基于改进卷积神经网络的多源数字识别算法
2019-01-07卜令正王洪栋朱美强
卜令正,王洪栋,朱美强,代 伟
(中国矿业大学 信息与控制工程学院,江苏 徐州 221116)(*通信作者电子邮箱zhumeiqiang@cumt.edu.cn)
0 引言
随着经济的发展和社会的进步,生活中数字的应用越来越广泛,使用场景也越来越丰富,对应的自然场景数字识别需求也迅速增长,其中也有多种类型数字混合的场景识别需求。例如,电测量数字显示仪表的印刷电路板检测中,板载电子元器件上有多种不同类型阿拉伯数字,仪表上电显示的数字为八段数码管。又如,图1(a)所示的报销单识别中,单据既包含打印体的金额、日期编号等信息,又包含修改的数量、金额等手写数字信息。因此,研究多种类型混合数字的识别有较高的现实意义和经济价值。
作为光学字符识别的一个重要分支,数字识别的研究由来已久,其识别方法主要分为模板匹配法、基于特征的机器学习方法和深度学习方法。传统的数字识别方法多是利用数字本身的特征进行识别。例如:陆靖滨等[1]提出了改进最大类间方差法对数显数字仪表图像字符自适应提取,用穿线法实现数字的自动识别;董延华等[2]基于模式识别技术,通过改进的特征匹配算法改变了特征向量并增加学习次数;陈玮等[3]提出了基于欧拉数的模板匹配,将模板图像进行分组,只将目标图像与具有相同欧拉数的模板进行匹配。上述传统数字识别方法易受环境因素影响,背景的变化、数字的浮动和漂移、光照的强弱对识别效果都有较大的影响,在图像质量退化时识别率较低。
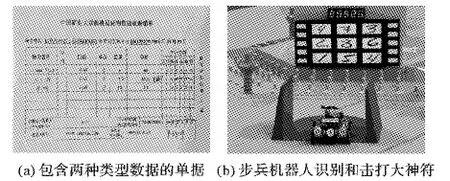
图1 多源数字的不同应用Fig. 1 Different applications of multi-source digits
机器学习的发展为模式识别提供了新的方法,在数字识别中也被广泛地使用。甘胜江等[4]对K近邻(K-Nearest Neighbors,KNN)和随机森林方法进行改进,将KNN分类器的多元输出转化为二元输出;然后,构建随机森林各个决策点的决策函数,对手写体数字进行分类。Tuba等[5]用基于投影直方图的手写体数字识别算法,使用仔细调整的45个支持向量机(Support Vector Machine, SVM)进行分类。潘虎等[6]将二叉树型结构和快速Adaboost训练算法结合起来,将纸币号码识别问题转化为一系列Adaboost二分类问题。传统的机器学习方法多数需要人工提取图像特征,特征提取的好坏对识别结果有至关重要的影响,不同样本库识别效果可能会有较大差别;样本的数量与质量对识别效果也有影响。例如:在KNN当中,因要与数据集中样本依次比较,增大数据集会降低识别速度;而在SVM中样本质量越高,分类效果越好。
