边缘智能背景下的手写数字识别
2019-01-06王建仁马鑫段刚龙薛宏全
王建仁 马鑫 段刚龙 薛宏全
摘 要:随着边缘智能的快速发展,现有手写数字识别卷积网络模型的发展已越来越不适应边缘部署、算力下降的要求,且存在小样本泛化能力较差和网络训练成本较高等问题。借鉴卷积神经网络(CNN)经典结构、Leaky_ReLU算法、dropout算法和遗传算法及自适应和混合池化思想构建了基于LeNet-DL改进网络的手写数字识别模型,分别在大样本数据集MNIST和小样本真实数据集REAL上与LeNet、LeNet+sigmoid、AlexNet等算法进行对比实验。改进网络的大样本识别精度可达99.34%,性能提升约0.83%;小样本识别精度可达78.89%,性能提升约8.34%。实验结果表明,LeNet-DL网络相较于传统CNN在大样本和小样本数据集上的训练成本更低、性能更优且模型泛化能力更强。
关键词:边缘智能;卷积网络;手写数字识别;Leaky_ReLU;混合池化;自适应;dropout;遗传算法
中图分类号: TP30文献标志码:A
Handwritten numeral recognition under edge intelligence background
WANG Jianren, MA Xin*, DUAN Ganglong, XUE Hongquan
(College of Economics and Management, Xian University of Technology, Xian Shaanxi 710054, China)
Abstract: With the rapid development of edge intelligence, the development of existing handwritten numeral recognition convolutional network models has become less and less suitable for the requirements of edge deployment and computing power declining, and there are problems such as poor generalization ability of small samples and high network training costs. Drawing on the classic structure of Convolutional Neural Network (CNN), Leaky_ReLU algorithm, dropout algorithm, genetic algorithm and adaptive and mixed pooling ideas, a handwritten numeral recognition model based on LeNet-DL improved convolutional neural network was constructed. The proposed model was compared on large sample MNIST dataset and small sample REAL dataset with LeNet, LeNet+sigmoid, AlexNet and other algorithms. The improved network has the large sample identification accuracy up to 99.34%, with the performance improvement of about 0.83%, and the small sample recognition accuracy up to 78.89%, with the performance improvement of about 8.34%. The experimental results show that compared with traditional CNN, LeNet-DL network has lower training cost, better performance and stronger model generalization ability on large sample and small sample datasets.
Key words: edge intelligence; Convolutional Neural Network (CNN); handwritten numeral recognition; Leaky_ReLU; mixing pooling; adaptive; dropout; genetic algorithm
0 引言
