一种针对复杂体制雷达信号的分选识别方法
2019-01-19郑志娟
蔡 伟,郑志娟,吴 健
(中国电子科技集团公司第五十一研究所,上海 201802)
0 引 言
随着雷达的低截获概率、多参数捷变等技术的发展,以及各种工作体制和多种抗干扰技术综合应用为特点的复杂雷达信号环境的出现,给雷达信号分选提出了极为严峻的考验[1]。传统的信号分选方法是基于雷达信号参数的规律性、脉间参数可重复性的基础上发展而来的。某些新体制的雷达(如相控阵雷达)通常缺乏参数的脉间可重复性,若引用传统的分选方法,则很难对脉间的参数规律建模,从而分选识别出该信号[2]。
在实际侦收的雷达信号脉冲数据中发现,雷达辐射源的发射脉冲序列可作为表征复杂雷达信号样式的一种有效手段,脉冲序列描述法能通过时序这条主线将脉冲各个维度的特征更精确、完整地体现出来,从而分析辐射源的工作模式和预测干扰辐射源时序。这种以脉冲特征参数来描述雷达辐射源特征的方法相对于传统的用归纳的雷达信号样式特征与特征参数的描述方法,更为精细,更为完整,且最大的优点是能表征复杂体制雷达的信号样式。这样对特定信号的分选问题转化为如何以该信号脉冲序列样本为依据,从侦收的脉冲数据流中快速分选识别出与该信号样本匹配的信号[3]。
由于系统接收的脉冲数据流是按照时间先后顺序排放的数列,所以这在统计学上属于时间序列挖掘问题,即在海量的时间序列数据中用数据挖掘技术,利用时间序列相似性的快速匹配及滑窗技术,实现对多参数联合变化的复杂雷达信号的快速分选识别。综上所述,基于脉冲序列样本的信号分选方法可以作为解决复杂体制雷达信号分选识别的一种有效方法。
1 基于信号样本的相似性匹配原理
由于该基于脉冲序列样本的信号分选方法本质上是基于时间序列的相似性匹配原理,故估计相似度是以在时间序列维度匹配的前提下评估其余维度测量值的相似度。
假设样本的长度为n,样本序列为Ssample={X1,X2,…,Xn},通过时间序列匹配后得到的关系是RMATCH={(Pi1,X1),(Pi2,X2),… (Pin,Xn) },其中Pik可以为null,即没有匹配的脉冲。针对该匹配关系,定义匹配的相似度函数为[4-6]:
(1)
(2)
(3)
f(Pik,Xk)是评估每个脉冲相似度的模型,若在时序上没有检测到样本对应的某一脉冲,则该脉冲的相似度为0,只有在时序上存在脉冲,才从其余各个维度的测量值评估脉冲的相似程度。
在上述评估模型中,设测量的维度为M,ωm为各测量维度在相似度中的权重,而在考虑每个维度与样本的接近程度时,ΔXm为侦察设备在各个维度的测量精度所决定的测量偏差,σm为系统噪声与测量噪声所确定的各个维度的参数容差。
由于系统的测量性能不一,ΔXm、σm这2个量按照实际的测量情况确定。ωm则认为是相对稳定的分配,比如系统仅有频率、脉宽、到达时间(TOA)的测量值,则在一般情况下重频(RF)、脉宽(PW)上分配的权重系数为某固定值;当信号为宽脉宽信号时,且PW的测量相似度很高,这时可改变权重的分配提高脉宽的系数,因为对宽脉宽信号来说,脉宽是个很好的分类属性,宽脉宽的高度相似使得事件的定性很明确,需要高度重视这一信息。
2 处理流程
基于样本序列信号分选流程见图1所示。

图1 基于样本序列信号分选流程图
步骤1:将接收的每个脉冲首先与样本库每个样本的参数范围进行粗相关,参数相关的脉冲存入该样本对应的活动雷达脉冲缓存中,单个脉冲可以与多个样本的参数范围相关,故可以存入多个活动雷达的脉冲缓存中。该过程本质上是预过滤处理,过滤参数段不相关的脉冲,排除完全不相关的脉冲,将可能的脉冲预存入缓存,故脉冲可以一对多地被存入多个活动雷达的缓存。
步骤2:在每个活动雷达缓存中积累的脉冲的持续时间达到该样本的帧时长,则转入序列匹配的过程,否则继续等待后续脉冲。
步骤3:序列匹配是以判断当前缓存的首个脉冲是否属于样本中的一个进行匹配的,将缓存中的首脉冲依次与样本的前一半每个脉冲对齐,开始尝试N/2种匹配法,每种匹配法都将以接收的首脉冲对样本的第n个(n=1,2,…)脉冲开始进行序列的最大相关匹配,得到匹配的个数Mn,在所有的匹配中得到最大的匹配相似度,若最大的匹配相似度大于设定的门限,则匹配成功,转入步骤4(优化:在n=1,2,…由小到大的匹配过程中,若当前n的匹配达到理想匹配状态,即从n开始的样本全部得到了匹配,则可以结束匹配过程,不可能再有更好的匹配情况了);否则匹配失败,说明缓存首脉冲不是样本中的一个,将缓存中首脉冲从滑窗中移走,转入步骤2。
