面向事件的中文指代语料库的构建
2019-01-08张亚军刘宗田
张亚军, 刘宗田, 李 强, 周 文
(1.上海大学计算机工程与科学学院,上海200444;2.上海精密计量测试研究所,上海201109)
指代是自然语言中一种常见的语言现象,在篇章和对话中大量出现,它使得语言表达简洁连贯,但在篇章中大量使用指代会增加计算机对篇章的理解难度.指代消解的主要任务就是识别篇章中对现实世界同一实体的不同表达过程[1].以往大量的研究工作都是集中在非事件的文本中[2],取得了一定的成果.随着“事件”这一概念的兴起,越来越多的学者开始着手面向事件的研究.事件关系到多方面的静态概念,是比静态概念粒度更大的知识表示单元,以事件作为人类知识的基本单元,更接近人类的认知过程,更符合客观实际,受到了越来越多领域研究者的关注,并逐渐被计算机语言学、人工智能、信息检索、信息抽取、自动文摘等知识处理领域所采用.
自20世纪80年代末,一些信息抽取的国际测评会议开始兴起,如信息理解会议(Message Understanding Conference,MUC)、自动内容抽取(automatic content extraction,ACE)会议等,这些会议为信息抽取以及指代消解等自然语言处理技术提供了统一的测试语料和测评方法.这些会议的召开在很大程度上推动了指代消解的发展,特别是会议提供的测试语料,使得指代消解系统从基于启发性规则的消解方法转向了基于数据驱动的消解方法.例如,MUC语料采用的是标准通用标记语言(standard generalized markup language,SGML)标注方法[3],用<COREF ID= “x”>,<COREF ID= “x”REF=“y”>分别表示实体、参照表达式的左边边界,用</COREF>表示实体、参照表达式的右边边界.x从1开始严格单调递增,表示实体在文本中的顺序标号,REF表示该实体的先行语信息,如果y等于某一个x的值,则这个参照表达式的先行语就是ID号为x的实体,若无REF值,则这个实体不存在先行语.而ACE语料与MUC语料不同,以ACE 2005[4]为例,是通过指代链描述文本中的指代关系,将指向同一实体的表达都放在一条具有相同编号的指代链中.值得一提的是,ACE语料从ACE 2003开始加入中文语料,目前已达到30万字的训练语料、5万字的测试语料,而且加入了对事件提及的评测,这是最早针对中文指代消解的国际测评语料资源,对于中文指代消解的发展起到了很大的推动作用.2011年,CoNLL提供了针对英文的OntoNotes 4.0[5]语料库,而且对事件名词与动词的共指关系进行了标注,并在2012年推出OntoNotes 5.0[6]语料库,提供英文、中文以及阿拉伯文的语料进行多语言的共指消解评测.近年来,国内对指代消解的研究也逐渐增多,相关语料库的构建也有很多.例如,赵知纬等[7]在ACE 2005中文语料库的基础上构建了一个面向信息抽取的中文跨文本指代语料库,舒佳根等[8]在ACE 2005中文语料和中文维基百科的基础上构建了一个实体链接语料库.
然而,上述语料库大多不是基于事件的标注,虽然ACE语料库定义了8类事件,并对事件提及进行了评测,但其对事件的理解还停留在篇章层次,没有细化到具体的句子,并不能覆盖所有事件,而且对事件提及的评测并没有涉及共指消解的问题.OntoNotes语料库提供的关于事件的共指关系仅仅涉及英文,不适合中文的语句分析.国内大多数语料库也是建立在类似ACE中文语料的基础上,并没有以事件作为知识表示单元进行标注.事件中涉及多方面的实体,称为要素,与传统文本中的静态概念一样,同样存在大量的指代现象,同时事件本身也存在不少指代,对于面向事件的应用来说,这些指代带来了很多不确定性,需要对它们进行处理和研究,这就需要语料库的帮助.然而到目前为止,还没有面向事件的中文指代语料库.
