漏检;通过采样的方案,可以缓解由于大量突发小流的到达导致的漏检,即S-LRU算法在采样率设置适当的情况下,可以获得较好的准确性,但是采样也会引入新的检测误差;L-LRU使用分级淘汰策略,可以进一步缓解突发小流对检测准确性的干扰,尽量将包含数据量多的流保持在缓存中;所以从总体来看,与S-LRU相比,L-LRU算法具有较高的准确性.受存储空间的限制,CSS算法在淘汰流条目时,会导致统计误差逐步增大,而且流条目的淘汰依据报文的发送频率而不是传输速率,因此会存在一定的误差.WCSS算法通过窗口机制可以在一定程度上缓解CSS算法由于流条目的淘汰导致误差的累计,但窗口的截断机制也引入了新的误差.而基于速率的淘汰机制可以有效抑制突发小流的干扰,将低速率的数据流及时从缓存中淘汰,因此LRE-DH算法相比上述算法具有较高的准确性. Fig. 7 FNR comparison of different algorithms under different Rate_Threshold图7 不同检测门限下5种算法漏检率的对比 Fig. 6 The correlation between the packets number and the bytes number in flows图6 数据流的报文数与字节数的相关性 针对高速网络中以流量管理与控制为主要目标的大流检测,提出了低速流淘汰与d-Left散列相结合的大流检测算法(LRE-DH).通过适当配置d-Left散列子表的数目,确保了LRE-DH检测算法的准确性及最差情形下的处理能力.对所提出LRE-DH算法的存储开销、性能及准确性进行了理论分析;使用实际网络流量数据测试结果表明:在相同存储开销下,随着d-Left散列子表数目的增加,LRE-DH算法的漏检率逐渐降低;在相似的性能及存储开销条件下,LRE-DH算法的准确性优于S-LRU,L-LRU,CSS,WCSS算法.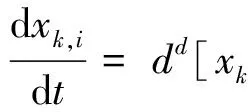
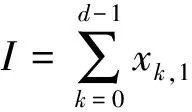
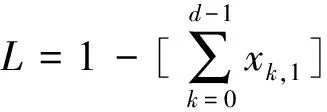
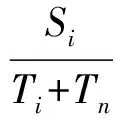

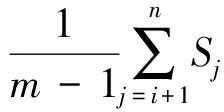
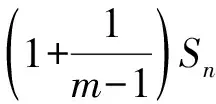

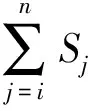
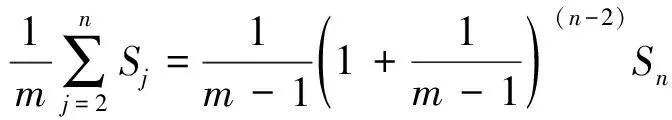
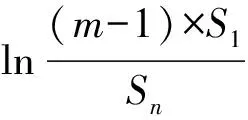
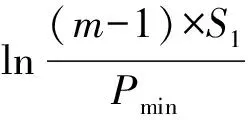
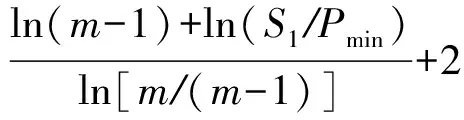

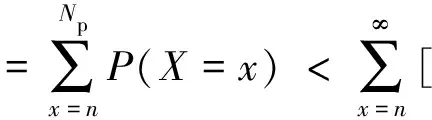
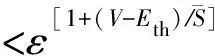
4 实验与评价

4.1 最大并发高速流的数目

4.2 d-Left散列子表数对LRE-DH算法准确性的影响
4.3 LRE-DH与其他算法检测准确性的比较
5 小 结