深度学习不需要人工特征提取,而是在模型学习中自动逐层提取特征,在数字识别方面得到了广泛的研究与应用。Lecun等[7]提出了LeNet卷积神经网络(Convolutional Neural Network, CNN),是特征自动提取的多层学习算法,最早应用于邮政编码中的手写体数字识别;Alani[8]提出了一种使用受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)和CNN相结合的深度学习算法,对阿拉伯式手写数字进行识别;Singh等[9]提出了一种使用计算统一设备架构(Compute Unified Device Architecture, CUDA)识别数字的深度CNN(Deep CNN, DCNN);Sabour等[10]提出了胶囊网络,在识别高度重叠的数字方面比传统的卷积神经网络更好。对于大样本自然环境数字识别问题,深度学习方法在识别率与鲁棒性等方面均优于传统机器学习方法。
已有的数字识别研究工作多针对单一类型数字进行识别,对多源混合数字进行识别的研究较少。在上述研究中,卷积神经网络对于大样本数字识别问题具有训练简单、泛化能力好的优点。本文以RoboMaster机甲大师赛中移动步兵射击机器人识别数码管与手写字体,并击打相应的九宫格为背景(如图1(b)所示),研究基于改进卷积神经网络的多源数字识别方法。
1 RoboMaster多源数字识别场景
RoboMaster机甲大师赛是国内首个激战类机器人竞技比赛,参赛队伍需自行研制多种类型的机器人进行协同作战。在比赛的能量机关激活环节,也称大神符环节,全向移动步兵射击机器人通过读取地上固定的无线射频识别(Radio Frequency IDentification, RFID)卡,激活其正前方的触摸屏屏幕。触摸屏屏幕上方为数码管密码显示区域,下方为九宫格手写数字显示区域,具体见图1(b)。机器人在本体的固定位置上安装有识别摄像头,以第一视角获取前方图像。
比赛时,机器人需要通过摄像头先识别数码管区域的5个密码数字,然后控制射击机构依照顺序用塑料子弹击打九宫格区域内对应的手写数字。九宫格区域内的手写数字每1.5 s更新一次,每次只有一个手写数字与数码管密码区内的某个数字一致。步兵射击机器人只有正确识别两类数字,并按照数码管数字顺序连续5次成功击打九宫格内的手写数字,才算成功完成这项任务。比赛在室内场馆进行,光照强度适中,分布相对均匀,但也有一定的明暗变化。
2 多源数字识别流程
多源数字识别算法流程如图2所示,主要包含四个步骤:
1)从视频文件中获取含有待识别大符的图像,对数码管数字和九宫格手写体进行定位,图3为定位结果;彩色图转化为灰度图进行边缘检测,然后查找轮廓。手写体数字部分,按照轮廓面积、轮廓最小包围矩形的长宽比与旋转角筛选出9个满足条件的最小包围矩形,从而确定九宫格中手写体位置。数码管部分依据与九宫格的相对位置,在原图中用感兴趣区域(Region Of Interest, ROI)框定。

