BP神经网络与支持向量机模型在智能手机对大学生影响中的评价研究
2019-01-23士紫薇张仕光李燕培晋洁牛永博范静
士紫薇,张仕光,李燕培,晋洁,牛永博,范静
(河南师范大学计算机与信息工程学院,新乡453007)
0 引言
手机的面世和不断地更新换代,极大地方便了我们的生活。但同时,人们对手机的依赖性也前所未有地增加。中国是世界上近视发病率最高的国家之一,近视眼人数居世界第一。2017年,世界卫生组织研究报告称,中国近视患者多达六亿。其中,我国高中生和大学生的近视率均已超过七成,并逐年增加,中国青少年近视率高居世界第一。
学生群体对手机过度的依赖是显而易见的。对于手机不离身的学生来说,娱乐远远大于工作。在这种平均每六分钟低头一次的“低头族”时代,手机除了为我们带来了便捷,还带来了什么?
在对这一现象的研究中,本文基于BP神经网络[1]和支持向量机对其进行分析和研究。BP神经网络实质上实现了一个从输入到输出的映射功能,具有较强的非线性映射能力和高度自学习和自适应的能力。而且,BP神经网络还具有将学习成果应用于新知识的能力和一定的容错能力。将此方法应用于智能手机对大学生影响的研究中,颇为有用。
神经网络在半个世纪以来,理论和技术基础已达到了一定规模,就应用的技术领域而言有语言的识别、理解与合成,优化计算,模式识别,知识推理专家系统与人工智能[2]等。与传统的统计方法相比,神经网络具有很强的学习能力,极大地提高了分类的精度和预测的准测度。
本文将以本校大学生群体为研究对象,通过网上发表调查问卷,收集手机对大学生视力方面影响的数据,并利用BP神经网络和支持向量机[3]等工具,研究和分析智能手机对大学生的影响。
1 数据分析与处理
本次收集数据的方式为线上线下问卷调查,为方便答题和节省时间,问卷的设计主要以选择为主。调查对象为高校学生。
(1)基本信息统计
100名大学生中,男生占32%,女生占68%。其中大一学生占12%;大二学生占19%;大三学生占65%;大四学生占4%。
(2)使用习惯
91%的被调查者表示手机是他们的必带物品。被调查者中只有2%的表示一直坚持做眼保健操、滴眼药水等保护眼睛的习惯,从来不做的占比31%。大部分被调查者将手机放置在眼前30厘米以内的位置。专家建议,在使用手机眼睛与手机应保持30~50cm的距离,而在调查中能做到的仅有一人。
(3)使用目的
在上课时,59%的被调查者会经常使用手机,用于听音乐、打游戏、购物、查资料、看小说等方面。没有一位被调查者表示课堂上从不使用手机,其中,仅有29%表示课堂上使用手机是用来查知识。
(4)使用频率
据数据显示,对于手机一天的使用频率来说,38%的被调查者每天使用手机时间大于6小时,晚上玩手机的大部分时长都在2小时之内,10%的时长会大于2小时;84%的被调查者晚上熄灯后会继续玩手机,大部分的被调查者在4小时内会感到疲惫;而34%的被调查者表示玩手机长于4个小时后才会感到疲惫。
(5)视力下降程度
据数据显示,34%的被调查者的视力下降的度数小于100度,15%的被调查者视力下降的度数大于400度。
在本次调查中,为保证调查的可靠性,我们分别对四个年级,共100名在校大学生进行了调查,并设置了5个指标作为分析依据。其中,因素一:大学生在白天玩手机的时长;因素二:大学生在晚上玩手机的时长;因素三:手机的放置距离;因素四:代表大学生玩手机后对眼睛的保护频率;因素五:大学生玩手机感到疲惫的时间,而结果就是视力下降的实际值。
为方面统计和编码实现功能,将各个因素划分为四个等级,并合理取值
原数据形式如图1所示:

图1 原数据形式
在MATLAB中对其进行归一化处理,如图2所示。归一化函数采用MATLAB中自带的函数mapminmax。此函数默认将数据归一化到[-1 1],在这里选择将其归一到(0,1)。归一化可以使后面数据的处理方便,其次是保正程序运行时收敛加快。mapminmax(Input,0,1)实现输入数据归一化;mapminmax(Output,0,1)实现输出数据归一化。将数字归一化,可以避免不同数量级的数字之间相互影响,也可以加快网络学习速度。
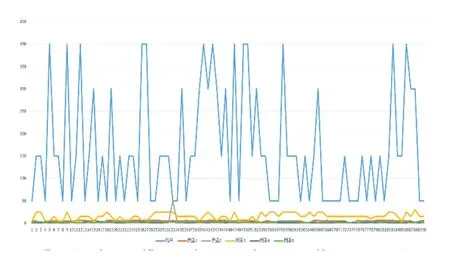
图2 原数据
归一化处理后的数据格式如图3所示:

图3 归一化处理后数据形式

表1 等级划分

图4 归一化处理后数据
2 BP神经网络与支持向量机模型建立
2.1 BP 神经网络模型建立
(1)BP神经网络模型结构

图5 神经网络基本结构
xj表示输入层第 j个节点的输入 j=1,2,...,M;
wij表示隐含层第i个节点到输入层第j个节点之间的权值;
θi表示隐含层第i个节点的阈值;
F(x)表示隐含层的激励函数;
wkj表示输出层第k个节点到隐含层第i个节点之间的权值, i=1,...,q;
ak表示输出层第 k个节点的阈值, k=1,...,L;
Y(x)表示输出层的激励函数;
ok表示输出层第k个节点的输出。
(2)关于手机使用所导致的视力下降程度的神经网络预测模型
①模型结构
本课题的目标为通过神经网络模型分析手机对大学生视力的影响,问题核心是找到主成分分析除的特征变量(手机使用时长、黑暗环境下手机使用时长、放置距离、护眼行为频率、感到疲惫时间)与导致视力下降程度之间的映射关系,这里确定网络模型的输入为已选定的五个特征变量,输出为加深程度的范围。通过问卷调查收集的相应的数据,我们将这五个因素具体量化,并将对应的视力下降程度分四个等级。100份有效数据中,95份用来训练,5份用来预测。
对BP神经网络进行指定参数的训练,这里采用traingd(梯度下降算法)、traindm(栋梁梯度下降算法)、trainda(变学习率梯度下降算法)、traindx(变学习率动量梯度下降算法)。调用newff函数,传输函数使用tansig、purelin,选取“trainlm”函数来训练,其算法对应的是Levenberg-Marquardt算法。利用神经网络进行预测,首先需要根据输入输出来确定网络的结构。由以上讨论,需有5维输入、一维输出,并选择中间层隐节点为7,因此确定此BP神经网络为5-7-1的结构。
②参数的初始化
调用MATLAB神经网络工具箱,直接可初始化输入层与隐含层之间的权值、输入层与隐含层之间的阈值、输出层与隐含层之间的权值、输出层与隐含层之间的阈值。而初始值为随机选定的,在后来训练数据的过程中,根据网络预测误差调整网络的权重和阈值[5]。具体参数设置如下:
输入样本数 Input_Num=95,预测样本数量Sim_Num=5
输入节点Input_Num 5
中间层隐节点Hidd_Num 7
网络输出维度Out_Num 1
最多训练次数MaxEpochs 50000
学习速率lr 0.01
目标误差 E0 0.45*10(-2)
初始化输入层与隐含层之间的权值:
W1=0.5*rand(Hidd_Num,Input_Num)-0.1
初始化输入层与隐含层之间的阈值:
B1=0.5*rand(Hidd_Num,1)-0.1;
初始化输出层与隐含层之间的权值
W2=0.5*rand(Out_Num,Hidd_Num)-0.
初始化输出层与隐含层之间的阈值
B2=0.5*rand(Out_Num,1)-0.1;
③测试和预测
用测试数据测试神经网络的性能。用剩下五组数据当做被预测数据。比较误差,评价此模型的准确性。
2.2 支持向量机预测模型
支持向量机和支持向量机回归[6]是统计学习理论的重要组成部分。和感知机模型一样,SVM(支持向量机模型)也是旨在求出n维空间的最优超平面将正负类分开。这里的达到的最优是指在两类样本点距离超平面的最近距离达到最大,间隔最大使得它区别于感知机学习,SVM中还有核技巧,这样SVM就是实际上的非线性分类器函数。
假设给定一个特征空间上的训练数据集:

其中,表示N个样本实例,xi为第i个特征向量(实例),yi为 xi的类标记。xi∈X=Rn,yi∈Y={+1,—1},i=1,2,3,…,N,表示N个样本实例,xi为第i个特征向量(实例),yi为 xi的类标记。
量机模型参数的设置:svm类型选择2(one-class-SVM),核函数使用径向基函数是高斯核函数(RBF核),其中函数值设置为0.07,degree设置为3,coef设置为0。
其中C与g采用交叉验证选择最佳参数。对于参数与核函数的设置如前面所叙述方法选取。
另外针对研究问题这里采用间接法的SVM多分类
(1)间接法:
主要是通过组合多个二分类器来实现多分类器的构造,常见的方法有one-against-one和one-against-all两种。
(2)一对多法(one-versus-rest,简称 OVR SVMs)
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
假如有四类要划分(也就是4个Label),它们是A、B、C、D。于是在抽取训练集的时候,分别抽取
①A所对应的向量作为正集,B,C,D所对应的向量作为负集;
②B所对应的向量作为正集,A,C,D所对应的向量作为负集;
③C所对应的向量作为正集,A,B,D所对应的向量作为负集;
④D所对应的向量作为正集,A,B,C所对应的向量作为负集。
使用这四个训练集分别进行训练,然后得到四个训练结果文件。在测试的时候,把对应的测试向量分别利用这四个训练结果文件进行测试。最后每个测试都有一个结果 f1(x),f2(x),f3(x),f4(x)。于是最终的结果便是这四个值中最大的一个作为分类结果。
3 实验结果分析
为了增加预测结果的准确性和模型的可行性,分别用可高度非线性化映射的BP神经网络和支持向量机对人工数据进行训练预测以及分类。
3.1 基于神经网络预测分析
对调查问卷所得的数据进行整理以及对主成分进行数据化。共收集得100组数据,使用95组数据作为训练样本,所剩作为测试样本,用以测试训练的函数的性能。采用2.1小节中的描述算法确定参数以及选取训练函数。
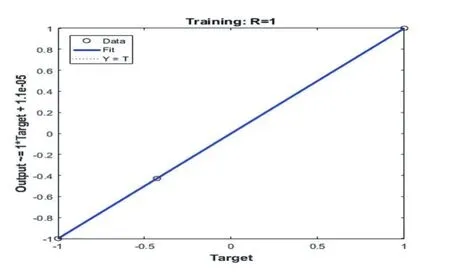
图6 数据训练相关系数

