并行绘制系统中基于多响应随机森林的负载估计
2019-01-23段思羽贾文娟
段思羽,贾文娟
(四川大学计算机学院,成都 610000)
0 引言
大型实时绘制系统中为解决单个GPU无法流畅显示的问题,通常采用的分配任务方法主要有:①静态划分任务[1],即每一帧以同样的方式划分任务,很难适应动态变化的绘制场景;②基于帧间相关性划分任务[1],根据前一帧负载分布情况来调整下一帧任务分配,这种方法在场景产生突变的情况下不能得到良好的效果。这些方法都有一个共同的缺点——不能在某一帧绘制前准确的知道负载分布情况。
如果可以估计当前要绘制的一帧在屏幕空间中负载的大致分布情况,就能够比较容易的划分任务。对于某一帧,我们能够得到绘制场景相关的一系列特征X=X1,X2,…,Xm,Xm+1,Xm+2,…,Xm+k,其中X1~Xm为绘制场景特征,Xm+1~Xm+k为划分位置特征。本文假设并行绘制系统的绘制节点数N固定,基于屏幕空间划分任务的模式固定,旨在用机器学习模型估计出每个子节点的负载Y=Y1,Y2,…,YN。这是一个多响应的回归问题,考虑到随机森林适合处理高维数据的回归问题,并且抗过拟合的能力强,采用多响应的随机森林(MRF)[2]作为预测负载的模型。另外,由于绘制系统中采集的数据分布并不均衡,本文借鉴了数据增强(Data Augmentation)[4]的方法对随机森林算法中抽取Bootstrap的方法进行了改进。
1 算法综述
1.1 多响应随机森林
由Breiman[4]等人提出的随机森林是由多棵树集成的学习器,可用作回归数据的预测。回归树框架由四个部分组成:①是否为一个二进制(或分裂)问题,通过一系列预测因子划分空间。通过根据这些分割而创建的子空间被称为节点。没有任何后代节点的节点是叶子结点。②节点纯度的衡量,通常与样本响应的方差有关。③节点划分函数φ(s,t),可以用于评估每个节点t的每个分割位置s,最佳的分割位置是最优化φ,即所得到的子节点中的响应分布在所有竞争分裂中是最同质的,同质性通过杂质测量评估。
在单响应数据集中,用xij和yi分别表示预测因子和响应。考虑包含数据集子集的节点t,我们的目标是将t分为两个子节点,做节点tL和有节点tR,设j是连续或有序分类预测因子的索引。允许的分割点位置是在tL=i∈t:xij≤c,tR=i∈t:xij>c范围内的顺序在所有可能的值上产生不同的tL,tR;对于无序分类预测变量,允许所有分类为不相交的类别子集。节点的纯度衡量依据平方和其中μ(t)是节点t中y的平均值。此时分割函数为:

考虑多个响应的数据,鉴于响应之间的预期依赖性,可以通过同时分析所有响应来实现解释性和预测性增益。简单起见,我们假设响应数量相同,预测因子是“基线”变量,不随k变化。将回归树扩展到多个响应所需的只是修改分割函数。一个自然的公式是用协方差加权模拟代替节点纯度测量:

这里η表示表征所描述的协方差结构的参数。使用(2)根据(1)创建多响应分割函数。对多响应回归树的每个叶子节点的预测值是该叶子节点中的数据响应的平均值。
1.2 数据增强
丰富的高质量数据是伟大的机器学习模型的关键。但是良好的数据不会在树上生长,而稀缺性会阻碍模型的发展。解决缺乏数据的一种方法是数据增强(Data Augmentation)。程序化数据增强的智能方法可以将训练集的大小增加10倍或更多。更好的是,模型通常会更加健壮(并防止过度拟合),并且由于更好的训练集,甚至可以更简单。有许多方法可以增加数据。最简单的方法包括添加噪声并对现有数据应用转换。插补和尺寸缩减可用于在数据集的稀疏区域中添加样本。更先进的方法包括基于动态系统或进化系统的数据模拟。
大多数机器学习分类算法对数据的不平衡敏感。让我们考虑一个乳腺癌数据集极端的例子:假设我们有10个恶性样本和90个良性样本。已经在这样的数据集上训练和测试的机器学习模型现在可以预测所有样本的“良性”并且仍然获得非常高的准确度。不平衡的数据集会将预测模型偏向更常见的数据。
为了防止过拟合,让模型更加鲁棒性,可针对不平衡的数据采用数据增强的方法进行改进。
2 实现细节
2.1 特征选取
本文通过一个绘制帧的信息 X_1,X_2,…,X_m,以及某一划分轴位 X_(m+1),X_(m+2),…,X_(m+k),预测得到每个节点的负载大小Y_1,…,Y_N。其中X_(1~m)根据绘制场景中影响绘制时间的因素决定,例如视点位置、视点朝向、光源信息等;X_(m+1~m+k)表示所有划分轴相对屏幕原点的坐标位置。以三个绘制节点为例,基于屏幕空间划分任务的模式固定如图1所示,屏幕的高和宽分别为W、H,用两条划分轴即可分割屏幕,此时有特征 X_(m+1)和 X_(m+2);此时响应值为三个节点的绘制时间。
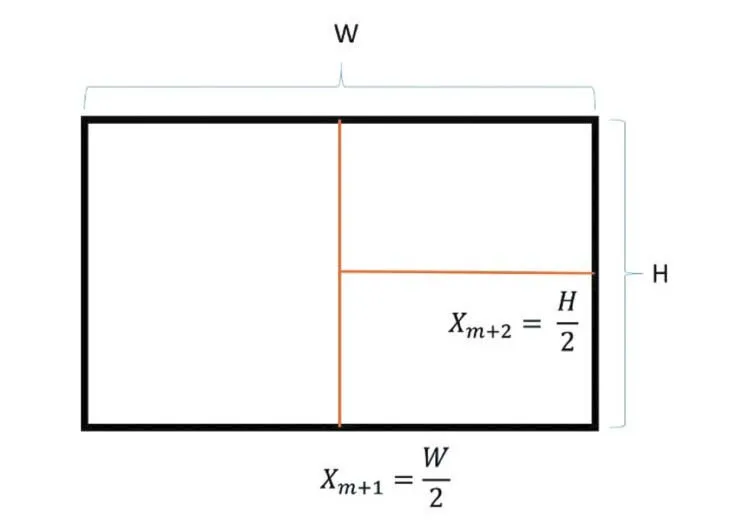
图1 三个绘制节点下的划分模式
2.2 机器学习模型
对于此回归问题首先想到的方案是用绘制帧信息和子屏幕位置坐标分别预测同一帧不同子窗口的绘制时间,此方案可以运用原始的单响应回归森林模型来拟合数据。然而这个方案有一下几个缺点:①采集训练数据时,同一帧对于每种划分的每个窗口都要采集数据,导致数据集数量很庞大;②估计一帧的负载分布需要对每个子窗口都预测一次,效率变低;③数据集中有大量的数据绘制帧信息特征是相同的,原始随机森林模型不能很好地处理这种情狂,导致预测准确性下降。
以三个绘制结点为例,单响应方法对同一帧的一种分布需要采集3条数据;若采用多响应回归森林,所需的数据量就会变为原来的1/3,同理在估计负载分布时,使用模型预测的次数也将变为原来的1/3。在效率提高的同时,准确性也得以保障。
