基于卷积神经网络的P300事件相关电位分类识别
2019-01-21丑远婷邱天爽钟明军
丑远婷 邱天爽 钟明军
(大连理工大学电子信息与电气工程学部,辽宁 大连 116024)
引言
近年来,基于P300事件相关电位的脑机接口(brain computer interface, BCI)系统得到广泛的重视和应用。它通过分析处理在不同视觉刺激下人体脑部产生的脑电(electroencephalography, EEG)数据,检测P300事件相关电位,进而转换成相应的指令来实现对外部设备的操控。其中,P300事件相关电位的分类识别在BCI系统中占据着至关重要的地位。在字符拼写脑机接口系统中,P300事件相关电位是人体接受视觉刺激后在脑部头皮中可检测到的潜伏期约300 ms左右的正向电位。由于其波幅小、信噪比低,常常淹没在自发脑电和伪迹干扰中,因此P300事件相关电位不易被检测。高效准确地从EEG数据中分类识别出P300事件相关电位,对于BCI系统的正常运作具有重要的意义。
近年来,文献中报道了较多P300事件相关电位的分类识别方法。其中,文献[1]介绍了早期的分类方法,这些方法主要基于信号的时域特征来对信号进行处理,通常将固定时间长度窗口内提取到的EEG波形的最大幅度差、波形面积以及待识别信号与P300事件相关电位模板信号的相关系数作为分类特征。早期研究方法仅仅考虑到时域信息而忽略频域等方面的信息,分类方法比较简单,因而对于P300信号识别正确率仅有80%。更多的研究者致力于EEG信号的特征提取方式和分类模型的研究。Liu等利用频带功率和逐步判别分析(stepwise discriminant analysis,SWDA)计算的P300幅值共同作为分类特征,并使用受试者工作特征(receiver operating characteristic,ROC)曲线下的面积(area under curve,AUC)作为度量标准[2]。在自定义的刺激范式下,其AUC可达0.981;但由于计算频带功率需要的信号段较长,因此比较耗时。Kaper等提出了一种基于支持向量机(support vector machine, SVM)的P300信号识别方法,直接将采集到的EEG信号作为特征来训练支持向量机,其P300电位的识别正确率可达84.5%[3]。为了提高单个支持向量机的字符识别正确率,Rakotomamonjy提出一种基于集成支持向量机的P300识别方法,虽然识别精度有所提高,但是计算复杂度高,加大了分类训练难度和时间[4]。Li将经过独立成分分析(independent component analysis, ICA)去除伪迹后的数据送入SVM分类器中提高分类效果[5],虽然经过ICA预处理后的信号更容易准确识别,但是在数据处理上需要消耗一定的时间。