隨着经济社会的不断发展,日常生活中与数字相关的应用越来越广泛,使用场景也越来越丰富,对应的手写数字识别需求也显著提升[1],例如:大规模纸质手写数据的统计、会计报表的扫描和识别、银行开户单身份证信息的识别、高校试卷分数扫描识别并累加等[2]。手写数字识别作为光学符号识别的一个重要分支,国内外众多学者对其识别方法进行了广泛而深入的研究,概括起来可分为基于模板匹配、基于机器学习和基于深度学习的识别方法三类。在基于模板匹配的识别方法研究方面,已有大量文献探讨了如何利用手写数字本身的特征进行识别,典型的研究有董延华等[3]基于模式识别技术提出了改进特征匹配算法对手写数字进行识别;陆靖滨等[4]提出了改进最大类间方差法对仪表外显图像进行自适应提取,并通过穿线法对数字进行识别;凌翔等[5]提出了基于改进的顶帽重构和模板匹配的车牌识别算法对自然场景下的车牌进行自动采集与识别; Saha等[6]提出了一种基于计算几何特征的方法对小样本手写数字图像进行识别;Jiao等[7]提出了一种基于主方向差异特征的快速模板匹配算法,对视频图像进行自适应获取并识别。此类研究方法虽具有简单、高效及可对手写数字进行较好的识别与分类等优点,但由于是对数字图像本身特征的提取与归纳,因此对图像质量要求较高,方法易受图像自身亮度、背景、角度等因素的影响,识别精度较低。在基于机器学习的识别方法研究方面,针对模板匹配方法中存在的识别精度低、易受图像采集质量影响等问题,郭伟林等[8]在圆形邻域局部二进制模式基础上,提取各图像分割子区域二进制模式直方图,并训练支持向量机(Support Vector Machine, SVM)分类模型对手写数字进行识别;甘胜江等[9]基于K近邻和随机森林算法提出了一种融合机器学习方法,该方法在手写数字目标分类中的准确率高于K近邻、Adaboost、SVM和随机森林算法模型;潘虎等[10]运用一种快速弱分类器训练算法和高速缓存策略来加速Adaboost算法训练对纸币号码进行识别;Khan等[11]提出一种基于熵的SVM特征选择方法,通过多特征的提取与融合对车辆牌照进行识别;Kulkarni等[12]提出了一种基于尖峰触发归一化近似下降算法对手写数字进行识别,并就MNIST数据集进行验证,实验结果证明算法精度较高。此类方法比传统的模板匹配方法准确率更高、性能更佳,但需要人工提取图像特征,导致特征提取的优劣将对最终的识别结果产生较大影响,并且,不同数据集的识别效果可能存在较大差异。基于深度学习的识别方法,比基于模板匹配和机器学习的手写数字识别方法,它不仅不受图像质量的影响且无需人工提取图像特征,而且图像识别精度更高,性能更优,如Yun等[13]结合卷积神经网络(Convolutional Neural Network, CNN)特征提取和极限学习机(Extreme Learning Machine, ELM)目标分类提出了一种车牌识别算法;Qiao等[14]提出了一种自适应深度Q学习策略,进一步提高手写数字识别精度和缩短运行时间;Trivedi等[15]基于遗传算法与L-BFGS(Large Broy-den-Fletcher-Goldforb-Shanno)方法提出了一种混合深度学习模型对梵文手写体数字进行识别;茹晓青等[16]在卷积神经网络中引入形变卷积模块,提出了一种改进的形变卷积神经网络对手写体数字进行识别;马义超等[17]针对CNN卷积核随机初始化情况下收敛速度慢和识别率低等问题,提出一种主成分分析(Principal Component Analysis,PCA)初始化卷积核的CNN识别算法对手写数字进行识别。在实际的应用场景中,此类方法特别是卷积神经网络模型被广泛应用于手写数字识别,将预处理后图像数据送入卷积神经网络模型进行训练,模型最终的结果为softmax函数输出的包含10个元素的向量,通过与原始标签进行比较,便可得最终的预测结果。然而,针对手写数字识别卷积网络的一系列改进,如增加网络深度、增强卷积模块功能及增加新模块功能等,使得网络模型越来越臃肿,在精度提升的同时,训练成本也越来越高。
综上所述,经多年研究,无需人工特征提取、精度较高且性能更优的基于深度学习特别是卷积神经网络模型的手写数字识别逐渐成为各学者研究的主要方向。然而,随着物联网技术(Internet of Things, IoT)的进一步发展,人工智能(Artificial Intelligence, AI)与IoT的融合越发紧密,AI模型逐渐偏向IoT终端侧部署,传统的依赖于远端高性能服务器或云实现的基于CNN的手写数字识别网络模型训练成本较高且小样本泛化能力较差,不适应IoT终端算力低、数据量小等特点。因此,本文在边缘智能背景下,提出了一种基于LeNet-DL改进网络的手写数字识别模型,并分别于大样本标准数据集MNIST和小样本真实数据集REAL上与常用LeNet、LeNet+sigmoid、AlexNet等手写数字识别算法进行对比实验,以此来验证模型性能。
1 相关工作
1.1 边缘智能
边缘计算指在靠近网络边缘侧,融合计算、存储、应用核心能力等的分布式开放平台,就近提供智能服务,能有效满足行业数字化相关需求[18],边缘智能(Edge Intelligence, EI)则为AI、IoT与边缘计算深度融合的产物[19]。随着传统的依赖于云的AI模型因云端个人数据泄露、能耗较高以及模型延时性较高等问题为人所诟病,边缘智能作为一种满足某些实时物联终端需求的技术越来越为人们所重视。
在商业领域,EI的相关研究特别是AI智能芯片的研究异常火热。如国内通信领域霸主华为相继发布搭载专门神经网络的AI核心处理器麒麟970等产品,电商巨头阿里发布AI芯片Ali-NPU,中科院计算所推出寒武纪芯片等,国外智能手机领跑者Apple发布A11仿生处理器,NVIDIA发布专用于AI的GPU,谷歌推出TPU,IBM推出“真北”等。而学术领域对EI的研究却不温不火。以题名、关键字或摘要(边缘计算、边缘智能)在CNKI和Elsevier不完全统计2009年到2019年相关文献,边缘计算共208008篇,边缘智能共17447篇,其中中文期刊文章分别占比0.2%和0.1%,理论研究较为欠缺,因此,对边缘智能的相关理论研究具有较高价值。该领域典型研究多集中于计算网络服务性能提升方面,主要包括:施巍松等[18]在对EI研究现状充分分析的基础之上,总结了推动EI发展的7项关键技术和6类需迫切解决的问题,为EI研究指明了方向;袁培燕等[20]为降低骨干网络流量压力并提升终端用户体验,基于移动边缘计算的内容卸载技术提出了一种贪心策略内容卸载方案;Xu等[21]为改善网络拥堵,将移动边缘计算网络服务器与区块链智能合约相结合,提出了一种无信任混合人机群智能平台; Tan等[22]为实现车载网络的低成本高效率目标,提出了一种联合通信、缓存与边缘计算的策略;Huang等[23]提出了一种用于构建智能物联网应用的边缘智能框架。
