测试用例执行轨迹分析的故障定位方法
2019-01-24周宽久
曹 迅,周宽久
(大连理工大学 软件学院,辽宁 大连 116620)
1 引 言
随着计算机软件在现代社会中的广泛应用,软件的代码量和复杂程度都不断提高.大型系统软件的设计过程中,由于设计缺陷或者程序员的编码失误而引入的软件故障无法避免.据统计,软件测试和软件调试的花费已经占到软件生命周期的50%以上[1].程序调试(Program Debugging)技术作为一种定位并修复软件故障的技术,在软件开发生命周期中的地位重要性越来越高.程序调试通常包括故障定位(Fault Localization)和故障修复(Fault Recovery)两方面,其中如何准确并且快速地定位故障源已经成为软件设计中的主要难点.高效的程序调试技术特别是软件故障定位技术,对于节约软件开发成本、提高软件产品质量有着十分重要的意义.
国内外关于软件故障定位技术的研究已经持续了近30年,科研人员从不同角度和尺度提出了许多故障定位的方案,现有的技术大致可以分为:
基于程序频谱的故障定位(Spectrum-based Fault Localization)通过执行测试用例获得一组抽象的程序执行轨迹(程序频谱),通过分析程序频谱从而定位软件故障.Tarantula[2]技术最早将程序频谱应用于软件故障定位,分别统计语句在失败用例和成功用例中的执行次数,并赋予那些被更多错误测试用例覆盖的语句更高的怀疑程度.Ochiai[3]方法基于代码块定位故障源,同时还考虑了那些不会导致错误结果的故障情形.DStar[4]方法基于相似度系数设计怀疑度计算公式,在定位多个故障时效果理想.此类方法中,无论是语句级别还是代码块级别的怀疑度都可以通过设计或改良怀疑度计算公式来得到,实现时较为容易.另一方面,基于程序频谱的故障定位将程序看成一个黑盒,并没有考虑语句或者代码块之间的依赖关系.
基于统计方法的故障定位(Statistical-based Fault Localization)考虑故障语句与执行结果的统计关系,通过建立程序语句或者代码块与执行结果之间的统计学模型定位故障.Wong[5]等人根据覆盖率信息构造交叉表,通过卡方检验计算语句与测试结果的从属关系,从而得到怀疑度值.Hao[6]等人提出基于相似度感知的故障定位方法,将测试用例看作一个模糊集,从而减少相似测试用例对于故障定位结果的影响.Abreu[7]根据覆盖关系计算组件(代码块)的错误关系,使用贝叶斯方法计算代码块的怀疑度.Zhang[8]使用最小二乘法拟合状态与测试结果之间的非线性关系,用平均标准偏差作为状态的怀疑度值,该方法在正确样本数较少时的优势明显.基于概率统计的方法考虑到了测试用例之间、测试用例与测试结果之间、程序之间的关联关系,但仍然没有充分考虑程序内部的依赖关系,同时统计模型多种多样,设计和实验成本高.
基于模型的故障定位(Model-based Fault Localization)从模型角度描述程序和故障.谓词模型[9]通过对谓词在成功执行和错误执行时的取值进行建模,判断谓词出错的可能性.Yilmaz[10]提出时间频谱模型,通过跟踪方法或者模块一次执行所消耗的时间来预测故障,在定位故障时使用了聚类方法.Zhang[11]等人将程序中可能出现的错误类型看作一个离散的随机过程,使用马尔科夫模型预测错误类型,从而选择最佳的错误定位技术.Zong[12]将故障定位分为函数级定位和语句级定位两个步骤,函数级定位时采用基于模型的方法,语句级定位时采用基于频谱的方法.
基于依赖关系的故障定位(Dependence-based Fault Localization)考虑程序内部的数据依赖和控制依赖对于定位结果的影响.程序切片技术[13]被用于软件故障定位,可以缩小定位故障时的搜索空间.马凯[14]根据程序的控制流图对程序进行分块,通过控制流块的覆盖率、关系分析故障在相邻控制流块中的影响系数.Baah[15]在程序依赖图的基础上,通过增加节点和边得到概率依赖图,根据程序执行的失败信息计算节点存在故障的条件概率.Yang[16]等人分析Java程序运行时变量操作状态变化及其依赖关系,提出基于数据链路的故障定位方法.
基于数据挖掘的故障定位(Data-mining-based Localization)随着近些年数据挖掘和机器学习技术的兴起被应用到软件故障定位领域.文献[17]将C4.5决策树算法应用于软件故障定位,该方法认为相同的情况下执行失败的测试用例最有可能由相同的错误造成,提出用决策树划分的方式来对测试用例进行分类.文献[18-20]使用神经网络训练与虚拟测试用例预测相结合的方法来定位错误,其中文献[18]使用BP神经网络,文献[19]使用RBF神经网络,文献[20]使用DNN网络.这三篇文献中都将代码的覆盖率信息作为输入,将程序的执行结果作为输出,用于训练神经网络.网络训练完成后,将一个虚拟测试用例输入网络中,预测每条语句出错的可能性.
目前基于数据挖掘和机器学习的软件故障定位被认为最具发展前景,但现有的方法都将被测程序看成黑盒,仅从语句或者状态是否被覆盖进行预测,并没有考虑软件本身的结构特性.同时在运行测试用例时代码或者函数的覆盖次数、执行的先后顺序都没有被充分考虑.因此本文在现有研究的基础上,提出基于执行轨迹的软件故障定位方法.我们将待测软件在执行一次测试用例时的执行轨迹表示为一个序列,并将序列数据用于循环神经网络的训练和预测.
本文的主要创新点包括:
1) 使用基于控制流分析的执行轨迹信息表示测试用例,为故障定位算法保留更多有效信息;
2) 将循环神经网络应用于测试用例训练和怀疑度预测,循环神经网络能够学习到测试用例中的顺序信息,故障定位的效果更加准确.
全文章节安排:第2节分析了故障定位的基本问题;第3节介绍了本文使用的循环神经网络的基本结构和训练过程;第4节中介绍了本文所提方法的具体流程;第5节进行了实验和结果分析,验证了方法的有效性;最后是总结和展望部分.
