模糊关联规则挖掘算法研究
2018-12-28冉娜
摘 要:由于信息技术的发展迅速,海量信息不断累积,如何从大量并且随机的数据集中挖掘出一些有价值的信息,是一个重要而且有意义的研究方向,所以带动了数据挖掘技术的迅速发展。这样能利用模糊关联规则挖掘数据库中各个数据之间的关联,更有效的为我们服务。本文则研究模糊关联规则算法及其改进算法。
关键词:数据挖掘;模糊关联规则
study of fuzzy association rule mining technology
Ran Na
(Department of Computer ,Sichuan TOP IT Vocational Institute ,Chengdu 611743 ,China)
【 ABSTRACT 】 Due to the rapid development of information technology and the accumulation of massive information, it is an important and meaningful research direction and research to excavate some valuable information from a large number of random data sets. So the rapid development of data mining technology. In this way, we can use fuzzy association rules to mine the association between data in the database and serve us more effectively. In this paper, the fuzzy association rules algorithm and its improved algorithm are studied.
【 KEY WORDS 】: data mining; fuzzy association rules mining;
一、研究背景及意义
关联规则重点在于找到不同数据之间的关系,并且找到大于已经设置好的支持度和置信度阀值的,并且隐藏在多个领域之间的数据关联规律[1],按照给不一样的属性进行取值方式,关联规则包含两种类型:第一种是布尔型关联规则,第二种是多值属性关联规则,在对第二种类型的挖掘过程中,如果将属性值精确划分到某个特定范围内,可能会导致比较突出的边界问题,从而导致丢失了区间边界周围的有用信息。为了解决这个问题,在挖掘中加入模糊概念方法,可以将多值属性进行模糊化处理,达到从一个区间到另一个区间的过渡比较平顺,保存区间周围信息的目的[2]。因此,数据库是多值属性的可以用属性模糊化的办法来获得更多、并且更有用的规则,本文的数据集就是属于多值的。
二、算法分析和研究
在推荐系统中使用模糊关联规则的原因如下:首先可以更直接地展示推荐结果,而且会以比较容易的方式让用户接受,其次可以轻松发现新的兴趣点,而且不需知道过多的专业知识。
(一)基于 Fuzzy FP-tree 的模糊关联规则挖掘算法
Lin等人第一次使用了一种叫做模糊关联规则挖掘方法——Fuzzy FP-tree算法进行挖掘[3]。它借鉴了FP-tree的算法中心内容,使用“分层治理”方法,先整理数据库中的信息保存在FFP-tree这样的结构中。FFP-tree的优势是不需要构成复杂的候选项集,基本没有什么内存占用,不足在于处理模糊属性本领较弱,会直接挖掘结果中有意义的信息,无法获得完整的挖掘规则。研究的改进算法有比较强的能力,不会造成有用信息丢失。
(二)改进的模糊关联规则挖掘算法
通过研究了很多篇资料可以得知,对模糊关联规则挖掘影响最大的因素就是支持度的确定和隶属度的确定。隶属度由隶属函数计算出来的。所以要想改进模糊关联规则,就要挖掘出更高效的隶属度函数确定的方法。改进的算法为NFAR(New Fuzzy Association Rules),研究改进算法需要首先通过隶属函数将模糊化数据库为Df 。接着计算各个模糊项目的支持度,筛选出支持度大于最小支持度的数据构成频繁1-项模糊集L1。由L1形成候选2-项集C2 ,通过Fuzzy FP-tree算法对C2去除噪声数据形成包含有意义数据的频繁模糊项目集。所有满足ms的模糊项目都加入到L1 中,可以让数据更加完整。
(三)算法实验
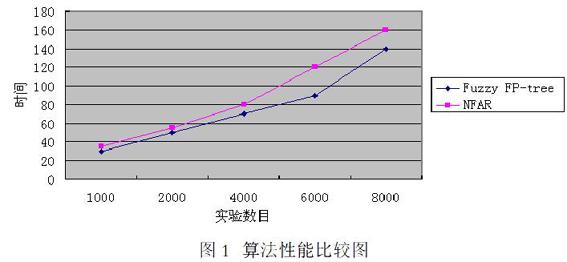
为了评估改进算法的效率,实验数据来自大型数据库订单信息表,对Fuzzy FP-tree算法与改进的模糊关联规则算法NFAR算法进行比较。10000 条相同属性模糊化处理之后分别使用两种算法挖掘关联规则。将数值型属性通过各自设定的隶属函数转化为模糊项目集,就能将数据库 D转化为模糊数据库Df,接下来对转化后的数据进行算法性能测试。
在此部分的实验中,主要是比较两种算法在相同支持度的情况下,对不同数量的数据集进行挖掘,得出频繁项集所用的时间。设置相同的最小支持度为10%,对于数据集取出不同数目的实验数据,分别取出数据集的1000条,2000条,4000条,5000条和8000条进行试验,比较二者算法所用的时间。
比较结果如图1所示
通过上面的实验证明了,改进的NFAR算法在处理不同数量的数据集的情况下,效率是优于Fuzzy FP-tree算法的。在数据集的数量较小时,两种算法的性能相差很小,但是当数据集中的数据的逐渐变多时,改進算法的效率有了较大提高。原因在于改进算法主要是去除噪声数据,去除了对生成频繁项集毫无意义的数据,也就减少了搜索频繁项集所用的时间,所以在数据集多的时候,新的算法可以更好的提升挖掘效率。
三、结语
目前,学者们对关联规则挖掘技术挖掘热情越来越高涨,各个方面都能看到它的运用。模糊关联规则作为其中的一个非常重要的领域,对它的学习具有重大的意义。类似于大型购物网站,与我们的日常生活密切相关,而且伴随着挖掘技术的不断成熟与发展,网站的前景发展广阔。
参考文献:
[1] 廖志 ,郝志峰 ,陈志宏.数据挖掘与数学建模[M].北京:国防工业出版社,2011:188.
[2] 李雄飞 ,董元芳 ,李军.数据挖掘与知识发现[M].北京:高等教育出版社,2015:12..
[3] Lin C W,Hong T P,Lu W H. Linguistic data mining with fuzzy FP-trees[J]. ExpertSystems with Applications,2015,37:4560-4567.
作者简介:
①冉娜(1983-),女,汉,四川广安人,讲师,研究生,主要研究方向为数据挖掘。
