一种面向主动服务的情境感知引擎
2019-01-24李伟平卢思远
周 航,莫 同,李伟平,卢思远
(北京大学 软件微电子学院,北京 100871)
1 引 言
随着物联网的发展,很多应用场景下的被动服务提升为主动服务.主动服务无需人来驱动,由系统自动采集数据,根据逻辑进行判断,然后主动提供如信息检索、智能管理等典型应用服务,极大减少了人力成本,同时提高了服务触发的及时性和准确性[3].情景感知(context aware)是实现主动服务的一种主流方式[1],“情境”和“情境感知”被定义为“位置、人和物体周围的标识以及这些物体的变化”[2],通常可以用情境属性来指代这些物理或者社会性的特征和信息.相应的情境感知即指对这些情境属性的获取和处理过程[1].
在之前的相关工作中,我们为全国各地多个粮库的储粮过程中的通风、制冷和杀毒等需求以及大楼的安防监控等需求分别建立了情境感知模型[4,5].在这些情境模型中,我们定义了情境属性,并划分出不同场景,指定当场景下的情境属性符合某个规则时需要触发的服务.在实现层面,引擎是非常重要,良好的引擎可以主动适应规则变化,帮助人们以很低的成本来高效准确的管理复杂的情境感知系统,因此引擎的设计面临许多技术上的挑战.一方面,引擎要支持各种语义表达(业务逻辑的描述)的解析与执行.另一方面,由于传感器自动采集数据的数量和频次较高,引擎在面对大数据量时需要具备较好的处理性能.相关研究[6,7]为此提出了由事件驱动的可扩展的设计方案,我们学习并测试了这些方案的可行性,并调研了市场上的几款开源规则引擎如Drools、JRuleEngine[8,9],并尝试将处理规则匹配的操作托付给它们.以Drools为例,它是一个基于Java的开源规则引擎,可以将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件中,使得规则的变更不需要修正代码重启机器就可以立即在线上环境生效[10,11].但在实际开发过程当中,Drools等规则引擎并不能很好的满足实际的业务需求.第一,Drools的表达能力较弱.Drools的规则文件仅支持符合自然语义的规则定义,不能够完整、准确地描述一个情境模型,如原始传感器数据到情境属性的映射关系、情境规则和场景的从属关系等.第二,Drools在执行时存在性能瓶颈.在情境模型中,每一条规则都包含在一个具体场景下,而Drools在执行前并不能将数据定位到其从属的场景下,这导致每一条传感器数据在执行过程中都将遍历所有规则并进行匹配,在处理短时间密集传入的传感器数据时存在不可容忍的时间损耗.对此我们的工作目标是设计并实现一个情境感知引擎,它具备更好的模型描述能力,如定义场景下赋值条件、处理传感器数据的时序逻辑等.同时在执行过程中可以通过缓存服务、场景构造等方法快速定位到当前数据匹配的场景下,提升性能.
本文第1节介绍了研究背景,对相关的情境感知模型以及规则引擎的研究现状进行回顾和分析,提出了情景感知引擎的设计目标.第2节介绍了引擎的内部各个模块的作用及整体的执行流程.第3节解释了一个标准的模型文件的组成.第4节详细解释了后端引擎在获取传感器数据后进行场景构造、场景定位、规则匹配和服务触发的具体流程.第5节从几个角度对所提出的方案和进行仿真实验,最后在第6节给出本文的结论和未来的工作.
2 情境感知引擎
主动服务要想能够实现,需要一个计算机可理解的业务逻辑来自动执行.模型相当于把业务表述成计算机可执行的业务逻辑,典型的模型可以被组织成如结构化文档XML等格式.用户首先通过图形化的建模工具完成建模,之后通过接口将模型文件输入引擎解析并存储.当传感器采集到数据时,该条数据被输入引擎,根据模型(业务逻辑)对实时数据进行处理,判断是否满足服务调用条件,若满足则调用,实现主动服务.引擎统计服务触发率、数据吞吐率等信息并上报给监视器供用户分析和实时调整,系统结构如图1所示.