图2 多源数字识别流程Fig. 2 Flow chart of multi-source digit recognition
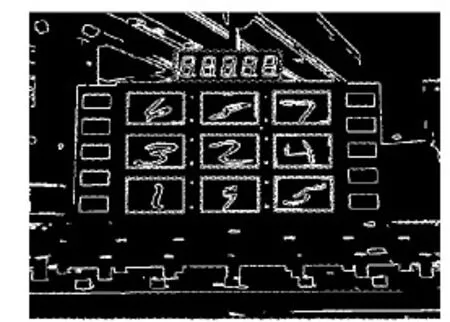
图3 九宫格和数码管定位Fig. 3 Jiugongge and digital tube positioning
2)手写体和数码管提取。手写体部分,依据最小包围矩形,经透视变换将手写体数字变换成40×40正方形数字。数码管部分通过二值化、腐蚀膨胀、滤波去除噪声并进行轮廓查找,以标准矩形包围轮廓;然后拆分5个数码管。
3)对手写体数字和数码管数字进行处理。手写体部分,进行二值化和反二值化,成为与训练集一样的黑底白字,并进行抗扭斜处理、倾斜纠正,数字居中并添加黑边,大小调整为50×50,变化过程如图4(a)所示。数码管部分,将拆分的数码管数字居中并归一化统一大小,结果如图4(b)所示。

图4 验证集数字处理Fig. 4 Digital processing of verification set
4)用Caffe(Convolutional architecture for fast feature embedding)[11]框架下训练好的改进卷积神经网络对分割出来的数字进行识别。改进的卷积神经网络算法详见第3章。
3 基于改进卷积神经网络的识别算法
3.1 训练数据集的产生
训练改进神经网络的混合数据集是MNIST手写体图像和八段数码管仪表提取的图像。MNIST数据集是一个手写体数字数据库[12]。数码管图像是从安科瑞电气股份有限公司13组电子仪表检测线上获得[13]。数据集分布如表1所示。混合数据集部分数字样本如图5所示。
改进的卷积神经网络输出时,基于softmax的概率分类方法,将两种不同形态数字分为了20类[14]。图像数据集转化为Caffe[15]支持并方便大批量数据处理的lmdb(lightning memory-mapped database)格式。虽然Caffe的ImageLayer可以直接读取图像文件,但依次读取几万、十几万张图像时间非常长。lmdb文件结构简单,只有两个文件:数据文件(data.mdb)和锁文件(lock.mdb)。lmdb文件访问简单,只要代码中引用lmdb数据库,给出访问路径即可,减少了I/O开销并使用内存映射的方式访问文件,文件寻址开销非常小。
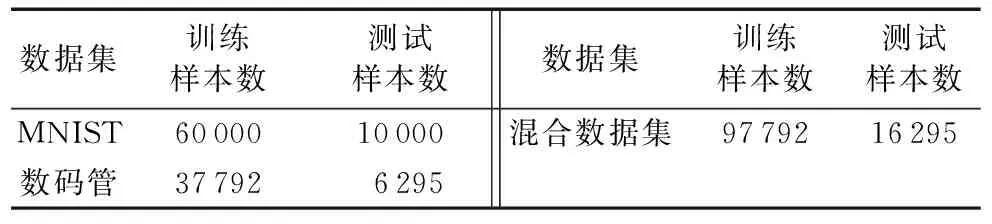
表1 实验用数据集Tab. 1 Data sets for experiments
