基于孪生检测网络的实时视频追踪算法
2019-01-06邓杨谢宁杨阳
邓杨 谢宁 杨阳


摘要:目前,在视频追踪领域中,大部分基于孪生网络的追踪算法只能对物体的中心点进行定位,而在定位快速形变的物体时会出现定位不准确的问题。为此,提出基于孪生检测网络的实时视频追踪算法——SiamRFC。SiamRFC算法可直接预测被追踪物体位置,来应对快速形变的问题。首先,通过判断相似性来得到被追踪物体的中心点位置;然后,运用目标检测的思路,通过选取一系列的预选框来回归最优的位置。实验结果表明,所提SiamRFC算法在VOT2015|16|17的测试集上均有很好的表现。
关键词:孪生网络;物体检测;实时视频追踪;相似性学习;卷积神经网络
中图分类号: TP391.4文献标志码:A
Siamese detection network based real-time video tracking algorithm
DENG Yang1,2, XIE Ning1,2*, YANG Yang1,2
(1. School of Computer Science and Engineering, University of Electronic Science and Technology of China, Chengdu Sichuan 611731, China;
2. Center for Future Media, University of Electronic Science and Technology of China, Chengdu Sichuan 611731, China)
Abstract: Currently, in the field of video tracking, the typical Siamese network based algorithms only locate the center point of target, which results in poor locating performance on fast-deformation objects. Therefore, a real-time video tracking algorithm based on Siamese detection network called Siamese-FC Region-convolutional neural network (SiamRFC) was proposed. SiamRFC can directly predict the center position of the target, thus dealing with the rapid deformation. Firstly, the position of the center point of the target was obtained by judging the similarity. Then, the idea of object detection was used to return the optimal position by selecting a series of candidate boxes. Experimental results show that SiamRFC has good performance on the VOT2015|16|17 test sets.
Key words: Siamese network; objection detection; real-time video tracking; similarity learning; Convolutional Neural Network (CNN)
0引言
在計算机视觉中,视频追踪领域是一个非常重要且具有挑战性的问题。由于被追踪物体会产生遮挡、形变和外观等变化,精确定位目标物体显得较为困难。另外,在大量的应用中,比如自动驾驶、视频监控等,都具有实时性的要求。因此,设计具有实时性且高精度追踪算法就成为视频追踪领域主要的挑战。
在视频追踪领域,基于相关滤波器方法[1-4]被广泛地应用。相关滤波器方法是训练学习一个滤波器,用于从背景中分离出被追踪物体。但是基于滤波器的方法具有很多缺点,比如需要在线更新;另外,对于背景较为复杂和快速形变的物体则不能很准确地定位。近年来,由于硬件性能的提升和可利用的标注数据的增多,为深度卷积神经网络在计算机视觉中的快速应用奠定了基础。目前,基于学习深度特征的相关滤波器能够持续提高算法的精确度[1,5-6];文献[7-9]则是直接利用深度学习的方法进行追踪。但是这些方法通常需要在线更新,所以很难达到实时性。