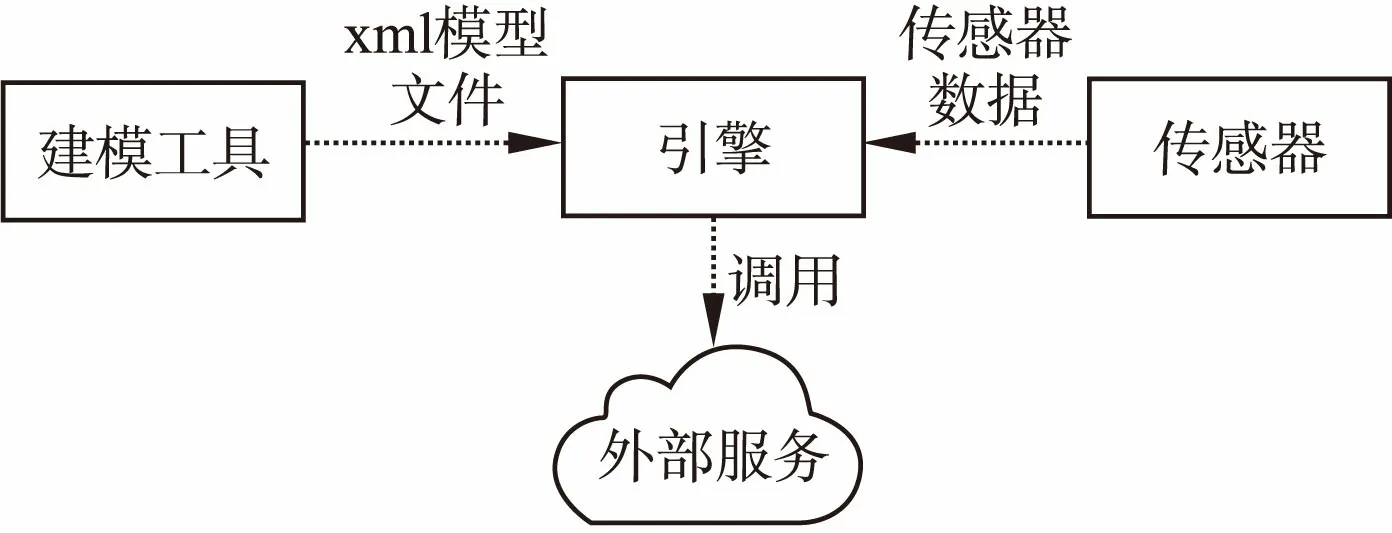
图1 情境感知系统Fig.1 Context-aware system
引擎内部的模块结构如图2所示.引擎主要分为两三个部分,解析器、执行器和监视器.对于建模工具输入的xml文件,由解析器中的XML Parser和Rule Parser共同完成完成解析,并将结果送入ModelStore,后者使用内部的数据结构存储模型信息,并与执行器交互.XML Parser负责解析模型中原始数据、场景、属性、规则、服务的定义,同时记录他们之间的对应关系,维护索引.Rules Parser则负责处理模型中定义的规则并生成规则文件供Drools在执行时调用.考虑到用户可能不具备很好的编程基础,Rules Parser能够处理一些不符合drools语法的规则,如括号的自动补全、逻辑表达式写法的纠正、错误变量命名的修正等,并在不能够修正的情况下给予提示反馈.
在执行器部分,引擎通MQListener订阅底层的消息队列MQ,对于每一条从消息队列中获取的传感器数据,将其输入Mappings模块完成原始数据到情境属性的映射上.通过SceneConstructor完成相关联场景的构造和匹配,这个过程依赖于缓存服务Cache来获取数据快照.对于匹配场景下定义的规则,RulesEngine为规则内属性赋值并执行,在规则满足条件的情况下通过ServiceTrigger调用接口触发对应的外部服务.具体一条传感器数据处理的流程会在第5节详细描述.
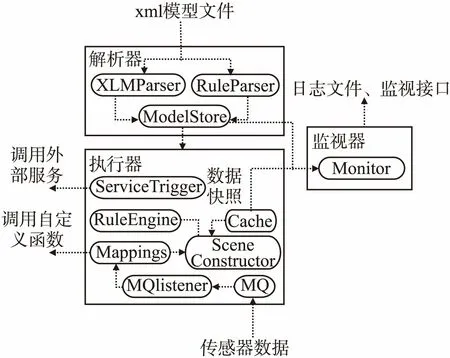
图2 引擎架构Fig.2 Engine architecture
整合进入引擎的监控工具Monitor可以通过日志和外部接口来暴露引擎内部的一些信息,如从ModelStore获取引擎正在执行的模型数量,其内部的场景和规则数量.同时可以结合ModelStore和缓存Cache获取具体某个场景实例内的属性值,以及该场景一段时间内触发的服务.