随着人工智能的飞速发展,由于深度学习强大的特征提取能力,使其在图像、语音、生物信号处理等领域中具有广泛的应用[6-7]。Cecotti首次实现了用深度学习对P300事件相关电位的分类[8],然而实验次数为10次时,其字符的识别正确率还达不到90%。在此基础之上,Liu在训练时加上batch normalization技巧[9],很大程度地提高了网络对P300事件相关电位识别正确率。在实验次数为15次时,字符识别正确率可达98%;但是在实验次数较少的时候,其识别结果仍有待提高。
综上所述,目前大多数算法的P300事件相关电位分类正确率有待提高。笔者基于经典的卷积神经网络,对网络的结构进行研究改进,在网络的第二层上用3个并行结构的卷积层代替网络中单个串行连接的卷积层来处理数据,提取到数据的多样化特征,进而使用组合后的特征实现P300信号的分类,并同时改变对数据的预处理方式,使得字符识别的正确率得到一定提高。
1 实验方法
1.1 实验
1.1.1实验过程
P300事件相关电位通常采用oddball刺激范式诱发得到。在P300拼写范式中,受试者面前有一个由36个字符组成的视觉刺激器(见图1),它将常用的36个字符排列成一个6行×6列的矩阵。在实验前,受试者被告知视觉刺激器中某一指定字符为目标字符,每次实验随机指定字符。在实验过程中,受试者需要紧盯视觉刺激器中的目标字符位置,同时视觉刺激器中的任意一行或列以固定频率随机闪烁。若目标字符所在行或列发生闪烁时,受试者会受到视觉刺激,并在接受刺激300 ms后在大脑头皮中检测到正向的P300事件相关电位(P300 event related potential, P300 ERP);若非目标字符所在行或列发生闪烁,则在人脑头皮中检测到的EEG数据是非P300事件相关电位(Non-P300 event related potential, N-P300 ERP)。每次实验会将所有行和列随机闪烁一次,共计12次,其中有2次包含目标字符。为保证所获取信号的质量,每次实验之间都有一定的时间间隔,提供给受试者休息时间,以防产生视觉疲劳。在字符拼写器完成字符识别的过程中,如果能够确定当前采集到的脑电信号是P300 ERP,再根据当前EEG信号的所在行和列,就可以确定出目标字符,进而完成字符的拼写,达到人体与外界沟通交流的目的。
1.1.2EEG数据
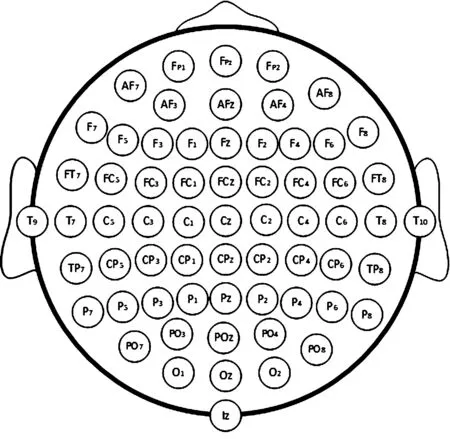
图2 电极分布Fig.2 Electrode distribution

图1 视觉刺激器Fig.1 Visual stimulator
