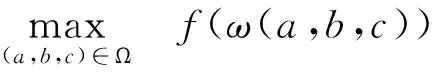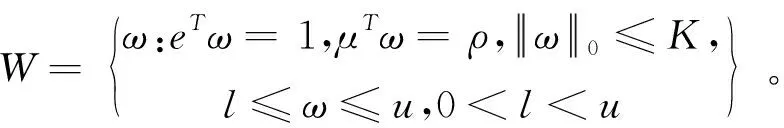一类稀疏投资组合双层参数估计模型及其应用
2019-02-14徐凤敏
徐凤敏,景 奎,梁 循
(1.西安交通大学经济与金融学院, 陕西 西安 710061; 2.中国人民大学信息学院, 北京 100872)
1 引言
投资组合的参数估计是现代金融研究领域中的一个热点问题[1-3]。Markowitz于1952年提出的均值-方差模型[4]是现代投资组合理论的基石。该模型旨在给定风险水平下最大化预期收益或给定收益水平下最小化投资风险,已经在投资组合资产选择和配置当中得到了广泛的应用。
根据风险度量方式以及真实市场条件的不同,经典的均值-方差模型发展出了很多拓展形式。其中一个重要的方面是将基数约束纳入考虑,因为实际投资组合中资产数量是存在限制的[5-6]。这一改进能够减轻投资者的管理负担,降低交易费用。Chang等[7]最早建立了带基数约束的均值-方差模型。由于带基数约束的投资组合优化问题是混合整数二次规划问题,容易证明此问题是NP难的[8]。针对基约束下的投资组合问题的研究主要集中在两个方面,一是采用放松约束条件或者目标函数来逼近原问题从而得到解析解,二是采用启发式算法求解基数约束问题。
对带基约束的投资组合模型涉及的参数进行有效的估计能够使该模型更好地为投资者决策发挥积极的指导作用。Best和Grauer[9]发现由样本得到的最优投资组合对风险资产收益率的变化非常敏感。Broadie[10]指出参数的估计误差对最优投资组合有明显的影响且会促使各风险资产的投资比例产生极端结果。由此可见,最优投资组合的有效性与参数的选择有着紧密的联系。
为了给出市场参数更有效的估计,尽量减轻估计误差的影响,学者们进行了不懈地探索,逐步发展出以下两种策略:用统计方法取代样本方法重新估计市场参数;优化构造出的参数集(例如扰动集或优化问题的最优解集合)。对市场参数的统计重估方法可以被分为三类。第一类是结构因子模型,即CAPM[11]、FF3[12]、BARRA[13]和ATP[14]方法。第二类是贝叶斯收缩估计,这类方法可进一步分为考虑投资者的先验信息与否两种。