图8 训练数据的梯度和均方误差之间的关系图
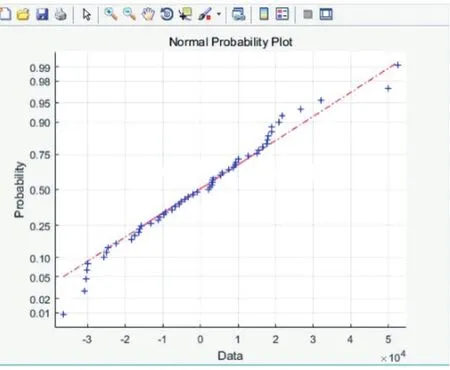
图9 残差的正态的检验图
由平均均方差与残差以及training曲线可观察到BP算法训练后的网络的逼近能力与对数据的泛化都有不错的效果,可以调用训练完成的网络准确预测出综合因素影响下的结果。
3.2 基于支持向量机预测结果及分析
针对研究问题采用SVM算法对数据非线性建模,训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。即把问题归结为多次分类的二分类问题,先将 50~150标签为 1,150~400标签为 0,每组数据五十份,完成之后再次对一类数据进行分类,重复至完成。
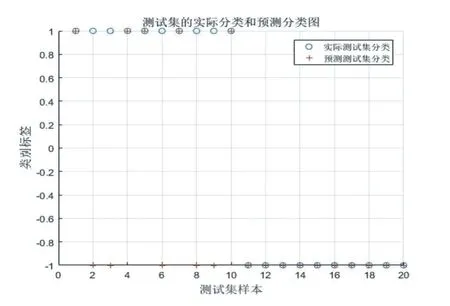
图10 SVM对数据的分类和预测如果图
由图观察第一次二分类结果图,问题基于SVM算法对数据的分类以及分类后的预测有较好的反映。从而可根据此算法依次对所给数据多次分类选择出综合因素影响的结果区间。
预测性能评价指标[7]:
预测性能的评价,一般用基于预测值y1’和测量值y2间的相似度来度量。即:
最常用的评价度量的指标是平均值绝对误差(Mean Absolute Error,MAE);相对平均值绝对误差(Mean Absolute Percentage Error,MAPE;根平方值误差(Root Mean Square Error,RMSE);标准误差(Standard Error of Prediction,SEP),是预测误差中应用比较广泛的方法。
对神经网络模型预测以及SVM分类预测性能的指标的对比。这里选取Accuracy(准确率),均方误差(Mean-Square Error,MSE),以及常用的评价度量的指标是平均值绝对误差(Mean Absolute Error,MAE):
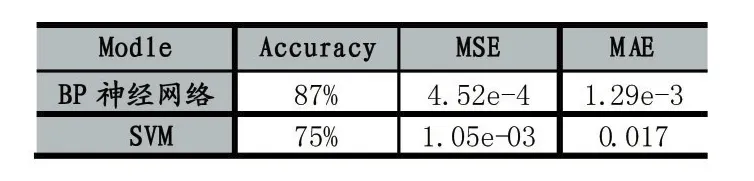
表2
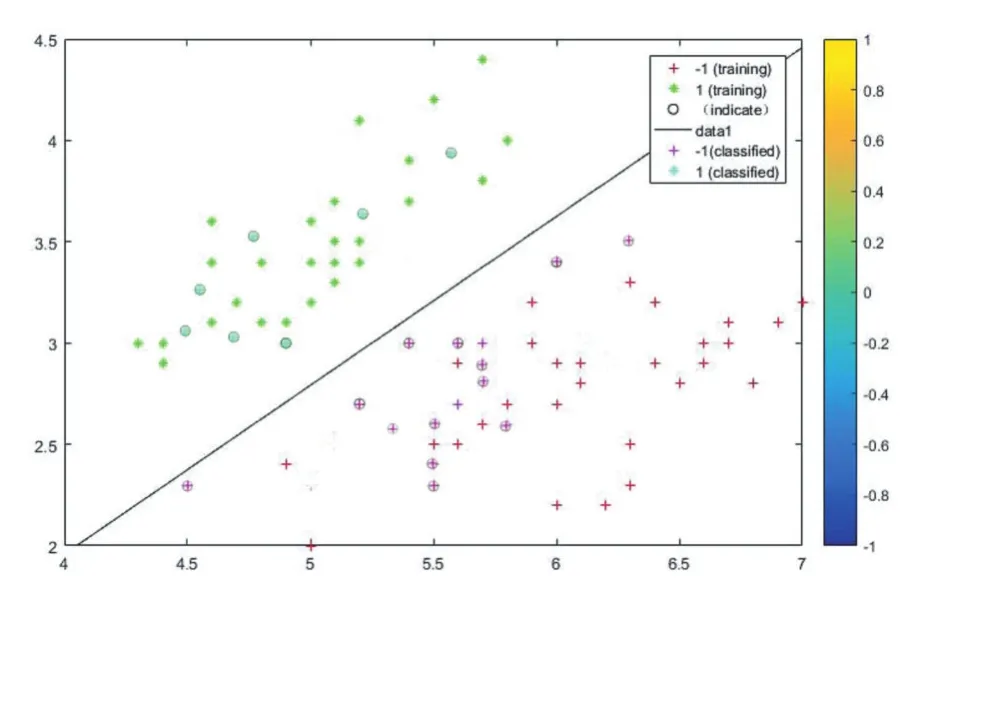
图11 SVM模型分类预测结果