目前,基于深度卷积神经网络[10-12]的实时追踪方法被广泛应用于目标追踪领域中。如文献[11]把追踪看成是一个回归问题,通过卷积神经网络(Convolutional Neural Network, CNN)直接回归出被追踪物体的位置;Siamese-FC(Fully-Convolutional Siamese network)[10] 把追踪看成相似性学习,通过深度卷积神经网络学习一个判别模型来定位物体中心点的位置,但是对物体形状的预测只是通过初始帧中物体的形状和相应的形变约束来控制。Siamese-RPN(Siamese Region Proposal Network)[12]把追踪看成一个检测问题,利用Faster R-CNN(Faster Region-CNN)[13]中区域回归的思想来定位被追踪物体的位置。尽管Siamese-RPN具有很高的追踪能力,但是需要比文献[10-11]方法设置更多的参数,因此会增加大量训练数据。
为解决以上问题,本文提出一种基于孪生检测网络的实时视频追踪算法——SiamRFC(Siamese-FC Region-convolution neural network)。SiamRFC算法分为两部分:第一部分跟Siamese-FC相似,通过学习CNN来得到一个判断物体相关性的关系网络,该网络可以定位被追踪物体的中心点位置;第二部分则是利用这个中心点的位置,提取一系列预选框,然后通过回归和分类网络来定位被追踪物体。SiamRFC算法结合了Siamese-FC和Faster R-CNN的优势:一方面Siamese-FC具有很好的判别能力,能过定位被追踪物体的中心点;另一方面利用区域回归的思想进一步定位目标。本文的算法与Siamese-RPN区别在于不是全局定位物体位置,最大的优势是模型参数少,使用少量的数据仍然可以得到很好的追踪效果。
在VOT2015[14]、VOT2016[15]和VOT2017[16]评估提出本文提出的追踪算法SiamRFC。在VOT系列的测试集上的实验结果表明,本文算法能达到很好的性能。由于SiamRFC是在Siamese基础上进一步定位目标,会增加一些追踪时间,但是仍然满足实时性的要求。
1相关工作
1.1视频追踪
基于孪生网络的追踪算法由两部分组成,首先提取第一帧中被追踪物体的特征,然后和候选区域特征进行比较,得到相似性信息。基于这种方法的追踪器通常在一个域上学习信息,然后迁移到其他域中。这种方法并不需要在线更新,满足实时追踪的要求。
最近几年,孪生网络引起极大的关注[10-12,17-21]。文献[11]是一个基于孪生网络的回归方法。Siamese-FC[10]则是通过学习候选区域特征和目标特征之间的关系来得到相似图谱。Siamese-FC使用全卷积网络来进行学习,全卷积网络的优点在于目标补丁的大小和候选补丁大小可以不相同,因此可以向网络提供更大的搜索特征,然后生成一个密集相似性图来评估特征之间的关系。文献[20]则是在Siamese-FC基础上增加滤波器方法,尽管最终的算法性能和Siamese-FC不相上下,但是却可以使得Siamese-FC模型参数更少并且更加健壮。Siamese-RPN[12]则是在孪生网络中引入区域回归思想来追踪物体位置。文献[19]则尝试在孪生网络中添加在线学习的方法,尽管精度大幅度提高,但是损失速度。
基于孪生网络的追踪算法Siamese-FC[10]主要缺点只是学习物体的中心点信息,对于物体的大小变化信息則并没有进行相应的学习,因此,本文尝试在孪生网络Siamese-FC[10]添加分类和回归网络来进一步学习物体的空间信息。
物体检测是计算机视觉的一个重要分支,最近几年取得极大的进展。从R-CNN(Region-CNN)[22]开始,物体检测的方法可以分为两个阶段,即:通过生成的感兴趣的区域来进行分类和回归。Fast-RCNN[23]则是通过在共享的卷积层特征上提取感兴趣区域来解决R-CNN冗余计算的问题。Faster R-CNN[13]则是通过CNN来自动生成相对较少但质量更高的感兴趣区域来进一步减少冗余计算,不仅提高了检测质量,还提高了检测速度。
1.3Faster R-CNN