1.2 卷积神经网络
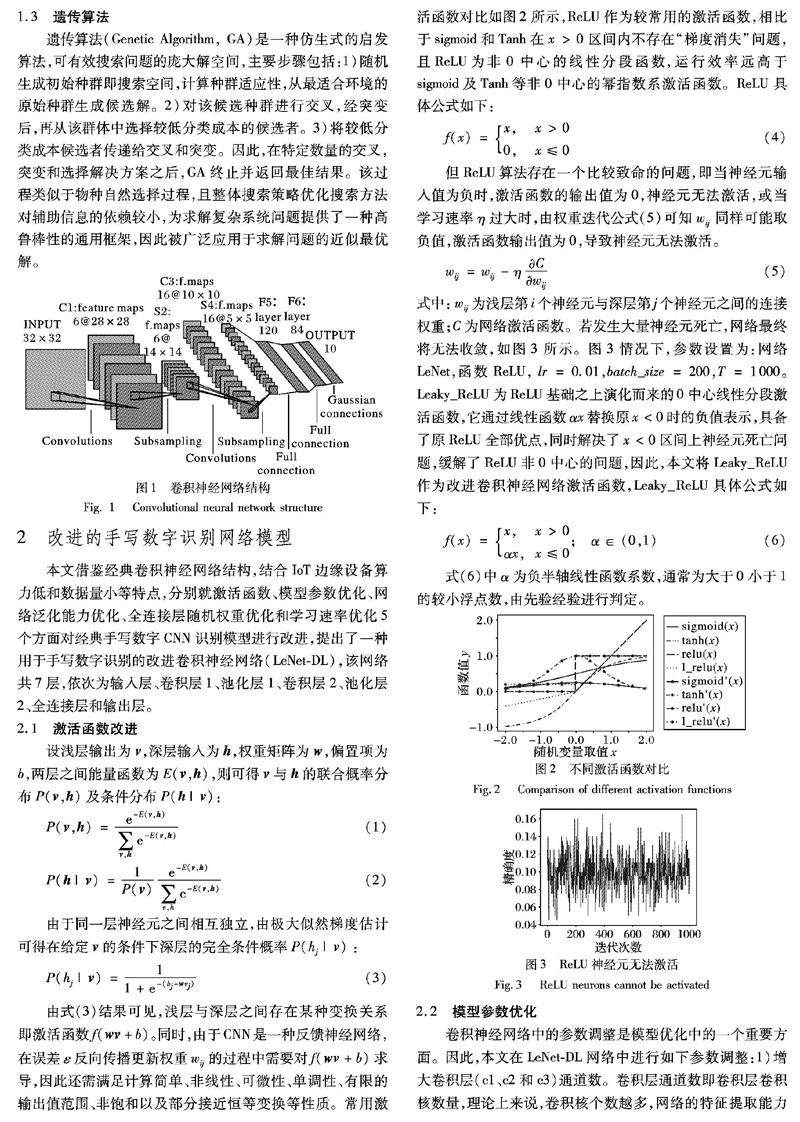
CNN是一大类特殊的反馈神经网络,主要由卷积层和池化层交替连接,并最终由全连接层实现图像分类。CNN对图像特征的提取及分类均是基于卷积层与池化层进行的,因此对卷积层、池化层及层级的优化调整能有效提高特征提取性能并优化分类结果,典型的研究如:LeCun等[24]提出的用于手写数字识別的卷积神经网络LeNet,该网络共包含8层,主要由输入层、卷积层、池化层、全连接层、输出层组成,是目前为止最为经典的手写数字识别网络算法;Krizhevsky等[25]基于LeNet网络,进一步提升网络深度并引入激活函数、Dropout函数等新功能模块提出了一种新的深度卷积神经网络AlexNet对图像进行识别;以及在此基础之上发展起来的VGG网络、NIS网络、ResNet网络和GoogleNet网络等。卷积神经网络的普遍结构如图1所示,图中共包括2层卷积C1和C3,2层池化S2和S4,2层全连接F5和F6,当目标图像以二维数组形式输入网络,通过网络层层处理,最终输出图像分类结果,分类的个数通常由实际的任务所决定。
1.3 遗传算法
遗传算法(Genetic Algorithm, GA)是一种仿生式的启发算法,可有效搜索问题的庞大解空间,主要步骤包括:1)随机生成初始种群即搜索空间,计算种群适应性,从最适合环境的原始种群生成候选解。2)对该候选种群进行交叉,经突变后,再从该群体中选择较低分类成本的候选者。3)将较低分类成本候选者传递给交叉和突变。因此,在特定数量的交叉,突变和选择解决方案之后,GA终止并返回最佳结果。该过程类似于物种自然选择过程,且整体搜索策略优化搜索方法对辅助信息的依赖较小,为求解复杂系统问题提供了一种高鲁棒性的通用框架,因此被广泛应用于求解问题的近似最优解。
2 改进的手写数字识别网络模型
本文借鉴经典卷积神经网络结构,结合IoT边缘设备算力低和数据量小等特点,分别就激活函数、模型参数优化、网络泛化能力优化、全连接层随机权重优化和学习速率优化5个方面对经典手写数字CNN识别模型进行改进,提出了一种用于手写数字识别的改进卷积神经网络(LeNet-DL),该网络共7层,依次为输入层、卷积层1、池化层1、卷积层2、池化层2、全连接层和输出层。
2.1 激活函数改进
设浅层输出为v,深层输入为h,权重矩阵为w,偏置项为b,两层之间能量函数为E(v,h),则可得v与h的联合概率分布P(v,h)及条件分布P(h|v):
P(v,h)=e-E(v,h)∑v,he-E(v,h)(1)
P(h|v)=1P(v)e-E(v,h)∑v,he-E(v,h)(2)
由于同一层神经元之间相互独立,由极大似然梯度估计可得在给定v的条件下深层的完全条件概率P(hj|v):
P(hj|v)=11+e-(bj+wvj)(3)
由式(3)结果可见,浅层与深层之间存在某种变换关系即激活函数f(wv+b)。同时,由于CNN是一种反馈神经网络,在误差ε反向传播更新权重wij的过程中需要对f(wv+b)求导,因此还需满足计算简单、非线性、可微性、单调性、有限的输出值范围、非饱和以及部分接近恒等变换等性质。常用激活函数对比如图2所示,ReLU作为较常用的激活函数,相比于sigmoid和Tanh在x>0区间内不存在“梯度消失”问题,且ReLU为非0中心的线性分段函数,运行效率远高于sigmoid及Tanh等非0中心的幂指数系激活函数。ReLU具体公式如下:
f(x)=x, x>0
0,x≤0 (4)
但ReLU算法存在一个比较致命的问题,即当神经元输入值为负时,激活函数的输出值为0,神经元无法激活,或当学习速率η过大时,由权重迭代公式(5)可知wij同样可能取负值,激活函数输出值为0,导致神经元无法激活。
wij=wij-ηCwij(5)
式中:wij为浅层第i个神经元与深层第j个神经元之间的连接权重;C为网络激活函数。若发生大量神经元死亡,网络最终将无法收敛,如图3所示。图3情况下,参数设置为:网络LeNet,函数ReLU,lr=0.01,batch_size=200,T=1000。Leaky_ReLU为ReLU基础之上演化而来的0中心线性分段激活函数,它通过线性函数αx替换原x<0时的负值表示,具备了原ReLU全部优点,同时解决了x<0区间上神经元死亡问题,缓解了ReLU非0中心的问题,因此,本文将Leaky_ReLU作为改进卷积神经网络激活函数,Leaky_ReLU具体公式如下:
f(x)=x, x>0
αx,x≤0; α∈(0,1)(6)
式(6)中α为负半轴线性函数系数,通常为大于0小于1的较小浮点数,由先验经验进行判定。
2.2 模型参数优化
