第三十二讲 类系化合物构效关系研究案例分析
2019-01-07徐静安贺少鹏商照聪
徐静安 贺少鹏 商照聪
多年来参与一些项目的评审,研究生论文的答辩,相关专业文献的查阅等,笔者感受到随着计算机软硬件技术的发展,20世纪80年代以来,化合物的定量结构-活性/性质相关性(简称构效关系,英文缩写QSAR/QSPR)逐渐成为研究的热点。2018年2月7日上午,笔者应邀参加在华谊集团大厦举办的煤基多联产工程中心和计算化学化工工程中心技术委员会的年度会议,会上,计算化学也受到了工程界的重视。
上海化工研究院科研工作也进行了相应的安排、探索。2006级硕士研究生贺少鹏,其学位论文“有机污染物的正辛醇/水分配系数预测及QSPR研究”,导师是徐大刚、刘刚二位教授级高工。笔者作为研究生办公室顾问一直跟踪项目和参与讨论。2009年3月笔者还从贺少鹏处借阅《化学计量学方法》,阅读后2011年网购了几本赠与有关专业人员学习、应用。2012年又阅读了商照聪、贺少鹏的论文“有机污染物分配系数(正辛醇/水)预测软件比较研究”。
2013年院部采购了IBM高性能小型机;2014年,购置了DPS软件,还和上海应用技术大学共建共享配置了VASP软件;2015年院部购置了Gaussian软件。此外,研究院还在2013年和2014年针对性地招聘了量子化学软件应用的专业人员。
在材料、生物、环境等科学领域,构效关系研究在宏观、介观及微观层面展开,本文讨论的是分子尺度的化合物构效关系。
一、建立构效关系模型的主要步骤
根据《有机污染化学》(王连生编著),建立QSPR/QSAR模型的主要步骤见图1。具体如下:
1 训练集化合物的选择
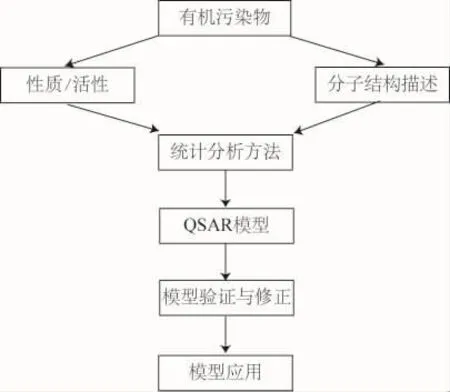
图1 建立QSAR/QSPR模型的主要步骤
根据一定的统计标准和结构标准选择类系化合物,作为建模的训练集。化合物选择的条件为:统计上的随机性、结构上的代表性和全面性,以及性质/活性数据的可获得性。
2 性质/活性数据的获得
数据收集的方法主要有3种:科学文献的查阅、收集;性质/活性数据库中获取;实验室中测试。一般来说,性质/活性数据有两种:连续响应数据(例如水溶解度等)和非连续分类、分级响应数据(例如致癌性的阳性/阴性、毒性等级等)。
3 分子结构描述符
首先应用分子模拟方法,构建正确的二维或三维分子结构,采用构象分析、分子力学等方法获得最优化的构象;采用拓扑学方法、量子力学方法等计算化合物的分子结构特征参数,获取分子的结构信息,进行分子结构描述。
4 QSAR模型构建
