语义相似度计算在内检测数据参数匹配中的应用
2019-01-02张河苇金剑董绍华张来斌李宁
张河苇,金剑,董绍华*,张来斌,李宁
1 中国石油大学(北京)机械与储运工程学院,北京 102249
2 中石油管道有限责任公司西部分公司,乌鲁木齐 830000
0 引言
管道内检测数据是维护管道运行的重要参考数据,通过内检测数据可以获得很多有价值的信息,是管道公司查找管道缺陷、进行管道修复的重要依据,因此针对同一管段往往会进行多轮内检测。然而,由于管道所处的环境以及检测过程中部分因素的影响,例如起始点不同、内检测器运行速度不同等,使得多次内检测数据无法完全对齐,降低了数据的利用水平,出现缺陷无法匹配等问题,甚至如果两次检测的检测商不同,则会进一步加剧这个情况。针对多轮内检测的比对问题,目前检测公司都是通过人工比对两次内检测数据,业务量巨大,而且对于管道运营商来说无法确定结果的真实性。
鉴于内检测数据比对的重要性,近期在内检测数据的比对理论方面,部分国内学者也进行了一些研究。王良军等[1]通过调研了解到国外的管道运营公司,例如DOW、BP、EnbrigeSingapore、Gas Company等,已有百余条管道开展了内检测数据比对工作。王良军等综述了内检测比对方法的研究现状,归纳出此项研究工作中的两个关键步骤为内检测里程数据对齐和内检测特征数据比对[1]。王丹丹等[2]提出在确定关键点对齐的前提下,以相对里程、时钟方位以及表面位置为核心参数的比对方法,并运用改进方法对海底管道的剩余强度和剩余寿命进行了评估。孙浩等[3]对内检测比对的流程进行详细叙述,包括关键点对齐和缺陷的活性判断方法,并以天然气管道为例进行方法验证,得到较好的计算效果,其限制条件主要为内检测数据须由同一检测承包商提供。杨贺[4]对比对中的关键流程(焊缝对齐、缺陷点识别)算法进行了设计,其限制条件为导入文件的格式必须与模板一致。
现阶段内检测数据比对方法的基本流程已经确定,存在的问题主要是缺少快速匹配不同检测商提供的内检测报告的方法,该问题的存在限制了大数据背景下的数据对齐研究。通过语义相似度计算方法研究,有利于建立数据匹配字段的关联关系,实现数据的快速入库,为大数据技术的应用奠定基础。
1 基础理论
语义相似度计算是处理自然语言的重要研究内容,在信息检索、翻译等涉及到同义匹配等领域均有应用。目前绝大多数描述概念词语相似度的计算模型的基本思想是Dekang Lin从信息论的角度给出的如式1所示的理论[5]。含义为任意两个对象之间的相似度取决于它们之间的共性commonality和个性differences,共性越多,相似度越大;个性越多,相似度越小[6]。
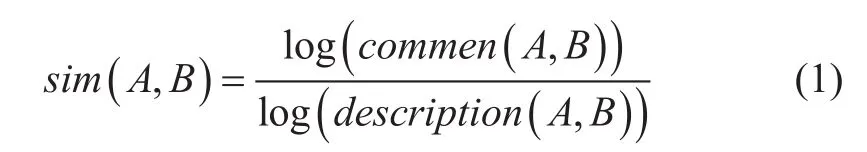
式(1)中的分母表示完整描述A,B所需的信息量大小,分子表示描述A,B共性部分所需的信息量大小,sim(A,B)表示A,B之间的语义相似度。
