移动端人脸图像无参考质量快速评估方法
2019-02-15何长婷
何长婷,朱 明
(中国科学技术大学 信息科学技术学院,合肥 230000)
1 引 言
本文提出了一种移动端人脸图像无参考质量评估方法,其目的是在移动端进行人脸识别的过程中提高识别准确率.利用移动设备采集人脸图像进行识别的过程中,由于光线,噪声等因素的影响,不可避免的会造成图像失真导致质量下降[1].虽然基于深度学习的人脸识别方法如DeepId[2]、FaceNet[3]等方法在包含多种质量的人脸数据集上通过端到端的学习一定程度上克服了光照、姿态等因素的影响,但对于严重失真的人脸图像仍然无法正确识别.尤其对于移动端人脸识别,由于硬件条件的限制,基于深度学习的人脸识别方法在移动端无法取得理想中的效果.因此目前在移动端多采用传统的人脸识别方法进行识别,而传统的人脸识别方法容易受光照、姿态等变量的影响.因此在识别之前进行质量评估,并根据评估结果,进行一些预处理操作,比如去噪,光照处理等操作获得较清晰的图像,能够获得更加可靠的识别结果.
近年来,图像质量评估这一研究领域受到广泛的关注,通常可分为主观评价和客观评价两种方法[4].主观评价是指通过观察者人眼观测,得到对图像质量的评估值.虽然这种方式获得的评估结果是最准确和最可靠的,但是由于工作量大,耗时久,通常不予采用.客观评价方法是指由计算机根据给定的算法通过计算获得图像的质量评估结果.评价时,根据是否需要参考图像可以分为全参考(Full-Reference)、半参考(Reduced-Reference)以及无参考(No-Reference)三种方法.全参考方法(FR)[5]在评价失真图像时,需要提供一个无失真的图像进行参考,通过将两种图像进行比对,获得最终的评价结果.通常可以采用信噪比(SNR)、均方差(MSE)等指标表示.研究表明这种方法能够取得较高的准确率,但缺点是在使用时需要提供无失真的参考图像,这在实际应用中很难满足.半参考方法(RR)不需要将失真图像和参考图像进行比较,而只需要将失真图像的某些特征与参考图像的相同特征进行比较,如小波变换系数的概率分布等.无参考方法(NR)又称为盲图像质量(BIQ),不需要提供参考图像,而是根据失真图像的自身特征来评估图像的质量,代表算法有DIIVINE[6]、BRISQUE[7]和CORNIA[8]等.在实际评估中,获取到无失真的参考图像是非常困难的,因此无参考评估方法具有最重要的应用价值,同时也是更加困难的研究方向,目前是图像质量评估的重要研究领域.
上述提到的质量评估方法均是针对一般图像提出的而非人脸图像,因此对人脸图像评估时存在一定的误差.目前,针对人脸图像质量评估的相关研究较少.Sang[9]等人针对模糊的人脸图像提出一种将图像变换到频率域的方法进行模糊人脸评估.李月龙等[10]根据眉毛、嘴、眉毛、鼻子这几个关键点评估人脸是否模糊.这些人脸图像评估方法均是针对单一失真提出的,并没有考虑到其他的失真类型.因此在实际应用中存在很大的局限性.本文提出的人脸图像质量评估方法相比于传统质量评估方法,主要特点如下:
1)本文针对人脸图像的质量评估提出了基于深度学习的评估算法,目前针对人脸图像利用深度学习进行质量评估的方法研究并不多.
2)其次一点贡献在于本文提出的方法是快速质量评估,能够达到实时性的要求,同时CPU占有率低.由于本文的算法运行在移动端,因此评估速度是最大的挑战.
实验发现,在实际场景中最常见的人脸图像失真类型主要是由运动引起的运动模糊,由光照过暗而引起的昏暗图像,由于口罩、墨镜等物件引起的人脸面部遮挡以及由于身体摆动引起的姿态不正.本文主要针对这几类失真类型进行评估,并将本文提出的算法与现有的优异模型DIIVINE和BRISQUE进行比较,实验结果证明了本文算法的优越性,具体实验将在下文介绍.