应用特征变量筛选方法筛选描述符,应用统计方法或其他建模方法将训练集有机化合物的性质/活性数据与分子结构参数数据建立QSAR模型。常用的统计分析方法有回归分析、偏最小二乘分析、因子分析、主成分分析、聚类分析等,其中多元逐步回归分析是应用最多的方法。近年来,人工神经网络和遗传算法等高级建模方法也得到了关注和应用。
5 QSAR模型的评价和验证
模型的评价主要针对:模型的拟合优度、稳健性和预测能力。在回归分析中,模型的拟合优度采用回归系数的平方(R2)或自由度校正的R2(R2edj)、显著性水平、检验值F、标准偏差s等参数来评判。模型的稳健性一般采用交叉验证方法来进行检验,通常有两种方式:逐一剔除法(即留一法)和分组剔除法(即留多法)。得到的交叉验证的R2(q2)和标准预测误差(SEP)用来评价模型的稳健性。模型预测的验证是构建一个测试集,用训练集建立的拟合模型来预测测试集化合物的性质。只有具有统计上的显著性、稳健以及具有高度预测能力的模型才能够进行应用。
6 QSAR模型的应用
应用有三个方面:一利用模型对其他未知化合物的相关性质/活性进行预测,在效应评价和暴露评价等方面可弥补缺失的数据,对有机化合物进行筛选和评价;二根据模型的组成与形式,结合已有的化学、生物学知识,探求有机化合物的毒理性质、环境过程和生态效应等机理分析;三根据所阐明的结构-性质关系结果,为设计目标化合物指明方向。
二、案例一
选取自《化学计量学方法》。化合物的结构是个三维图像,对于化合物分子尺度构效关系的研究,就是将结构图特征参数与其性质/活性去构造相关的数学模型。主要参数类型有(1)拓扑类参数;(2)几何类参数;(3)电子类参数;(4)理化性质类参数;(5)综合类参数;等。构效关系模型建立的目的是对新的未知样本进行预测。
案例为50个酚类化合物麻醉毒性的QSAR研究,样本量N=50,提取可能影响麻醉毒性的结构特征参数有M=135个变量,经过变量筛选获得构效关系的统计模型、多元线性回归方程:

式中:SHDWi——分子投影面积;

按全回归分析方法,自变量M=135,样本量N=50,此回归模型无法求解。由于有的自变量——结构特征参数对其响应参数不显著,特别是分子描述符参数之间普遍存在共线性关系,所以结构特征参数的提取、筛选是构效关系研究的关键。应用数据处理方法,本例经筛选进入模型的自变量m=9,大大简化了模型。本例M=135,选用最简单的多元线性回归,可能构成的模型有2M-1=2135-1;如果选用二次多项式回归,仅考虑一次项和二次项,可能构成模型有(22M-1)个。采用穷举法时计算工作难以操作,由此研究产生若干变量筛选算法。