实验数据源于Wadsworth研究中心NYS Department of Health 提供的 BCI Competition III A组竞赛数据。该实验使用的刺激范式简述如下:视觉刺激器以频率5.7 Hz随机闪烁其行或列,即每次闪烁持续100 ms,中间间隔75 ms进入下一次闪烁,一次实验闪烁12次,每次实验对应同一个目标字符,持续时间2.5 s。每个目标字符重复实验15次。实验通过一个简易便携的脑机接口研究开发平台BCI2000获取到EEG数据,使用符合10/20国际标准的64导联记录EEG数据,电极为 Ag/AgCl 材质,电极阻抗不超过5 kΩ,其放置位置如图2所示。采集设备的采样频率为240 Hz,每个数据样本都以刺激时刻0 ms开始,到1000 ms结束。将获取的EEG数据经过0.1~60 Hz的带通滤波处理后得到A组数据,这样每次刺激下的样本数据的大小为240×64,其中240代表单个样本数据时域上的采样点数,64代表单个样本数据的通道数。竞赛中将A组数据分成训练集和验证集,其中分别含有85和100个字符,样本量分别为15 300(12×15×85=15 300)和18 000(12×15×100=18 000)。关于数据的详细介绍可参见文献[10]。
1.2 方法
1.2.1数据预处理
为了更好地分类识别P300 ERP,笔者在频域和时域上对数据进行预处理。在频域处理中,由于P300 ERP频域特性主要分布在0.1~20 Hz,而采集到的EEG数据会受到工频干扰和伪迹干扰的影响,因此将EEG数据先后通过一个3阶截止频率为0.1 Hz的高通滤波器和一个6阶截止频率为20 Hz的低通滤波器。在时域处理中,由于P300 ERP在视觉刺激300 ms后产生,故将EEG数据中的每通道数据都在时域上截断,取刺激后0~667 ms数据(即数据长度为160个采样点)来处理分析。这样,每次刺激后得到的EEG数据可以看成一个160×64的矩阵。在BCI Competition Ⅲ的实验方案中,由于每次实验中所有行和列都会遍历闪烁一次,而包含目标字符的行与列只有2次,故EEG数据中含有P300 ERP和N-P300 ERP的样本数据量分别为2 550(2×15×85=2 550)和12 750(10×15×85=12 750),这会造成训练数据中P300 ERP和N-P300 ERP的数据量不平衡。为了保持训练过程中两类数据的平衡和多样性,笔者参考文献[11]中的处理技巧,依据诱发电位的锁时特性,对现有的P300 ERP样本数据量进行一次叠加平均计算,合成新的用于训练的P300 ERP,这样合成后P300 ERP与N-P300 ERP的数据量等同,总训练集样本量为25 500。同时,为了提高P300诱发电位识别正确率,对采集到的EEG脑电信号xij做零均值、单位方差的归一化处理,得到