卷积神经网络中的参数调整是模型优化中的一个重要方面。因此,本文在LeNet-DL网络中进行如下参数调整:1)增大卷积层(c1、c2和c3)通道数。卷积层通道数即卷积层卷积核数量,理论上来说,卷积核个数越多,网络的特征提取能力越强,所能提取的图像特征就越多,网络的性能则更优;2)将最大池化修改为混合池化。池化即将卷积所得特征矩阵划分为若干子矩阵,从每个子矩阵中选取某个值表征其特征,起到压缩特征矩阵、简化计算的作用,主要包括均值池化(mean-pooling)和最大池化(max-pooling)两种。由于卷积层通道数的增大会进一步提升卷积参数误差所造成的估计均值偏移程度,故将池化层1(p1)的池化方式调整为max-pooling,尽可能减小估计均值偏移程度;同时,为更好保留各特征矩阵的背景信息,缩小邻域大小受限造成的估计值方差,池化层2(p2)则采用mean-pooling,即将子矩阵内像素点均值作为该子矩阵的表征。具体参数如表1所示。
2.3 网络泛化能力优化
考虑到物联网终端侧数据量较小,训练数据无法反映数据整体特征,模型无法充分理解总体特征,极易出现“训练集优,测试集差”的过拟合现象,致使模型泛化能力较差,且传统卷积神经网络的全连接层通常位于网络后端,与传统神经网络连接方式基本一致,并未考虑网络對过拟合数据的泛化能力,本文借鉴AlexNet网络过拟合处理思路,在LeNet-DL网络全连接层引入dropout函数,进一步提升网络泛化能力。
dropout的主要流程如下:
1)训练阶段:网络前向传播过程中,为降低节点间相互作用,借鉴模型集成思想,以概率p激活某些神经元、概率(1-p)终止某些神经元,通过集成n次模型训练所得不同模型结果,提升模型泛化能力;
2)测试阶段:由于训练阶段某神经元在dropout前的输出为x,dropout后期望输出为E=px+(1-p)×0=px,且测试中各神经元均处于激活状态,因此为使期望不变,测试阶段权重w′=pw。
另外,为进一步提升测试性能,降低模型测试时间,LeNet-DL将权值缩放转移至训练阶段,即以概率p保留下来的神经元对应权重w调整为w′=w/p,测试阶段不进行任何处理。dropout计算过程对比示意图如图4所示。
2.4 全连接层随机权重优化
传统卷积神经网络模型大多采用随机梯度下降算法对模型进行训练,为加快网络收敛,则需激活函数导数值尽可能地大,而某个神经元j的输入是由上层一系列神经元i的输出加权求和并经激活函数f变换后所得,即可表示为xj=f(∑ixi wij+b),因此,只需将∑ixi wij+b控制在某一初始值范围内,更进一步,即将权重wij的初始值控制在某一范围内,使得激活函数导数值落入取值较大的范围内即可。
实际应用中,卷积神经网络模型权重的初始化方式主要有三种:标准正态分布初始化、方差递减正态分布初始化和截断正态分布初始化,均通过生成一系列服从正态分布的随机数作为网络初始权重,操作简单,但会降低梯度下降算法效率,影响网络收敛。以标准正态分布随机数为例,假设存在有n个输入神经元的CNN,且连接下一层的权重wij已初始化为标准正态分布随机数,为简化计算,设定输入层输出为x,则一定概率存在n/2的权重为0剩余神经元权重为1的情况,此时,下层第j个神经元的输入值为zj=f(∑ni=1wijxi+b),因为各独立随机变量和的方差等价于各独立随机变量方差的和,因此(∑ni=1wijxi+b)~N(0,n2),n越大,(∑ni=1wij xi+b)服从的正态分布方差越大,|∑ni=1wij xi+b|值的变动幅度越小,激活函数导数值变动较小,最终导致权值的更新速度较慢,模型收敛速率低。而无论是随着网络模型深度的增加权值初始化的正态分布标准差逐渐缩小的方差递减正态分布初始化还是所产生随机数满足条件(xij-μ)<2σ的截断正态分布初始化,均不同程度地存在上述问题。
本文鉴于遗传算法具有高效搜索局部或全局最优解的特点,将种群个数为10,染色体长度等于softmax分类器中权重数的遗传算法生成值作为全连接层的初始化权重。全连接层计算方式如图5所示
2.5 学习速率优化
诸如LeNet、AlexNet等传统网络模型学习速率(learning rate, lr)的设定主要有两种方式:依靠先验经验设定和逐一测试挑选最优lr。此种方式对于深度网络来说是灾难性的,模型训练成本极高,会耗费大量计算资源和时间。此外,lr过大,理论上可认为算法模型更易接近局部最优或全局最优,但实际情况下模型损失后期存在较大波动,始终难以达到最优;lr过小,虽可有效缓解模型训练后期损失波动较大问题,但会延长模型收敛时间,降低模型性能。
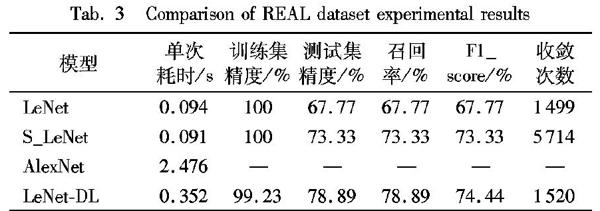
鉴于现有CNN学习速率设定存在上述问题,改进的LeNet-DL算法采用非线性自迭代方式对lr进行自适应调整。非线性自迭代的基本思想为模型训练初期使用较大lr寻优,随着迭代次数的增加,lr逐渐缩小,确保后期训练损失不会出现较大波动。具体公式如下:
lr_ri=TL×br_r+e-i1+e-i, 10000≤L
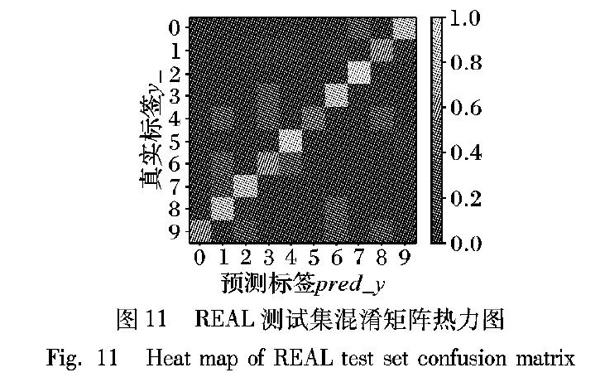
LT×br_r+e-i1+e-i, 0 其中:lr_ri為模型迭代第i次的学习速率;br_r为初始迭代速率;T为模型总迭代次数;L为总样本量。从图6中可见,在L为60000的条件下,迭代次数越小,模型学习速率曲线趋近x轴的速率越快;在迭代次数不变的条件下,样本量减小,模型学习速率曲线趋近x轴的速率越快。 3 实验验证与结果分析 本部分模型训练单机硬件配置为Intel Core i7-8550U @1.80GHz 2.00GHz核心处理器,8.00GB RAM,218GB固态硬盘,Intel UHD Graphics 620和Radeon RX 550双显卡,软件平台为PyCharm集成开发环境,TensorFlow深度学习框架、opencv图像处理、Numpy科学计算、time时间操作、matplotlib2D绘图和sklearn机器学习等库,操作系统为Windows 10 家庭中文版。 