传统的变量筛选方法有前进法、后退法、逐步回归法、最佳子集法;常用的逐步回归法已可有效筛选变量。在多元回归分析中,亦有使用主成分分析法、正交变换法筛选变量。如果多元线性回归建模效果不好,研究对象较为复杂,基于MIV的人工神经网络法、自变量降维的遗传算法,以及针对小样本的支持向量回归法(SVR)等值得关注。
作为应用案例,本案例模型尚应进一步进行预报测试的评估与验证检验。
三、案例二
选取自“有机污染物的正辛醇/水分配系数预测及QSPR研究”。将美国国家环境保护局推荐的105种优先毒性污染物作为考察对象,即样本量N=105。按化学结构可分为卤代(烷、烯)烃类,苯系物,酚类,多环芳烃类,亚硝胺类等10个类系化合物。响应分配系数实验值选自SRC公司的PHYSPROP数据库。
资料表明,对于分子描述符现已开发出上百种拓扑指数,原文列举常用的拓扑指数38种,几何结构性质描述符24种,量子化学描述符35种,溶剂化描述符13种及理化性质10余种等等。原文用现有的采用不同特征参数的10种估算分配系数的软件(ALOGPs,AC logP,AB/LogP,COSMOFrag,miLogP,ALOGP,MLOGP,KOWWIN,XLOGP 2,XLOGP 3) 对105 种污染物进行了计算分析。其中ALOGPs采用拓扑指数等描述符、KOWWIN采用碎片常数法进行预测估算,预测效果相对较好,其他软件对此分配系数的性能预测偏差较大。为进一步改进提高有机污染物正辛醇/水分配系数logP的预测性能,原文探索筛选新的特征参数构建QSPR新的模型。
分子描述符的计算提取。先使用ChemBio3D Ultra11.0软件将105种有机物的二维分子结构转化为三维结构式,并使用内置的MM2分子优化软件计算出能量最低的状态,进行能量优化,使用MOPAC软件进行几何构型优化。再使用Chem3D软件计算29种分子结构描述符,其中有:分子面积、椭圆度等7种结构性质描述符;总能量、生成热等8种量子化学描述符;分子拓扑指数、分子半径等14种拓扑描述符。此外,根据研究文献表明有机物的分配系数与其水溶解度logSw和相对分子质量Mw有很大关系,相对分子质量根据结构式计算可得,水溶解度数据取自SRC公司的PHYSPROP数据库。共提取特征参数M=31个。
对特征参数进行初筛选一般采用变量零值检测、偏差测试、相关性测试、共线性测试。由于多元线性逐步回归同时完成变量剔除和模型建立,本例采用此主体技术。
