机器学习技术在软件测试领域的应用
2018-12-26葛修婷
葛修婷 潘 娅
(1.西南科技大学计算机科学与技术学院 四川绵阳 621010;2. 西南科技大学计算机应用研究所 四川绵阳 621010)
随着互联网的快速发展,软件的功能不断丰富,软件的规模不断增大,软件的迭代速度不断加快,这给传统的软件测试工作带来了较大的压力,主要体现在:(1)由于Android系统的开源性和碎片化,移动应用软件的安全性与可靠性是一个值得关注的问题,传统的测试无法解决软件多样性带来的安全问题;(2)随着软件开发的复杂度和迭代速度的增加,传统的测试方法无法快速地发现和定位软件缺陷;(3)在软件的开发、测试和运维过程中,产生了大量的数据,如何有效地利用这些数据来提高软件测试的效率也是亟待解决的问题。
近年来,人工智能的发展加速了将机器学习用于软件、医疗、教育等多个方面。机器学习横跨计算机科学、工程技术和统计学等多个学科,致力于研究如何通过计算手段来改善系统自身的性能,即通过从数据中学得的结果,来帮助新数据的预测和判断。机器学习技术对实际问题有较好的普适性,它不仅能从复杂且棘手的问题中提取有用的信息,而且对不精确的、不确定的和错误的数据有一定的容忍性。
由于软件功能的增多和软件规模的增大,利用机器学习技术对产生的数据进行挖掘和学习,可以较准确地对软件中存在的缺陷进行预测和判断,为软件质量保证提供了一定帮助,提高软件测试效率。因此,近年来,利用机器学习技术研究提高软件测试效率和保证软件质量是逐步成为软件测试领域的研究热点之一。
本文希望通过讨论机器学习技术在软件测试领域的应用,以对测试技术改进进行一些展望。论文结构组织如下:第1节总结了机器学习技术在软件测试领域的应用概况的相关文献;第2小节分析和讨论了机器学习在软件测试领域的主要技术;第3小节对全文做了总结。
1 文献的收集与分类
1.1 文献收集方法
本文文献主要来源于两个方面,第一方面是ACM Digital Library,IEEE Xplore Digital Library,Springer Link Online,ScienceDirect等数据库,第二方面是软件的主要期刊和会议,如SATE、ISSTA、ASE等。使用搜索关键词software testing AND machine learning,或software testing and data mining,或software testing and statistical learning theory,或software defects OR faults OR bugs OR vulnerability,或software security OR reliability,同时在文献的标题、摘要、关键词和索引中进行搜索,搜索时间范围从2015年1月到2018年1月。在此基础上,通过去除重复和与软件测试领域不相关的论文,最后共筛选出80余篇文献(因篇幅限制,参考文献仅列出19篇)。