2 方法介绍
本文提出了一种基于深度学习的移动端人脸图像质量评估算法.算法分为两个阶段,首先构建训练数据集,并对数据集中的数据进行预处理操作,之后用构建的数据集对轻量级网络模型MobileNet进行训练,然后利用训练好的网络对人脸图像进行实时准确的评估.
2.1 图像预处理
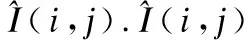
(1)

(2)
(3)
其中C是不能被零整除的正常数.P和Q是归一化窗口的大小.在文献[7]中,证明了较小的归一化窗口能提高实验性能.本文选择归一化窗口大小为P=Q=3,窗口大小比输入图像块小得多.请注意,通过这种局部归一化,每个像素可能具有不同的局部均值和方差.局部归一化是非常重要的,如果使用的窗口过大可能会导致不好的效果.值得一提的是,当用深度学习进行物体识别的时候,通常对整张图片进行一个全局归一化,归一化不仅缓解了早期使用sigmoid神经元时常见的饱和问题,而且使网络对光照和对比度变化具有鲁棒性.在质量评估问题上对比度归一化是局部的.
2.2 网络结构
本文训练的模型最终将应用于移动端,由于移动端硬件条件的限制,如果采用VGG[11],Inception[12]等模型进行训练,所获得的模型很大,评估一张图片可能需要几十秒甚至更多,在实际应用中无法满足对速度实时的要求.因此在选择网络模型的时候,本文选择了在速度和模型大小都做了优化的MobileNet[13]作为基础网络模型,并用自己的数据集利用迁移学习进行再训练调优.
MobileNet是2017年谷歌提出的专门应用于移动端的轻量级神经网络,在提高处理速度的同时,保持精度不变.MobileNet采用了深度可分离卷积(depthwise separatable convolution) 的思想.和标准卷积不同的是,深度可分离卷积在进行卷积的时候并不对通道进行融合,而是采用先逐通道卷积然后利用1×1卷积核进行点卷积的方法来分步卷积,这种方式能够大大降低计算量.标准卷积和深度可分离卷积的卷积过程如图1所示.

图1 (a)图是标准卷积在MobileNet中被(b)和(c)中的逐通道卷积和点卷积所替代Fig.1 Standard convolutional filters in (a) are replaced by two layers: depthwise convolution in (b) and pointwise convolution in (c) to build a depthwise separable filter
标准卷积是用DK×DK×M×N大小的卷积核对DF×DF×M的输入进行卷积,假设步长为1,将产生一个DK×DK×N大小的输出特征图.其中DF×DF是输入图像以及输出特征图的大小,DK×DK是卷积核的大小,M是输入通道数,N则是输出通道数.分析可知标准卷积的计算量为:
DK·DK·M·N·DF·DF
(4)
逐通道卷积时使用一个DK×DK×1的卷积核对每个输入通道进行分别卷积,特征数量保持不变.1×1点卷积则使用一个1×1×M×N卷积核,将M个输入特征变为N个输出特征.深度可分离卷积方法的计算量为:
DK·DK·M·DF·DF+M·N·DF·DF
(5)
两种卷积方式的计算量比较如下式:
(6)
通过式(6)可看出,MobileNet用这种分离卷积的方式,大大降低了计算量,通常可以降低8~9倍.由这两种卷积方式构成的卷积单元结构如图2所示.