步骤4:匹配成功,获取当前匹配脉冲的序列、匹配标志(对应样本的每个脉冲有1/0的匹配标志)、匹配的相似度,若需要实时输出,则将当前的匹配结果输出。
步骤5:若为定时输出的,则将当前匹配结果存入缓存,统计匹配相似度的最小、最大值,转入步骤1。
步骤6:定时输出点到,将活动雷达库中每个信号匹配成功的所有帧输出,清空匹配结果缓存。
步骤7:上述流程是以后续数据流作为判断时序的触发条件而处理的。为防止某一雷达信号接收数据不再出现而导致该活动雷达库的脉冲缓存出现“dead data”现象,还应有处理活动库中脉冲缓存剩余脉冲的能力,触发条件可以为定时或批处理结束。
基于样本序列信号分选数据流见图2所示。
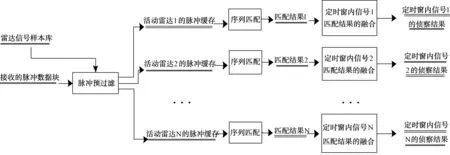
图2 基于样本序列信号分选数据流图
脉冲过滤将原始数据与样本库中不吻合的脉冲字预先舍弃,预存与每类样本可能匹配的脉冲,当预存入的脉冲群满足一定条件后,与预存入的样本进行精细的时序匹配,计算出与样本的相似度。相似度高于匹配门限,则样本匹配成功,基于匹配成功后的脉冲序列可以进行各维度参数统计、信号质量评估等后续信息量的挖掘。
3 分选效果评估分析
(1) 分选效果评估方法概述
对本分选方法的评估,从参数交叠、信号密度、噪声率、脉冲丢失率、测量误差等几个方面验证基于脉冲序列样本的信号分选技术的处理能力和对环境的适应性[7]。
分选效果的验证主要包括:
分选正确率:当脉冲字的检测成功和参数正确的概率达到80%以上,基于该方法的分选的正确率达到90%以上。
同时相似多信号的分选能力:该方法能正确分选识别出两列同时在频率、脉宽、方位参数交叠,脉冲时序特性不同的辐射源脉冲序列。
(2) 分选正确率的验证
样本1设计如下: [(9 300 MHz、1 μs、1 000 μs),(9 300 MHz、1 μs、433 μs),(9 300 MHz、1 μs、477 μs),(9 300 MHz、1 μs、511 μs),(9 300 MHz、1 μs、523 μs),(9 300 MHz、1 μs、533 μs),(9 300 MHz、1 μs、555 μs),(9 300 MHz、1 μs、571 μs),(9 300 MHz、1 μs、591 μs)];以此样本产生仿真的脉冲字序列,共产生25 478个PDW字,其中符合样本1的脉冲序列共3 081帧。
在仿真时选择了下列属性值:
(a) 脉冲丢失概率20%;
(b) 测量误差:
RF: 5 MHz;
PW: 0.2 μs+20%*PW;
TOA: 300 ns;
(c) 叠加了随机噪声脉冲。
实验结果如下:
辐射源识别号: 1;样本长度:9;共截获帧次数:3 022;共匹配脉冲总数: 22 012;匹配时长: 15 996.520 ms;平均匹配个数: 7.283 917;最佳匹配个数:9;最差匹配个数:5;平均匹配系数:0.797 614;最佳匹配系数: 1.000 000;最差匹配系数: 0.528 075。
基于上述匹配可得出多维参数分布情况如下:
RF HISTOGRAM
SAMPLE_NUM:22 012;RF_MIN: 9 295.00 MHz;RF_MAX:9 305.00 MHz;RF_AVG: 9 299.99 MHz;
RF:9 300.04 MHz;ACCU_NUM:8 864;
RF:9 296.52 MHz;ACCU_NUM:6 662;
RF:9 303.52 MHz;ACCU_NUM:6 485;
RF:9 298.00 MHz;ACCU_NUM:1。
PW HISTOGRAM
SAMPLE_NUM:22 012;PW_MIN:0.60 μs;PW_MAX:1.40 μs;PW_AVG:1.00 μs;
PW:1.00 μs;ACCU_NUM:22 012。
结论:
样本1信号帧的识别率为3 022/3 081=98.085%,符合预期要求。
(3) 同时相似多信号的分选能力验证
样本选取2个频率均为800 MHz、脉宽1 μs的脉冲序列,重周均在400 μs~600 μs 之间跳变,差别在于精确的时序不同。
具体的样本序列如下:
样本2: [(800 MHz、1 μs、1 000 μs),(800 MHz、1 μs、433 μs),(800 MHz、1 μs、477 μs),(800 MHz、1 μs、511 μs),(800 MHz、1 μs、523 μs),(800 MHz、1 μs、533 μs),(800 MHz、1 μs、555 μs),(800 MHz、1 μs、571 μs),(800 MHz、1 μs、591 μs)];
样本3: [(800 MHz、1 μs、1 000 μs),(800 MHz、1 μs、417 μs),(800 MHz、1 μs、417 μs),(800 MHz、1 μs、417 μs),(800 MHz、1 μs、453 μs),(800 MHz、1μs、4 535 μs),(800 MHz、1 μs、453 μs),(800 MHz、1 μs、497 μs),(800 MHz、1 μs、497 μs),(800 MHz、1 μs、497 μs)];
以上述两样本产生仿真的交错脉冲字序列,共产生178 385个PDW字,其中符合样本1的脉冲序列共9 752帧,符合样本2的脉冲序列共9 930帧。在仿真时选择了下列属性值:
(a) 脉冲丢失概率10%;
(b) 测量误差:
RF: 5 MHz;
PW: 0.2 us+20%*PW
TOA: 300 ns
(c) 叠加了随机噪声脉冲。
实验结果如下:
辐射源识别号:2;样本长度:9;
共截获帧次数:9 744;
共匹配脉冲总数:78 449;
匹配时长:50 650.888 ms;
平均匹配个数:8.051 067;最佳匹配个数:9;最差匹配个数:5;
平均匹配系数:0.881 853;最佳匹配系数:1.000 000;最差匹配系数:0.527 428。
基于上述匹配可得出多维参数分布情况如下:
RF HISTOGRAM
SAMPLE_NUM:78 449;RF_MIN:795.00 MHz;RF_MAX:805.00 MHz;RF_AVG:800.01 MHz;
RF:797.45 MHz;ACCU_NUM:31 485;
RF:803.03 MHz;ACCU_NUM:30 981;
RF:800.25 MHz;ACCU_NUM:12 615;
RF:795.22 MHz;ACCU_NUM:3 368;
PW HISTOGRAM
SAMPLE_NUM:78 449;PW_MIN:0.60 μs;PW_MAX:1.40 μs;PW_AVG:1.00 μs
PW:1.00 μs;ACCU_NUM:78 449
辐射源识别号:3;样本长度:10;
共截获帧次数:9 906;
共匹配脉冲总数:88 864;
匹配时长:50 646.829 ms;
平均匹配个数:8.970 814;最佳匹配个数:10;最差匹配个数:6
平均匹配系数:0.884 440;最佳匹配系数:1.000 000;最差匹配系数:0.571 575
RF HISTOGRAM
SAMPLE_NUM:888 64;RF_MIN:795.00 MHz;RF_MAX:805.00 MHz;RF_AVG:800.00 MHz;
RF:802.24 MHz;ACCU_NUM:35 722
RF:796.98 MHz;ACCU_NUM:34 958
RF:799.60 MHz;ACCU_NUM:11 640
RF:804.63 MHz;ACCU_NUM:6 543
RF:797.70 MHz;ACCU_NUM:1
PW HISTOGRAM
SAMPLE_NUM:88 864;PW_MIN:0.60 μs;PW_MAX:1.40 μs;PW_AVG:1.00 μs
PW:1.00 μs;ACCU_NUM:88 864
结论:
样本2产生的信号帧的识别率为9 744/9 752=99.917%,符合预期要求。
样本3产生的信号帧的识别率为9 906/9 930=99.758%,符合预期要求。
4 结束语
本文针对复杂体制雷达,给出了一种基于脉冲序列样本的信号分选方法。该方法突破了传统分选方法对复杂信号样式建模的局限性,大大提升了系统应对复杂信号环境的侦察能力。实验结果表明,采用本方法分选正确识别率达到98.085%,并能正确分选识别出2列同时在频率、脉宽、方位参数交叠,脉冲时序特性不同的辐射源脉冲序列,对具有时域、频域参数交叠的信号环境、含噪声脉冲的信号环境适应性强,具有一定的工程实用性。