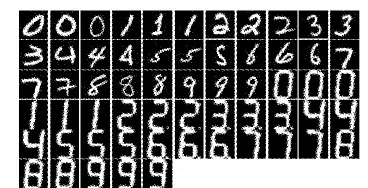
图5 混合数据集部分样本图像Fig. 5 Partial sample images of mixed data set
3.2 改进的网络结构
改进的卷积神经网络结构如图6(a)所示,该网络结构相比图6(b)的LeNet有较多的改进。首先,改进网络在多个卷积层上添加了Relu激活函数,在网络中添加非线性因素,用于加速神经网络的收敛。其次,改进网络参考了如图6(c)所示的AlexNet网络[16],采用dropout函数[17]。dropout函数在训练时随机选取一部分神经元输出取值为0,下次训练时又会恢复保留取值。这样的操作削弱了神经元节点之间的联合适应性,增强了泛化能力,从而避免了过拟合问题。改进的卷积神经网络比LeNet深,能提取更多的特征以增强分类效果。但相比AlexNet结构更为简洁,识别速度比AlexNet更快。
训练时,改进网络模型各层变化与参数配置如表2所示。Accuracy层得到测试集准确率,Loss层采用交叉熵函数作为损失函数获得训练的损失值。测试时,通过softmax分类器得到测试图像的分类结果。
采用随机梯度下降法训练神经网络,学习策略为inv,动量值momentum为0.9。学习率随着迭代次数的增加而降低,可以很好地实现自动调节。学习速率迭代方法如下:
new_lr=base_lr×(1+gamma×iter)-power
其中:new_lr为新的学习速率;base_lr是网络基础学习速率,为0.01;iter为当前迭代次数;gamma是学习率变化的比率,为0.000 1;能量值power为0.75。卷积神经网络训练阶段最大迭代次数为20 000,含有13个epoch。预测阶段迭代次数为163,可以覆盖测试集16 295个图像。
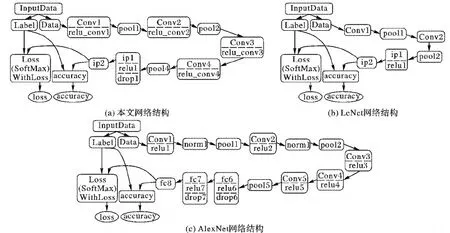
图6 网络结构Fig. 6 Network structure
3.3 验证结果
3.3.1 实验设置
实验所用的电脑配置为Intel Core i5-6300HQ处理器,Nvidia GTX 960M 4 GB独立显卡,16 GB DDR4内存,512 GB固态硬盘,软件平台为Linux16.04下的Caffe深度学习框架,集成开发环境(Integrated Development Environment, IDE)软件为codeblocks16.01。
训练时,图像在神经网络的不同层可生成不同的特征图,将特征图可视化容易看出其中的错误信号。据此可以判断模型的结构设计是否合理,并有针对性地修改网络结构或参数。手写体数字“2”在神经网络各层中的变化如图7(a)所示,层次越深,神经网络提取的特征越抽象。通过卷积核将上一层特征图转化为更高层次、更抽象的表示。特征提取可以很好地剔除掉噪声对神经网络的影响,因此卷积神经网络可以提取更为复杂的图像特征,改进的卷积神经网络才有了较好的识别效果。