本工作就是为了弥补这一方面的缺陷,在中文突发事件语料库(Chinese emergency corpus,CEC)的基础上,构建了一个面向事件的中文指代语料库,其中包括了对已存在要素、缺省要素和事件的指代标注.与传统的中文指代语料库相比,面向事件的中文指代语料库有其自身的优点:①面向事件的中文指代语料库是建立在事件的基础上,以事件作为知识表示单元,反映了事物的动态性,更符合客观实际,便于计算机模拟大脑工作;②传统的指代标注进行了过多实体类别的划分,而面向事件的指代标注是依托事件和事件要素进行的标注,分类少,而且结构清晰;③面向事件的指代标注不仅对指向同一实体的要素进行标注,而且对基准类型的指代进行了标注,通过这种指代关系,可以将抽象要素具体化;④基于事件的标注使传统指代中的零指代消解[9]转变为缺省要素[10]的指代消解,使实体要素化,结合事件的语言表现规则,更利于缺省要素的识别和消解;⑤传统的指代消解因缺少必要的篇章知识用于消解,容易受到限制,而面向事件的指代标注可以通过与事件关系[11-12]的结合,挖掘出更多的篇章知识,提高指代消解系统的性能.虽然受CEC语料的限制,语料库规模较小,但本工作的初步研究可以为面向事件的中文指代消解提供一个有效的资源支持,对于面向事件的应用来说有十分重要的意义.
1 相关定义
定义1 事件(Event)[13]指在某个特定的时间和环境下发生的、由若干角色参与、表现出若干动作特征的一件事.形式上,事件可以表示为e,定义为一个六元组:
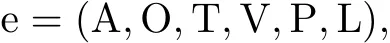
式中,事件六元组元素称为事件要素,分别表示动作、对象、时间、环境、断言、语言表现.本工作仅对对象、时间、环境三个要素进行指代消解的标注研究.
O(对象),指事件的参与对象,包括参与事件的所有角色,这些角色的类型数目称为对象序列长度.对象可分别是动作的施动者(主体)和受动者(客体).主体是主导者,是事件的主角,有时是事件的制造者或期望事件的发生者.客体是事件中的被动者.
T(时间),事件发生的时间段,从事件发生的起点到事件结束的终点,分为绝对时间段和相对时间段两类.
V(环境),事件发生的场所及其特征等.例如,在小池塘里游泳,场所为小池塘,场所特征为水中,其中场所特征是现实世界中隐藏的无形环境,是人们通过常识在头脑中经过简单推理得出,并没有显示在文本中.
定义2 事件类(Event Class)[13]指具有共同特征的事件的集合,用EC表示,定义如下.

式中:E是事件的集合,称为事件类的外延;Ci为事件类的内涵,表示每个事件在第i个要素上具有的共同特性的集合;cim是事件类中每个事件在第i个要素上具有的一个共同特性.
定义3 事件触发词(Trigger)[14]又称事件指示词或事件核心词,是指文本中可以用来清晰表示所发生事件的词.一般情况下,触发词是句子中的主要动词(也可能是名词),触发词直接描述了事件.
定义4 先行要素和照应要素 面向事件的中文文本中如果存在要素间的指代关系,表达较为具体的要素称为先行要素,表达较为抽象的要素称为照应要素.
定义5 先行事件和照应事件 面向事件的中文文本中如果存在事件间的指代关系,表达较为具体的事件称为先行事件,表达较为抽象的事件称为照应事件.事件的具体和抽象的判别与事件所包含的要素是否齐全有关,即事件的对象、环境和时间要素是否缺省.
定义6 面向事件的指代消解 在面向事件的文本中寻找先行要素(或先行事件)和照应要素(或照应事件)之间的关系,并明确给出照应要素(或照应事件)所指向的先行要素(或先行事件)的过程.
2 语料库的标注
面向事件的中文指代语料库是在CEC的基础上进行的标注,共有两大类指代关系的标注,分别为事件要素(对象、环境和时间)的指代标注和事件的指代标注,其中事件要素的指代标注又分为已存在要素的指代标注和缺省要素的指代标注.