2 问题分析
2.1 使用程序频谱描述测试用例
软件故障定位的最终目的是通过目标程序在一组测试用例上的执行情况,寻找最有可能导致当前测试结果的软件故障所在的位置,定位具体位置可以是代码行、代码块或者函数级别.为了表述方便,在接下来的内容中我们将代码行、代码块和函数统一称为组成程序的组件.在正式定位软件故障之前,需要对待测试软件在输入测试用例后的执行情况进行表示,目前被广泛使用的一种测试用例表示方法是程序频谱技术.
假设程序P由m个组件组成,表示为C={c1,c2,…,cm},其中cj代表第j个组件.程序P在n个测试用例上进行了测试,测试用例表示为T={t1,t2,…,tn},测试结果储存于n维向量e中,e中的每个元素代表相应测试用例的执行结果,具体的:ei=0代表测试用例ti在程序P执行成功;ei=1代表测试用例ti执行失败,失败的情形包括程序输出与预期结果不一致、运行崩溃等.为了加以区分,用Tpass表示成功执行的测试用例,表示为Tpass={ti|ti∈T,ei=0};用Tfailed表示没有成功执行的测试用例,表示为Tfailed={ti|ti∈T,ei=1}.使用一个n×m的矩阵A记录测试用例对于组件的覆盖情况,A中的每个元素aij表示在执行测试用例ti时组件cj是否被覆盖,如果覆盖则aij的值为1,否则aij的值为0.最终,合并后的矩阵[A,e]就是能够刻画测试用例执行的程序频谱.
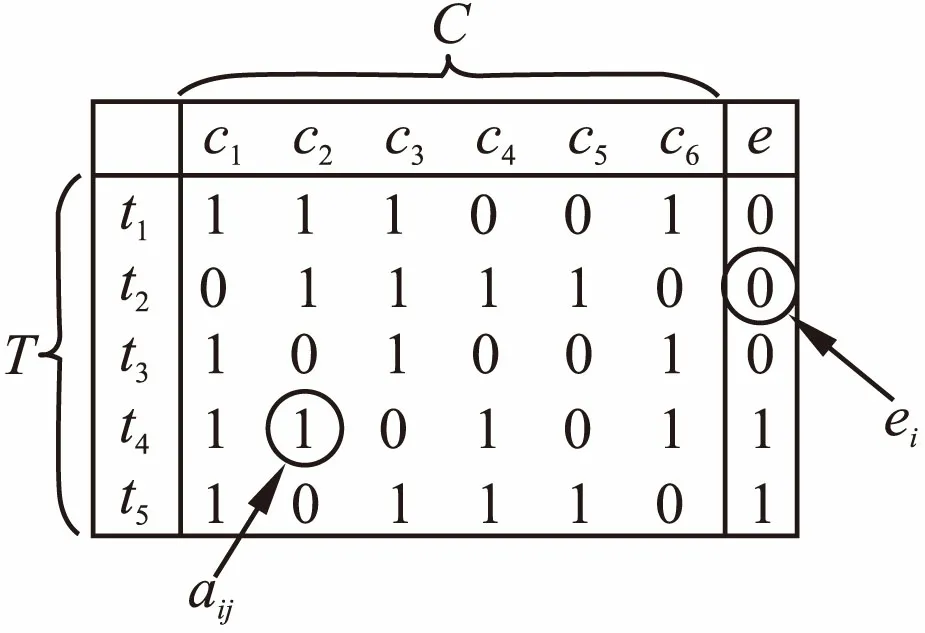
图1 程序频谱举例Fig.1 An example of program spectrum
图1是一个程序频谱的例子,该程序由c1到c6总共六个组件组成,并且在5个测试用例上进行了测试.从图1中的例子可以看出,程序频谱的每一个测试用例仅包含了通过的组件和测试结果两类信息,并不能完全反映被测程序在执行测试用例时的全貌.因此,基于这样的测试信息进行故障推断时损失了一部分测试信息.
2.2 使用控制流图描述测试用例
使用控制流图(CFG,Control Flow Graph)可以精确表示测试用例在被测程序中的执行情况,相比于程序频谱,控制流图保留了程序内部的调用关系、执行的先后顺序等信息.控制流图用有向图G表示,G中的节点称为基本块(basic block),一个基本块是一段不包含跳转或分支语句的顺序代码集合,位于基本块中的代码在一次执行中要么全部被执行,要么全部被跳过,G中的所有基本块可以表示为B={b1,b2,…,bm}.G中的有向边称为跳转,跳转连接了两个不同的基本块,一条从基本块bε指向基本块bγ的边表示程序执行完bε中的所有代码,同时使程序处于将要执行bγ的状态,G中的所有跳转可以表示为E={ei|ei=
2.3 基于控制图的测试路径生成
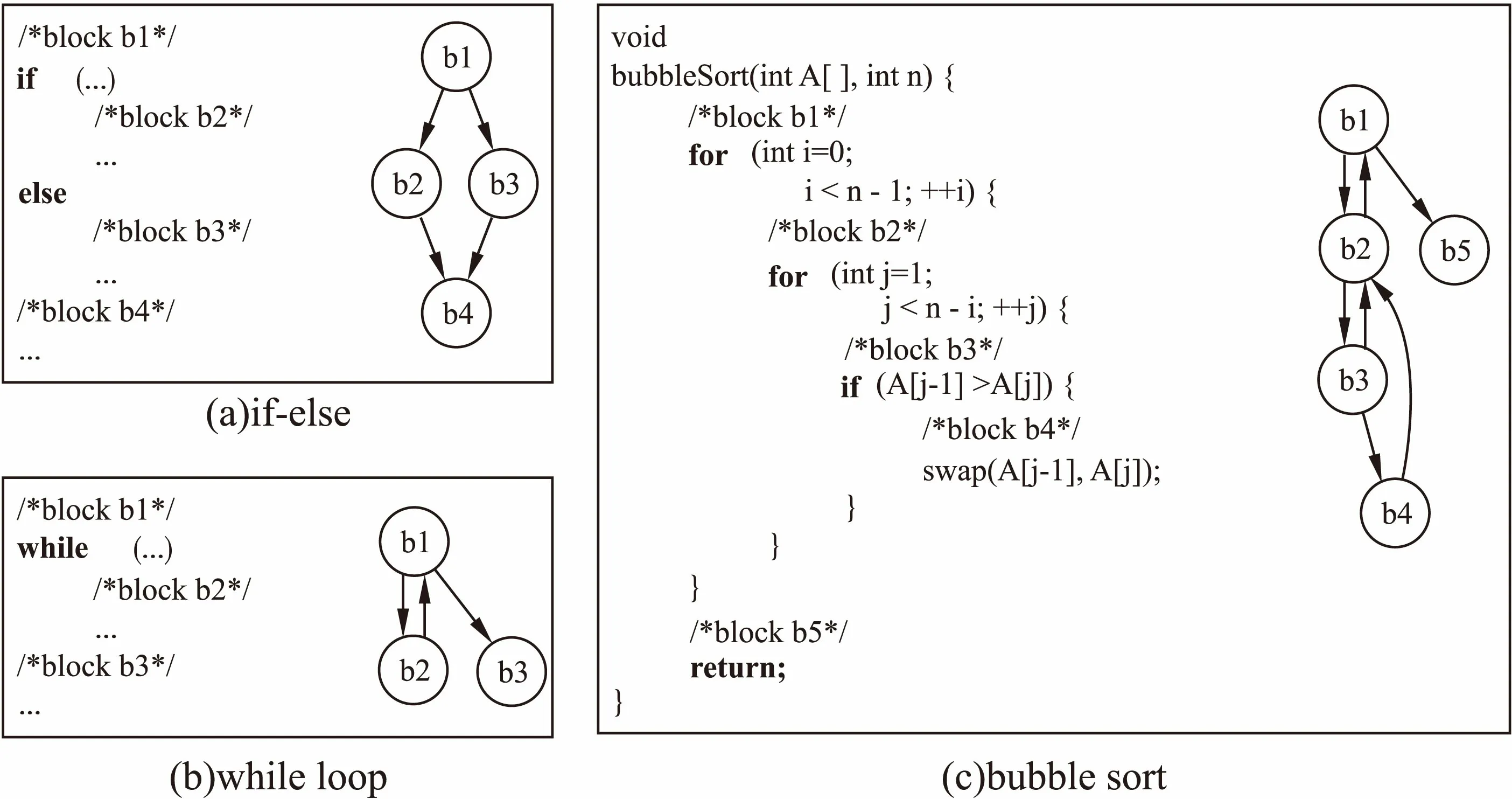
图2 控制流图Fig.2 Control flow graph