对于前者,BL模型[15-16]是最受欢迎的方法之一,如Lejeune[17]给出了考虑VaR和交易约束的FOF基金选择问题的VaR BL模型,然后设计了一种特殊的分支定界算法来构造最优FOF基金。对于后者,Ledoit和 Wolf[18-19]提出了一种变形的股票协方差矩阵收缩估计方法,这种方法可以估计样本协方差矩阵和单指数协方差矩阵之间的最优加权平均。最后一类是分层抽样[20-21]和时间序列聚类[22-23]。如Wang Meihua等[24]提出了一种新的投资组合策略:这种策略结合了已有抽样策略和用于求解指数追踪问题中混合整数规划模型的优化抽样策略。Focardi 和Fabozzi[22]引入了距离函数的概念,并提出了利用时间序列聚类来识别具有相似行为的资产。Dose和Cincotti[23]将时间序列聚类方法应用于指数跟踪中,发现聚类方法提高了噪声抑制能力,且与随机选择技术相比,在鲁棒预测应用中有更好的效果。
参数集合的优化方法分为两类。一类是在设计的扰动集上进行优化,在数学上称为鲁棒优化[25-26]。它已被广泛地应用于现代投资组合中,以系统地对抗最优投资组合对相关市场参数估计中统计和建模误差的敏感性[27]。如对一个鲁棒最优资产分配问题,Lobo 和 Boyd[28]在考虑资产收益率均值和协方差的不确定性的情况下,对组合的最坏情况风险进行建模,并提出一种比蒙特卡罗方法更精确、更快的内点方法。Tutuncu和 Koenig[29]针对资产收益率结构不可靠情况下的基金稳健优化配置问题,提出了保守策略,并构造了最优最坏情况资产组合。Garlappi等[30]通过最大似然估计将MV 投资组合模型扩展到多阶段,以明确地考虑预期收益估计的不确定性。另一个是对参数优化问题的最优解集进行优化,称为双层规划(BLP)。相应的求解方法有三种。一种是通过最优条件将内层规划转换为均衡约束[31],另一种是利用内层规划的值函数设计迭代算法[32],最后一种是通过构建内外层规划的可行方向集进行直接搜索[33]。如Chen Xiaojun[34]针对双层组合管理模型,提出了一种平滑直接搜索算法,其中内层为经典MV模型,外层为夏普比率最大化。他们精确地求解了投资组合权重和风险厌恶因子的最优上界和下界,或者得到了它们的紧致范围。
