混合精英学习的分组APO算法
2019-01-16李云仙谢丽萍
李云仙,谢丽萍,谭 瑛
(太原科技大学 计算机科学与技术学院,太原 030024)
启发式算法是基于客观世界中的自然现象,而人类受大自然的启发,提出一些用于解决各种复杂问题的启发式算法。比如,模拟生物群体智能行为的群智能算法,微粒群算法[1]、蚁群算法、人工蜂群算法等,还有一类模拟物理原理的算法,模拟退火算法[2](SA)、拟态物理学算法(APO)等。针对微粒群算法的不足,研究者进行了大量改进,文献[3]提出反向学习PSO算法,提高了种群多样性。文献[4]一种基于动态邻居和变异因子的粒子群算法,粒子的学习跟随自己的历史经验和所有邻居的经验,引入水平混合变异,提升粒子跳出局部最优解的能力。文献[5-6]提出一种扰动的精英反向学习PSO算法,算法引入反向策略,引导粒子向最优解空间靠近,采用扰动增强算法局部探索能力。
借鉴PSO算法的改进策略,本文以拟态物理学优化[7-9](Artificial Physics Optimization, APO)为研究对象,对APO算法改进。该算法是最新提出的一种基于群体寻优的随机搜索算法,它基于万有引力定律定义个体之间的虚拟作用力,根据个体的适应值优劣制定个体间的引斥力规则,并在所制定的虚拟力规则的作用下在问题的可行域内搜索全局最优点。由于APO算法具有较强的全局搜索能力,且算法过程涉及的参数较少,增加了算法的鲁棒性。但APO算法只遵循一种运动规则,过程单一,多样性较差,易使算法陷入局部最优,为此,本文提出混合精英学习的分组APO算法。
1 混合精英学习的分组APO算法
1.1 分组APO算法运动规则集的构造
制定高效的作用力规则,为算法迭代过程中不同的个体分配不同的作用力规则[10],挖掘更多的有效信息,来引导个体向更好地区域搜索是增强算法多样性,提高APO性能的关键。鉴于此,构造的规则集如下:
规则一:标准APO作用力规则即对组内任意一个个体i,适应值较好个体吸引适应值较差个体,适应值较差个体排斥适应值较好个体。同时适应值最优个体具有绝对吸引力,吸引组内其他所有个体,而其本身则不受组内其他个体吸引或排斥。公式如下,其中xi,k,vi,k分别表示个体i在第k维的位置分量和速度分量,Fij,k为个体j对i在第k维的作用力,mi为个体i的质量。个体i的质量和个体j对i在第k维的作用力公式为:
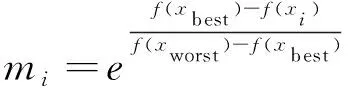
(1)
∀i≠j,i≠best,i,j=1,2...m
(2)
个体i在第k维所受其他个体合力公式为
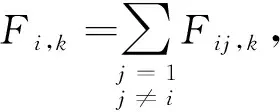
(3)
个体i在第t+1代速度和位置公式分别为
vi,k(t+1)=wvi,k(t)+αFi,k/mi
(4)
xi,k(t+1)=xi,k(t)+vi,k(t+1)
(5)
规则二:运用模拟退火运动规则,对较优个体邻域进行搜索。按照Metropolis准则,若新的解比之前的优,则接受并更新,否则,就使个体在一定概率范围内接受不好的解,可以探索更多潜在的搜索空间,提高算法的全局勘探能力。Metropolis 准则:
T(t+1)=p*T(t)
(6)
模拟退火运动规则的速度和位置的更新公式如下:
xi,k(t+1)=xi,k(t)+(2*rand-1)*L
∀i≠best
(7)
vi,k(t+1)=vi,k(t)+xi,k(t+1)
(8)
规则三:扩展APO作用力规则即对组内任意一个个体i,受比它适应值好的历史最优个体的吸引,比它适应值差的历史最优个体的排斥。
该规则有效地利用了其他个体的历史最优位置信息,提高了个体找到最优值的概率。
如下公式:
其中pj,k表示个体历史最优位置。个体j对个体i在第k维的作用力和合力公式:
∀i≠j,i≠best,i,j=1,2...m
(9)
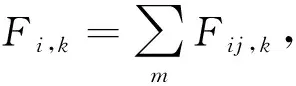
(10)
1.2 种群多样性策略
种群多样性[11-14]的变化对算法性能有着重要的影响,因此,引入种群多样性的概念,动态调整组内个体的运动情况,使个体保持持续的进化活力。
前期实时监控组内种群多样性,以一定概率对适应值较差个体反向学习,改善种群多样性,后期种群多样性变小,各组个体较为密集,相似性高,各组个体融合为一组进行全局精细搜索,提高个体间的差异性,使种群多样性回升,进而搜索得到全局最优点。计算种群多样性的公式参考文献[15],N为种群大小,D为维度L为搜索空间对角线长度。
1.3 分组精英学习APO算法思想过程
APO算法具有很强的全局搜索能力,但是必须同时具有全局搜索能力和局部搜索能力才能使算法表现出良好的性能,此外,种群多样性也是衡量算法好坏的重要标准,在算法过程中起着重要的作用。