1.2 文献汇总
本文对筛选出的文献进行了分类,按研究主题主要分为基于机器学习的软件安全与可靠性检测、软件缺陷、基于源码的研究和其他4大类,如图1文献分类图(括号的数字表示涉及到此类别的文献数)所示。
从图1的主题分类再细分一下可知,基于机器学习的软件测试领域的研究问题主要集中在二值分类问题和优化问题两方面。大部分研究者主要针对软件安全性与可靠性和软件缺陷方面的研究,这属于二值分类的问题。其余大部分是优化问题,如:自动化测试、测试用例优化。下面将对每个类别逐一进行总结。
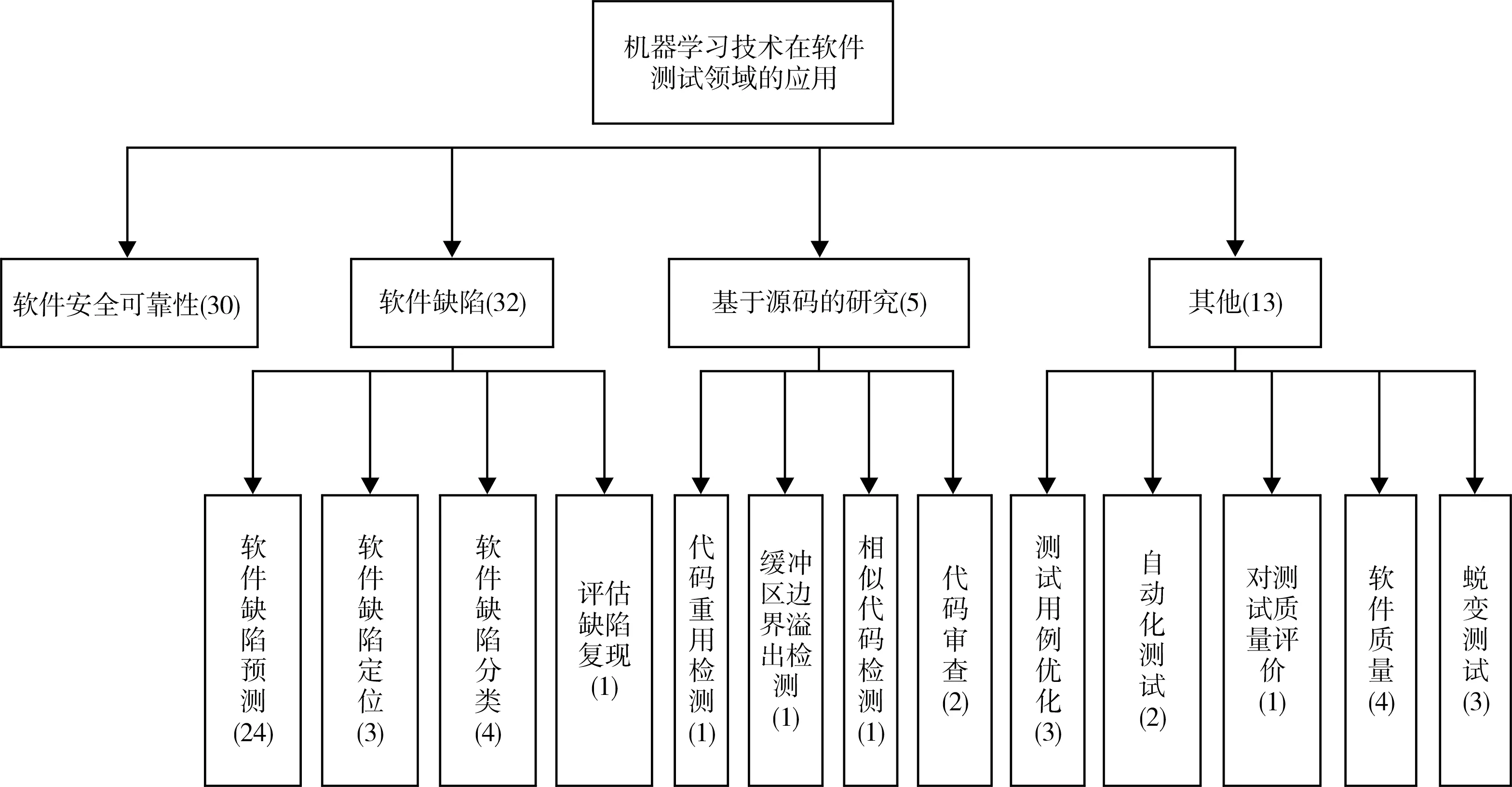
图1 文献分类图Fig.1 Literature classification map
1.2.1 关于软件安全可靠性的研究
在软件安全可靠性研究的30篇文献中,多数是针对移动应用软件的安全性和可靠性的检测和预测,少数文献是针对Window和Linux应用软件[3,14,19]。
对于Window和Linux应用软件的安全性和可靠性检测和预测,通常是对API分类和API调用序列进行分析、利用工具从源码中提取信息、监控并记录软件行为等方法提取信息作为模型的输入特征,利用支持向量机、逻辑回归、随机森林等常用的机器学习模型在虚拟机或沙箱中进行实验和分析。
对于Android应用程序[6,8,12],主要是利用AAPT提取APK的元信息,同时结合应用程序的性能数据、网络流量、软件行为等信息对应用程序进行静态和动态分析,提取特征集,利用常用的机器学习算法进行模型构建、训练、预测和评估,实验结果表明在检测新软件是否是恶意软件,利用机器学习方法对软件安全性和可靠性的检测和预测相对于传统的杀毒软件更快速且更高效。
1.2.2 关于软件缺陷的研究
软件缺陷是计算机软件或程序中存在的某种破坏正常运行能力的问题、错误,或者隐藏的功能缺陷。在软件缺陷方面,所阅读的部分研究文献针对缺陷预测、缺陷定位和缺陷分类进行了研究。
(1)软件缺陷预测
软件缺陷预测是用已有的历史数据来预测软件中是否存在缺陷。研究文献中主要以静态分析为主,动态分析为辅,利用机器学习算法进行模型构建、训练和评估,其中静态分析中提取的特征主要包括:面向对象准则、继承准则、代码准则等特征。由于静态分析所得到的特征较多,且不同的特征对预测缺陷的权重不同,且分类类别不平衡,因此,在将这些特征进行机器学习训练时,需要对数据进行清洗后才能用于学习和训练,以避免产生较大的误差。随着软件测试领域逐渐发展,软件缺陷数据的积累越来越多,充分利用已积累的缺陷数据,可以减少开发人员和测试人员的工作量,提高软件测试的效率。