2.3 不平衡数据处理
通过对绘制场景中大规模采集的数据进行分析,我们发现数据的分布很不均衡,每一帧的绘制时间y分布从 10ms~170ms,其中绝大部分数据分布在10ms~50ms之间。然而我们更期望将绘制时间大的帧有良好的预测能力。用这样不平衡的数据训练得出的模型容易出现过拟合的现象,欠缺对数量少的数据的预测能力。
随机森林中使用了bagging[6]的方法,每棵树的训练数据为随机有放回的从原始数据集中抽取数量与原始数据集相同的数据作为训练集,此方法会使每棵树的训练数据中有约2/3的数据被选中从而更偏向于一些数据,但整体上来看并未对某些数据有所侧重。为了使我们的模型更侧重于绘制时间大的数据,借鉴等人He Kaiming[7]处理不平衡数据的方法中Label Shuffling的类别平衡策略,我们针对随机森林中bagging的步骤进行了改进。步骤如下:首先对原始数据集按照响应值的大小进行排序;然后计算每个区间的数据数量,并得到数据最多的那个区间的数据条数,更具这个最多的数据数量,对每个区间都产生一个随机排列的列表;然后用每个区间的列表中的数对各自区间的数据数求余,得到一个索引值,从此区间中选取数据,生成此区间的随机列表;然后把所有区间的随机列表连在一起,做Random Shuffling,得到最后的数据集,用这个数据集进行训练。此过程如图2所示。
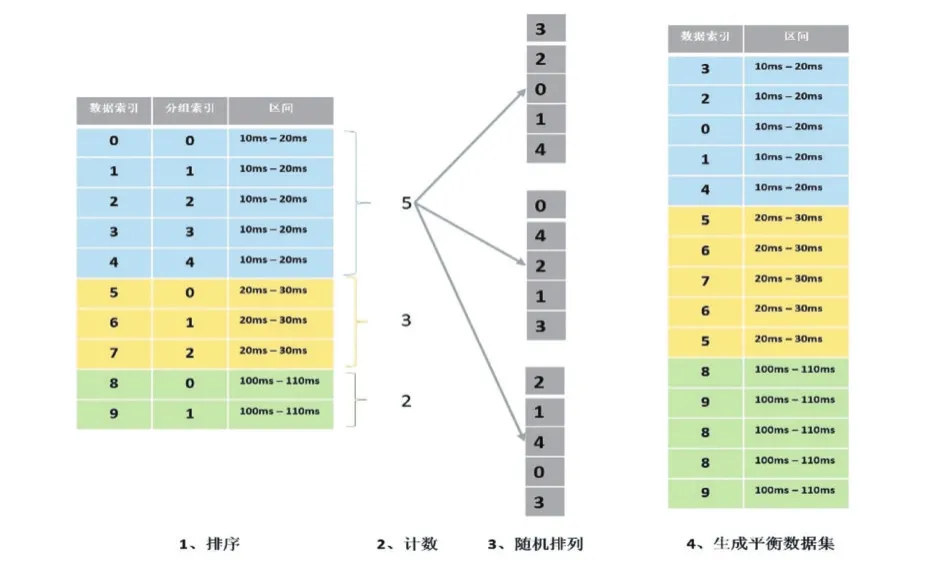
图2 选取训练数据过程
3 实验
本文研究的目的在于准确高效地估计绘制帧的负载分布情况,实验针对四个绘制结点的情况进行负载分布估计,与单响应方法的效果做对比。
实验场景:实验场景包含LLL算法、SSAO算法等绘制算法;所采集的绘制信息特征有311维(包括视点位置、视点朝向、光源位置等),划分轴信息有3维。
实验结果对比:
对于同一条漫友路径下采集的训练集,分别用单响应和多响应回归森林的模型做实验。其中单响应的训练集包含数据80,000条、多响应的训练集包含数据20,000条。对比预测偏差Biass=abs(Yi-Y‘i),以及对所有数据的预测时间。单响应模型的预测最大偏差为5.25ms,多响应的预测最大偏差为3.23ms;对所有数据的预测时间单响应情况下为10.0min,多响应情况下为7.8min。本文采用的模型在准确性和效率上均有明显优势。
4 结语
本文使用多响应随即森林模型,并结合数据增强的方法,提出一种可以根据当前帧的信息预测某一划分方式下的负载分布的方法。打破了“当前帧绘制之前无法得到负载分布”的假设,在预测准确性和效率上都有良好的效果。此方法为下一步在并行绘制系统中实时绘制做准备,在保证预测准确性的情况下,未来将继续研究如何利用学习模型所预测的分布进行调度。