由于本文的追踪算法跟Faster R-CNN算法相关,因此,在这里简要介绍Faster R-CNN:首先提取图片的特征,对于提取到的特征选取一系列的预选框,即具有不同面积和宽高比的矩形框;然后通过区域回归网络(RPN)来预定位图片中所有物体的位置;最后对于选出的建议框通过非极大值抑制(Non-Maximum Suppression, NMS)进一步减少建议框的数量。池化层则把这些建议框统一到相同的空间维度,以便于输入到后续的网络中进一步进行预测。
本文的算法思想与Faster R-CNN的算法思想类似,都是生成预选框进行定位。不同之处在于本文算法并不需要全局搜索,而是局部搜索,即在孪生网络预定位的基础上生成预选框。
2本文算法
2.1孪生网络
在第一阶段定位被追踪物体中心点的过程中,使用来自Siamese-FC[10]的网络结构,Siamese-FC是一个全卷积的网络结构,如图1(a)所示。假如Lτ表示转换操作(Lτx)[u]=x[u-τ],如果操作是全卷积则需要满足以下条件:
h(Lkτx)=Lτh(x)(1)
其中k表示网络的步长。
孪生网络中可以通过学习一个关系函数f(z,z′)来比较两张图片的关系,其中z和z′图片尺寸相同。由于Siamese-FC是全卷积网络,候选图片和目标图片不需要具有相同空间维度。若x表示被搜索的图片,则两个图片之间的关系可表示为:
f(z,x)=Φ(z)*Φ(x)+b·1(2)
其中:“*”表示卷积操作; f(z,x)表示分数图谱。分数图谱的真实标记可以表示如下:
y[u]=+1,k‖u-c‖≤R
-1,其他(3)
其中:k是网络步长;R是分数图谱的半径。
2.2检测网络
第二阶段的区域回归网络图1(b)所示。从图1可以看到,区域回归网络可以分为两个分支:一个分支是区别前景背景的分类网络;另一个是用来定位目标位置的回归网络。若(z)表示通过CNN的目标图像特征,则(z)分为两个部分:[(z)]cls和[(z)]reg,分别拥有相较于(z)的2倍和4倍的通道数量。若(x)表示通过CNN的搜索区域的特征,从图1可以看到,(x)基于预测的中心点位置选取K个不同比例、不同面积的特征区域。这些特征被归一化到相同的空间大小[x′]1,2,…,k,最后通过和(z)操作得到相应的分类和被追踪物体的位置。
Lcls2k=[(z)]cls*(x′)1,2,…,k
Lreg4k=[(z)]reg*(x′)1,2,…,k(4)
其中:Lcls2k表示的是模板z和x′卷积之后得到的分类结果,z和x′具有相同的空间特征;k表示预选框的数量;Lreg4k表示k个预选框和预测的物体位置之间的正则化距离。
在训练的过程中,本文使用和Faster R-CNN[13]相同的损失函数,对于分类网络使用交叉熵损失,对于回归网络使用L1正则化损失函数。假设Ax、Ay、Aw、Ah表示预选框的中心点位置和目标大小,Gx、Gy、Gw、Gh表示实际物体的中心点位置和大小。则正则化距离为:
δ0=Gx-AxAx
δ1=lnGwAw
δ2=Gy-AyAy
δ3=lnGhAh(5)
其中L1正则化损失函数表示如下:
smoothL1(x,α)=0.5x2α2,|x|<1/α2
|x|-1/(2α2),|x|≥1/α2(6)
其中α是一个超参数,用来调节损失。
则最终损失函数为:
L=∑iLcls(pi,qi)+λ∑iqiLreg(di,δi)(7)
其中:pi表示预测的前景和背景的概率;qi表示该预选框是背景还是前景;λ是一个超参数用来平衡两个损失。Lcls表示交叉熵损失函数,Lreg表示如下:
Lreg=∑3i=0smoothL1(δ[i],α)(8)
2.3追踪阶段
和Siamse-FC一样,在该阶段首先用第一帧中目标区域来初始化网络,得到目标图像特征,并在追踪阶段一直保持不变。接下来用不同范围的搜索区域通过网络得到搜索区域的图像特征,用目标图像特征作为卷积核,预测目标中心点位置。基于这个中心点,对于当前帧特征选取不同的预选框,并把它们规整到相同空间大小的特征维度,最后得到分类和回归结果。
由于选取的锚点的数量并不会影响网络参数,因此尽可能多地选取预选框以保证目标被包含。在推测阶段,对于分类的结果,可能会有较多的锚点会产生较高的前景分数,因此需要对这些分数施加一定的约束。使用初始帧目标物体的大小和预选框的大小计算交并比(Intersection over Union, IoU)作为约束条件:
iou=area(ROIT∩ROIG)area(ROIT∪ROIG)(9)
pcls1,2,…,k=cls1,2,…,k·iou1,2,…,k(10)