传统的投资组合模型中参数主要包括各个风险资产的预期收益率以及这些预期收益率之间的协方差矩阵等,通常根据历史数据对这些参数的值进行估计。Merton[35]于1980年指出预测各风险资产的收益率的均值比预测这些收益率的协方差更加困难,同时他还指出均值的估计误差比协方差矩阵的估计误差对投资组合的影响要大得多。1993年Chopra和Ziemba[36]的研究表明预期收益率均值的估计误差对最优投资组合的影响要比协方差矩阵估算误差的影响要大数倍。因此,对稀疏投资组合模型的预期收益率进行科学的估计是参数估计的重点。
与传统的投资组合选择模型不同,带基约束的投资组合问题还有一个特有的参数,即投资组合的规模,通常用稀疏度表示。虽然带基约束的投资组合问题在求解方面取得了很多进展,但是对稀疏度的最优选择问题,研究还十分匮乏。许启发等[37]使用LASSO分位数回归方法(1范数)对带有范数约束的CVaR高维投资组合进行求解,并建立了SIC准则与GS准则对最优的约束参数进行了估计。因为Zhao Zhihua等[38]发现当使用p(p∈[0,1])范数对投资组合的稀疏性进行刻画时,随着p的减小,投资组合模型的稀疏性增强,即0范数对最优稀疏约束的刻画更为精准。因此本文在对控制标的资产的数目时采用了更有优势的0范数。
本文基于带基约束的投资组合模型,从一个全新的视角出发,对该模型的预期收益率和稀疏度进行了估计。在带基约束的均值-方差模型的基础上,以投资组合效用(用夏普比率度量)极大化为外层目标,内层极小化投资组合的风险,以0范数控制投资组合中的资产数量,并利用上下界约束控制各项资产的权重,建立了双层参数估计模型;其次分析了该模型的收益率以及投资组合的稀疏度选取范围,并结合无导数优化方法设计了基于ADMM的双层参数估计算法;在实证部分,我们对投资组合预期收益率以及稀疏度进行了数值分析。仿真结果表明,本文模型得到的参数估计结果更符合实际,对投资活动有指导意义。
2 稀疏度的影响分析
考虑一个由6支股票的6期收益率组成的收益率矩阵(如表1所示),在此矩阵中,不同股票的收益率是高度相关的。表2列出了分别由MV模型和稀疏MV模型求解得到的最优解。从表2可以看出,稀疏MV模型只投资其中两支股票就可以达到MV模型投资6支股票所取得的夏普比率,这个结果说明对于中小投资者而言,关注相对少量的投资标的而不影响组合的整体回报是可能的,同时,也可以节约交易费用。