控制流图包含了目标程序中的结构信息,借助控制流图可以精确地分析测试用例在被测程序中的执行情况,当一个测试用例被输入到目标程序中之后,会从控制流图的入口节点开始执行,经过多次跳转后达到出口节点,测试用例执行完毕.因此给出测试用例执行轨迹的定义:测试用例ti的执行轨迹是其输入程序控制流图中后经过的所有基本块组成的序列,用符号Seqti表示,显然Seqti总是从bin出发最终到bexit.以图2(c)中的冒泡排序为例,假设测试用例ti的输入为数组[3,2],则通过观察测试用例在控制流图中的执行情况,可以得到测试路径Seqti:b1→b2→b3→b4→b2→b1→b5,记为Seqti=b1b2b3b4b2b1b5.
通过一个例子比较基于程序频谱的故障定位和基于路径的故障定位,图3中的is_num_constant()函数选自西门子测试套件中的print_tokens2程序的v6错误版本,该函数的功能是判断一个字符串是否全部由数字组成,如果是则返回TRUE否则返回FALSE.
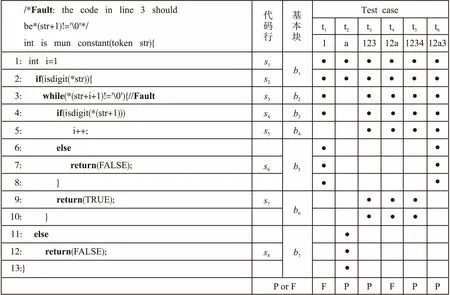
图3 Is_num_constant的覆盖情况Fig.3 Coverage info of is_num_constant
图3中的第一列是程序代码,从错误描述中可以看出错误出现在代码的第3行中.第二列是代码行,用si表示,在标记时略过了没有实际意义的代码(如:“else”、“}”等).第三列是根据代码行划分的基本块.第四列对应一组若干测试用例,每个测试用例包括用例编号、测试输入、代码行以及最终的测试结果.用“•”表示用例覆盖了对应的代码行和基本块,最后的F代表测试用例执行失败,P代表测试用例执行通过.以用例t1为例,该用例的测试输入为字符串“1”,用例执行的过程中覆盖到的基本块和代码行包括:b1(s1,s2),b2(s3),b3(s4),b5(s6),最终的测试结果为F,也就是函数错误的把字符串“1”判断成不是全部由数字组成,并返回了结果FALSE.
通过图3中的覆盖表可以得到包含覆盖矩阵和测试结果向量的程序频谱,通过程序频谱进行预测.然而,观察测试用例t3,t4和t5会发现这三个测试用例对于代码行和代码块的覆盖情况完全相同,但测试结果t3和t5显示为测试通过,而t4则显示为测试失败.也就是说在对应的程序频谱中对于用例t3,t4和t5对测试情况的描述完全相同,但在测试结果上确存在差别,因而无法区分.
对比程序频谱,使用基于控制流图的路径分析方法表示图3中的测试用例,路径分析的结果显示在图4中.对比图4中的执行路径发现,虽然用例t4与t5在基本块的覆盖情况上没有区别,但是观察对应的路径会发现t4的执行路径Seqt4=b1b2b3b4b2b6,t5的执行路径Seqt5=b1b2b3b4b2b3b4b2b6,两者的执行路径存在区别,因此可以通过执行路径将两个测试用例加以区分.