3 元模型定义
在执行过程中,为了能实现主动服务,需要在模型中定义原始数据、属性、场景、规则、服务等元素.通过对大楼监控模型和粮库通风模型[3]的分析,我们提取出了这些元素之间的对应关系,如图3所示.
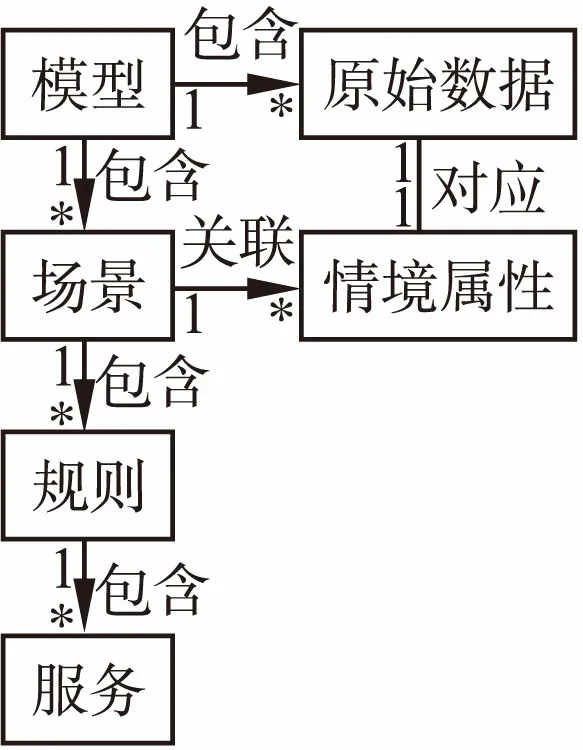
图3 模型-原始数据-情境属性-场景-规则-服务对应关系Fig.3 Relation between model-raw data-attribute- scene-rule-service
图3反映的这种层次结构比较适合被组织成XML格式的文件,便于用户核对以及后端引擎解析.每一个元素具体的定义以及在引擎中的处理方式如下.建模人员在其基础上通过规范的建模过程就可以得到满足不同需求的模型实例.
定义1.情境模型 Model
情境模型头部描述了情境模型的基本信息,包括模型名称和版本号,版本号便于引擎动态的更新modelStore中的模型信息.
定义2.原始数据 Rawdata
原始数据是由消息队列发布的一条传感器数据,会被存储在Cache中.
定义3.情境属性 Attribute
情境属性由原始数据映射而来,描述系统中某个对象的状态.在执行过程中主要由Mappings模块负责处理原始数据到情境属性的映射关系以及合法性判断.dataType,range,rawDataId,mapping>定义了一个情境属性.dataType 代表数据类型,如定义int整型则代表该属性实例值可以进行数学运算.range 代表数据取值范围,用于判断数据的有效性,避免设备故障情况下非法的输入数据对引擎造成的干扰.rawDataId标识出情境属性将被从哪个原始数据映射得到.映射函数mapping通常是一个系统函数,其内部实现可以是一些复杂的运算操作,也可以是对外部接口的访问.举例来说,原始数据Rreader_F1为大楼一层读卡器读到的工卡号,通过Mappings(Rreader_F1)→Arole可以将工卡号这条原始数据映射到情境属性”用户身份”上,得到该情境属性的实例值为“员工”或是“安保人员”,而这个映射过程需要以工卡号作为唯一的输入,调用员工管理系统提供的外部接口得到.
定义4.场景 Scene
场景是一系列情境属性匹配条件的集合,引擎中的SceneConstructor模块负责与场景相关的操作.
表示温度被限定在1~9摄氏度或者刚好为16摄氏度.
定义5.规则 Rule
规则是一种基于事件调用服务的逻辑.在建模过程中,建模人员选取在第一部分定义的情境属性名,组合基本的逻辑表达式来定义符合自然语意的规则,这条规则最终会被引擎解析并被Rules Parser处理成符合Drools语法的drl规则文件,如(Ci1-Ci2>0).
定义6.服务 Service
服务是一种可以被系统调用并具有一定功能的执行流.例如,拨打语音电话给安保人员提醒其去某楼层巡视观察即使一种即时消息通知服务.服务的触发由ServiceTrigger模块完成,在触发过程涉及对外部接口的调用.