3.1 手写图像数据预处理 本节选取数据集共两部分:MNIST标准手写体数字数据集和西安理工大学30名在校学生真实手写数字数据集。 第一部分数据集为美国国家标准与技术研究所(National Institute of Standards and Technology, NIST)构建,共70000幅手写体数字图像,由250人手写,其中1/2为高中生,1/2为人口普查局工作人员,图片按照字节形式存储,所有图像数据均经过相关预处理,部分手写体图片如图7所示。 第二部分数据集为本实验人工搜集数据集,共300幅手写数字图片,年龄范围为18~28岁,其中年级分布上1/2为本科生,1/2为研究生;性别分布上1/2为男性,1/2为女性。文章为进一步减少图像噪声、类间和类内变换,强化模型提取图像特征的能力以及提高模型分类精度,对图像进行相关预处理,具体的预处理过程如下: 1)BGR图像转换为Greyscale灰度图,采用单通道表征图像特征; 2)手写图像为智能手机终端采集的白底黑字图像,为降低因拍摄角度、亮度和噪声等环境差异对图像识别造成的干扰,文章将各像素点大于115的像素值替换为255; 3)各像素点像素值翻倍后减35,进一步提高手写数字与背景对比度; 4)图像重构为LeNet-DL网络输入层图像大小28×28。图像预处理过程及最终处理结果如图8所示。 3.2 模型检验 3.2.1 MNIST数据集实验结果分析 为验证本文提出的LeNet-DL网络在大数据集中的分类性能,在MNIST数据集上构建LeNet、S_LeNet、AlexNet以及LeNet-DL手写体数字识别模型进行对比实验,并设定输入图像大小为28×28,灰度图,初始迭代速率br_r=0.001,训练批量batch_size=200,总迭代次数T=60000,dropout概率p=0.5,采用交叉熵定义损失函数,梯度下降算法训练样本数据,同时,为提高实验结果的普适性,分别在相同实验条件下进行重复实验,所得数据均为各实验结果平均值。实验结果对比如表2所示。 从表2中数据可知,LeNet-DL具有较好的模型泛化能力,在多分类大数据集MNIST中性能更优,训练集精度与测试集精度、召回率和F1-score均优于传统网络模型,分类准确率达99.34%,性能提升约0.83%;同时,LeNet-DL网络模型的训练成本要远低于AlexNet及基于AlexNet网络演化而来的深层卷积神经网络(GoogleNet、VGG16和ResNet等),单次训练耗时为0.347s,性能提升约79.72%。在收敛速度方面,LeNet网络由于深度较浅且卷积层与池化层间无非线性变换,导致模型收敛速度极慢;S_LeNet网络由于在LeNet基础之上增添了非线性变换激活函数sigmoid,网络模型得以收敛,但整体效果不佳,收敛速度较慢;AlexNet网络深度较深,有6000万个参数和650000个神经元,模型训练往往需要百万级甚至更大量级的图像数据,模型训练成本高,收敛速度慢,因此在60000张MNIST手写数字图像下以batch_size=200训练60000次模型并未收敛。 图9为选取LeNet-DL模型60000次迭代的训练集精确度和损失值的对比,从图中可见,模型训练前期损失值loss下降较快,同时精确度也快速上升,迭代至27600次左右时loss和accuracy已基本趋于稳定,中间过程虽稍有波动,但总体呈稳定趋势,最终模型精度可达99.6%。图10所示为LeNet-DL模型预测集单数字预测精度,从具体结果数据对比可见,模型对0~9手写数字的预测精度均高于传统卷积网络算法,整体识别率较高,LeNet-DL网络具有较好的鲁棒性。综上分析,LeNet-DL网络的性能更优,收敛速度更快。 3.2.2 REAL真实数据集实验结果分析 网络模型的泛化能力越强,表明模型的普适性越强,对未知数据集的处理能力就越强;否则,网络模型的泛化能力越差。本文为进一步验证LeNet-DL网络在物联网终端设备小样本条件下的泛化能力,基于真实手写数据集构建模型对比实验。数据集共包括300张手写数字,训练集与测试集划分比例为7∶3,图像大小为28×28,灰度图,br_r=0.001, batch_size=210,总迭代次数T=10000,dropout概率p=0.71,采用交叉熵定义损失函数,梯度下降算法训练样本数据,所得实验数据均为多次重复实验结果的平均值。具体实验结果如表3所示。 从表3实验数据中可见,LeNet和S_LeNet网络模型的收敛速度较快,模型训练精确度可达100%,但测试集中的精确度却仅有70%左右,远低于训练集中的精确度,模型出现严重过拟合现象,不足以应对小样本条件下的精确分类;以AlexNet为代表的一系列深度卷积神经网络,虽针对可能出现的过拟合问题进行了相关改进,但网络深度较大且数据集较小,模型无法有效收敛;从图11和图12可知,本文提出的LeNet-DL相比于传统网络模型泛化能力较強,性能较优,收敛速度较快,但同样出现了较小程度的过拟合现象,文章分析主要有以下三点原因: 1)训练数据过少:由于数据量与数据噪声量呈反比,少量数据便可导致较大的噪声。 2)测试集与训练集分布差异较大:本实验所收集数据虽然在年级、性别和年龄等方面较为均衡,但在训练集和测试集划分过程中采用的是机器学习库sklearn中cross_validation模块train_test_split函数随机划分的,很难保证训练集中年级、性别和年龄等方面与测试集中保持一致,影响模型对数据分布的有效分析。 3)采集数据集存在“霍桑效应”:霍桑效应是指当被试者察觉到自己正在被他人关注或者察觉时,会刻意改变某些行为或言语表达的倾向。