下面通过一个数值算例来阐述我们研究的动机,即为何要对稀疏投资组合模型的稀疏度进行选择。图1是OR-Library中五个标准数据集[39]的稀疏度-夏普比率曲线,图中折线的折点表示在稀疏度取相邻的五个整数时,夏普比率的平均值。由图1易知,稀疏投资组合的夏普比率并不随稀疏度单调地进行变化,因此,研究稀疏度的最优选择问题是十分有价值的。
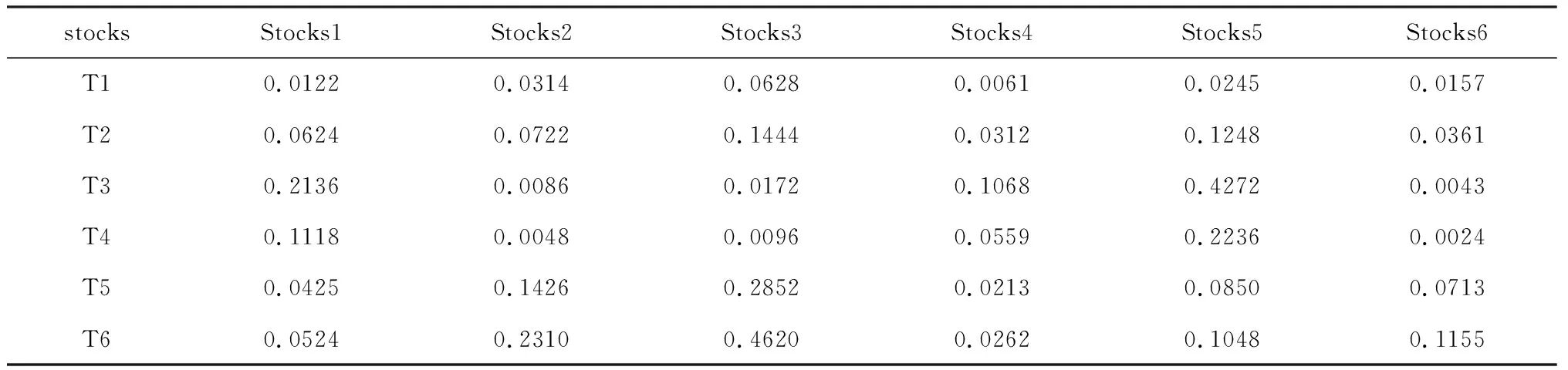
表1 股票收益率矩阵

表2 最优投资比例
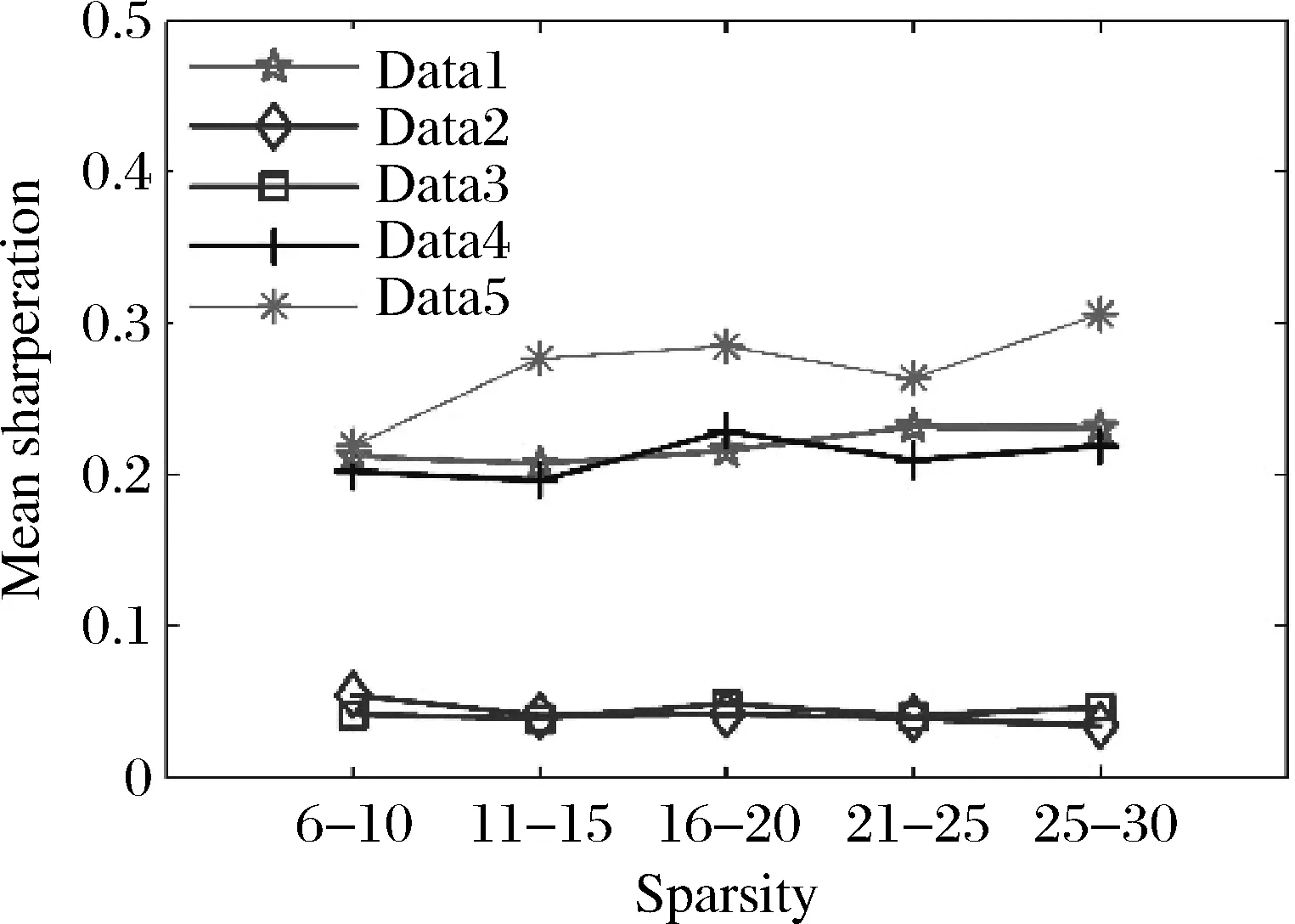
图1 稀疏度-夏普比率图线
3 建立模型
3.1 经典的MV模型
Markowitz的均值-方差模型[4](MV):
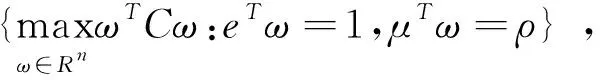
3.2 考虑基约束的MV模型
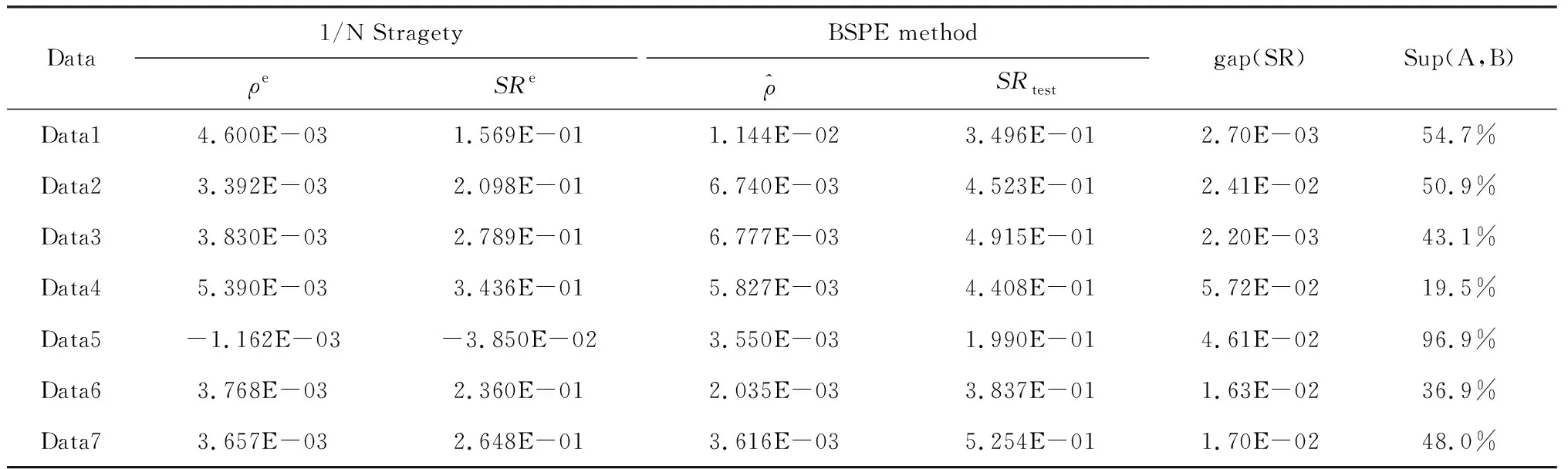
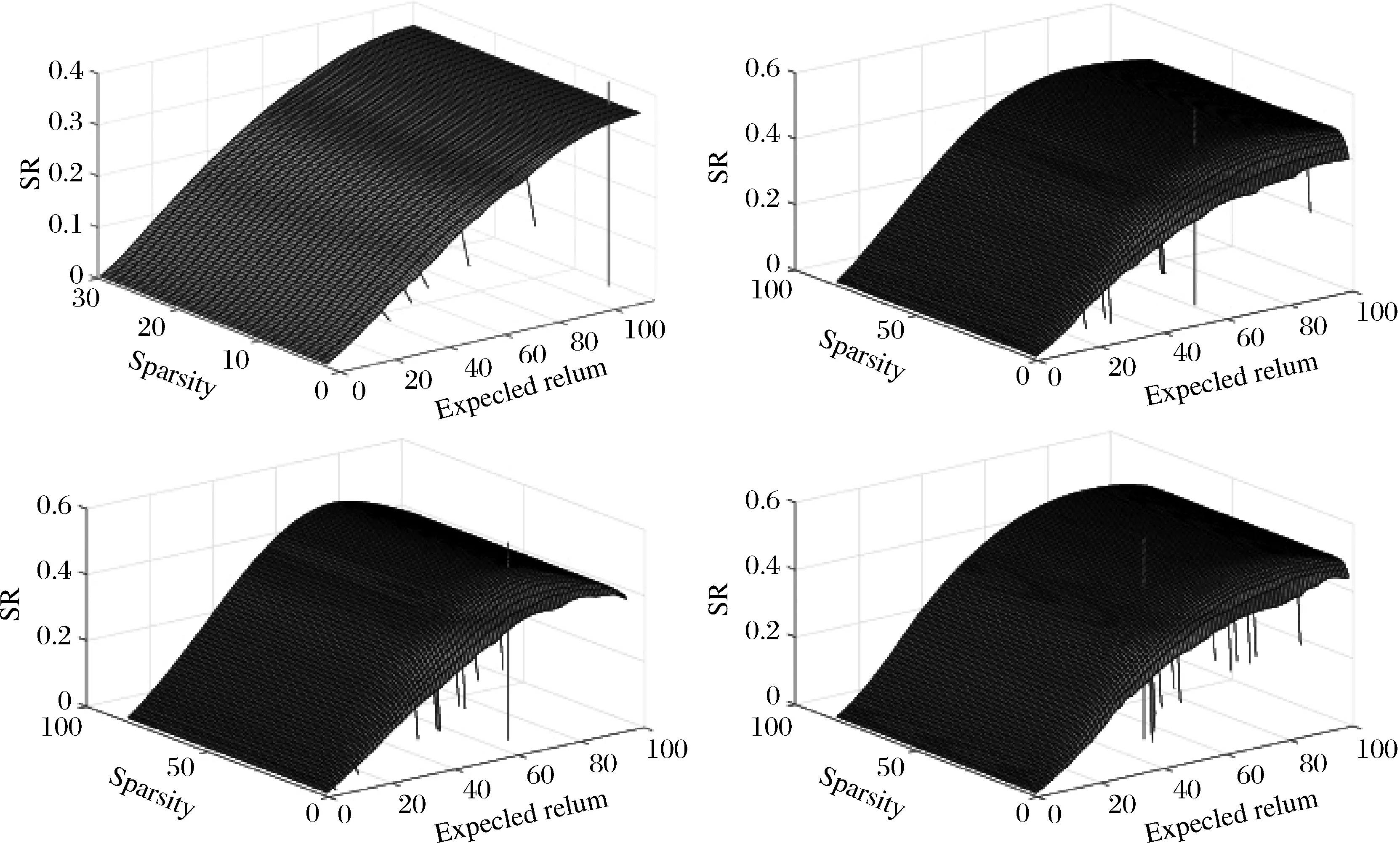
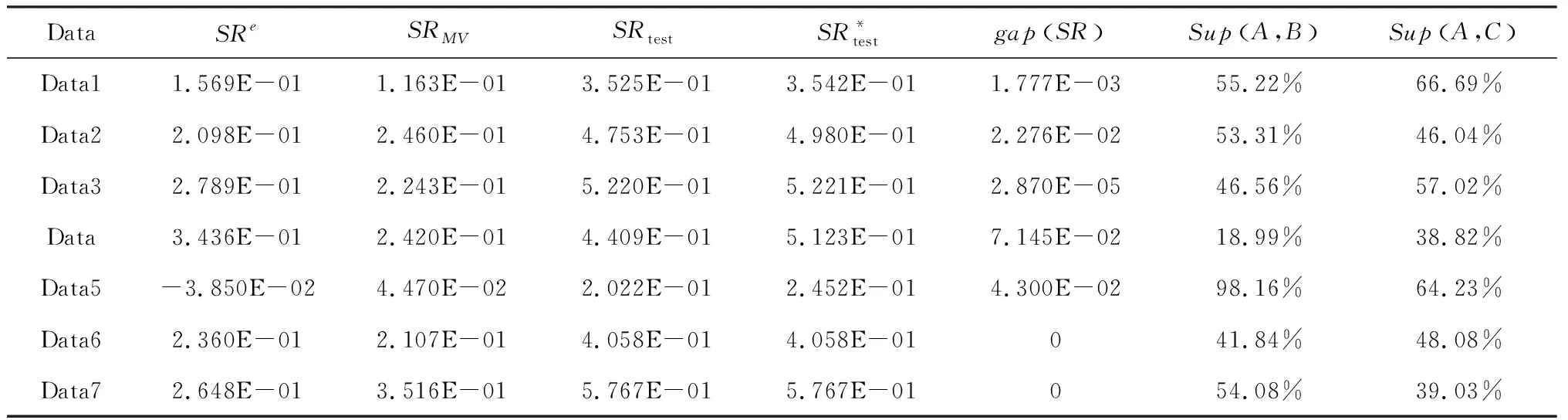
对基约束的刻画主要有两种方法,一种间接控制投资组合中风险资产数目的稀疏优化方法是在目标函数上增加一个关于投资组合权重的惩罚项。Brodie等[40]于2009 提出了基于1范数的稀疏投资组合模型,但是1范数并不能有效地与卖空机制结合,因此Chen等[7]提出了基于p(0 在投资组合问题的研究中,为了同时对存在一定冲突的不同目标进行优化,往往应用双层规划构建模型进行求解。楼振凯[41]构建了应急物流系统LRP的双层规划模型并设计了一种带启发式规则的两阶段混合模拟退火算法对其进行近似求解;李镜儒[42]运用双层规划对投资组合中风险与收益的冲突进行建模,为投资者选择理想的投资方案。夏普比率在投资组合绩效评价领域有着广泛的应用[43],其含义是投资组合每承受一单位总风险,会产生多少的超额回报。根据William Sharpe的工作,夏普比率可以表示为: (1) 本文基于双层规划的思想,建立了带基约束的投资组合双层参数估计模型(SBPE)。 ω(ρ,K)=argminωTCω s.t.ω∈W (2) 模型(2)是一个结合了夏普比率的双层参数估计模型,包含了未知参数ρ和K,我们的目标是选取最优的ρ和K,使得组合的绩效最大。