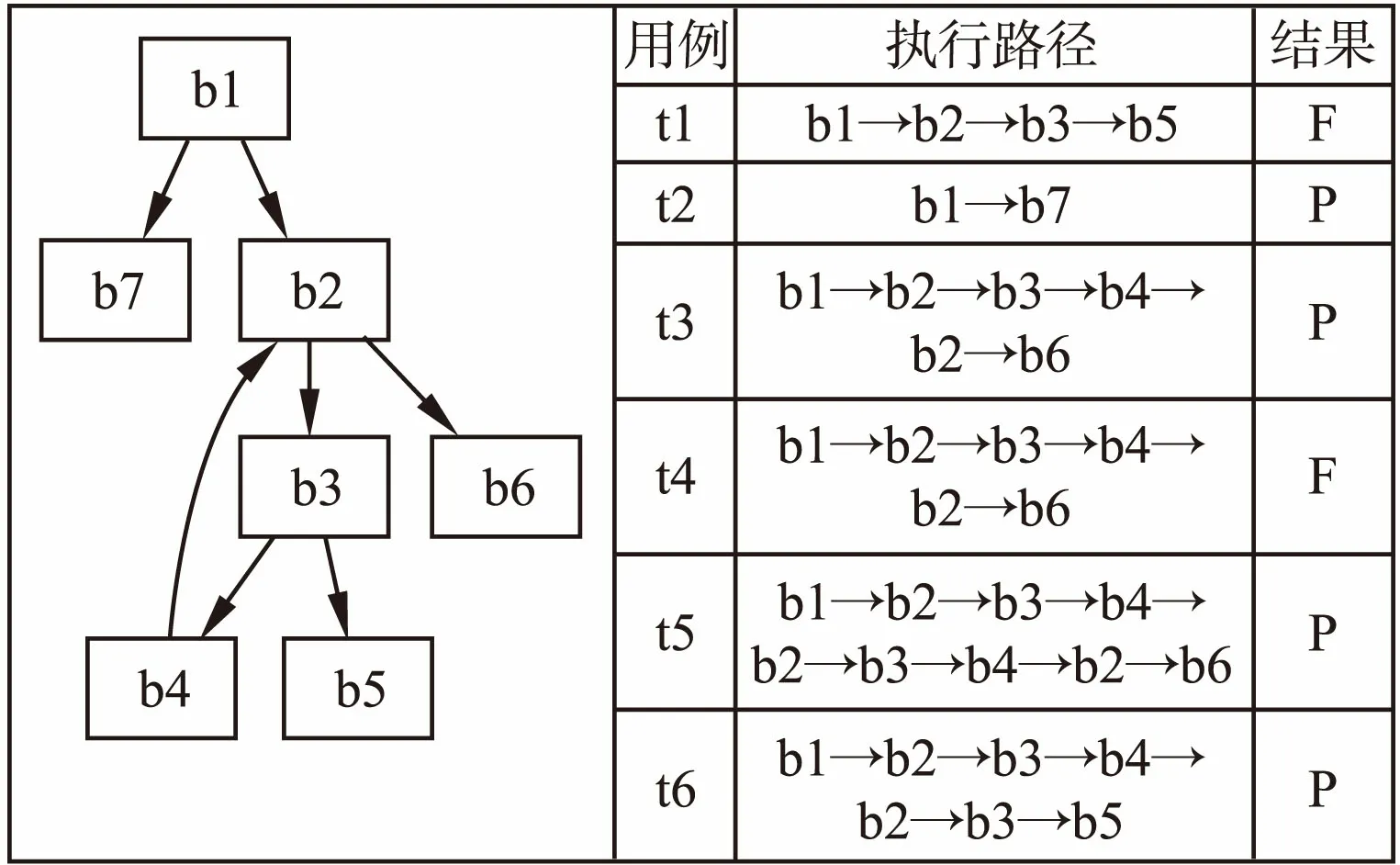
图4 Is_num_constant的执行路径分析结果Fig.4 Exectuion trajectory of is_num_constant
通过上述分析可以看出,基于程序控制流图的测试序列分析与程序频谱分析相比,前者不仅包含了每个测试用例执行时组件的覆盖情况,还包含了被覆盖组件的执行次数和执行的先后顺序.
3 循环神经网络
3.1 循环神经网络简介
循环神经网络作为一种具有记忆功能的人工神经网络,在处理序列化的数据时具有独特的优势.与基本的人工神经网络相比,循环神经网络最大的不同是存在于各隐藏层节点间的连接边,这些连接在隐藏层的前后状态间建立起联系,使得神经网络具备“记忆”功能.
图5中比较了基本的神经网络和循环神经网络在结构上的不同,这两种神经网络都由输入层、隐藏层和输出层组成(每一层都可以包含若干个神经元节点,这里抽象成一个).图5(a)是一个最基本的神经网络,向量x表示输入层状态,向量s表示隐藏层状态,向量o表示输出层状态,U是连接输入层节点和隐藏层各节点之间权重矩阵,V是隐藏层和输出层之间的权重矩阵,从该结构中可以看出隐藏状态s取决于输入层状态x,表示成s=f(Ux).图5(b)是循环神经网络的基本结构,可以看出与基本的神经网络最大的不同是同一隐藏层节点之间通过一个权重矩阵W连接,这样的结构使得循环神经网络的隐藏层状态s不仅仅取决于当前输入x,还取决于上一次隐藏层的状态.将图5(b)中的循环神经网络展开可以得到图5(c)中的结构,从这个结构可以更加清晰的地看到参数在网络中的传递情况.st的值不仅取决于当前的输入xt还取决于隐藏层上一次的状态st-1,可以表示成st=f(Uxt+Wst-1).