(2)软件缺陷定位
软件缺陷定位在软件测试领域是一个较为困难的问题。目前,大多数的缺陷需要人为查找和排除,代码走查和审查成为了查找和排除缺陷的重要手段和方法,但是此方法会耗费大量的人力和时间,因此,如何快速有效地定位软件缺陷成为了亟待解决的问题。在研究文献中,软件缺陷定位的方法分为两类,一类是Li等[1]基于模糊理论进行定位,即把历史数据中产生的软件缺陷进行抽象和概括;另一类类似于软件缺陷预测的方法,Jonsson等[17]和Le等[19]以静态分析进行模型构建、训练和评估。
(3)软件缺陷分类
软件缺陷分类主要是判别提交的缺陷是否是真正的缺陷。在研究文献中,不同的学者对缺陷的提取特征不同。例如:在开源的项目中,Pandey等提取JIRA和BUGZILLA中的缺陷描述、发现缺陷的步骤、缺陷隶属的项目等信息作为特征;在众包测试中,Wang等提取交叉领域的历史测试数据作为特征;在软件开发项目中,提出软件的静态分析准则作为特征。在缺陷管理平台的众多缺陷中,准确地判断缺陷可以较少开发人员和测试人员的工作量。但是,随着众包测试和开源工具的增多,检测缺陷的重复提交还需更进一步研究。
(4)缺陷复现
在缺陷管理平台中,不同的缺陷复现的难易程度是不一样的,如闪退或崩溃类型的缺陷。Gu等通过对软件历史版本的缺陷复现的路径分析来预测新缺陷复现的难易程度,在缺陷修复的过程中,给开发人员提供帮助。
1.2.3 基于源码的研究
基于源码的研究主要是对源码进行静态分析找出源码中的缺陷。此研究主题最重要的是对源码进行抽象语法数、函数调用图、符号执行等方法的静态代码分析,提取有效的特征进行模型构建、训练和评估。基于源码的研究大致可分为代码重用、代码相似度的检测、代码审查、缓冲区溢出检测。代码重用和代码相似度检测类似,即检测源码中的相似的代码,对相似的代码进行封装,减少开发的工作量和代码维护成本。在有源码的基础下,对源码进行分析可为软件质量提供更好的保障。
1.2.4 其他
(1)测试用例优化
回归测试在整个软件测试过程中占有较大的比重,软件开发的各个阶段都会进行多次回归测试。在回归测试过程中,测试用例优化是用来解决如何在巨大的测试用例库中选择较少的测试用例以达到较大的代码覆盖率和功能覆盖率的问题。在研究文献中,不同的研究者对测试用例优化问题进行了研究,以整个测试用例库作为特征集,通过对用例自然语言处理、执行用例后的代码覆盖率、变异得分等对测试用例库进行降维,去除冗余的测试用例,再将得到的数据进行模型构建、训练和评估。
(2)自动化测试