判断一个卷积神经网络是否合理的另一种方法是对模型权值进行可视化。对应不同卷积层的权值可视化图如图7(b)所示,其中,从第一个卷积层到第四个卷积层变化的权值图以灰色图的形式表示。卷积核既不是类似于噪声,也不是相关性太高或缺乏结构性,神经网络结构相对合理。
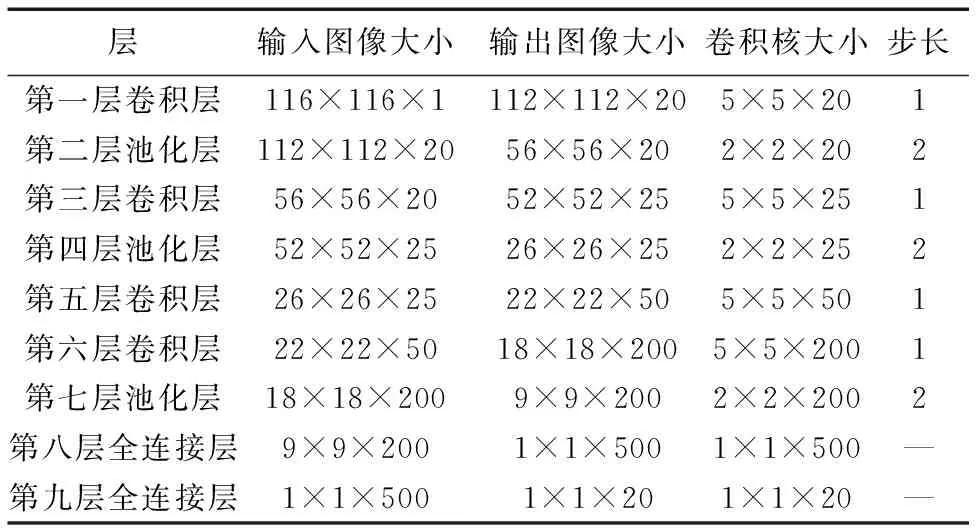
表2 网络模型的参数配置Tab. 2 Parameter configuration of network model
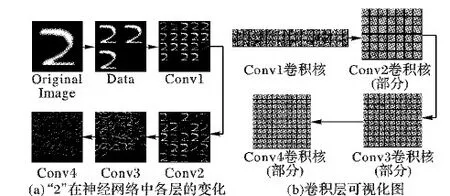
图7 图像和卷积权值的逐层变化Fig. 7 Layer-by-layer changes of images and convolution weights
改进的卷积神经网络训练得到的日志数据中,有测试集损失值与准确率随着训练迭代次数的变化,以及训练集损失值随训练迭代次数的变化,结果如图8所示。
如图8(a)所示,选取前10 000次迭代的softmax损失值。由图8(a)可以看出,随着迭代次数的增加,训练集和测试集的损失值都不断减小;训练集损失值快速下降,中间稍微有一
些波动,但整体呈下降趋势;测试集损失值下降过程中波动不大,但一直在不断降低;最终损失值都收敛到0.05以内,完成优化。如图8(b)所示,训练前期测试集准确率随着迭代次数的增加快速上升,准确率达到99%以后变化趋于平稳。
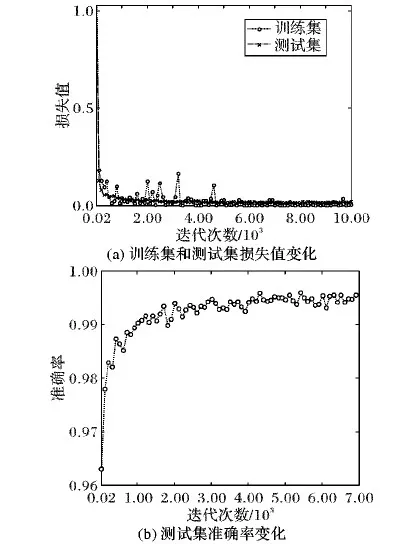
图8 损失值和准确率随迭代次数的变化Fig. 8 Changes of loss value and accuracy with iteration times
3.3.2 测试集测试
本文算法对混合数据集中测试集16 259张图像识别结果的混淆矩阵如表3所示,矩阵对角线数据是分类正确的图像个数,其他位置是分类错误的。从表3可以看出,本文算法分类的准确度较高。
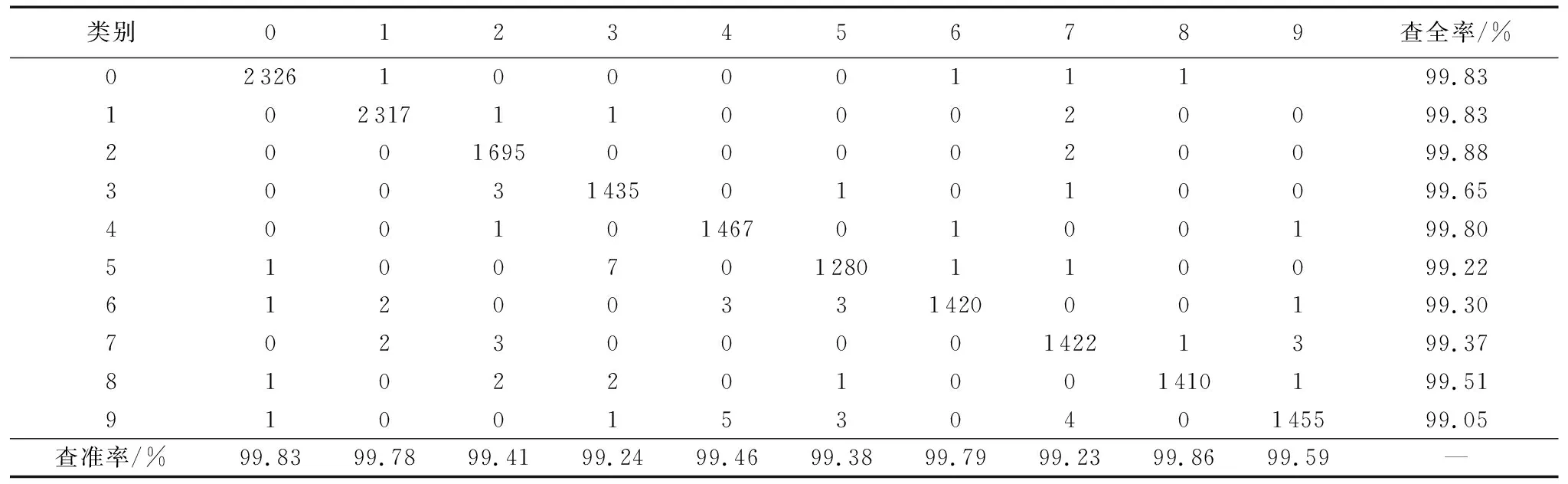
表3 测试集混淆矩阵Tab. 3 Confusion matrix of test set
不同算法对混合数据集中测试集16 259张图像的识别结果如表4所示。
表4中,方向梯度直方图(Histogram of Oriented Gradients, HOG)特征提取,每8×8的像素组成一个细胞单元(cell),把梯度方向平均划分为9个区间(bin),块的大小为16×16,即2×2个细胞单元(cell)组成一个块,所以每个块内有4×9=36个特征。以8个像素为步长在水平方向有4个扫描窗口,在垂直方向将有4个扫描窗口。而输入的图像大小调整为40×40,就是每张图像总共提取有9×4×16=576个特征。