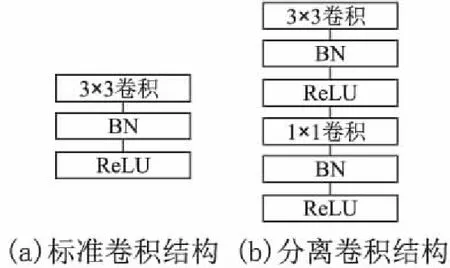
图2 标准卷积结构(左)及分离卷积结构(右)Fig.2 Standard convolutional structure (left) and discrete convolutional structure (right)
为了进一步降低模型的计算量,MobileNet引入了两个超参数,宽度乘法器α和辨率乘法器ρ.超参数的选择不同,MobileNet模型的计算量和精度也不同.超参数α的作用是对网络的每一层进行压缩,对于给定的超参数α,将M通道的输入压缩为αM的输入,将N通道的输出压缩为αN的输出.使用超参数 后的卷积计算量为:
DK·DK·αM·DF·DF+αM·αN·DF·DF
(7)
其中α∈(0,1),常见取值有0.25、0.5、0.75、1.当α=1时是基础MobileNet网络,当 的时候为压缩MobileNet网络.
第二个超参数为分辨率乘法器ρ,ρ的作用是通过降低图像的分辨率来降低模型的参数.当对模型设置了宽度乘法器α和分辨率乘法器ρ时,模型的卷积计算量为:
DK·DK·αM·ρDF·ρDF+αM·αN·ρDF·ρDF
(8)
其中ρ∈(0,1),通常通过设置模型的输入分辨率来间接的设置参数ρ,常见输入分辨率的取值有224、192、160、128.本文在后面的实验中选择了不同的超参数组合,对这两个参数的压缩作用进行验证.
2.3 网络训练过程
在实际训练网络中,很少有人选择从头开始训练一个网络,因为很难获得一个足够大的数据集.而且从头开始训练模型往往需要几天或是几周的时间,这取决于训练机器的硬件条件.相反的,如果选择一个已经在足够大的数据集(比如:ILSVRC-2012-CLS)预训练过的模型,并用自己的数据重新训练,这往往只需要几个小时,这种方式通常被称之为迁移学习[14].本文中,我们利用迁移学习的概念使用自建的数据集对预训练的MobileNet网络模型重新训练,实现在移动端快速的对人脸图像进行质量评估.
在利用迁移学习重新训练时,将预训练MobileNet网络的最后一层softmax层更改为自己需要的分类器,然后对更改的softmax层进行训练.除开最后一层,其他层的参数全部固化,无法更新.因此,本文在实验时,先将数据集(包含训练集、验证集与测试集)中的所有图片导入到MobileNet模型中,获取最后一层的输入,也即是倒数第二层的输出,定义为瓶颈层(Bottlenecks).然后直接使用瓶颈层对最后更改的softmax层进行训练,将大幅度提升模型的训练速度.瓶颈层为最后的输出层前面一层,即整个模型的倒数第二层.瓶颈层将产生有效的数据供给最后的决策层做出最后的分类预测.
3 实 验
本文主要关注四种失真类型分别是运动模糊(指由于运动引起的模糊)、昏暗图像(指由于光线条件较差导致的昏暗图像)、姿态不正(指严重侧脸、低头的图像)、遮挡问题(指由墨镜、面具、口罩等物件大面积遮挡面部的图像),这些都是在实际场景下最常出现的失真类型.
由于目前针对人脸图像质量评估还没有公开的权威数据集,所以本文建立了自己的数据集进行实验.在实际应用中,有时候对于图像的评估结果只需知道是合格或不合格两种结果.而对于一些情况,除了知道图像合格或不合格以外,还需知道图像质量不合格的具体原因是什么,以便做出一些改进,比如调节光照,摆正姿态等.因此本文设置了三组实验来验证算法的有效性.同时为了验证本文提出算法在移动端的有效性,我们在实验四中将本文的算法和其他优秀的算法进行了比较.
3.1 数据集
现存的针对图像质量评估存在的数据集有LIVE、TID2008[15]、CSIQ、IVC.但是针对人脸图像质量评估还没有公开的权威数据集,因此本文采用自制数据集的形式进行实验.数据集中包括6000张正样本(清晰的正脸图像),12000张负样本(包括3000张运动模糊的人脸图像,3000张昏暗人脸图像,3000张姿态不正人脸图像,以及3000张遮挡人脸图像.)