(1)
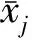
由于本研究采用有监督的网络训练方式,故需构造与EEG数据相对应的监督信号y。针对一个二值分类的问题,网络输出代表属于P300 ERP信号的概率,因此按照下式确定监督信号的取值,将(xij,y)代入设计的网络进一步训练,有
(2)
1.2.2卷积神经网络
作为一种多层神经网络,卷积神经网络凭借其强大的特征提取能力,成功地应用在计算机视觉、图像处理等领域。随着研究者的不断革新,卷积神经网络由最初简单的LeNet5网络[12]演变出各种强大的网络,如VGG、AlexNet、GoogleNet等。其中,Inception v1网络是一种结构与LeNet5网络不同的卷积神经网络[13],图3对比展示了两者的部分结构。Inception v1网络是不同的卷积层以并联的方式连接在一起,这样在构建网络时会平衡网络的深度和宽度,使得流入网络的信息最大化,更有利于网络特征的提取,因此在图像分类问题中具有更佳的效果。
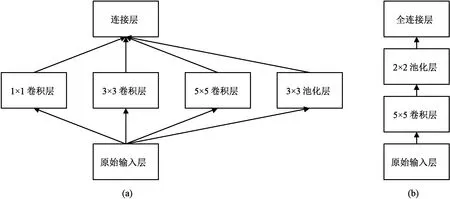
图3 网络结构对比。 (a) Inception v1网络; (b) LeNet5网络Fig.3 Comparison of network architecture. (a) Inception v1 network; (b) LeNet5 network
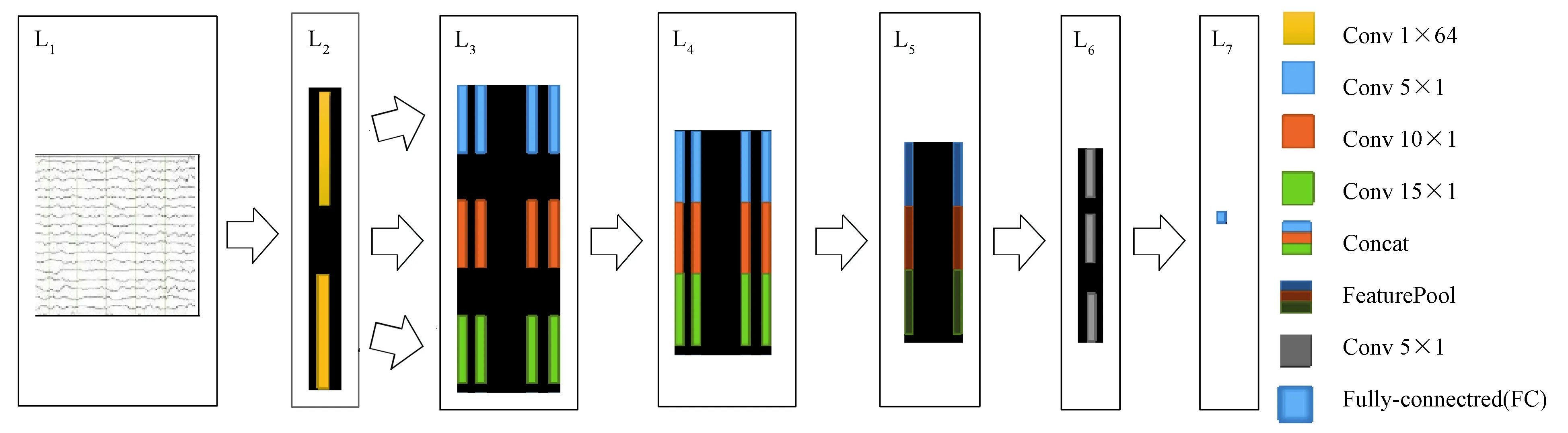
图4 改进的网络架构CNN-IEFig.4 The improved network architecture CNN-IE
1.2.3改进的网络架构
本研究融合了Inception v1网络和EEGNet网络[14],提出了一种改进的网络架构(命名为CNN-IE网络),如图4所示。
该网络深度为7层,分别命名为L1~L7,具体改进的网络架构描述如下:
1) L1:输入层,载入待识别的EEG脑电信号数据,将xij在本研究的后续实验中取i=160,j=64,并以张量的形式传递给下层网络。
2) L2:卷积层,由一个卷积核大小与信号通道数量相等的多个卷积核组成。这种操作相当于对输入信号的所有通道进行空域滤波,类似于加权叠加平均和共同空间模式[15]等传统的信号统计处理方法,可以有效提高信号的信噪比,除去信号在空间上的冗余信息。
3) L3:卷积层,由3个具有不同卷积核大小的卷积层并行排列组成,每个卷积层的卷积核数量相同。对同一输入采用不同尺度的卷积核能提取到不同信息,增加特征的复杂度。本研究对L2层空域滤波后的信号进行不同时间尺度上的时域滤波,相当于在不同时间段内提取数据特征,进而提取多样化信息。