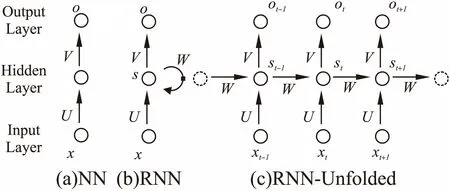
图5 基本的人工神经网络与循环神经网络Fig.5 Artificial neural network and recurrent neural network
3.2 训练过程
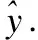
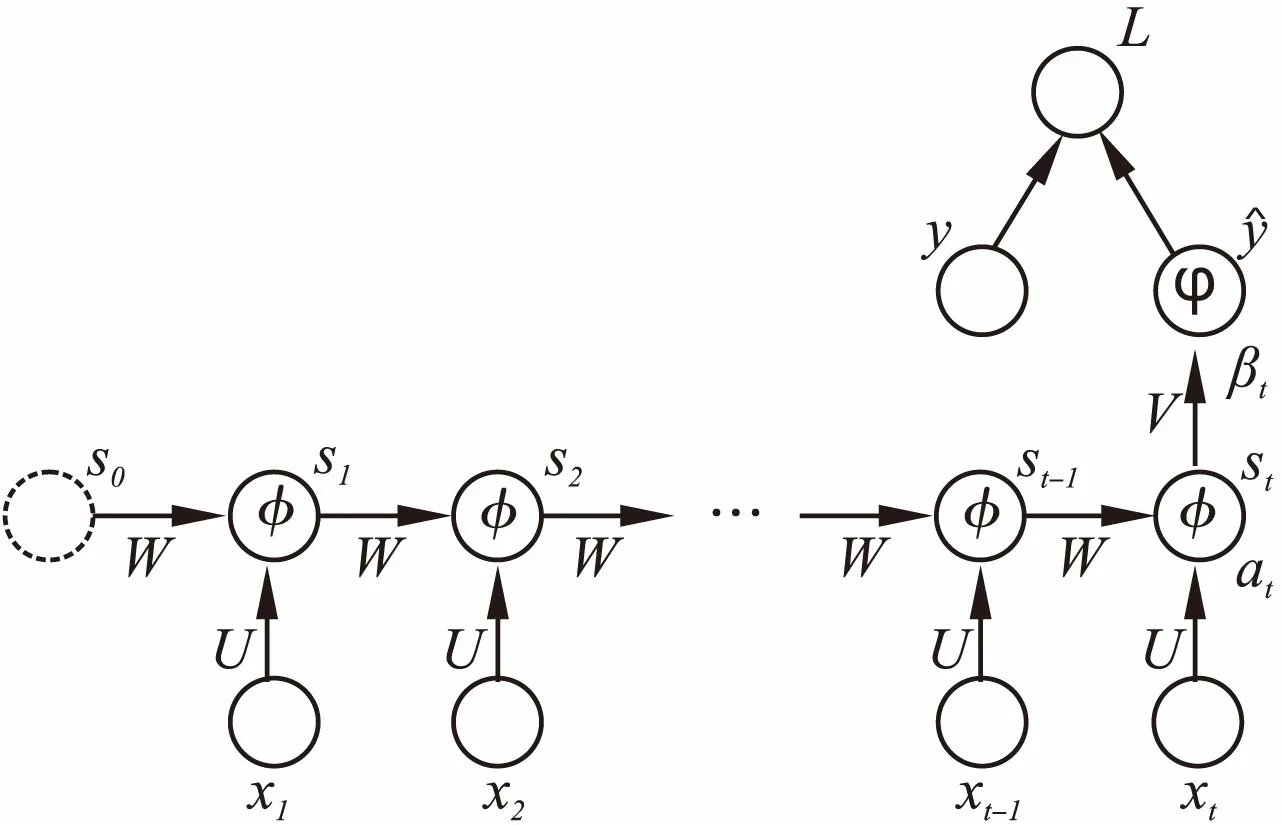
图6 多输入单输出循环神经网络Fig.6 RNN with multi inputs and single output
3.2.1 损失函数
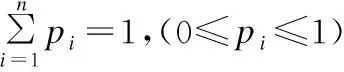
(1)
对于多分类问题,通常使用交叉熵作为损失函数,损失函数的形式如下:
(2)
3.2.2 更新参数V
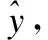
βt=Vst+c
(3)
(4)
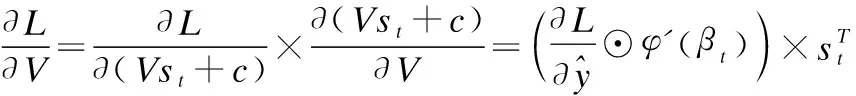
(5)
上述公式中的×代表矩阵乘法,⊙代表矩阵中的元素相乘.
3.2.3 更新参数W和U
与参数V不同,参数W和U在整个循环神经网络中沿着从后向前的方向传播了t次,可以通过循环的方式计算梯度.为了方便表示,用αt表示隐藏层在t时刻的输入值.在计算全局梯度之前,需要先计算每个时刻的局部梯度,计算公式为:
αt=Uxt+Wst-1+b
(6)
(7)
(8)
利用局部梯度计算U和W的梯度:
(9)
(10)
得到梯度公式后,就可以根据设定的学习率对参数进行更新.以上就是基于反向传播算法的循环神经网络的整个训练过程.
4 基于循环神经网络的故障定位方法
4.1 获取测试用例执行轨迹
在开始故障定位之前需要获得测试用例的执行轨迹信息,本文使用基于控制流图的方法分析测试用例的执行轨迹,将基本块作为程序执行的基本单位.同一基本块中的代码在所有测试用例中的被执行和调用的情况完全相同,因此同一基本块中的代码存在故障的怀疑度值也是无差别的,故障定位到基本块级别之后只需在当前基本块中顺序搜索即可.
本文进行故障定位分析的目标程序是C/C++程序,使用插桩的方式获得执行轨迹信息.使用的插装函数如图7所示,在执行测试之前在每个基本块中插入桩函数,当基本块被执行时会向日志文件中输出一个唯一标识,最终得到的标识序列就是测试用例的执行轨迹.