图3 无失真和失真人脸图像示例图Fig.3 Samples of undistorted face image and distorted face image
为了获取所需要的正样本人脸图像,本文利用CASIA-WebFace人脸数据集作为基础数据集,从中选择8000张图像,由于CASIA-WebFace中的人脸图像并不都是高质量的,因此再通过人工筛选出6000张作为正样本,部分正样本如图3中第1行所示.
为获得姿态不正的人脸图像,同样选择CASIA-WebFace数据集作为基础数据集,从中选择3000张人脸姿态不正的图像,包括低头、侧脸等.获得样本图像如图3中第2行所示.
遮挡人脸图像的获得,由于没有公开数据集,基础数据集中也只有少量数据,因此本文选择从网络上获取.首先在谷歌和百度两个搜索引擎根据关键字进行爬取,再通过人脸检测器进行人脸检测去除部分背景获得图像.由于人脸检测存在一些误差,因此通过手工提纯获得最终的样本.获得的部分样本如图3中第三行所示,图中展示了戴口罩、墨镜以及同时戴墨镜和口罩的人脸图像.
为了获得运动模糊和昏暗人脸图像,由于没有公开的数据集,同时网络上也难以搜集此类失真的人脸图像,因此本文仿照LIVE数据集构建负样本的形式,通过在正样本上添加合成失真以获得相应的负样本.
运动模糊,是指在拍摄设备快门打开的时间内,物体在成像平面上的投影发生平移或旋转,使接受的影像发生重叠.为了便于用数学语言描述运动模糊图像的产生,现规定如下:图像的左上角为坐标原点(0,0),图像的长度方向为x轴,宽度方向为y轴,整个图像落在第一象限.假设无任何模糊和噪声的真实图像为f(x,y),模糊图像为g(x,y).由于运动模糊是由图像彼此重叠造成的,所以有下式成立:
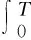
(9)
其中,Cx为图像在方向上的平移速度,Cy为在方向上的平移速度,T为快门打开时间即产生模糊图像的时间,n(x,y)为加性噪声.为了简化计算过程,假设只有运动模糊而没有任何加性噪声,而且产生模糊的运动是沿x方向的.根据上述过程,模拟运动模糊的过程,实验结果图3中第四行所示.由实验结果可以看出,上述过程基本可以完美的模拟现实中真实的运动模糊,获得相应的样本图像.
为了收集由光照影响引起图像过暗的负样本,本文通过降低图像像素值的方法获得相应的样本数据.同时为了丰富样本的多样性,从数据集CASIA-WebFace人工筛选了部分图像作为补充样本.最终获得的图像如图3中第5行所示,图中前3张为补充样本,后两张为通过降低图像的像素值模拟得到的昏暗人脸图像.
3.2 实验1:针对单一失真类型的人脸图像
在某些情况下,我们只关注某些特定的失真类型.判断出特定失真类型后,对失真图像进行相应处理,比如针对模糊失真,当判断出属于此类失真类型后,可以进行去噪处理获得清晰的图像.
由于运动模糊是实际应用中最常见的失真类型,故此处以运动模糊为例,用运动模糊的图像和清晰的图像作为正负样本进行训练,从而区分出清晰的和模糊的人脸图像.
MobileNet因超参数选择的不同,模型的大小和效果也不同.比如MobileNet-v1-1.0-224,这里"1.0"对应着前文所说的超参数α,"224"对应超参数ρ.本实验选择几种具有代表性的模型进行实验,对前文提到的两个超参数α和ρ的功能进行验证.同时为了更好的证明模型的优越性,实验中利用Inception模型作为对比.由于实验1、实验2和实验3均选择了相同的几种模型,模型的复杂度相同,故将在实验4对模型的时间性能和CPU占有率进行分析.