该模型外层目标函数为极大化夏普比率,其自变量为ω(ρ,K),该自变量的可行域由模型的内层决定。由于外层目标是含参的非凸函数,梯度类方法难以施展,求解十分复杂;模型的内层是考虑上下界约束与基数约束的均值-方差模型,其中的投资上界u是给定的非负常数,预期收益率ρ是未知参数,而在给定ρ时,模型的内层则是一个混合整数二次规划问题。含0范数的基约束条件使其成为了NP难问题,很难找到该问题的全局最优解。 模型(2)是一个稀疏约束非光滑非凸优化问题,具体地,其外层目标函数不能直接进行求导运算,故使用无导数优化方法[44]求解,而内层由于含有基约束,使用ADMM[45]对子问题进行求解。 SBPE 直接搜索算法步骤1 选择一个初始点x∈Ω, 步长h和迭代系数alpha;步骤2 计算ω(x)和f(x)的值;步骤3 计算ω(y)的值,其中y=x±hν,ν∈V且y∈Ω并计算fmax;步骤4 当fmax≤fx时,用αh更新迭代步长h;否则, 设x=y*且f(x)=f(y*),其中y*∈y|f(y) =fmax,y=x±hυ,υ∈v且y∈Ω;步骤5 当h≤β时,终止计算, 否则返回步骤3。 ADMM(Alternating Direction Method of Multipliers) 算法是机器学习中使用比较广泛的约束最优化方法,它是增广拉格朗日乘子法的一种延伸,将无约束优化的部分用块坐标下降法分别进行优化,因此可以有效地对模型(2)的内层进行求解。首先我们引入中间变量τ和约束条件ω=τ将模型(2)的内层转化成如下形式: minωTCω s.t.Aω=b, l≤ω≤u, ω=τ. (3) 其中A=[μ;e]T,b=[ρ;1]T。利用增广拉格朗日函数,则模型(3)可转化为: (4) 其中λ是关于约束条件ω=τ的拉格朗日乘子,φ是惩罚因子。模型(4)可以分成两个子问题,第一个子问题是关于变量τ的约束优化问题,另一个则是关于变量ω的无约束优化问题。