表1 元模型与Drools规则文件表达能力对比
Table 1 Comparison of expression ability in Meta Model and Drools rule

表达元模型Drools规则流程控制(如if-else)支持支持数值计算(如a-b*c)支持支持逻辑运算(如a&&b)支持支持数值缓存(如数据有效期1s)支持不支持自定义函数(如时序逻辑)支持不支持业务细化(如定义场景、属性)支持不支持
在一份模型文件被输入到图2引擎中的解析器后,除了规则定义部分会被移交给RuleParser模块来处理成符合Drools语法的规则文件之外,其他部分都会交由XMLParser解析并存储到modelStore当中,图4描述了模型文件中各部分在modelStore当中的存储关系,以及各部分在引擎中都将被哪个模块处理.表1对比了元模型与Drools规则文件两者的描述能力.
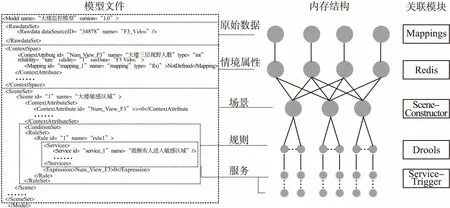
图4 模型文件在ModelStore中的内存结构Fig.4 Digested model file in ModelStore
4 数据处理流程
xml文件被Rules Parser和XML Parser处理后,除了提取各个元素节点并转化成内部的实例之外,还需要使用额外的内存来维护图3中正向和部分反向的对应关系作为内存中的索引,这些索引会在执行过程中被频繁使用.我们定义Set代表多个元素的合集
relation1:Rawdata → Attribute
relation2:Attribute → Set(Scene)
relation3;Scene → Set(Attribute)
relation4:Scene → Set(Rule)
relation5:Rule → Set(Service)
一条传感器数据被送入MQ并发布给引擎的监听器后,首先通过relation1获得与该原始数据对应的情境属性,通过用户定义的Mapping映射函数映完成映射,并存入Cache,同时设置失效时间.接下来要构造这个情境属性以及其关联属性的数据快照SNAPSHOT[12,13].数据快照是在同一个时间节点下,所有相关联情境属性实例的一个瞬时值合集.通过relation2获取所有和这个情境属性关联的场景Set(E),对于每一个场景,通过relation2获取场景下相关联的情境属性集合Set(E).对于所有关联的情境属性,从Cache获取缓存的同一时间间隔内的传感器数据存入快照,至此数据快照构造完毕.之后进入场景构造匹配以及规则执行流程,对于Set(C)中的每个场景,送入SceneConstructor从快照当中取值构造每个场景的实例,并进行场景匹配.SceneConstructor包含一个简单的语法分析模块,可以判断一个情境属性的实例是否满足场景下匹配条件
在构造场景和规则匹配过程中,如果出现涉及场景过多,特别是场景内情境属性过多的情况,SceneConstructor和RuleEngine的执行过程会带来一定的时间消耗.数据快照能够保证引擎在执行过程中所拿到数据是瞬时有效的而不是在执行过程中被送入MQ或者被Cache当做失效值清理掉的空值,这样SceneConstructor和RuleEngine执行时延不会导致规则的误触发或者丢失触发,而会平滑的蔓延到服务触发的时间节点.在涉及120个情境属性的模型中,触发时间的平均时延为12ms.这适用于一些可以容忍触发服务当中中存在轻微时差的场景,如大楼门禁的报警服务、粮库的自动通风服务等.在需要做到瞬时触发多个场景下多个服务的模型,如军用作战模型,则需要开发更高效的规则解析模块代替SceneConstructor和RuleEngine.算法1描述了整体的执行流程.
算法1.引擎处理传感器数据过程.
//For each rawData
//phase One-construct snapshot
snapshot = new snapshot( );
attribute = relation1(rawData);
insertToRedis (atribute);
sceneSet = relation2(attribute);
foreach scene in sceneSet
attributeSet.add(relation3(scene));
foreach attr in attributeSet
snapshot.add(getFronRedis(attr));
// phase Two - go through all relevant scenes
foreach scene in sceneSet
sceneInstance = constructScene(scene,snapshot);
if (determinerMatch(sceneInstance,scene) == false)
continue;
ruleSet = relation4(scene);
foreach rule in ruleSet
ruleInstance = constructRule(rule,snapshot);
if(droolsMatch(ruleInstance,rule) == false)
continue;
serviceSet = relation5(rule);
foreach service in serviceSet
triggerService(service);
5 引擎性能测试与分析
引擎被部署在一台单核CPU 2.20 GHZ,内存4G,操作系统版本为Centos 6.5 64位的服务器上.引擎内部使用Maven来组织各个模块,由Spring3.0 管理各个服务实例.缓存服务(Cache)使用Redis 3.2.6,消息队列(MQ)使用ActiveMq 5.5.0,规则引擎(RuleEngine)使用Drools 6.5.0.使用单消息节点,主从结构的Redis,使用全局的JedisPool连接池来加速与Redis的交互操作.同时缓存了Drools的会话连接和knowledgeBase,避免每次调用规则引擎都重新编译drl规则文件.在模型更新时才去更新该全局的knowledgeBase.