本实验手写图像均由实验人员人工采集,在采集过程中明确告知被采集者采集数据供科研使用,并多次强调被采集者应按自己平时的书写习惯进行书写,但该种方式仍然与自然状态下被采集者的书写习惯有所区别,实验所用的数据存在一定误差。 4 结语 数字图像识别在实际场景中有着十分广泛的应用,而随着IoT与AI的进一步融合,现有的数字图像识别已不满足边缘部署、算力下降和数据量小的要求,因此,研究下一代既高效又精确的识别网络模型对促进边缘智能部署和数字识别应用具有十分重要的意义。 本文针对边缘智能背景下现有数字识别网络模型存在的泛化能力较差和训练成本较高等问题,提出了一种改进的数字识别卷积网络模型LeNet-DL。该网络模型共7层,使用Leaky_ReLU激活函数替换原sigmoid或ReLU激活函数,在一定程度上解决了因原有激活函数所引起的“梯度消失”和“神经元死亡”问题,并进一步提升卷积核卷积能力,采用混合池化方式对卷积层输出Feature Map进行下采样,继而通过遗传算法优化卷积网络全连接层权重并引入dropout函数,提高了模型的泛化能力,并提出一种依据总迭代次数、当前迭代次数与训练样本总量的非线性自适应模型学习速率迭代算法,有效缩减了模型速率的人工调试过程,降低了模型训练成本。 基于大样本标准数据集MNIST和小样本真实数据集REAL,将LeNet、sigmoid+LeNet、AlexNet和本文算法LeNet-DL进行对比实验,分别就模型的单次训练耗时、训练集精度、测试集精度、测试集召回率、测试集F1-score、模型收敛迭代次数和精度损失对比进行比较分析。本文所提的LeNet-DL网络模型在兼顾模型识别精度、泛化能力和训练成本的基础之上,大样本识别精度可达99.34%,性能提升约0.83%;小样本识别精度可达78.89%,性能提升8.34%。实验结果表明,本文所提的手写数字识别卷积网络模型是有效的,其预测精度、模型泛化能力及网络训练成本较传统模型更优。但由于边缘智能本身较为复杂,本文对手写数字识别模型边缘部署研究仍处于探索尝试阶段,有待于进一步提高网络模型的精度和泛化能力,降低模型训练成本。 参考文献 (References) [1]卜令正,王洪栋,朱美强,等.基于改进卷积神经网络的多源数字识别算法[J].计算机应用,2018,38(12):3403-3408.(BU L Z, WANG H D, ZHU M Q, et al. Multi-source digital recognition algorithm based on improved convolutional neural network [J]. Journal of Computer Applications, 2018, 38(12): 3403-3408.) [2]AKHAND M A H, AHMED M, RAHMAN M M H, et al. Convolutional neural network training incorporating rotation-based generated patterns and handwritten numeral recognition of major Indian scripts [J]. IETE Journal of Research, 2018, 64(2): 176-194. [3]董延华,陈中华,宋和烨,等.改进特征匹配算法在银行卡号识别中的应用[J].吉林大学学报(理学版),2018,56(1):126-129.(DONG Y H, CHEN Z H, SONG H Y, et al. Application of improved feature matching algorithm in bank card number identification [J]. Journal of Jilin University (Science Edition), 2018, 56(1): 126-129.) [4]陸靖滨,许丽.基于自适应特征提取的数显仪表识别系统[J].现代电子技术,2017,40(24):147-150.(LU J B, XU L. Digital-display instrument recognition system based on adaptive feature extraction [J]. Modern Electronic Technique, 2017, 40(24): 147-150.) [5]凌翔,赖锟,王昔鹏.基于模板匹配方法的不均匀照度车牌图像识别[J].重庆交通大学学报(自然科学版),2018,37(8):102-106.(LING X, LAI K, WANG X P. Uneven illumination license plate image recognition base on template matching method [J]. Journal of Chongqing Jiaotong University (Natural Science), 2018, 37(8): 102-106.) [6]SAHA S, SAHA S, CHATTERJEE S K, et al. A machine learning framework for recognizing handwritten digits using convexity-based feature vector encoding [C]// Proceedings of International Ethical Hacking Conference 2018, AISC 811. Singapore: Springer, 2018: 369-380. [7]JIAO J, WANG X, DENG Z, et al. A fast template matching algorithm based on principal orientation difference [J]. International Journal of Advanced Robotic Systems, 2018, 15(3):1-9. [8]郭伟林,邓洪敏,石雨鑫.