4) L4:连接层,将L3层不同滤波器尺度下提取到的特征图堆叠起来,主要用于整合提取到的特征。
5) L5:池化层,由一个尺寸为2的池化滤波器组成特征池化层。本研究将L4层得到的特征图在其数量上做最大池化。该池化操作有利于减小网络的参数,既可以加快计算,也可以防止小数量训练样本过拟合的问题。
6) L6:卷积层,是一个常用的普通卷积层。用10个大小为5的卷积核,对L5层得到的特征继续进行卷积滤波操作,提取更抽象深层且有利于分类的特征,同时减少最后连接全连接层的网络参数。
7) L7:全连接层,输出节点为1。将L6层提取的特征进一步加权计算,得到当前输入信号被网络判断为P300 ERP的概率P,选定判别阈值为0.5,若当前网络输出概率不小于0.5,则判别当前信号为P300 ERP;否则,判别当前信号为N-P300 ERP。其中,判断结果E表示如下:
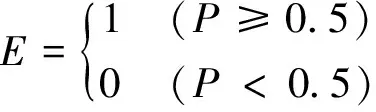
(3)
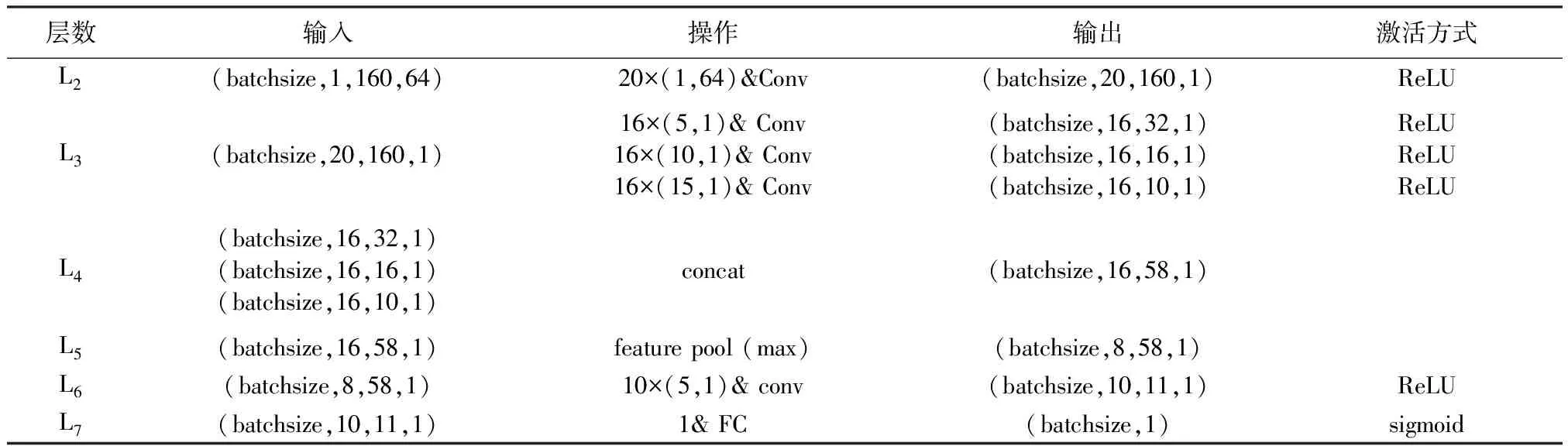
表1 网络参数设置Tab.1 Network parameter settings
本研究采用二值交叉熵代价函数[16]作为损失函数,用以衡量网络的分类误差。采用正则化思想[17],通过在损失函数中添加刻画网络复杂度的指标来避免过拟合问题。对L2层和L7层采用l2正则化方法,以降低过拟合的风险,同时将l1正则化方法引入L2层,使得参数变得更加稀疏,达到类似特征选取的功能。其中,l1=0.001,l2=0.001。为使网络获得更好的鲁棒性,网络采用dropout策略[18]。在L1层和L5层后使用dropout训练技巧,将对应层中的节点以固定概率P=0.2随机丢弃,训练过程中相当于多个网络组合,以减轻网络过拟合问题。同时,在设计网络时,通过对L3层中并行卷积层的数量以及卷积核的大小进行增减,以确定最佳的网络结构。为验证L3层中并行卷积层的数量对字符识别正确率的影响,采用将并行卷积层的数量分别设定为2、3、4层。另外,在讨论卷积核大小对字符识别正确率的影响时,本研究设定了3组网络。设定Ⅰ组网络的L3层中并行卷积层的卷积核大小分别为(3,1),(5,1)以及(10,1),Ⅱ组网络的L3层中并行卷积层的卷积核大小分别为(5,1),(10,1)以及(15,1),Ⅲ组网络的L3层中并行卷积层的卷积核大小分别为(10,1),(15,1)以及(20,1)。
1.3 分类识别