在插桩时需要考虑两类特殊情况:
1)函数
当基本块中有函数调用时,需要将调用函数的部分看作单独的基本块,并在函数调用前插入装函数记录被调用函数的入口,使得在分析测试用例的执行路径时更加清晰.

图7 插桩函数Fig.7 Stub function
2)复合逻辑谓词
由于多个逻辑谓词在组合使用时存在短路现象(如:1||0、0&&1等),因此在遇到这种情况时需要对每个可能产生短路的谓词单独插桩,插桩的方式如图8所示.
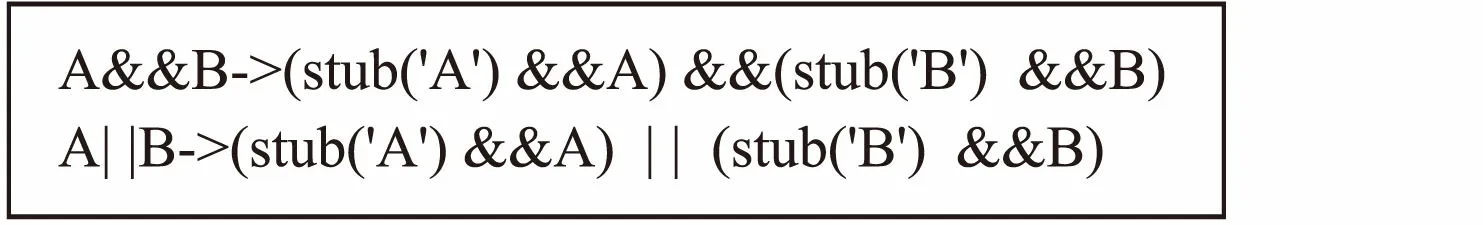
图8 复合谓词插桩Fig.8 Stubs of composite predicate
通过插桩的方式获得的是一组不同长度的由组件标识构成的序列(如图4所示),但这样的序列不适合直接用于循环神经网络的训练,因此需要对序列进行标准化.路径序列的标准化算法如算法1所示.
算法1.路径序列标准化
输入:测试路径集合Seq
输出:标准化矩阵M
1.Initialize MapState2Index= {(None:0)}
2.Initialize ListM= []
3.InitializeMaxLength= 0
4.InitializeIndex= 1
5.forSeqiinSeqdo
6.MaxLength= max(MaxLength,length(Seqi))
7. forbjinSeqi
8. ifState2Index.find(bj) = Ø
9.State2Index[bj] =Index
10.Index=Index+ 1
11. end if
12. end for
13.end for
14.forSeqiinSeqdo
15. Initialize Listtemp= []
16. Initializecurlength= length(Seqi)
17. forbjinSeqi
18.temp.append(State2Index[bj])
19. end for
20. whilecurlength 21.temp.append(State2Index[None]) 22. end while 23.M.append(temp) 24.end for 25.returnM 算法1的输入为测试序列集合Seq,输出是标准化后的矩阵M.算法首先遍历Seq中的每一条路径,遍历的目的是找到所有测试用例中的基本块并且为每个基本块映射唯一的索引号,同时获得最大序列长度MaxLength.第二次遍历时,将序列中的每个基本块对应的索引号放入矩阵M,在当前序列的长度小于最大序列MaxLength时,用0补齐剩下的部分.应用算法1处理图3中的例子的结果显示在图9中. 在开始训练之前,需要设置网络的循环次数、各层节点数、激活函数等,图10展示了网络的训练过程. 图10 训练网络过程Fig.10 Training process 图中输入层节点数为基本块数,隐藏层节点数可以根据实际情况设置,输出层节点数为目标类别数.训练时将标准化矩阵M作为网络的输入,每次训练输入一行,代表一个测试用例.数据输入时按照先后顺序每次向输入层输入一个代表基本块的标识,在实际应用中通常对输入数据进行编码处理后再作为网络的输入,编码的方法如算法2所示. 算法2.一位有效编码 输入:标准化矩阵M,基本块个数L 输出:编码后的矩阵MEncode 1.Initialize ListMEncode= [] 2.forlineiinM 3. InitializenewLine= [] 4. foritemjinlinei 5. InitializenewItem= {0} with sizeL 6. ifitemj!= 0 7.newItem[itemi- 1] = 1 8. end if 9. end for 10.end for 11.returnMEncode 以图10中的测试用例t1为例,t1的测试序列经一位标准编码后,对应的输出结果为[[1,0,0,0,0,0,0],[0,1,0,0,0,0,0],[0,0,1,0,0,0,0],[0,0,0,1,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,0,0]]. 循环神经网络中输入层到隐藏层间的激活函数通常使用双曲正切函数,计算公式为: y=(ex-e-x)/(ex+e-x) (11) 循环神经网络的隐藏层输入不仅来自本次的输入层,还来自与上一次循环时隐藏层的输出值.特别地,在第一次循环时将来自上一隐藏层的输入s0设置为0向量.通过观查网络的输入数据可以发现,当路径序列的标识变为0时,输入层数输入值变为[0,0,…,0],这时输入网络中的数据不再有意义,因此隐藏结束向后传播并且将数据输出到输出层.以图10中的测试用例t1和t5为例,t1在第4步后结束循环,同时向输出层输出此时的隐藏层状态s4;t5则在全部数据输入完后,将最后一步的隐藏层状态s9输出到输出层. 由于一条测试用例的测试结果只有成功和失败两种情况,因此输出层的节点个数设置为2.同时,输出值经过softmax函数处理后变为测试用例成功或者失败的概率分布,输出的形式为: (12) 其中p表示测试用例失败的概率,1-p表示测试用例成功的概率.