基于局部二进制和支持向量机的手写体数字识别[J].计算机应用,2018,38(S2):282-285, 289.(GUO W L, DENG H M, SHI Y X. Handwritten digit recognition based on local binary and support vector machine [J]. Journal of Computer Applications, 2018, 38(S2): 282-285, 289.) [9]甘胜江,白艳宇,孙连海,等.融合改进K近邻和随机森林的机器学习方法[J].计算机工程与设计,2017,38(8):2251-2255,2275.(GAN S J, BAI Y Y, SUN L H, et al. Machine learning method fusing improved K-nearest neighbors and random forest [J]. Computer Engineering and Design, 2017, 38(8): 2251-2255, 2275.) [10]潘虎,陈斌,李全文.基于二叉树和Adaboost算法的纸币号码识别[J].计算机应用,2011,31(2):396-398.(PAN H, CHEN B, LI Q W. Paper currency number recognition based on binary tree and Adaboost algorithm [J]. Journal of Computer Applications, 2011, 31(2): 396-398.) [11]KHAN M A, SHARIF M, JAVED M Y, et al. License number plate recognition system using entropy-based features selection approach with SVM [J]. IET Image Processing, 2018, 12(2): 200-209. [12]KULKARNI S R, RAJENDRAN B. Spiking neural networks for handwritten digit recognition — supervised learning and network optimization [J]. Neural Networks, 2018, 103: 118-127. [13]YUN Y, LI D, DUAN Z. Chinese vehicle license plate recognition using kernel-based extreme learning machine with deep convolutional features [J]. IET Intelligent Transport Systems, 2018, 12(3): 213-219. [14]QIAO J, WANG G, LI W, et al. An adaptive deep Q-learning strategy for handwritten digit recognition [J]. Neural Networks, 2018,107: 61-71. [15]TRIVEDI A, SRIVASTAVA S, MISHRA A, et al. Hybrid evolutionary approach for Devanagari handwritten numeral recognition using convolutional neural network [J]. Procedia Computer Science, 2018, 125: 525-532. [16]茹晓青,华国光,李丽宏,等.基于形变卷积神经网络的手写体数字识别研究[J].微电子学与计算机,2019,36(4):47-51.(RU X Q, HUA G G, LI L H, et al. Handwritten digit recognition based on deformable convolutional neural network [J]. Microelectronics and Computer, 2019, 36(4): 47-51.) [17]马义超,赵运基,张新良.基于PCA初始化卷积核的CNN手写数字识别算法[J].计算机工程与应用,2019,55(13):134-139.(MA Y C, ZHAO Y J, ZHANG X L. CNN handwritten digit recognition algorithm based on PCA initialization convolution kernel [J]. Computer Engineering and Applications, 2019, 55(13): 134-139.) [18]施巍松,孙辉,曹杰,等.