本研究对上述构建的网络进行有监督训练。网络的主要参数设置如表1所示,其中批量处理数据样本数batchsize为64。采用收敛速度快且优化效果佳的Adam优化方法[19]更新参数,在默认情况下,β1=0.9,β2=0.999,ε=10-8。每次实验中,所有行和列都会闪烁一次,产生相应的EEG数据,数据经网络计算输出对应的概率值。比较这些概率值大小,进而判断出诱发P300 ERP的行号和列号。然而实际中,一次实验并不能准确地判断目标字符的位置。本研究累加n次实验中网络的输出概率P(k,i),其中k表示实验序号,i是对应的行号或列号。搜索概率最大的列和行即为目标字符的位置(x,y),进而计算网络对字符的识别正确率,有
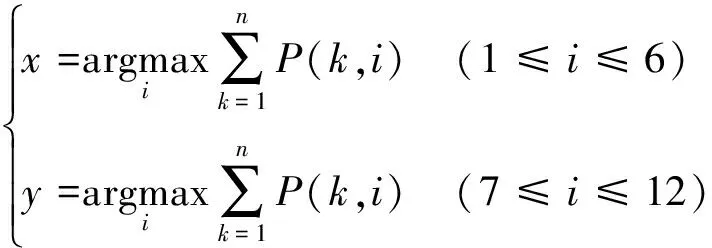
(4)
1.4 算法实施与评价
本研究使用竞赛中A组数据,其中每个字符都进行15次重复实验。选择含有85个字符的EEG数据作为训练集进行训练网络,含有100个字符的EEG数据作为测试集以验证算法。在验证时,先将每次实验获得的脑电数据输入到网络中,经网络计算输出当前实验输入信号属于P300 ERP的概率,然后依据式(4)来计算不同实验次数条件下相对应的字符,并与目标字符比较,计算其字符识别正确率如下:
字符识别正确率=正确预测的字符数/字符总数
(5)
为进一步描述网络对字符识别速度,采用计算信息传输率(information transfer rate, ITR)[20]来评价,其定义为
(6)
式中:Pc为字符识别正确率;N表示待识别的字符种类数,即视觉刺激器上的字符数,总计36种;通常意义下,T是识别一个字符所需时间,min。
2 结果

表2 不同实验次数下字符识别正确率Tab.2 Correct rate of character recognition under different experiment times %
图5给出了当并行卷积层的数量分别为2、3、4层时,不同实验次数条件下的字符识别正确率。可以看出,当并行卷积层层数为3层时,可取得更好的结果。初步分析,当层数较少时,网络提取特征的能力有所欠缺;当层数较多时,网络较为复杂,可能会造成一定程度的过拟合。
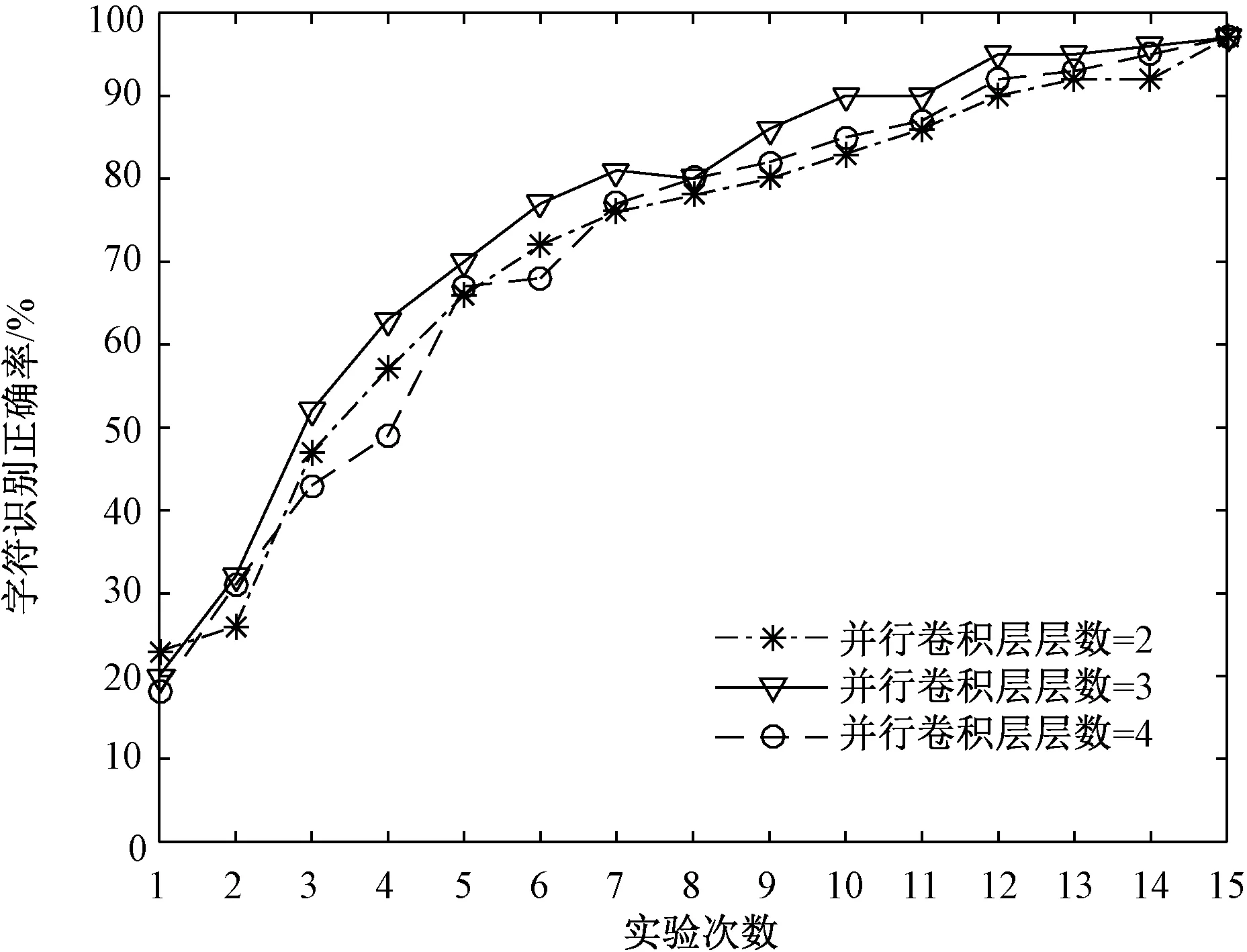
图5 并行卷积层数量不同时,字符识别正确率与实验次数关系Fig.5 The relation between correct character recognition rate and experiment times when the number of parallel convolution layers is different