表4中,SVM识别算法,核函数选择为径向基核函数(Radial Basis Function, RBF)(高斯核函数),SVM类型为C类支撑向量机,20类分组。训练数据总量为6 915个,在训练数据量小的时候,SVM识别准确率不如KNN,训练样本点太大时,计算耗时,算法效率不高。
HOG特征提取结合KNN算法,在K=5时识别效果较好。如果KNN算法样本维度太高,因为要与每一个样本进行比较,计算速度将会很慢,所以训练数据选取442个。从测试集识别结果可以看到,KNN+HOG识别速度较快,但准确率一般。
从表4的算法对比可知:改进卷积神经网络算法识别率不仅高于两种传统机器学习算法,也略优于同为卷积神经网络的LeNet算法和AlexNet算法,并且测试集损失率更低。
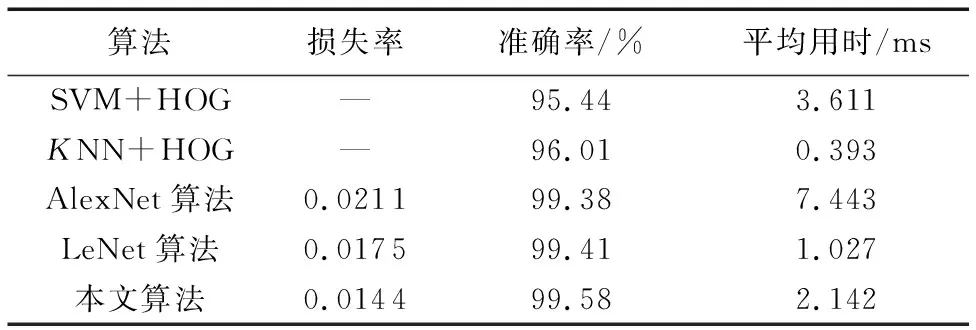
表4 不同算法对测试集的识别结果Tab. 4 Recognition results of different algorithms for test set
本文算法在识别单张测试集图像时,平均识别一张数字图像时间为2.142 ms,略长于LeNet网络,但远少于AlexNet网络(单张字符时间为7.443 ms)。AlexNet因为网络结构更深,识别时间相对较长,不能直接用于实际比赛。相比LeNet和AlexNet,改进网络识别精度提升并不明显;但从第4章比赛视频测试结果可以看出,改进的卷积神经网络算法对手写体和数码管都保持较高的识别率并满足识别速度要求,具备多源数字识别能力,有较好的泛化能力和鲁棒性。
4 比赛现场测试结果与分析
4.1 验证集获得与测试
在多个时段不同光照条件下,以全向移动步兵机器人视角获得大神符视频。从视频中提取出手写体数字和数码管数字并处理整合成用作验证算法效果的验证数据集。多数深度学习算法[18]中将数据集一部分作为训练集,另一部分作为测试集,测试集与训练集是同分布的。此处验证集与表1中的训练数据集(混合训练集和混合测试集)来源不同,互不关联,这样能更好地验证算法的性能。验证集数字分布如表5所示。
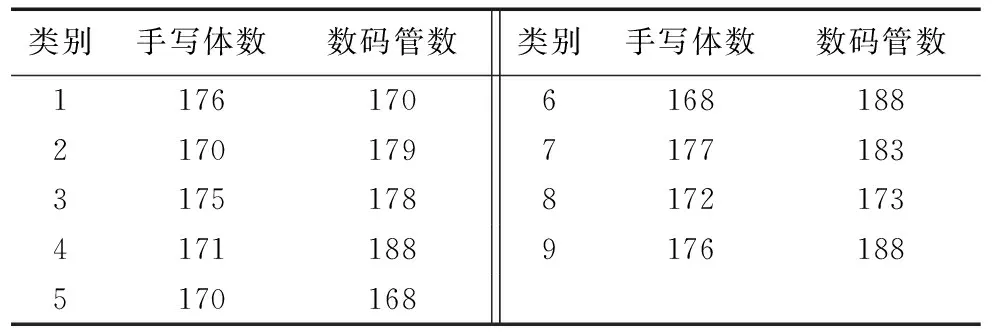
表5 验证集数字分布Tab. 5 Digital distribution of validation set
验证集中手写体数字共有1 555张,数码管数字共有1 615张。