log Pow的QSPR模型:
(1)对7种结构性质描述符建模;
(2)对8种量子化学描述符建模;
(3)对14种拓扑描述符建模;
(4)对水溶解度、相对分子质量建模;
(5)对31个描述符综合建模。
经多元线性逐步回归,模型统计量汇总见表1。

表1 模型统计量汇总
由表1可见,综合参数模型拟合性能最优:
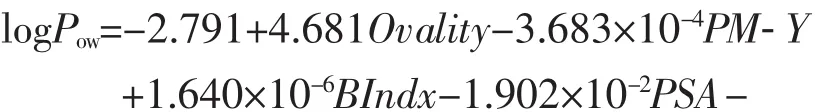

模型中:Ovality——分子椭圆度,
PM-Y——惯性主矩的y分量,
Bindx——Balaban指数,
PSA——分子极化表面面积,
logSw——水溶解度对数值,
Mw——相对分子质量。
从数理统计角度,此构效关系模型拟合性能具有显著的统计意义,尚应对模型预报性能进行评估验证。
内部验证。采用留一法预测标准偏差。
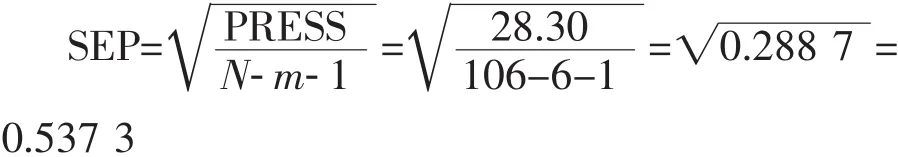
预测相关系数平方:
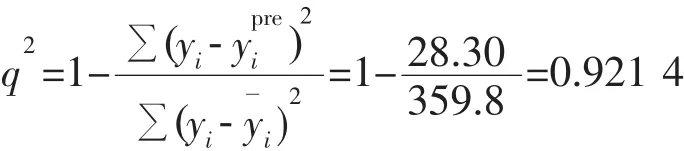
预测和拟合相关系数及标准偏差变化不显著,模型具有稳定性。
外部验证。对新考察的①萘、②苯甲酸甲酯、③苯甲酸乙酯、④苯乙酮、⑤二苯醚、⑥肉桂醇、⑦溴苯、⑧苯甲酸苄酯8种有机物,使用高效液相色谱实验测定正辛醇/水分配系数,使用上述软件计算6项参数。参数计算值、响应预测值、实验值见表2。
外部验证的标准偏差
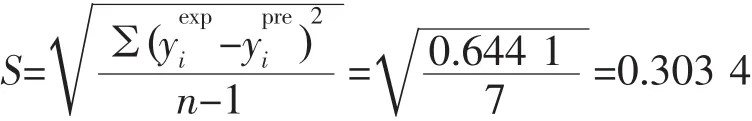
验证标准偏差相对稳定,具有统计意义。2004年QSAR国际会议正式形成经济合作与发展组织(英文简称OECD)规则,明确必须使用外部验证集(即测试集)来评价模型的预测能力。如果样本量足够大,也可以从105个样本中随机取8个样本作为测试集,97个样本作为训练集。本案例执行该规范。
四、案例三
选自上海交通大学环境科学与工程学院的“Fenton法降解有机物的热力学及构效关系研究”一文。2017年11月29日笔者在院内彭东辉教授级高工实验室讨论高浓度有机废水处理项目时阅读到此文,值得推荐。
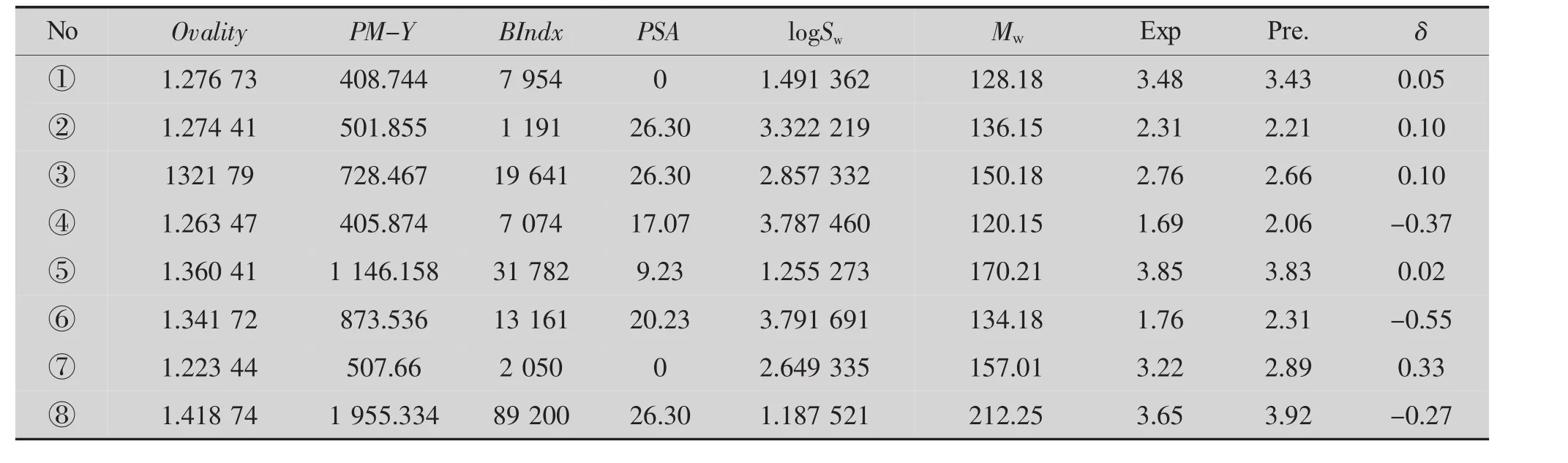
表2 外部验证数据汇总
案例针对有机废水中的①3,4-二氯苯胺、②对氨基苯磺酸、③ 2,4-二硝基苯肼、④ 双酚A、⑤ 酸性橙、⑥间甲酚紫6种有机污染物,实验探究了不同温度下Fenton氧化降解有机物的去除率及反应动力学;在Fenton试剂过量、假定反应初期为一级反应动力学速率常数的基础上,通过Arrhenius方程计算获得6种有机物的Fenton反应活化能Ea。