针对卷积核大小的选择问题,一般来说,小的卷积核提取到的特征更加细腻,但是P300 ERP从产生到消失具有一定的时间范围,故卷积核较小时网络计算得到的时域特征意义不大,而较大的卷积核导致计算复杂度迅速增加。图6给出了3组不同卷积核大小时对应的字符识别正确率。综合各种因素,进而确定最佳的卷积层数与卷积核大小如表1所示。
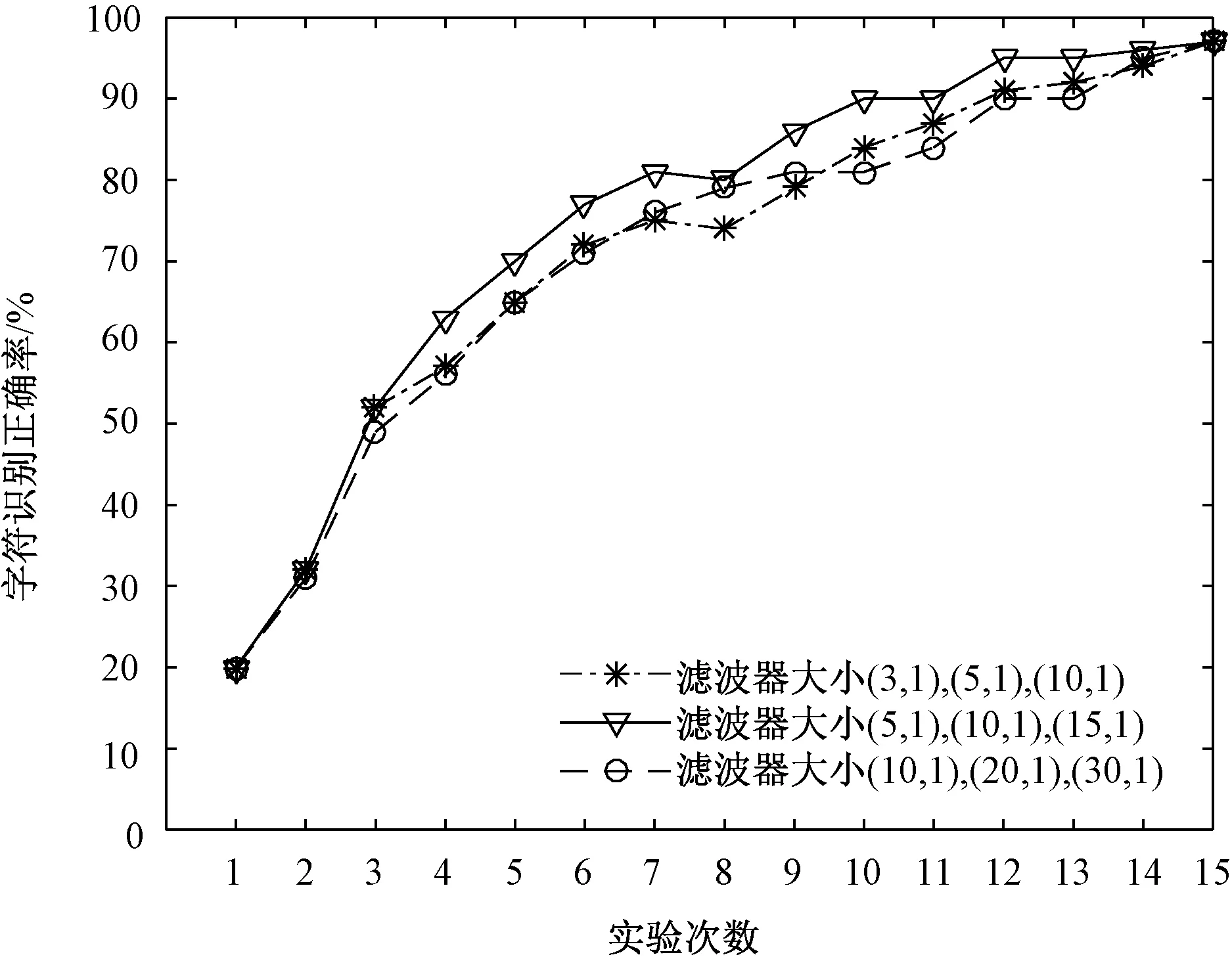
图6 并行卷积层卷积核大小不同时,字符识别正确率与实验次数关系Fig.6 The relationship between correct character recognition rate and the number of experiments when convolution kernels′ size in the parallel convolution layer is different
表2展示相同字符在不同实验次数下利用CNN-IE网络计算得到的字符识别正确率,并与文献[9]中BN3网络和文献[8]中CNN-1网络所得到的实验结果进行对比。可以看出,虽然在实验次数低于7次的情况下本研究的结果稍逊于文献[9]的结果,但是在实验次数为7~15次时,CNN-IE网络的字符识别正确率的均值±方差为90%±6%,明显优于BN3和CNN-1的89%±7%和88%±7%的结果。在实验次大于11次时,其字符识别正确率均在95%以上,表明了CNN-IE网络具有优良的识别正确率,可望在BCI系统应用中得到较好的结果。
图7给出了在不同实验次数下3种网络计算得出信息传输速率。对比可以看出,虽然CNN-IE网络在信息传输速率方面稍逊于BN3网络,但是在大部分实验次数条件下,都可以取得每分钟10 bit以上的信息传输速率,具有一定的应用价值。
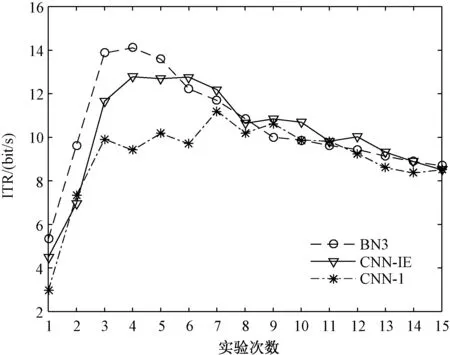
图7 不同实验次数下3种网络的信息传输速率Fig.7 The information transmission rates of the three networks under different experiment times
3 讨论与结论
本研究的主要内容是利用深度学习中的卷积神经网络来实现BCI系统中P300事件相关电位的分类识别。不同于传统的统计信号处理方式,本研究并没有借助常用的EEG信号处理算法搜寻适合分类的特征,而是依据卷积神经网络强大的特征提取和组合能力构造性能较好的分类器,进而在不同实验次数下提升字符识别正确率。而卷积神经网络的分类性能取决于数据和网络结构设计两个方面,本研究的主要工作集中在数据预处理和网络结构设计上。在数据预处理中,充分利用竞赛中的训练数据,采用一次叠加平均的方式扩增训练样本中数量较少的P300信号,在保证扩增的数据接近真实数据的基础上使训练数据多样化,避免网络过拟合。