语义相似度计算的研究领域主要分为两大类[7]:一是依据某种世界知识来计算,主要是通过词典中概念结构关系(上下位关系、同位关系、整体-部分关系等)来计算相似度;二是利用大规模的语料库,利用统计学方法将上下文信息的概率分布作为词语语义相似度的度量。
本文研究的方法属于第一类。目前国外的语义研究词典主要包括WordNet[8]、FrameNet[9]、MindNet[10]等。国内的汉语语义研究词典主要为知网[11]、同义词词林[12]等。由于《同义词词林》的编排结构与国际研究常用的WordNet词典结构最为相似,该词典已逐渐成为汉语语义研究的重点,本文讨论的方法也是基于同义词词林建立的。
1.1 同义词词林
《同义词词林》是1983年由梅家驹等[12]编篆而成的。后来哈工大信息检索研究实验室根据人民日报语料库中词语出现的频率对其进行扩展并对词林的结构和编码进行了改进,形成一部具有汉语大词表的《哈工大信息检索研究室同义词词林扩展版》(《词林扩展版》),共包含77 343词语。原版中只针对大类、中类、小类进行了编码,而《词林扩展版》形成了5层结构,同时将编码等级由三级扩充到了五级,划分为12个大类,95个中类,1428个小类,小类下方进一步划分为4026个词群和17 797个原子词群[13]。《同义词词林》扩展前后词典文件特征对比如表1所示。
同义词词林词典的5层结构如图1所示。上面四层的结点都代表抽象的类别,第5层的叶子结点表示具体的词条或义项[14]。对应5层结构设置了5层编码,第1层用大写英文字母表示;第2层用小写英文字母表示;第3层用二位十进制整数表示;第4层用大写英文字母表示;第5级用二位十进制整数表示。编码总长度为8位,结构具体如表2所示。
需要注意的是,第 8位的标记有“=”、“#”、“@”3种。其中,“=”代表“相等”、“同义”;“#”代表“不等”、“同类”,表示属于同类,但是语义不同;“@ ”代表“自我封闭”、“独立”,它在词典中既没有同义词,也没有相关词[12]。
1.2 语义相似度计算方法
部分学者在基于同义词词林的语义相似度计算方法研究方面已取得一定的成果,认可度较高的有田久乐[15]和王汀[16]提出的算法。
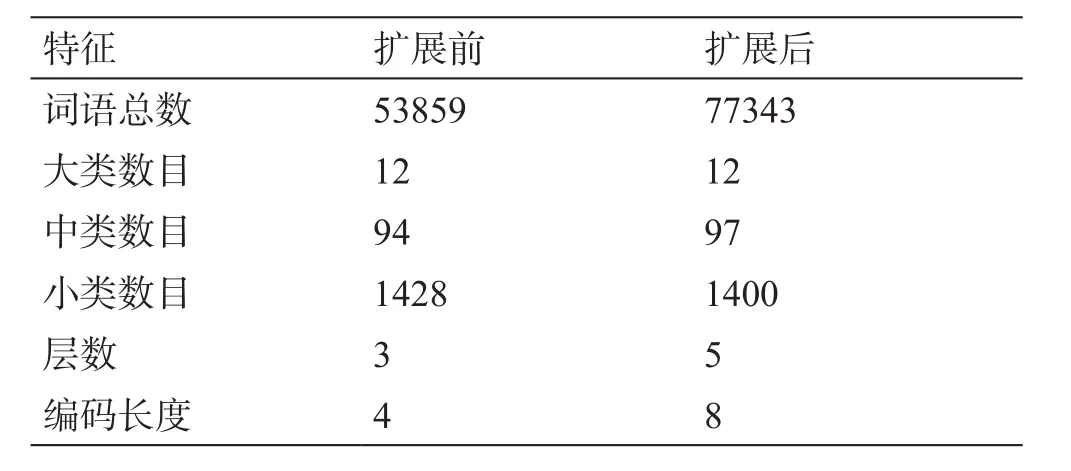
表1 《同义词词林》扩展前后词典文件特征对比Table 1 Comparison of dictionary file features before and after Synonym Word Forest expansion
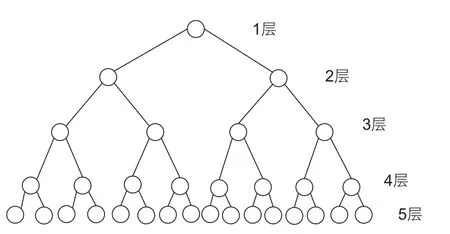
图1 同义词词林词典结构Fig. 1 Synonym Word Forest dictionary structure