不同算法对验证集的识别结果如表6所示。从表6中可以看出,AlexNet手写体识别精度略低于LeNet和本文算法,原因在于:AlexNet网络有6 000万个参数和650 000个神经元,相比于另外两种网络,其空间复杂度高,模型参数多,训练模型所需数据量大。本文的训练集仅有97 792张单通道数字图像,数据量少于训练AlexNet所需百万级ImageNet三通道彩色图像[19],使得训练出的模型出现一定程度过拟合。
在实际比赛场景下,不同算法对九宫格手写体数字识别结果如图9所示。
由表6和图9可知,对于验证集中的手写体数字,本文算法平均识别率位98.14%,相比于其他几种识别算法更高;改进的卷积神经网络对实际比赛场景下获得的手写体数字进行识别时,除了个别数字准确率略低于其他识别算法,整体识别准确率稳定且较高,表明了本文算法有更好的鲁棒性。

表6 不同算法对验证集识别结果Tab. 6 Recognition results of different algorithms for validation set

图9 不同算法对手写体数字识别结果Fig. 9 Recognition results of different algorithms for handwritten digits
部分识别错误的数字如图10所示。由图10中识别错误的字符可以分析出:由于分割不好、字符怪异等情况,部分数字无法识别。而卷积神经网络识别效果与样本数据也有很大的关系,扩大训练数据集样本量,尤其是图10中这种低质量的数字图像,可进一步提高识别准确率。

图10 部分识别错误的数字Fig. 10 Partial incorrectly identified digits
4.2 比赛视频效果测试
所提算法是否有效关键在于实际比赛的测试。测试的视频是从2017年东部赛区初赛现场获得,视频时长483 s,理想的情况下按照大符每1.5 s刷新一次来算,一共有322帧包含不同内容的大神符图像,而去掉摄像头可能被遮挡、九宫格与数码管刷新过程出现数字重叠与重复的部分图像实际上有265帧有效帧。其中,识别错误23帧,大符图像识别准确率为90.98%。视频在实验平台上处理时长为492 s,平均处理速度为每秒29.4帧。以连续成功识别5帧为成功激活一次大符来算,492 s的时间内可以成功激活大符42次,平均每分钟可激活5.12次。这一实验结果很好地满足了比赛时数据处理速度与准确率的要求。视频结果测试表明改进的卷积神经网络有很好的泛化性与实用性。
5 结语
针对多源数字识别的实际需求,利用卷积神经网络在图像识别分类上的优势,本文提出了一种改进结构的卷积神经网络。该网络能够同时识别数码管与手写体数字,并将改进算法应用于RoboMaster机甲大师赛,测试结果验证了算法的有效性。实验结果表明,改进的卷积神经网络算法性能优于SVM、KNN,识别率略优于AlexNet和LetNet网络,且具有较好的鲁棒性和泛化能力。