2.1 CEC
CEC是上海大学语义智能实验室以从互联网上收集的关于地震、火灾、交通事故、恐怖袭击以及食物中毒五类突发事件的新闻报道作为生语料,经过事件和事件要素等人工标注,并经过统计和分析构建的面向事件的中文语料库,目前共有332篇,具体的统计情况如表1所示.

表1 CEC统计概况Table 1 CEC statistics
2.2 指代标注方式
为方便计算机处理,CEC语料采用的是XML语言进行的标注,而且事件要素分为已存在要素的指代标注和缺省要素的指代标注,所以指代的标注有两种标注形式:第一种形式为属性(Attribute)标注,这种标注只针对要素的指代,与事件的标注无关,目的是进行事件中缺省要素的标注;第二种形式为标识(Tag)标注,即单独用一个标识进行指代标注,目的是进行已存在要素的标注和事件的标注.
2.2.1 属性标注
属性标注的标注位置是在各个要素标识的表示顺序编号的属性里:对象要素是在标识Participant或Object的属性sid(主体编号)或oid(客体编号)中进行标注;环境要素是在标识Location的属性lid中进行标注;时间要素是在标识Time的属性tid中进行标注,下面分别举例说明.
对于对象要素(见图1),事件e3与事件e4的主体对象缺失,它们的对象都为事件e2的对象,所以在事件e2的对象属性sid中同时标出事件e3与事件e4的对象标号s3,s4,以此表示此对象在事件e3与e4中也充当主体对象.有时一个事件的主体也可能在另一个事件中充当客体,这时就要用oid进行标注,比如事件e2的对象在e3中作为客体,则标注为<Participant sid=“s2”oid=“s3”>,或者是一个事件的客体在另一个事件中充当客体或主体,也是按以上形式标注.Object类型的对象也是如此.
对于环境要素(见图1),事件e2的发生地点同时也是事件e3和事件e4的发生地点,这时就要在事件e2的环境要素属性lid中进行标注.
对于时间要素(见图2),事件e19和事件e20都是在时间编号为t19的时间段内发生的,这时就在事件e19的属性tid中同时标注出t20.

图1 对象和环境要素的属性标注Fig.1 Attribute labels of object and environment elements

图2 时间要素的属性标注Fig.2 Attribute labels of time elements
2.2.2 标识标注
为了区别缺省要素的属性标注,加入eAnaphora标识用以进行事件中已存在要素以及事件的指代标注,详细表示为<eAnaphora anaType=“”aid=“”antecedent=“”rid=“”anaphor=“”/>.
(1)属性anaType表示指代类型,即哪种要素的指代,或是事件的指代.若是对象要素的指代,属性值为Object;若是时间要素的指代,属性值为Time;若是环境要素的指代,属性值为Location;若是事件的指代,属性值为Event.
(2)属性aid表示指代中的先行要素(或先行事件)的顺序编号,属性antecedent表示指代中的先行要素(事件指代标注没有这个属性).
(3)属性rid表示指代中的照应要素(或照应事件)的顺序编号,属性anaphor表示指代中的照应要素(事件指代标注没有这个属性).
所以,标识标注共有4种类型表示各要素及事件的指代,如图3所示.
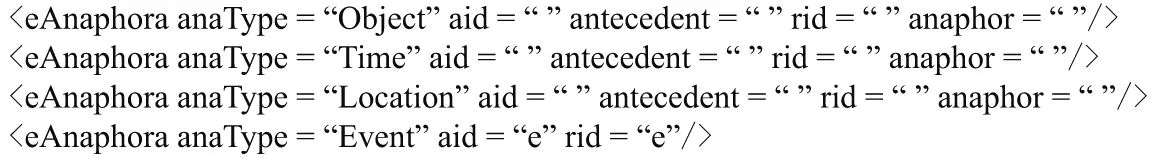
图3 标识标注Fig.3 Identification labels
2.3 标注过程
基于CEC的指代标注分为语料库的预处理、自动标注和人工标注三个过程,下面对标注规范进行说明.