因此,为了在整个进化过程中兼顾全局和局部搜索,本文提出分组精英学习策略,各组在进化前期运用规则一进行若干代的局部搜索,保证前期有效的局部搜索,可以使个体在当前较优解附近的区域搜索充分,更好地寻找潜在的较优解。后期由于各组间缺乏有效信息的交流,使得整个种群多样性难以提高。为了保证种群多样性,选出所有不在同一小邻域范围的最好个体组成精英个体进行精英搜索,精英个体是汇聚种群中所有粒子优秀信息的个体,精英个体所形成的搜索区域会收敛到全局最优所形成的搜索区域,因此采用规则二进行全局搜索,精英个体间共享各自的优秀信息,同时也可作为其他个体沟通的中介,指导其他个体的学习,改善全局搜索能力,促进算法快速收敛。精英个体的引入,能够保证组内组间协同搜索,防止种群个体受单一最优个体的影响,迅速收敛聚集到某一局部最优,在一定程度上提高了个体学习的灵活性。同时各组个体按照规则一围绕各自的精英个体附近精细搜索若干代,提高最优解的精度,改善算法的局部精细搜索能力。
该算法在前期组内若干代的局部搜索,可能会使粒子间相似度较高,种群多样性丧失,引入种群多样性动态监控各组运动趋势,并运用反向学习策略反向搜索,给定一定的反向学习概率p,满足如下公式(11)对较差个体评估其当前解和反向解,从而更好地发掘潜在的较好解。后期收敛阶段,各组融合为一组采用规则三(EAPO)进行全局精细搜索,刺激种群多样性回升,避免了局部最优,使得较好的解进入下一代搜索中,从而提高算法的寻优能力。
(11)
1.4 算法实现
综上所述,本文算法实现步骤如下
Step1:初始化种群,种群规模为N,分组个数d,每组粒子数m,种群多样性阙值D0,邻域半径r,组内迭代t1代,最大迭代代数tmax,令t=0,分别计算各组粒子的适应值,保留各组最优个体。
Step2:组内学习。当t≤t1代时,各组独自进化,根据文献[15]公式计算各组种群多样性D,若D>D0,根据公式(1)-(3)计算各组每个个体所受合力,根据适应值函数,评价个体的适应值,选出最优个体和m/2较差个体,对各组较差个体根据公式(11)进行反向学习,根据公式(4)、(5)更新各组个体的速度位置,对于各组每代产生的最优个体,进行最优保留,t=t+1.若各组D Step3:组间学习。当t1+1≤t≤tmax时,对所有个体按照适应值大小排序,选出不在同一小邻域r的d个最优个体(即精英个体),以精英个体为中心,剩余个体随机均分成d组。精英个体组成组间个体,按规则二运动,根据公式(6)(7)(8)更新精英个体的速度和位置,并保留历史最优和全局最优。 Step4:对于组内个体,按照step2各组分别在各自的精英个体周围搜索k代,对每代产生的历史最优和全局最优个体,进行最优保留。 Step5:若各组D Step6:若t≤tmax,转step3,直到满足结束条件,终止算法并输出所求的全局最优值。 为了测试该算法的性能,利用28个标准测试函数中14个函数(2个单峰函数(f1,f2),9个多峰函数(f3-f11),3个复杂函数(f12-f14))进行仿真。 单峰函数Sphere, Different Powers.多峰函数RotatedRosenbrock’s,RotatedSchaffersF7,RotatedAckley’s ,RotatedGriewank’s,Rastrigin’s,RotatedRastrigin’s ,Non-ContinuousRotatedRastrigin’s,RotatedKatsuura,LunacekBi_Rastrigin.复杂函数CompositionFunction5(Rotated),CompositionFunction6 (Rotated) ,Composition Function8 (Rotated) . 算法的评价结果以搜索函数的最小值为目标,函数最小值即为最优值。其中best表示最优(小)值,mean_best表示平均最优(小)值,std表示标准方差。