本实验用3000张正样本和3000张负样本, 迭代6000次得到的实验结果整理如表1所示.
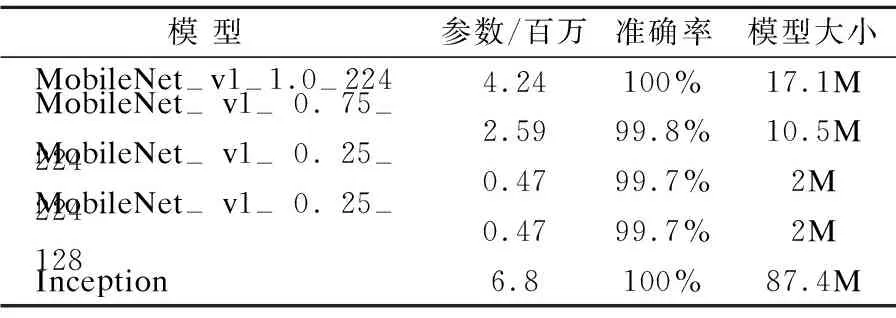
表1 针对运动模糊失真不同模型下的实验结果Table 1 Experimental results of motion blurred face images under different models
从表1中的实验结果可以看出,当简单的将人脸图像分为运动模糊和清晰的两类时,采用基础模型MobileNet-v1-1.0-224可以取得100%的准确率.当使用不同超参数进行压缩时,可以发现随着参数α的降低,模型的准确率略有降低,但模型的参数量在降低,模型的大小也大大减小.而参数ρ的改变对模型的大小和准确率,影响并不大.作为对比的Inception模型虽然也能取得100%的准确率,但是其模型最大,参数最多,不适用于移动端.正如前文所说MobileNet模型可以在保证精度基本不变的情况下,降低模型大小.
3.3 实验2:针对所有失真类型的人脸图像
在某些情况下,不仅仅针对某一单一失真,而是需要考虑所有可能的失真类型,对人脸图像进行全面综合的评估.因此本实验将所有失真类型的人脸图像作为负样本,和清晰的人脸图像一起训练,将图像分为合格或不合格两类.
本实验用全部6000张正样本和6000张负样本(包括2000张运动模糊人脸图像,2000张昏暗人脸图像以及2000张遮挡图像),在不同的模型下进行实验,实验结果如表2所示.
由表2中显示的实验结果可知,采用基础模型MobileNet-v1-1.0-224可以取得97.3%的准确率,利用超参数进行压缩时,模型准确率略有降低,模型大小大大减小.压缩程度最大的模型MobileNet-v1-0.25-128的准确率达到95.8%,而Inception模型却只能取得94.1%的准确率.
3.4 实验3:针对具体失真类型的人脸图像
在实际应用中有时候不仅仅需要知道图像质量是合格还是不合格,还要知道图像的具体失真类型,以进行后续的图像预处理或者及时调整环境.
本实验以生活中最常见的几种失真类型,运动模糊、昏暗、姿态不正、遮挡面部为例进行具体分类.从清晰图像中选取3000张图片作为正样本,从负样本中选择运动模糊、光线不良、姿态不正、面部遮挡各3000张图片进行实验.
由表3中的结果可知,基础模型MobileNet-v1-1.0-224可以取得最高的准确率97.2%,当采用超参数进行压缩时,模型的准确率有不同程度的降低.压缩程度最大的模型MobileNet-v1-0.25-128可以取得94.5%的准确率,复杂度最高的模型Inception能达到95.4%的准确率.
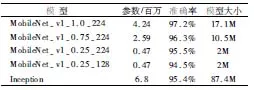
表3 针对具体失真类型不同模型下的实验结果Table 3 Experimental results of specific damaged face images under different models
3.5 实验4:算法性能比较与复杂度分析
为了说明本文算法的优异性,本实验将本文算法和现有的优秀算法DIIVINE和BRISQUE进行比较,主要从评估结果和时间性能两个方面进行比较.