表2 编码结构Table 2 Coding structure
1.2.1 田久乐算法
田久乐提出基于义项的语义距离来衡量词语的相似度[15]。假设两个义项A,B的相似度用sim表示。
(1)若两个义项不在同一棵树上

(2)若两个义项在同一颗树上
若在第2层分支,系数取a,
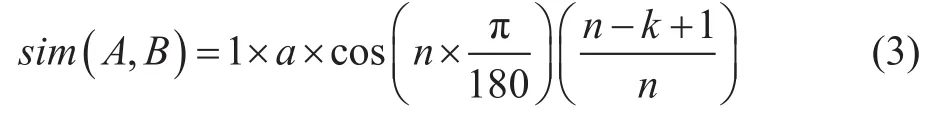
若在第3层分支,系数取b,
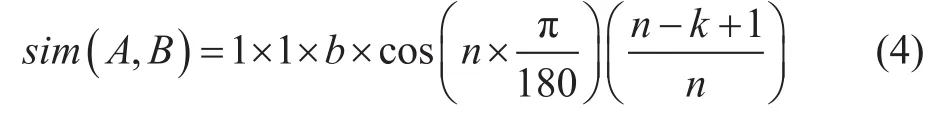
若在第4层分支,系数取c,
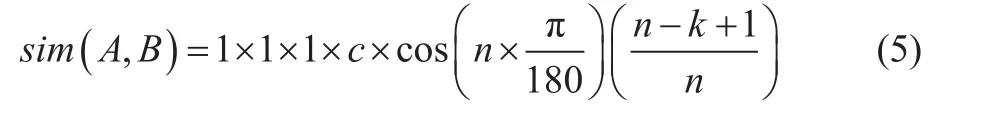
若在第5层分支,系数取d,

(3)若两个义项的编号相同,当末尾号为“=”时,相似度为1;当末尾号为“#”时,直接把定义的系数赋给结果;当末尾号为“@”时,因代表在一个编号中只有一个词,所以不予考虑。
需要注意的是,针对有多个编码的词语,在计算词语相似度时,取最大值。
1.2.2 王汀算法
相较于田久乐提出的算法,王汀算法引入了概念相似度权重系数表示集合L中的元素个数,恒等于5。算法公式[16]如式7所示。

λ∈(0,1),其取值不宜过高;Nt为词元在第i层分支上的节点总数;D为词元的编码距离;特别地,当概念的5 层编码均相等且词林编码末位为“=”时,SIMT的取值为1.0。
权重系数的引入使得不同层级的语义相似度区分更为明确。
2 基于内检测参数的语义相似度计算方法改进
使用前文介绍的两种方法进行实验验证发现,大部分的字段可以被区分开,然而部分字段的相似度计算差值较小,甚至无法区分,主要原因是未考虑路径对语义相似度的影响。由上文两种算法的公式可以看出田久乐算法仅设置了层级系数,王汀算法也只针对层级系数进行调节。本文通过增加路径权重对上述两种方法进行改进,改进后的公式如式8所示:
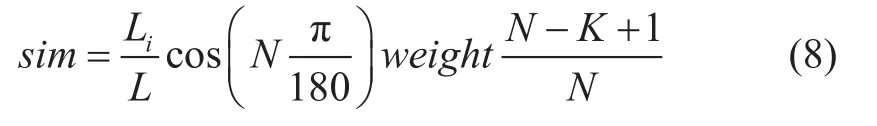
式(8)中引入新的概念—路径权重weight替代原参数λ,目的是增大路径所在层级对相似度值计算结果的影响。取值参照表3[17]中的设定值;Li/L为深度调节参数,Li={1,2,3,4,5},L=5;N代表分支层的节点总数;K代表两个义项的父节点的间距。路径、深度以及N、K的含义如图2所示,图中K=3,N=6。特别地,若两个义项的编号相同,当末尾号为“=”时,认为相似度最大;当末尾号为“#”时,认为相似度最小;当末尾号为“@”时,因代表在一个编号中只有一个词,所以不予考虑。