我们通过两个实验来测试引擎的性能表现.实验1对比在使用sceneConstructor模块划分场景和完全使用Drools规则描述模型时数据处理效率的差异.实验2测试场景下的赋值条件个数与数据处理效率的关系.
实验1.在第3节元模型定义中提到每个场景内部包含了该场景内情境属性所需满足的条件,这些匹配条件将不同场景做划分,作为可复用的公共条件缩短了规则的长度,同时可以帮助SceneConstructor模块在数据处理过程中快速定位到某几个场景下,减少Drools所需遍历从属规则的条数.因此建模过程中这些赋值条件的数目和精确程度将极大影响引擎执行的效率.假设总共有k1个场景,每个场景下平均定义了n个情境属性的条件,每一个情境属性平均会出现在k2个场景下,相同情境属性在不同场景下的碰撞率为p(即一条数据对应的情境属性同时满足两个判断条件的概率).那么对于一批符合场景1的数据,其也满足场景2所有判断条件的概率s为
(1)
在k1=6,k2=3,p=0.5的取值下,n(0)→n(3) 带来 S(1)→S(0.0156),极大减少了场景之间重合的概率(即相似度),减少了对Drools的输入.因此可以初步推断在定义一个场景E=
对此我们进行第一个实验对以上推测进行验证.我们首先构造仅包含1个场景,场景下包含20条规则的情境模型送入引擎解析执行,随后开发测试脚本批量模拟传感器数据送入消息队列.每一条传感器数据都会被控制在模型中原始数据定义的有效值范围之内,并遵从泊松分布,目的是让规则的触发尽可能的随机.我们统计在引擎执行5分钟当中处理一条传感器数据平均耗时.之后分多次更新模型,在模型内定义更多的场景并测试记录.对于规则匹配后的服务触发操作,因服务内容不同而会受到网络等外部因素的干扰,因此在测试过程中被省略.该部分测试完毕后,我们将模拟的每一个模型完全使用Drools规则文件描述,即将场景下的属性条件判断全部写入Drools规则中.在处理时跳过SceneConstructor模块,重复之前的测试步骤并记录测试结果.
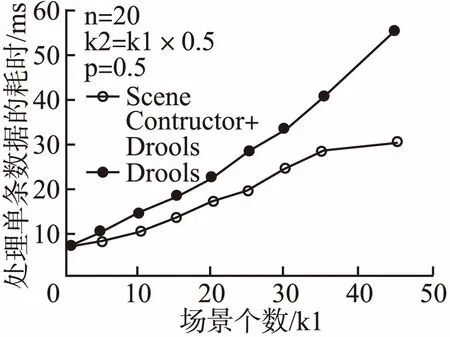
图5 SceneConstructor带来的性能提升Fig.5 Performance gains from SceneConstructor
图5验证了公式(1)的推导结果,可以初步得出结论,即划分场景可以带来性能的优化,且随着场景和规则数量的增多这种效率提升更为明显.
实验2.从算法1中可以发现,随Va的增多,每一条数据能够关联的场景数量也会增加,导致在Drools执行前场景匹配阶段中送入SceneConstructor的关联属性也在增加,反而带来时间损耗.因此单纯增加Va的个数并不能持续提升效率.为此我们进行了第二个实验.我们用包含7个场景,20个情境属性,30条规则的大楼模型进行测试.得到数据执行效率与场景下属性赋值条件Va的数量占该场景所有关联属性百分比α的关系,结果见图6.