其中:ROIT表示初始幀中目标区域;ROIG代表预选框的区域;“·”表示对应元素相乘;最终从pcls1,2,…,k中选取最大的分数作为当前帧分类的预测结果。用col、row作为第一阶段预测的被追踪物体的中心点,wan、han表示预选框的宽和长,则最后预测被追踪目标的位置如下:
xpred=col+dx*wan
ypred=row+dy*han
wpred=wan*edw
hpred=han*edh(11)
另外,由于在训练阶段使用同一剪裁方式的候选图片作为训练集,而在推测阶段,选用不同范围的候选区域进行推测,因此回归结果会产生偏差。对预测的{wpred,hpred}进行相应弥补:
wfi=wpred*p
hfi=hpred*p;p=1+c*(s-1)(12)
其中:s表示选取的比例;c表示约束条件。
3实验与结果分析
3.1实验方法
3.1.1数据集
实验在目前非常具有挑战性的三个数据集VOT2015、VOT2016和VOT2017上进行测试,VOT系列的数据集包含60个序列的视频,并且每年数据集中的视频会进行更新。
3.1.2数据维度
数据预处理和Siamse-FC保持一样,假如某帧中被追踪物体的大小为(w,h),则通过以下方式剪裁图片:
A=2B;B=(w+p)×(h+p)(13)
其中:p=(w+h)/2;A是最终需要剪裁出的区域,然后将A调整到255×255。
3.1.3 预选框
本文预选框选择的方式与Faster R-CNN选择方式不同。Faster R-CNN选择方式是根据不同的面积和宽高比进行选择,而本文是根据步长来增加宽和高。在本文的实验中这个步长设定为15,即输入图像的尺寸和输出的相似性图谱的大小的比例。另外为了平衡算法的速度和精度,最终挑选出15个不同的预选框来做最后的定位。
3.1.4训练阶段
本文的方法在ILSVRC-2015[24]和GOT-10K[25]数据集上进行离线训练,其中:ILSVRC-2015包含了超过4000个序列,并且又分为30个基本类别;而在GOT-10K中大约包含563个不同的类别和87种不同的运动模式,但是相较ILSVRC-2015有更少的可训练帧数。在这两个数据集上进行相同的数据处理,随机选取同一个视频中两帧作为训练对,且这两帧的时序间隔不超过100帧。随后使用随机梯度下降(Stochastic Gradient Descent, SGD)法对式(7)进行优化。训练50个循环,初始学习率为10-2,随后缓慢降低学习率到10-6。实验在i5-6500 3.2GHz CPU上和GeForce GTX 1060 GPU上执行,在VOT中测试速度约为35frame/s。
3.2实验结果
3.2.1VOT2015实验结果
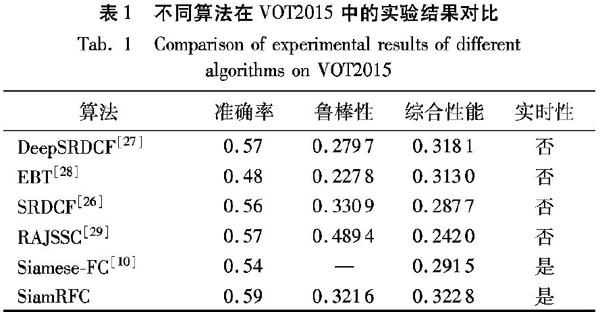
VOT系列是一个认可度比较高并且在追踪领域非常受欢迎的单目标追踪标准。 VOT2015中主要有两个测量标准:重叠率和失败次数。EAO(Expected Average Overlap)是考虑重叠率和失败次数这两个标准之后给出的算法综合性能评估。将本文算法SiamRFC与目前在VOT2015排名靠前的算法进行对比,测试结果如表1所示。
表1中:SRDCF(learning Spatially RegularizeD Correlation Filters for visual tracking)[26]主要解决滤波器存在的边界效应问题;DeepSRDCF[27]则是在SRDCF的基础上,将手动的特征换为卷积网络提取的特征;EBT算法[28]则结合区域检测的思想;RAJSSC(Joint Scale-Spatial Correlation tracking with Adaptive Rotation estimation)[29]从目标旋转的角度对跟踪算法进行改进,从而可以减少由于目标转动导致对于追踪性能的影响。
從表1可以看出,本文的算法SiamRFC在准确率和综合性能都优于其他算法,且与Siamese-FC相比各项性能都较大地超过了Siamese-FC算法,表明本文算法在实时性和性能方面都有较好的表现。
3.2.2VOT2016实验结果
VOT2016和VOT2015具有相同的序列集,不同的是VOT2016使用了自动的方法对样本进行重新标定。将本文算法SiamRFC和在VOT2016上排名靠前的追踪算法进行比较,测试结果如表2所示。