我们用L(τ,ω,λ,φ)来表示模型(4)的目标函数,用Δ表示模型(4)中关于变量τ的可行域,通过分别对两个子问题进行求解并更新拉格朗日乘子,得到ADMM算法框架如下: (5) 设定ε1>0,φ>0,U>0,ζ>0,并有初始值ω0,λ0,σ0,我们用k代表算法迭代次数,则算法的第k+1次迭代过程为: 研究发现A会计师事务所在合并之后CPA的人数不断增长,员工的专业水平和独立性都有了提高,事务所的业务收入综合排名都有提升,非标审计意见的数量也有所增加,表明审计质量有所提高,但是审计质量提高的幅度较小,事务所的合并对审计质量的影响还不是很显著,非标审计意见比例这个指标体现得最为明显。但由于选取的衡量指标较少,数据样本的有限,可能结论会有一定的局限性。 1.求解τk+1,即求解下列方程: (6) 转步2; 2.求解ωk+1,即求解下列方程: (7) 转步3; 3.更新拉格朗日乘子λk+1: λk+1=λk+φ(ωk+1-τk+1) (8) 转步4; σk+1=min(ζσk,U) (9) 转步5; 否则返回步2。 在第k+1次迭代中,子问题(6)可转换为如下形式: Bτ≤d. (10) 其中B=[-eT,eT],d=[lT,uT],为简化运算,取l是n×1维元素全为0的列向量。该问题是一个0范数约束的优化问题,目标函数为一个凸函数,利用硬阈值算法[46]可以获得该问题的显式解为: 中前s个最大值对应在指标序列。对于子问题(7),这是一个无约束优化问题,结合式(8)其一阶最优性条件为: 2∑ω+λk+1+σkAT(Aω-b)=0 (11) 解之得: (12) 我们使用HangSeng31、DAX100、FTSE100、S&P100和Nikkei225等5个标准数据集[39],以及来自于中国市场的上证50和中证100数据集。其中来自OR-library的5个数据集是从1992年到1997年的周收益率数据,上证50以及中证100数据集则是从2013年到2015年的日收益率数据。将每个数据集都等分成两部分,分别作为训练集和测试集。训练集用于得到得到模型(2)中的最优参数,测试集用于测试训练集所得参数的性态。 (13) 同理,记含上下界约束的MV模型的夏普比率为SRMV,SBPE方法相对于等权重策略的优势可表示为Sup(A,C)。SBPE方法得到的夏普比率的估计值与该数据集上夏普比率的最大值之间的差值记为: (14) 由于本文选取的数据集记录的是各指数成分股每周或每日的收盘价格,对应无风险利率较小,因此我们设定无风险利率rf=0。考虑到没有卖空机制,投资者不会考虑将资金投入到负收益的资产上,因此预期收益下界取min(0,ρ),其上界则不应超过成分股中的收益率最大值max(ρ)。