本文侧重讨论了结构参数与活化能之间的构效关系。根据现有资料,案例利用Hyperchem8.0软件初步优化6个有机物的结构,再用Gaussian09软件进行深度优化,利用Materials Studio软件进行参数计算。选取了19个量子化学结构参数,其中16个由软件计算获得,3 个为组合参数(EGAP,E2GAP,EHOMO+ELOMO),各参数的物理意义见表3,各参数值及与Ea的相关性见表4。
由于论文报道的仅仅是研究工作的阶段内容,样本量为N=6,结构特征参数M=19,还无法构建构效关系模型,但可以进行初步分析:
(1)先计算单一特征参数和活化能的相关关系,见表4。

表3 量子化学结构参数
表4参数与Ea间相关系数大于0.5的项数11/19=58%,而且大于0.7的项数有2项,粗略判断初选的结构参数是有效的。如果相关性普遍较低,就应考虑调整、扩充特征参数的选择范围。
(2)从案例一、二及相关资料分析可知,在构效关系研究中,由于化合物分子特征参数对化合物性能响应不同,很多参数对某一响应是不显著的;更为普遍的现象是显著项特征参数间还存在共线性现象,所以M项特征参数经筛选仅有限的m项进入构效关系模型。
(3)所谓共线性是指成对自变量(特征参数)之间的相关性。当相关性较高时,表示一个变量的信息含有对应变量的信息,可以剔除一个变量。如同时引入统计模型,除了增加计算工作量外,还会使模型计算性能变差。
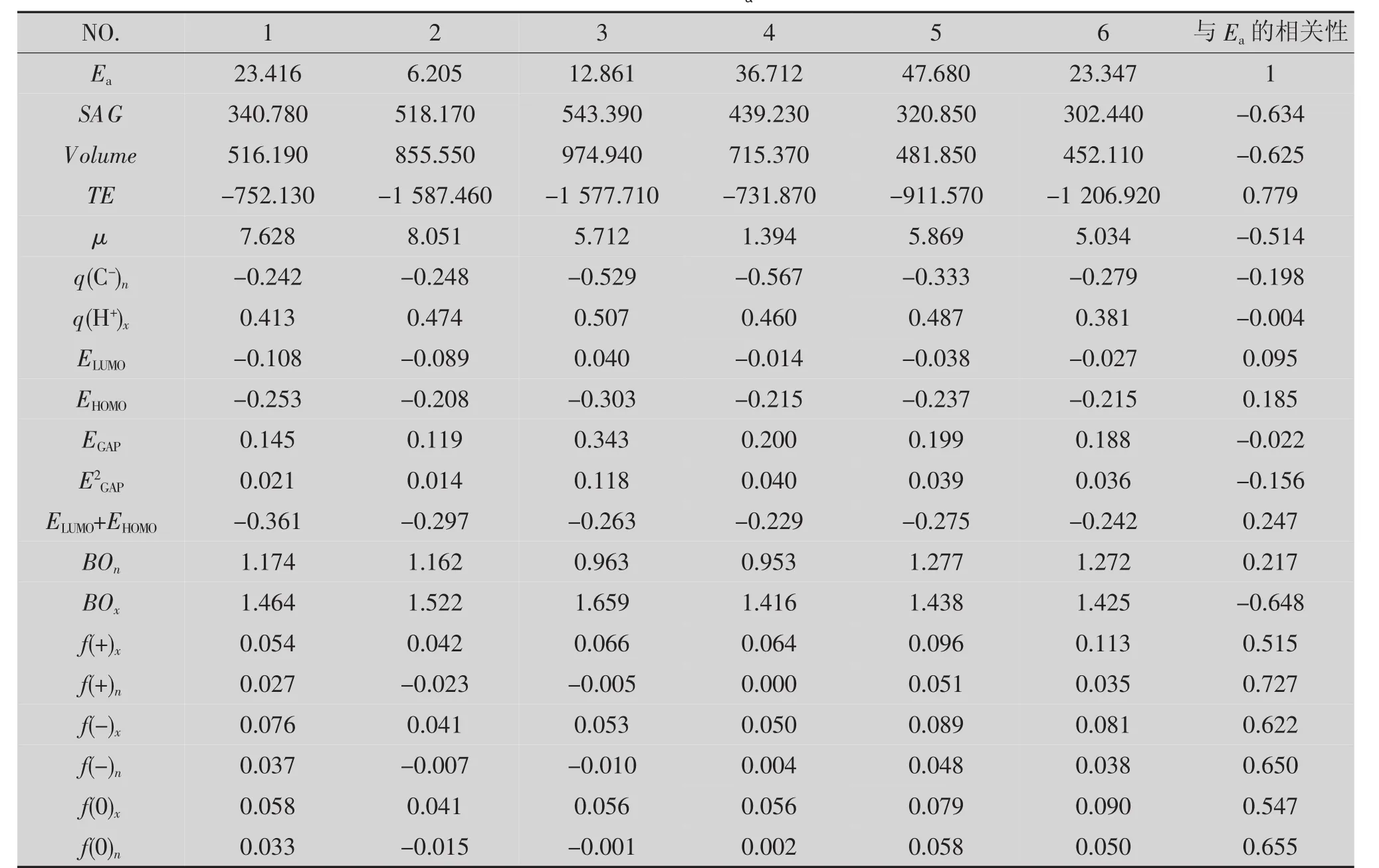
表4 各参数值及与Ea的相关性
本讲义第四讲回归分析中的变量筛选技术及统计检验(《上海化工》、2016年第8期)已做详细讨论。现再简单引用,原案例是4个变量的多元线性回归,计算机在逐步回归建模时,自动计算输出变量间的相关性,如表5所示。
x1与 x3相关系数 R=-0.824,P=0.001<0.05;x2与x4的 R=-0.973,P=0.000。可见:x1与 x3,x2与 x4均为显著相关,建模时将作剔除处理。
(4)由于构效关系研究中样本选择是随机的,多维空间结构参数的数值分布也是随机的,构建构效关系模型一般要求N/m≥5,一定的样本量保证模型的稳定性,所以完成本案例构效关系研究尚需一定的实验工作量。

表5 四个变量间的相关性
后记:在本讲义编写中,贺少鹏提交了第一节的文稿并提供同济大学的“QSAR模型内部和外部验证方法综述”等3篇资料。笔者2017年已欣然为贺少鹏写推荐信,现其正在此领域选题攻读在职博士。