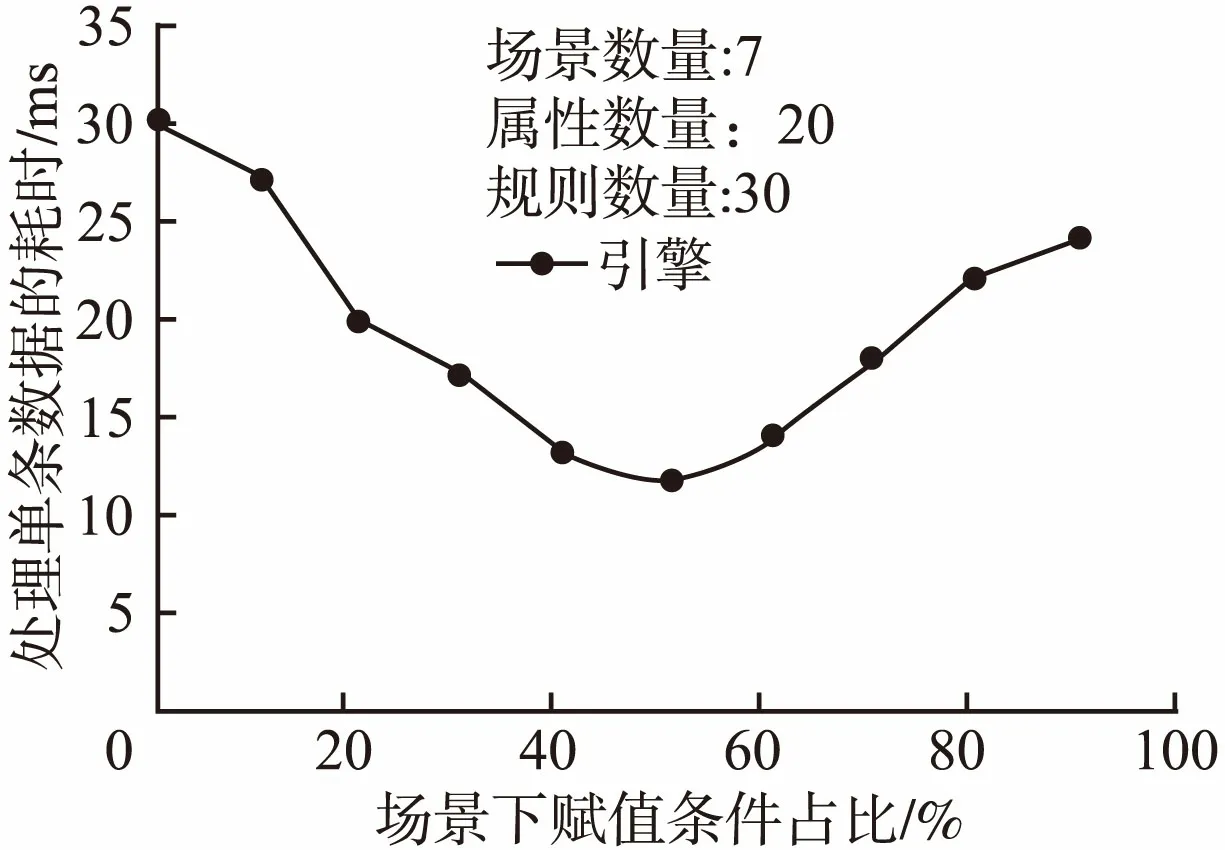
图6 数据处理效率与场景下赋值条件占比的关系Fig.6 Relation between condition ratio and engine performance
当α=0%时,模型退化成为不为场景属性赋值的情况,效率较差.随着α上升,SceneConstructor模块发挥作用使得效率提升,在α接近40%时效率达到最优.α超过40%后,执行效率下降,在不同的模型中这个阈值不同.这个测试结果说明,在定义场景中属性的判断条件Va时,应该尽量选取关键的,有区分性的情境属性来构造判断条件,不能盲目的加入Va.如在大楼模型下的“办公区”场景内,“楼层数”属于比较有区分性的情境属性,我们可以为其赋值Vfloor≥3,而“视野内人数”虽然从属于该场景,但并没有为其构造判断条件如Vview_num≥0的必要.
6 小 结
本文提出了一种面向主动服务的情境感知引擎,与开源的规则引擎如Drools相比,该引擎可以支持更丰富的模型描述语言,同时在处理短时间内大量数据时也表现出较好的执行效率和准确率.在建模过程中,开发人员只需要为建模人员提供原始数据到情境属性的映射函数Mappings,而建模人员通过建模工具提供的前端界面的组件拖拽、连线和简单规则输入即可完成模型建立,并将模型文件输入引擎进行主动服务.
引擎开发完成之后,在相关工作[4]中建立的储粮模型和大楼监控模型都已经被移植到该系统上进行后续维护.在一些较为复杂的系统如军用作战系统中,情境感知系统需要提供更多的功能如场景之间的切换,规则之间的跳转,以及支持非瞬时场景下的规则触发,那么需要通过更复杂的数据结构和执行流,引入状态机来实现.同时当数据量过大,需要将系统部署在多机协同处理,这也是我们下一步面临的挑战.