表2中:CCOT(learning Continuous Convolution Operators for visual Tracking)[6]将学习检测过程推广到连续空间域(使用插值方法),可以获得亚像素精度的位置; Staple[30]则是在同一回归框架中融合互补因子,从而能够很好处理光照变化对于目标追踪效果的影响;MDNet_N[31]提出了一个基于卷积神经网络的多领域学习框架,它将域无关的信息与域相关的信息分开,从而进行有效的追踪。
从表2可以看出,本文的算法SiamRFC在准确率方面优于其他算法,表明了本文算法的优势,可利用回归方法直接得到被追踪物体精确位置。
3.2.3VOT2017实验结果
VOT2017和VOT2016不同的是,VOT2017将其中10个视频替换成10个难度相对较大的序列;与此同时,还对所有的视频进行重新标定。将本文算法SiamRFC和在VOT2017上排名靠前的追踪算法进行比较,测试结果如表3所示。
表3中:其中SiamDCF(Discriminant Correlation Filters network for visual tracking)[32]把滤波器作为孪生网络中特殊相关滤波器层;ECOhc(Efficient Convolution Operators for tracking)[1]则是在ECO算法的基础上加入手动提取的特征;UCT(learning Unified Convolutional networks for real-time visual Tracking)[33]提出了一个基于卷积神经网络的端到端的目标追踪模型。从表3可以看出,尽管SiamDCF、CCOT在综合性能EAO方面优于本文算法,但是本文算法的准确率大幅度优于这两个算法,这也表明本文算法具有利用回归的方法直接定位被追踪物体方面的能力。另外,相较于Siamese-FC,本文算法在测试中各方面的能力都有较大提升。
4结语
本文算法结合了孪生网络和检测网络:一方面具有孪生网络在追踪领域定位和实时性的优势;另一方面,检测网络可以得到更精确的位置。本文算法在ILSVRC和GOT-10K进行离线训练。在VOT系列上的测试结果表明,本文算法的性能都达到或者优于其他对比的实时性算法,验证了本文算法的优越性。由于追踪网络依赖孪生网络的预定位,因此,在接下来的工作中,我们将会尝试利用注意力机制的方法提高孪生网络的预定位精度。
参考文献 (References)
[1]DANELLJAN M, BHAT G, KHAN F S, et al. ECO: efficient convolution operators for tracking [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6931-6939.
[2]ZHANG M, XING J, GAO J, et al. Robust visual tracking using joint scale-spatial correlation filters [C]// Proceedings of the 2015 IEEE International Conference on Image Processing. Piscataway: IEEE, 2015: 1468-1472.
[3]LUKEzIC A, VOJIR T, ZAJC L C, et al. Discriminative correlation filter with channel and spatial reliability [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4847-4856.
[4]GALOOGAHI H K, FAGG A, LUCEY S. Learning background-aware correlation filters for visual tracking [C]// Proceedings of the 2017 IEEE Conference on Computer Vision. Piscataway: IEEE, 2017: 1135-1143.
[5]QI Y, ZHANG S, QIN L, et al. Hedged deep tracking [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4303-4311.