2.3.1 标注规范说明
标注规范的制定,可以在一定程度上缩小不同标注者在标注时的差异,减少语料标注过程中的错误和不一致性,提高标注的效率.面向事件的中文文本指代标注与传统文本的指代标注是有差别的,对于缺省要素的标注在2.2节已作了说明,这里仅对已存在要素和事件的标注作简要说明.
(1)对象要素:事件中对象要素有两种语义类别,在语料库中分别以Participant和Object这两个标识进行标注,前者与人有关,后者与物有关,所以它们不属于一个语义类别,是不能相互指代的.
(2)环境要素:对于环境要素的标注,除了标注指向同一地理位置的要素,还要进行基准类型的标注,即通过先行环境要素,可以将照应环境要素的地理位置具体化.例如,“香溪洞景区”←“附近山体”,通过这种指代,可以将照应要素的地理位置具体化,可得知具体是在什么地点附近.
(3)时间要素:时间要素与环境要素类似,除了标注指向同一时间的要素,也要进行基准类型的标注.例如,“27日傍晚6时左右”←“随后”,通过这种指代可以确定随后是以哪个时间为基准.
以上是针对要素的标注规范说明,事件的指代标注与事件要素的指代标注是有区别的,事件包含对象、时间、环境等各个要素,即事件是由要素组成的.而事件要素的指代没有考虑事件之间的关系,只将两个要素单独进行指代关联.事件之间的指代,需要将各要素综合起来考虑,有时还需要联系上下文,根据上下文来判断两个事件是否表示同一个事件.
规定两个事件具有指代关系的标准如下.
(1)因为事件的触发词直接描述了事件,所以首先比较两个事件的触发词是否相同或同义,若是,则进行下一步,否则两事件无指代关系.
(2)比较两个事件各要素,因为每个事件必须包含触发词,而其他要素可能缺省,不会出现,所以要根据上下文补全缺省要素,然后判断两事件是否具有指代关系.具有指代关系的两事件的各要素必须一致,即指向现实中的同一实体.
通过上述两步就可以确定事件间的指代关系.
2.3.2 语料库的预处理
CEC中没有对标识为ReportTime的报道时间进行编号,由于ReportTime在时间要素的指代标注中可以作为基准时间,因此在标识中加入属性tid,属性值为t0.另外,CEC语料在最初标注时,没有考虑到指代消解的研究,所以对于对象要素的标注粒度没有作一定的规范限定.这里规定为粗粒度标注,即将修饰对象的一些修饰语连同对象一起标注,因为这些修饰信息往往包含了对象的职业、身份等有价值的信息,在以后的对象要素指代消解中,可以将抽象的对象要素具体化.例如,“中国地震局新闻发言人张宏卫”←“张宏卫”,这种指代的识别就可以得到照应要素的具体身份,对基于事件的推理提供帮助.
2.3.3 自动标注
在自动标注阶段,基于缺省要素标注的复杂性,仅对已存在要素和事件进行标注.对于已存在要素,通过简单的字符串匹配规则,采用标识标注形式进行标注;对于事件,通过对触发词进行同义词的检测方法,采用标识标注形式进行标注.
2.3.4 人工标注
在人工标注阶段,要安排3个人工作.首先,安排两位标注者对自动标注阶段生成的指代链进行校正;然后通过文本进行补全,包括自动标注阶段没有识别出的指代,以及缺省要素的指代标注;两位标注者在标注期间不准商量,两位标注者完成标注后,由第三个人进行仲裁.仲裁者首先找出两位标注者之间的差异,针对这些差异,通过外部知识来解决分歧,确定最终的指代链.
2.3.5 指代链输出
经过上述步骤后,就会得到最终的标注结果.缺省要素的标注结果已在图1和2中展示,图4是已存在要素和事件的标注结果.

图4 指代链Fig.4 Coreference chains
2.4 标注工具
标注规范的制定可以减少语料的不一致,而方便、高效的标注系统可以大幅度提高标注的效率和准确性,防止标注者出现误操作.图5是面向事件的中文指代语料标注工具界面,左边的空白处是对生语料进行事件要素、指代关系等标注的文本框,右边是添加XML标识以及各标识的属性,顶栏是工具栏.为了减轻标注者的负担,该标注软件提供了自动检查的功能,可以防止文档中出现不合法的标识,在一定程度上防止错误的语料进入语料库.