对于测试用例的正确标签y,也需要进行one-hot处理: y=[1-q,q],(q∈{0,1}) (13) (14) 之后可以使用反向传播算法进行训练,当误差小于设定值或者训练次数达到设定值时结束训练,得到最终的网络. 网络训练完成后可以用于测试用例预测,假设有一组虚拟的测试用例v1,v2,…,vm,这组虚拟测试用例的执行轨迹为: {πv1,πv2,…,πvm}={b1,b2,…,bm} 每一条虚拟测试用例vi(i=1,2,…,m)执行时仅经过一个基本块bi,如果测试用例vi执行失败,那么基本块bi就很有可能包含故障,因此调试时应当优先考虑.但在现实中,这样的一组虚拟测试用例是无法设计出来的,所以为了获得这些虚拟测试用例的执行结果,我们建立一个循环神经网络,并将现有的测试数据输入网络中进行训练.当网络训练完成后,将虚拟测试用例的执行路径标准化后输入到网络中,网络的输出对应基本块的怀疑度.预测过程如图11所示. 上述过程可以总结以下几个步骤: 1)使用插桩的方法获取测试用例的执行序列集合Seq,使用算法1将序列集合Seq转换为可以用于循环神经网络训练的标准化矩阵M; 图11 预测过程Fig.11 Predicting process 2)建立一个包含L个输入层节点(L为程序P中的基本块个数),h个隐藏层节点(本文中h设为30)和2个输出层节点的循环神经网络.设置输入层和隐藏层之间的传递函数为双曲正切函数tanh,输出层的转换函数为softmax函数. 3)训练循环神经网络,将准化矩阵M作为网络的输入,将测试用例对应的执行结果作为期望的输出,在训练时为了克服过拟合问题使用到了Dropout随机丢弃算法; 4)将虚拟测试用例输入到训练好的网络中,得到预测值pv1,pv2,…,pvm; 5)使用pv1,pv2,…,pvm对基本块b1,b2,…,bm进行排名,然后按照怀疑度从高到低的顺序在每个基本块中查找错误,直到错位被定位到. 表1 预测结果 基本块预测值基本块预测值b10.43503392b50.78848398b20.96262193b60.83428442b30.26716137b70.00091218b40.15842001—— 作为示例,使用本文所提方法对图3中给出的is_num_constant函数进行故障定位.is_num_constant总共被划分为7个基本块,并且在6个测试用例上进行了测试,每个测试用例对应的执行路径显示在图4中.通过对这6个测试用例进行标准化处理后得到图9中的标准化矩阵M.可以看出第一个测试用例t1的输入序列为(1,2,3,4,0,0,0,0,0)对应的期望结果为0,以此类推. 根据矩阵M的结构,设置循环神经网络的输入层节点数为7,隐藏层节点数为30,输出层节点数为2,当训练步数达到1000时停止训练. 将图11中的虚拟测试用例逐行输入网络中,得到表1中的预测结果,表中的预测值表示对应的基本块怀疑度.排序后得到最终的怀疑度排名是b2,b6,b5,b1,b3,b4,b7,结果表明基本块b2包括错误的可能性最高,与实际情况相符. 为了证明本文所提方法的有效性,从SIR官方网站获得了Siemens测试套件并进行了故障定位实验.实验的软件环境分为两部分,测试执行和数据收集工作在Ubuntu 16.04环境下进行,使用到的gcc和gcov均为5.4.0版本.数据分析部分在windows 7环境下进行,使用到的Python版本为3.5.4,训练神经网络时使用的TensorFlow版本为1.4.0.硬件环境为i7-6600U 2.6GHz CPU和12GB RAM. 表2 Siemens套件 ProgramVer.LOCCasesDescriptionprint_tokens7563(+159)4230词法分析器print_tokens210508(+57)4115词法分析器replace325635542模式匹配与替换schedule94102650优先级调度器schedule210307(+66)2710优先级调度器tcas411731608高度分离程序tot_info23406(+158)1052信息统计程序 Siemens测试套件是一组在软件故障定位领域被广泛使用的测试数据集,它包含了7个独立的C语言程序,每个程序都包括一个完全正确的源程序以及若干个包含故障的版本,同时还包含了大量的测试用例,测试套件有关信息整理在表2中.表2中每一列的数据分别代表:程序的名称、错误版本数、代码行数、测试用例数和以及程序的功能描述.其中在统计代码行数时仅对main函数所在的文件进行了统计,其余文件(如.h文件)的代码行数显示在括号中. 实验分为以下几个步骤: 1)Siemens测试套件提供了大量的测试用例,但并没有提供这些测试用例对应的执行结果,因此首先需要在正确版本的源程序上执行测试用例,获得正确的输出; 2)为了获得测试用例的执行轨迹信息,对于程序的每个错误版本,使用4.1节中的方法进行插桩并运行测试用例,获得程序的实际输出以及测试用例的执行轨迹信息; 3)为了获得测试用例的覆盖率信息用于对比,使用gcov工具在gcc环境下运行测试用例,并从测试结果文件中解析出测试用例的覆盖矩阵; 4)将测试用例在错误版本程序上的输出与正确输出比较,获得测试用例在该错误版本程序上的执行结果; 5)将测试用例的执行轨迹标准化后作为循环神经网络的输入,测试用例的执行结果作为输出,使用反向传播算法训练神经网络; 6)将一组虚拟测试用例输入训练好的网络中,获得对应基本块的怀疑度值,将排序后的结果作为最终的预测结果. 