投资权重的上界约束u取为n×1维分量全部为0.5的列向量。算法精度ε=10-5,初始迭代步长为h=0.005并且设置步长更新比例α=0.6。 图2 预期收益率-夏普比率图线 根据表3,比较SBPE模型得到的预期收益率与等权重策略的预期收益率,结果显示71.43%(5/7)的数据集中,SBPE模型估计得到预期收益率取值更大。将SBPE模型参数估计值对应的夏普比率与等权重策略的夏普比率进行比较,结果表明SBPE模型远优于等权重策略,对应的夏普比率至少提升了19.5%,从而说明了参数估计的有效性。 本节用基于ADMM的无导数优化算法对投资组合预期收益率ρ及稀疏度K进行估计,然后通过分析数值实验结果,验证算法的有效性。稀疏度的K初始值设置为5,其它参数设置均保持不变。图3依次分别是HangSeng31指数、DAX100指数、FTSE100指数、S&P100指数测试集的预期收益率-稀疏度-夏普比率三维图线。在各图中,红色直线在预期收益率-稀疏度平面上的投影坐标即是预期收益率ρ及稀疏度K的估计结果,而直线与曲面的交点则是估计参数在测试集中对应的夏普比率。从图3中可以看出,在预期收益率固定的情况下,随着稀疏度的增加,对应的目标函数值大约是呈倒U型变化的,目标函数值先逐步增大,在某个固定的稀疏度之后,开始逐渐减小。因此,对最优稀疏度进行估计可以优化投资策略,从而获得更高的预期回报。另外限于篇幅,训练集对应的图片未报告,备索训练集中两个参数对应的最优夏普比率取得了比较好的效果,即通过算法得到的参数在样本内有非常好的表现。对于测试集,SBPE模型估计出的参数对应的目标函数值(夏普比率)也在测试集最优目标函数值的附近,其中图3的前三个子图的效果非常好,而最后一个子图的效果则相对较差。 表3 BPSMV与1/N 策略的样本外表现对比(单参数估计) 图3 预期收益率-稀疏度-夏普比率三维变化图 表4分别列出了由SBPE模型估计出的预期收益率、稀疏度。从表4可知,由SBPE模型得到的稀疏度值远小于各指数中包含的风险资产数量,将极大地减轻投资组合的管理难度和降低交易费用。在表5中将SBPE方法得到的夏普比率与等权重策略、含上下界的MV模型进行了比较。其中,相较于等权重策略,样本外夏普比率提高了至少18.99%;相较于含上下界的MV模型,样本外夏普比率至少提高了39.03%。