在网络结构设计和参数设置上,在EEGNet网络的基础之上,将网络中串行的第二个卷积层改成多个并行结构的卷积层,即使用多尺度的卷积滤波器提取网络底层的信息,提升网络的特征提取能力。从表2中可以看出,相比文献[8-9]所提出的多个卷积层串行连接的网络,本研究所使用的部分卷积层并行连接的结构能在减少实验次数的条件下(实验次数为6~15次),提高字符的识别正确率。在实验次数为10次以上时,其字符识别正确率均能达到90%以上,其性能均优于BN3网络和CNN-1网络。在研究的过程中,为获得分类性能较好的分类器,对不同参数设置的网络进行实验。结果表明,在一定数量的训练样本下,网络识别正确率并不与网络的复杂度成正比。单一的网络可能存在欠拟合的情况,如在并行卷积网络层数较少和滤波器参数较小时,网络不能够很好地反映数据的特点,造成训练和测试数据中字符识别正确率较低;而太复杂的网络会造成过拟合的情况,如在并行卷积层数较多和滤波器参数较大时,训练数据的分类情况好,但测试数据的泛化能力有所降低。通过大量的对比实验,本研究确定最佳的网络结构。今后可利用更多可视化技术来辅助网络的建模和优化工作,力争在实验次数较少时提高字符识别正确率。
虽然在满足一定实验次数条件下,本研究的字符识别正确率有所提高,但是仅采用脑机接口竞赛数据进行离线分析,而在线BCI系统中,信号采样、处理和分析以及输出控制都要求是实时实现的,系统的实时性取决于硬件和软件算法的合理搭配以及实验范式的设计。本研究的主要工作是针对信号的处理和分析,因此在实验范式和软硬件搭建系统固定的条件下,对信号的处理和分析所消耗的时间进行了简单的分析。当实验次数为15次时,在装有GTX1080显卡的主机上,本算法分类识别100个字符约需2 s的时间,即判断一个字符需要约20 ms的时间。另外,实验范式中产生一个字符的测试数据用时34 s,识别一个字符的时间远远小于产生相对应数据的时间。故在特定的刺激范式和性能较好的系统硬件配置下,本研究提出的算法有望走向实时在线脑机接口系统。笔者后续也将以如何减少样本数据的通道数、进而减少网络规模和计算量为主要研究内容,提高网络的运行速度,使得本算法能够应用于在线系统中。
为提高P300事件相关电位的识别正确率,本研究结合经典的卷积神经网络,提出一种适用于EEG数据处理的网络结构CNN-IE。通过将传统网络结构中的1个串行连接的卷积层改成3个并行连接的卷积层,实现在时域上对信号的多尺度分析,进而提升网络特征提取能力。同时,结合数据扩增和滤波等预处理操作,有效提高了该网络对字符分类识别的正确率。后续的研究工作将探究本方法在实时在线脑机接口系统中的实现与应用。