[6]DANELLJAN M, ROBINSON A, KHAN F S, et al. Beyond correlation filters: Learning continuous convolution operators for visual tracking [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9909. Cham: Springer, 2016: 472-488.
[7]NAM H, HAN B. Learning multi-domain convolutional neural networks for visual tracking [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4293-4302.
[8]NAM H, BAEK M, HAN B. Modeling and propagating CNNs in a tree structure for visual tracking [EB/OL]. [2019-01-22]. https://arxiv.org/pdf/1608.07242.pdf.
[9]WANG L, OUYANG W, WANG X, et al. STCT: sequentially training convolutional networks for visual tracking [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1373-1381.
[10]BERTINETTO L, VALMADRE J, HENRIQUES J F, et al. Fully-convolutional Siamese networks for object tracking [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9914 . Cham: Springer, 2016: 850-865.
[11]HELD D, THRUN S, SAVARESE S. Learning to track at 100 fps with deep regression networks [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9905. Cham: Springer, 2016: 749-765.
[12]LI B, YAN J, WU W, et al. High performance visual tracking with Siamese region proposal network [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8971-8980.
[13]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C]// Proceedings of the 2015 International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 91-99.
[14]KRISTAN M, MATAS J, LEONARDIS A, et al. The visual object tracking VOT2015 challenge results [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop. Piscataway: IEEE, 2015: 564-586.
[15]KRISTAN M, LEONARDIS A, MATAS J, et al. The visual object tracking VOT2016 challenge results [C]// Proceedings of the 2016 IEEE International Conference on Computer Vision Workshop. Piscataway: IEEE, 2016: 777-823.
[16]KRISTAN M, LEONARDIS A, MATAS J, et al. The visual object tracking VOT2017 challenge results [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop. Piscataway: IEEE, 2017: 1949-1972.
[17]WANG Q, ZHANG M, XING J, et al. Do not lose the details: reinforced representation learning for high performance visual tracking [C]// Proceedings of the 2018 27th International Joint Conference on Artificial Intelligence. Menlo Park: AAAI Press, 2018: 985-991. http://www.dcs.bbk.ac.uk/~sjmaybank/VisualTrackingIJCAI2018.pdf.
[30]BERTINETTO L, VALMADRE J, GOLODETZ S, et al. Staple: complementary learners for real-time tracking [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1401-1409.
[31]NAM H, HAN B. Learning multi-domain convolutional neural networks for visual tracking [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4293-4302.
[32]WANG Q, GAO J, XING J, et al. DCFNet: discriminant correlation filters network for visual tracking [EB/OL]. [2019-01-22]. https://arxiv.org/pdf/1704.04057.pdf.
[33]ZHU Z, HUANG G, ZOU W, et al. UCT: learning unified convolutional networks for real-time visual tracking [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop. Piscataway: IEEE, 2017: 1973-1982.
This work is partially supported by the National Natural Science Foundation of China (61602088), the Major Special Plan for Science and Technology of Guizhou Province (20183002).
DENG Yang, born in 1993, M. S. candidate. His research interests include computer vision, deep learning.
XIE Ning, born in 1983, Ph. D., associate professor. His research interests include machine learning, computer graphics.
YANG Yang, born in 1983, Ph. D., professor. His research interests include artificial intelligence, multimedia information processing.
收稿日期:2019-04-29;修回日期:2019-07-26;錄用日期:2019-08-16。
基金项目:国家自然科学基金资助项目(61602088);贵州省科技重大专项计划项目(20183002)。
作者简介:邓杨(1993—),男,安徽六安人,硕士研究生,主要研究方向:计算机视觉、深度学习;谢宁(1983—),男,吉林长春人,副教授,博士,CCF会员,主要研究方向:机器学习、计算机图形学;杨阳(1983—),男,辽宁大连人,教授,博士,CCF会员,主要研究方向:人工智能、多媒体信息处理。
文章编号:1001-9081(2019)12-3440-05DOI:10.11772/j.issn.1001-9081.2019081427