另外,在训练集中,由SBPE模型估计得到的夏普比率与真实的最大夏普比率差值非常小,测试集中该差值有85.71%(6/7)小于5%,最大也不超过15%,因此可以认为SBPE模型取得了比较好预测效果。综合上述两个方面的结果,就说明了SBPE方法对参数估计的有效性。 表4 BPSMV的参数估计结果(双参数估计) 表5 三种投资策略的样本外表现对比(双参数估计) 本文构建了一种新的基于效用的带基数约束的双层投资组合模型SBPE。利用国内外股票市场的数据,该模型可得到预期收益率与最优稀疏度的估计值。实证结果表明,SBPE模型能够较好地对参数的真实值(在最大夏普比率下取得)进行逼近,从而为投资者的最优决策提供了可资借鉴的工具。事实上,本文提出的SBPE模型可以进一步推广得到其一般形式GSBPE: ω(a,b,c)=argming(ω(a,b,c)) s.t.ω∈W (15) 1)当f(ω(a,b,c))和g(ω(a,b,c))均为凸的,则GSBPE模型可以用CVX、CPLEX等优化软件包求解; 2)当f(ω(a,b,c))是非凸的,而g(ω(a,b,c))是凸的,则GSBPE模型可以使用无导数优化算法框架,对子问题使用ADMM、NPG[47]等算法求解; 3)当f(ω(a,b,c))是非凸的,g(ω(a,b,c))也是非凸的,则GSBPE模型可以使用无导数优化算法框架,对子问题使用遗传算法等求解。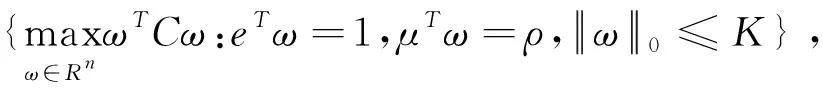
3.3 基于夏普比率的双层MV模型
3.4 SBPE模型

4 算法设计
4.1 无导数优化算法框架

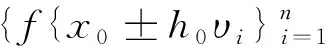

4.2 求解子问题的ADMM算法
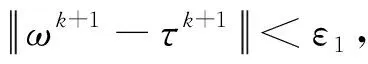
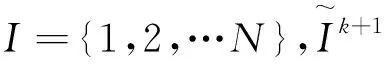
5 实证分析
5.1 数据生成过程

5.2 对预期收益率的估计
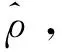
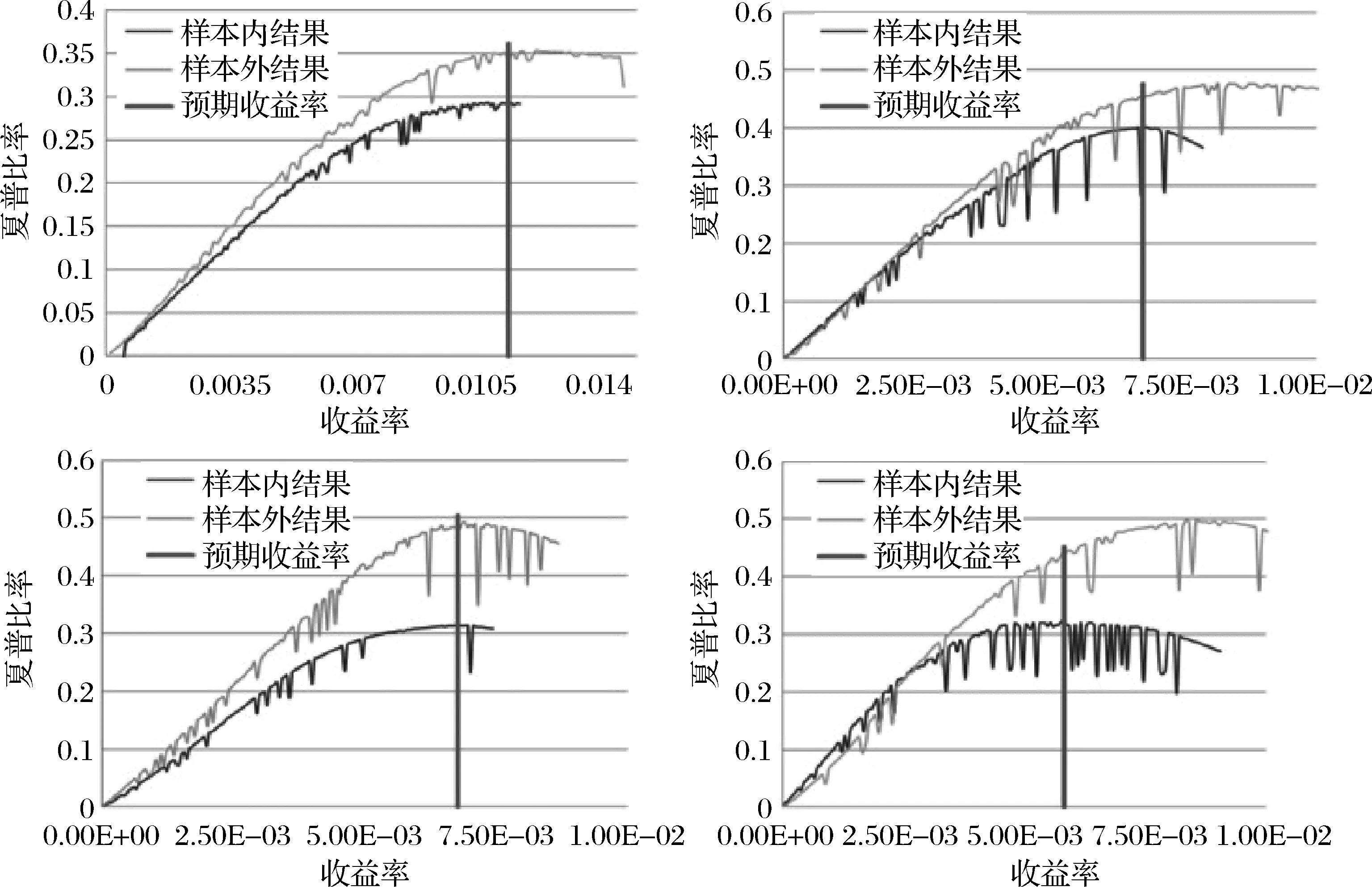
5.3 对预期收益率和稀疏度的估计

6 结语