为了评价故障定位方法的性能,使用score值作为评价标准,score值通过下面的公式获得: (15) 上述公式中N代表尚未被测试的代码行数,LOC代表总的代码行数,显然score的取值范围为[0,1),因为故障定位时按照怀疑度排名检索错误,最好的情况下在检索到第一行代码时就成功发现了错误,此时N=LOC-1;而最坏时则需要一直检测到怀疑度列表中的最后一行代码时才能发现错误,此时N=0.在衡量故障定位算法的性能时,score值越高意味着能在更短的时间内和更小的代价下定位到错误;相反地score的值越小则表明故障定位算法需要检测更多的不相关代码后才能发现错误,故障定位效果欠佳. 我们将本文方法与几个经典故障定位方法进行了比较,分别是:文献[2]中的Tarantula方法,文献[9]中的SOBER方法,文献[5]中的Crosstab方法,以及文献[18]中的BPNN方法.Siemens测试套件中总共包含了132个错误版本,本文的方法基于以下规则进行了一些删减: 1) 故障版本中的主程序不存在错误,错误代码位于头文件中,如print_tokens的v4和v6版本; 2) 所有的测试用例在错误版本中都成功执行,无法获得错误信息,如schedule的v9版本; 3) 故障版本存在段错误,导致所有的测试用例均无法成功执行,如replace的v27和v32版本,最终使用了122个错误版本.在其他故障定位方法中也根据各自情况进行了一些调整. 表3 Score值分布 score(%)TarantulaSOBERCrosstabBPNN本文方法[90,100)55.7352.3058.1450.0059.02[80,90)5.7421.5414.7324.5922.13[70,80)9.843.856.9811.489.02[60,70)8.204.6213.187.387.38[50,60)7.380.771.553.280.82[40,50)0.820.770.783.280.82[30,40)0.822.311.550.000.82[20,30)4.12.312.330.000.00[10,20)7.382.310.760.000.00[0,10)0.009.220.000.000.00 为方便统计,将score值划分为10个区间,分别统计每种故障定位方法在各个区间上能够定位的故障版本数的分布情况.表3为按区间统计的定位结果,最后一列为本文所提方法.从表中可以看出本文方法在仅检查10%的代码的情况下能够定位59%左右的故障版本,而同等情况下其余四种方法能定位的故障版本数为:55.73%,52.30%,58.14%和50.00%. 图12中使用折线图更加清晰地展示了表3中的信息,图中的x轴代表尚未检测的代码行数占总代码行数的百分比,y轴代表已经成功定位到的故障版本的百分比.图中的每个节点代表在当前百分比代码已经被检测过的情况下,成功定位到错误的故障版本的比例.从图中可以看出,在已经检测的代码行数相同的情况下,基于本文方法能够定位的故障版本数高于其它几种方法. 图12 实验结果对比Fig.12 Results of comparative experiments 如果把检测到故障需要检查的代码行数区间看作随机变量X,将在该区间内定位到的故障版本百分比看作随机概率P,可以得到这三种方法在定位故障时需要检测的代码的数学期望E,分别是:E(Tarantula)=0.276,E(SOBER)=0.282,E(Crosstab)=0.210,E(BPNN)=0.199,E(RNN)=0.175,结果表明本文所提方法在定位软件故障时需要检查的代码百分比为17.5%,期望值最低. 软件故障定位是软件调试过程中的重要环节,现有的软件故障定位方法中没有完全利用故障程序在执行测试时的测试信息.因此本文提出从程序的执行轨迹信息中定位软件故障,该方法基于程序的控制流图得到测试用例的执行轨迹,执行轨迹不仅包含了程序的覆盖率信息还包含了基本块的执行顺序和次数.通过将序列信息输入循环神经网络中训练,并使用一组虚拟测试用例进行预测,最终得到基本块的怀疑度值. 本文所提方法在实验数据集上取得了较好的故障定位效果,但在一些方面依然存在不足:首先,实际软件规模巨大时,得到的测试序列的长度也会超出想象,过长的序列会给神经网络的训练带来挑战;其次,使用测试序列的定位方案目前仅适用于单线程程序,对于多线程程序而言无法获得唯一的测试序列,因此无法推广.接下来的工作重点是考虑如何从长测试序列中提取有效性信息以及在多线程程序中的应用问题.4.2 训练网络

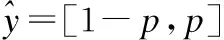
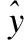
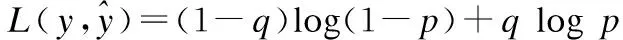
4.3 预测过程
Table 1 Results of prediction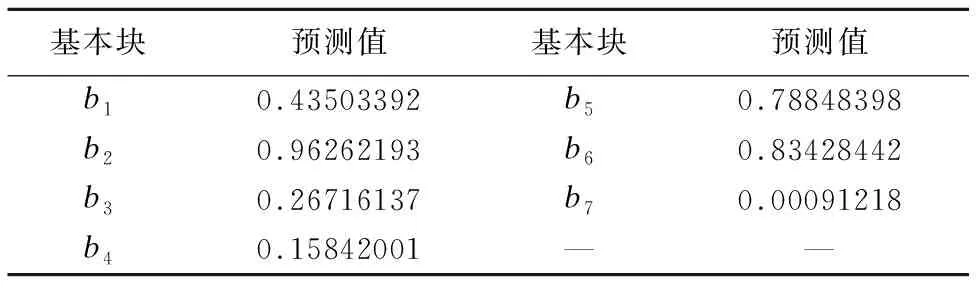
5 实验与对比
5.1 测试数据集
Table 2 Siemens suit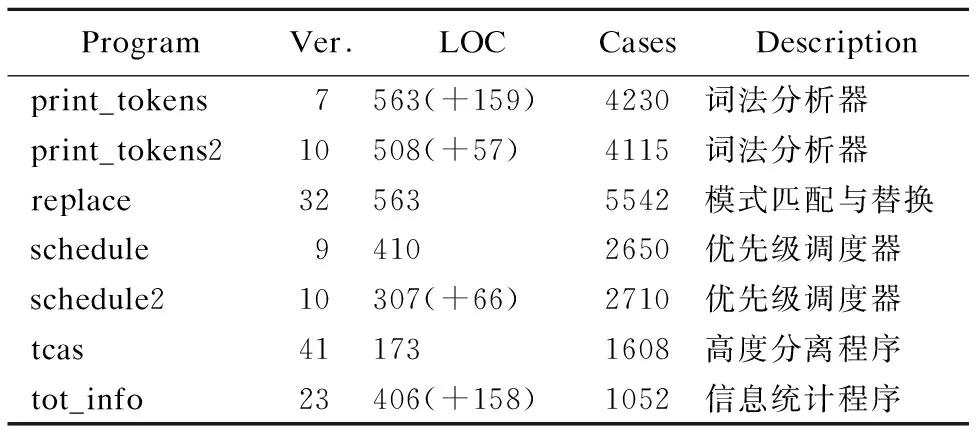
5.2 实验过程
5.3 结果分析
Table 3 Score distribution

6 结束语