图5 标注工具Fig.5 Annotation tool
3 语料库的统计与分析
3.1 一致性检验
为了保证语料标注的质量,两位标注者同时对语料库进行标注,目的是进行标注结果的一致性检测.本工作采用Passoneau[15]提出的语料库指代标注可靠性计算方法,并根据Krippendorff[16]的alpha系数来表示两位标注者标注结果之间的一致性.该方法通过一个距离度量来表示指代链之间的相似度,然后通过alpha系数计算指代链之间的相似度距离来表示不同标注者标注结果之间的一致性.
Passoneau相似度距离度量原则如下.
(1)当两条指代链完全吻合时,距离为0;
(2)当一条指代链是另一条指代链的子集时,距离为0.33;
(3)当两条指代链不互相包含且有公共的非空子集时,距离为0.67;
(4)当两条指代链交集为空集时,距离为1.
按照以上原则,根据两位标注者的标注结果,计算得到alpha系数为94.6%.Krippendorff认为,低于67%的alpha系数表明标注结果不可靠,因此认为两位标注者的标注结果高度一致.
3.2 语料库分析
目前已经标注完的语料共有100篇,其中地震、火灾、交通事故、恐怖袭击和食物中毒各20篇.这是第一期的标注,旨在确定标注流程和规范,对其中的指代进行了统计分析,在以后的工作中,会进一步基于CEC的剩余部分进行标注,并继续扩大.
3.2.1 指代分类
通过对已标注语料进行统计,对已存在要素的指代可以进行如下分类.
对于对象要素,可以分为如下4类.
(1)表述相同,即存在指代的两个要素的字符串完全匹配,例如“中国地震局新闻发言人张宏卫”←“中国地震局新闻发言人张宏卫”;
(2)缩略指代,即存在指代的两个要素中,照应要素是先行要素的一部分,例如“滚滚浓烟”←“浓烟”;
(3)表述不同,即存在指代的两个要素在文字表达上不同,两个要素间可能一个是另一个的别名,或者根据上下文,两个要素都指向同一个实体,例如“中华人民共和国”←“中国”,“修理巷道的20名矿工”←“被困人员”;
(4)代词类指代,即存在指代的两个要素间,一个要素为代词,例如“李女士”←“她”.
对于环境要素,可以分为5类,其中前4类与环境要素相同,下面只举例说明.
(1)表述相同,例如“医院”←“医院”;
(2)缩略指代,例如“四川省汶川县”←“四川汶川”;(3)表述不同,例如“四川省汶川县”←“灾区”;
(4)代词类指代,例如“750~850米处巷道”←“该段”;
(5)基准指代,此类指代与前4类是不同的,也是面向事件的指代与传统指代的不同点,前4类中存在指代的两个要素都是指向同一实体,而此类指代并非指向同一实体,而是以先行要素为基准,来确定照应要素的具体位置,例如“香溪洞景区”←“附近山体”.
对于时间要素,可以分为如下2类.
(1)同一时间,即存在指代的两个时间要素指向同一时间,例如“昨晚8时30分许”←“此时”;
(2)基准指代,与环境要素中的基准指代相似,是以先行要素为基准时间来确定照应要素的具体时间,例如“27日傍晚6时左右”←“随后”.
3.2.2 指代统计
在已标注的100篇语料中,共有1 767个事件,1 623个对象要素,522个环境要素,539个时间要素,其中对于已存在要素的指代数据如表2所示,缺省要素的指代数据如表3所示,各类事件的指代数据如表4所示.