表3 路径权重设定值Table 3 Setting value of path weight
3 案例
为了验证本文改进方法的有效性,选取管道缺陷描述字段中较难区分的模板字段:焊缝和沟槽,进行算法分析对比。将沟、坑痕、陷坑、槽子等几个描述词语与模板字段(焊缝和沟槽)通过两两计算语义相似度进行匹配。查询同义词词林[13]得到各字段的编码如表4所示。
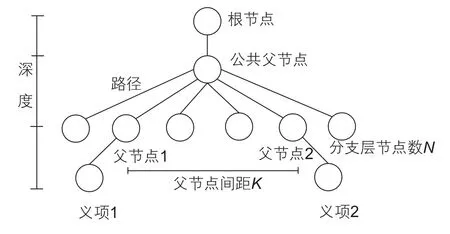
图2 示意图Fig. 2 Schematic
采用田久乐算法得到的结果如表5所示,采用王汀算法得到的结果如表6所示。由计算结果可知,王汀方法在沟槽与槽子、焊缝与槽子的语义相似度计算中,差值为负数,未能成功匹配。
采用本文算法得到结果如表7所示,比较3种方法的差值增加量如表8。对比可知,本文方法相对于其他两种方法非匹配字段的差值均有所增大,字段区分更为明显,并且能够区分其他方法难以区分的字段。
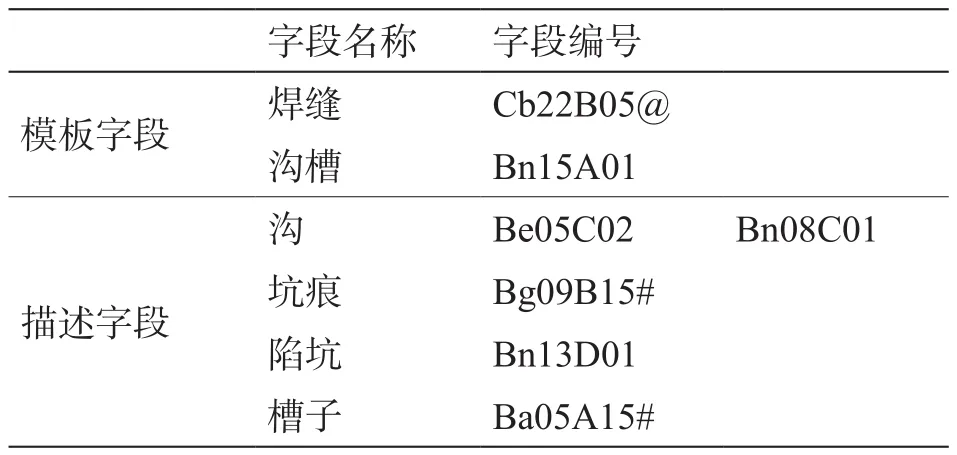
表4 字段编码表Table 4 Field coding table

表5 田久乐方法计算结果Table 5 Calculation results of Tian's method

表6 王汀方法计算结果Table 6 Calculation results of Wang's method

表7 本文方法计算结果Table 7 Calculation results of the improved method

表8 计算结果对比Table 8 Calculation results comparison
4 结束语
管道行业数据容量已经累计到大数据级别,建立大数据库能够有效提高数据利用率,实现数据描述字段的自动匹配,能够为智能化数据导入提供便利,节省人力物力。本文结合语义相似度计算算法,从内检测字段入手,通过增加路径权重改进现有计算方法,使其适用于管道行业。与其他方法对比证明了本文改进方法的有效性。现阶段管道行业亟待建立管道大数据,字段匹配结合已有的数据对齐流程可实现多轮次数据的对齐,提高数据利用率的同时,能够为发掘管道缺陷和风险预测奠定基础。