GEAPO与APO算法性能比较如下表(1) 表1 GEAPO与APO算法性能的比较 函数编号最优值bestAPOmean_beststdbestGEAPOmean_beststdF1-1400-1.4000E+03-1.4000E+039.7019E-08-1.4000E+03-1.4000E+037.5791E-14F2-1000-7.2734E+02-5.2512E+022.1891E+02-1.0000E+03-1.0000E+039.2825e-14F3-900-8.8355E+02-8.5805E+022.6578E+01-8.9475E+02-8.9207E+021.5795E+00F4-800-6.4900E+02-6.1893E+022.1656E+01-7.9949E+02-7.9768E+021.4821E+00F5-700-6.7909E+02-6.7905E+023.0563E-02-6.7919E+02-6.7915E+023.4966E-02F6-500-4.9985E+02-4.9900E+027.0865E-01-4.9997E+02-4.9994E+022.6085E-02F7-400-3.7612E+02-3.6896E+027.6754E+00-3.9005e+02-3.8580e+023.3127E+00F8-300-2.7214E+02-2.5870E+021.2565E+01-2.8906E+02-2.8358E+024.0687E+00F9-200-1.4866e+02-9.5064e+014.3479e+01-1.6987e+02-1.5566e+029.2279e+00F102002.0189E+022.0259E+022.6584E-012.0131E+022.0187E+022.7758E-01F11 3003.4559E+023.6298E+027.7611E+003.3934E+023.4455E+023.1175E+00F1211001.3452E+031.3616E+031.1833E+011.3446E+031.3532E+037.7375E+00F1312001.4006E+031.4012E+035.1302E-011.4000E+031.4000E+034.5383E-03F1414003.7017E+033.9774E+031.6955E+021.7000E+031.7000E+033.9382E-13 从表分析可知,通过GEAPO算法与APO算法的比较发现,GEAPO算法中函数的最优值,平均值和方差都优于APO算法。该算法中单峰函数能精确收敛到全局最优解,函数Rosenbrock ,Schaffers F7,Griewank,Rastrigin是典型的多峰函数,具有多个局部极值,很难找到全局最优,但从表中均值结果来看,改进算法能收敛到全局最优解附近,搜索精度较高,说明本文算法具有很强的全局寻优能力。对于复杂函数而言,由于函数图像比较复杂,没有特定的规律,解的精度提高变得相当困难,因此,相对于单峰和多峰函数,复杂函数在求解的精度上较差一些。从方差对比来看,算法的稳定性较好。所以,本文算法在整体性能上较优,大部分函数在收敛精度上有较好的优势。 从算法的时间复杂度分析,APO 算法在每一代都会评价一次所有个体的适应值,GEAPO算法对个体进行了分组,对组间个体加入了模拟退火规则,在每一代中除了要评价每一个个体的适应值,还要根据Metropolis准则评价组间个体的适应值,虽然时间频度不同,但算法的时间复杂度相同。精英个体和反向学习的个体只是改变了学习方式,未增加额外的时间消耗和空间消耗,因此,改进的算法在时间复杂度和空间复杂度方面是有效的,并未增加原APO的复杂度。 在大规模环境下,采用单一种群进化,会耗费大量时间,而GEAPO算法采用分组策略,将种群分为若干个子种群,各子群独自并行进化,在分布式环境下运行会缩短所耗时间,增加种群多样性。因此,从整体看,改进算法在大规模数据优化上,具有一定的应用前景。 由此可知,分组反向学习,组间精英学习,引入种群多样性指标,确实增加了种群多样性,平衡了全局和局部搜索能力,并且由于其运动规则的变化性,在整体性能上,优于遵循单一规则的APO算法,改善了算法陷入局部最优的缺点,提高了收敛精度。仿真实验表明本文算法是有效的。 提出了分组精英学习的APO算法,通过分组策略,各组独自进化,组内组间采用不同的作用力规则来达到寻优的目的。引入精英个体进行组间全局搜索更为优秀的解,加强优秀信息的共享,同时各个精英个体引导种群个体向全局最优位置运动,防止个体受单一全局最优影响迅速早熟收敛。组内局部搜索采用反向学习策略和种群多样性动态监控个体的运动,避免个体紧密聚合,陷入早熟收敛,提高了种群多样性,激活了个体的搜索活力。 仿真实验表明,该算法整体性能上具有一定的优势,且稳定性较好。算法的改进是有效的。当然,针对G的取值对算法性能影响较大的问题,可对参数G的设置进行进一步的研究探讨,后期还需在并行环境下对大规模问题进行研究,并将该算法用于求解有约束优化问题,解决实际的工程问题2 仿真结果及分析
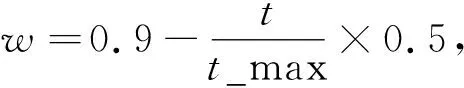
Tab.1 The performance comparison results of the algorithms GHAPO and APO
3 结 论