由于本文算法是针对移动端质量评估提出的,因此本实验选择在华为荣耀畅玩4C手机(运行内存2GB,机身内存8GB)对本文算法进行验证.DIIVINE和BRISQUE算法由于目前没有移动端的实现方式,因此在内存为8GB操作系统为64位的WINDOWS7电脑,利用MATLAB R2014a实现.通过对图4中的三张人脸图像进行质量评估来进行准确性的比较.

(a) (b) (c)图4 测试图像示例Fig.4 Samples of test images
图4(a)图为无失真人脸图像,分辨率大小182×182,图4(b)和图4(c)是模糊和姿态不正的失真人脸图像,图像分辨率大小分别为156×156和250×250.本实验选择在实验2中训练得到的不同模型对图4中的图像进行评估.评估得到的实验结果如表4所示,表中展示了不同模型评估得到的评估结果,以及评估一张图像所需的平均时间.
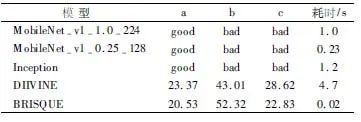
表4 不同模型的评估结果与运行时间的比较Table 4 Comparison of evaluation results and running time of different models
DIIVINE和BRISQUE的评估结果由取值在[0,100]区间内的数值表示,数值越低则表示图像的质量越好,反之数值越高则质量越低.由表4可知,DIIVINE和BRISQUE对人脸图像的评估存在较大的误差,如图4(c)图的人脸图像,属于姿态不正失真类型的人脸图像,而利用上述两种评估方法进行评估时均给出了一个较小的数值,代表当前图像质量较好.本文算法给出的结果为bad,正确的对图像质量进行了评估.因此从准确性来说本文提出的算法更优,接下来进行时间性能的分析.
由表4结果可知,利用MobileNet-v1-0.25-128模型评估一张图片平均需要0.2秒,BRISUQE仅需要0.02秒,虽然本文算法耗时略高于BRISUQE算法,但是本文的算法运行于移动端,而BRISUQE是运行在PC端.同时本文0.2秒的时间也能够满足实时性的要求,远远小于DIIVINE算法以及Inception所需的时间,能够进行快速评估.
本文的算法是针对移动端质量评估提出的,不仅对运行时间有很高的要求,对运行时CPU占有率也有很高的要求.过高的CPU占有率难以满足实际应用的条件.首先选择对基础模型MobileNet-v1-1.0-224进行占有率的测量,测定结果如图5所示.

图5 MobileNet-v1-1.0-224的CPU占有率Fig.5 CPU occupancy of MobileNet-v1-1.0-224
通过图5可以看出,基础模型MobileNet-v1-1.0-224的CPU占有率的为40到50%,峰值可以达到60%,是一个较高的占有率.接着对压缩的模型MobileNet-v1-0.25-128进行CPU占有率进行实验测量,结果如图6所示.

图6 MobileNet-v1-0.25-128的CPU占有率Fig.6 CPU occupancy of MobileNet-v1-0.25-128
通过结果可以看出,手机CPU占有率的占用大概为20%到25%,可以看出压缩的模型具有较小的占有率.同时,由于本文选择的实验手机配置属于一个较低配置,在较高配置的手机上应该能够取得更加小的CPU占有率.
由以上实验对比和分析可知,本文提出的算法可以在移动端准确快速的对人脸图像进行质量评估.
4 结 论
本文提出了一种基于深度学习的移动端人脸图像质量评估算法,旨在提高移动端人脸识别的准确率.现有的质量评估算法,均不是针对人脸图像提出,对人脸图像评估无法取得理想中的效果.针对这种问题本文提出了专门针对人脸图像的实时评估算法,实验证明本文提出的算法可以取得优异的实验效果,可以在保持高精度的情况下,保证实时性和低CPU占有率的要求,具有重要的应用价值.