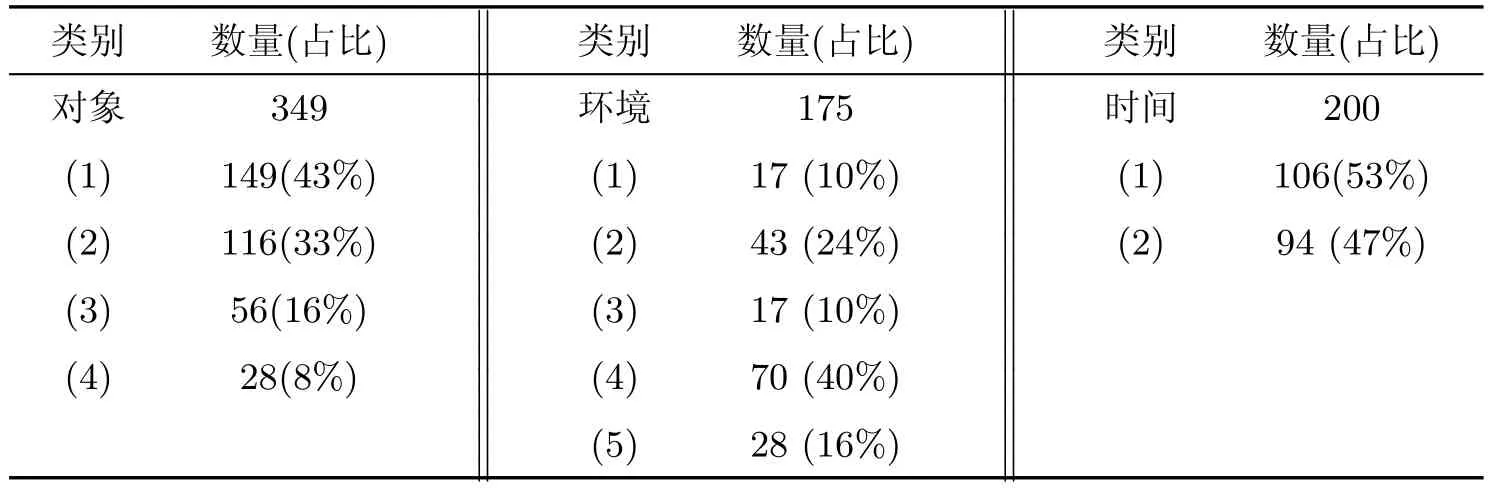
表2 已存在要素的指代统计Table 2 Coreference statistics of existing elements 个

表3 缺省要素的指代统计Table 3 Coreference statistics of default elements 个

表4 各类事件的指代统计Table 4 Coreference statistics of several kinds of events 个
3.3 语料库分析
3.3.1 已存在要素指代分析
对于事件中对象、环境和时间的已存在要素的指代,表2已详细统计了每个要素的指代数量,以及每个要素的不同类别的指代数量.对每种要素中的指代进行分类,可以对后续研究中实现各个要素指代的自动识别提供帮助,也可以帮助设计者思考如何设计算法来达到更优异的系统性能.
对象要素和环境要素的前4类与传统文本中的指代消解有许多共性,其指代的都是同一实体,这里不再分析,只进行环境要素的基准指代和时间要素的分析.
环境要素中的基准指代与传统意义上的指代有所不同,存在指代关系的两个要素并不是指向同一实体,而是一种关联关系,即通过先行环境要素来确定照应环境要素的具体位置.从表2中可看出,这种类型的指代占整个环境要素指代的16%,所以其识别与否对于指代消解系统的性能有显著的影响.在已标注的语料中,对这种指代关系进行统计得出,照应环境要素基本上都是以“周围”“附近”“外面”这种抽象的地理位置词开头,可以通过构建一个抽象环境要素的词典进行识别,然后再找出其对应的先行要素.这仅仅是初步的构想,具体实现还要综合各种因素进行考虑.
时间要素中的基准指代与环境要素是类似的,有别于传统意义上的指代,并且对其识别也与环境要素类似.在已标注语料中,具有此类指代关系的两个时间要素,其照应要素大多是“昨天”“今天”等抽象时间词,可通过构建一个抽象时间要素词典进行识别,再找出其对应的先行要素.对于同一时间的指代,在标注中发现,具有此类指代关系的两个时间要素,照应要素也是一些抽象的时间词,比如“现”“当时”等,因为语料都是新闻题材类的文本,所以“目前”和“现”大多指代的是新闻的报道时间,而对于“当时”,其先行时间一般出现在前一个事件中或与其最近的且包含时间要素的事件中.