边缘计算:万物互联时代新型计算模型[J].计算机研究与发展,2017,54(5):907-924.(SHI W S, SUN H, CAO J, et al. Edge computing — an emerging computing model for the Internet of everything era [J]. Journal of Computer Research and Development, 2017, 54(5): 907-924.) [19]李肯立,刘楚波.边缘智能:现状和展望[J].大数据,2019,5(3):69-75.(LI K L, LIU C B. Edge intelligence: state-of-the-art and expectations [J]. Big Data, 2019, 5(3): 69-75.) [20]袁培燕,蔡云云.移动边缘计算中一种贪心策略的内容卸载方案[J].计算机应用,2019,39(9):2664-2668.(YUAN P Y, CAI Y Y. Content offloading scheme of greedy strategy in mobile edge computing system [J]. Journal of Computer Applications, 2019, 39(9): 2664-2668.) [21]XU J, WANG S, BHARGAVA B K, et al. A blockchain-enabled trustless crowd-intelligence ecosystem on mobile edge computing [J]. IEEE Transactions on Industrial Informatics, 2019, 15(6):3538-3547. [22]TAN L T, HU R Q, HANZO L. Twin-timescale artificial intelligence aided mobility-aware edge caching and computing in vehicular networks [J]. IEEE Transactions on Vehicular Technology, 2019, 68(4): 3086-3099. [23]HUANG Z Q, LIN K J, TSAI B L, et al. Building edge intelligence for online activity recognition in service-oriented IoT systems [J]. Future Generation Computer Systems, 2018, 87: 557-567. [24]LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. [25]KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2012: 1097-1105. This work is partially supported by the Shaanxi Provincial Key Discipline Project (107-00X901). WANG Jianren, born in 1961, M. S., associate professor. His research interests include data mining, business intelligence, decision support. MA Xin, born in 1995, M. S. candidate. His research interests include machine learning, deep learning, recommender system. DUAN Ganglong, born in 1977, Ph. D., associate professor. His research interests include data mining, business intelligence, decision support. XUE Hongquan, born in 1978, Ph. D., lecturer. His research interests include computing intelligence, advanced manufacturing management.≡『』()¤==¤欄目网络空间安全¤==¤◎ 收稿日期: 2019-05-22;修回日期:2019-07-02;录用日期:2019-07-04。基金项目:陕西省重点学科资助项目(107-00X901)。 作者简介:王建仁(1961—),男,陕西西安人,副教授,硕士,主要研究方向:数据挖掘、商务智能、决策支持; 马鑫(1995—),男,山东潍坊人,硕士研究生,主要研究方向:机器学习、深度学习、推荐系统; 段刚龙(1977—),男,陕西西安人,副教授,博士,主要研究方向:数据挖掘、商务智能、决策支持; 薛宏全(1978—),男,陕西西安人,讲师,博士,主要研究方向:计算智能、先进制造管理。 文章编号:1001-9081(2019)12-3548-08DOI:10.11772/j.issn.1001-9081.2019050869