3.3.2 缺省要素指代分析
在语料库中,一个完整的事件应该包含对象要素、环境要素、时间要素和触发词,其中对象要素又包含主体和客体,也就是说,一个完整的事件应包含6个部分,而触发词是每个事件必须含有的,其他3个要素可以省略.为了描述各个要素的缺省程度,这里用“缺省度”来衡量:

已标注语料中各要素的缺省量如表5所示.

表5 事件中各要素缺省量Table 5 Default number of each elements in events 个
通过计算得到对象要素的缺省度为51%,环境要素的缺省度为73%,时间要素的缺省度为75%,由此可看出,环境要素和时间要素的缺省程度较大.但这里对对象要素的统计没有区分主体与客体,不能准确表示对象要素的缺省度,所以又对主体与客体的数量进行了统计,如表6所示.

表6 事件中主体与客体缺省量Table 6 Default number of subject and object in events 个
这里假设每个事件都应存在主体与客体,从表6中可以得到对象要素中主体的缺省度为57.2%,客体的缺省度为88.5%,客体缺省度远远大于主体缺省度.
缺省要素的指代消解分为两个步骤:缺省要素的指代识别和缺省要素的指代消解.对于缺省对象要素的指代识别,其难度要比环境要素和时间要素要大,因为一个事件肯定发生在某个时间的某个地点,也就是说一个事件中环境要素和时间要素只要不存在就可判断为缺省.而对象要素在一些事件中是可以不存在的,即要对对象要素是否缺省进行识别,而且对象要素又分为主体对象和客体对象,这就进一步加大了识别的难度,要判断是缺省客体还是缺省主体,还是主体与客体都缺省.从语料库中发现,对于一些事件,主体和客体的缺省与触发词有关,包含某些特定触发词的事件往往不包含对象要素,有的只缺省主体或者缺省客体,有的主体和客体都缺省,不过这只是初步构想,对于对象要素缺省指代识别,还需进一步研究.
将表3和5进行比较发现,各要素标注出的缺省指代数与各要素的缺省量不一致,那是因为缺省要素的标注只能根据篇章中已经存在的要素进行缺省要素补全,而一些事件的缺省要素在文中是没有描述的,这时是不能进行补全的,也就是说缺省指代只能根据已存在要素在一定程度上补全缺省要素.
3.3.3 事件指代分析
从表4的统计结果来看,事件的指代数量还是比缺省要素少,在5个事件类中,交通事故和恐怖袭击中指代的比例较高,这说明在这两个题材的新闻报道中,同一事件被重复提及的概率较大.事件指代的目的与缺省要素的指代一致,是将缺失若干要素的事件通过一篇文章上下文中的具体事件进行补全.只不过事件指代针对的是同一事件,而缺省要素的指代既可以针对同一事件,也可以针对不同事件.
对于事件的指代,从3.3.1节中提及的关于事件指代的标准可以看出,事件的指代有两个关键点:事件触发词和事件要素的组成.对于具有指代关系的两个事件,其触发词肯定同义或相同,因为触发词直接描述了事件.只有触发词相同还无法判定,触发词相同只能说明事件间属于同一个事件类,而不是同一个事件,还要通过判断两个事件各自的事件要素的组成,才能最终判定.
4 结束语
面向事件的中文指代语料库是在CEC的基础上,采用自动标注和人工标注的方法构建而成,以此进行事件中指代消解的研究.目前已标注完成100篇,第一期标注的语料已基本完成.本工作在已标注语料的基础上,通过对已存在要素指代、缺省要素指代和事件指代的统计,进行了初步分析,为今后的研究打下基础.
任何语料库的构建都不可能是完美无缺的,肯定会存在一些问题和不足,由于本工作所构建的语料库是基于CEC的,所以规模较小,在今后还要利用自动或手工的方法进一步扩充,循序渐进地改进,在今后的研究中不断完善.