自动化测试在软件测试过程中有极其重要的作用,自动化测试能减少测试人员的工作量,提高测试效率。Rosenfeld等利用机器学习基于预定义的activity类别对activity进行分类后,根据不同的分类进行自动化测试,以提高自动化测试的缺陷检测率。
(3)对测试质量评价
评价软件或项目测试质量的好坏对提高测试效率和质量有重要作用。Zhou等通过对软件或项目涉及相关人员、测试流程、软件或项目属性等特征进行模型选择、构建和评估,以此来评估软件或项目的测试质量。一个软件或项目的测试质量的影响因素是多方面且是不稳定的,因此,文献中实验结果还有待考证。
(4)软件质量
软件测试最终目的是提高软件的质量。在研究文献中,通过对历史软件版本的静态分析和动态分析,预测下一版本软件的改变趋势,使得测试人员对软件有更好的了解和测试,以此提高软件的质量。
(5)蜕变测试
蜕变测试是利用一些成功的测试用例来产生后续测试用例的一种技术。在研究文献中,主要是利用机器学习技术去除冗余或相似的蜕变规则以产生有效的蜕变测试用例,达到找到软件缺陷的目的。同时,Nakajima等在测试机器学习程序和软件方面基于蜕变测试为后面的研究者提供了一些思路。
2 文献中的核心技术
机器学习的一般流程是数据收集、数据特征提取和选择、不平衡数据的处理、模型选择与训练、模型预测与评估。在软件测试的过程中,会产生过程数据,同时,软件本身所具有的属性及软件运行过程中会产生大量的数据,因此,可以利用机器学习技术对这些数据进行处理。
通过对上述文献的细致分析和研究,可以发现利用机器学习技术对软件测试过程的贡献和进一步研究的可能性。
2.1 实验数据集的选择
文献研究发现数据来源分为两类,分别是开源数据集和未开源数据集。部分文献的实验数据来自多个数据集。开源数据集是可以免费获取到的,同时,在开源数据集上的实验是可重复性的,使得文献中的结果更具有可信度。未开源数据集主要是来自于商业项目的数据或作者提供的数据集,在此类数据集上的实验不可重复,实验结果可信度不高。图2开源数据集柱状图是对开源数据集的分类及每个分类的简要说明。
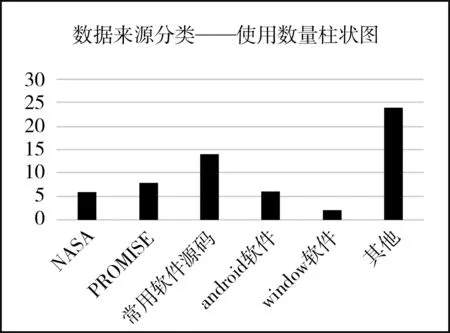
图2 开源数据集柱状图Fig.2 Histogram of open source datasets
(1)NASA
NASA数据集是由美国国家航空航天局测量程序所提供的,并且是公开的。在研究文献中,相对于开源数据集,占比10%。
(2)PROMISE
PROMISE数据集是免费且公开的,可以从PROMISE仓库中获得。在研究文献中,相对于开源数据集,占比大约13%(PROMISE仓库:https://code.google.com/p/promisedata/)。
(3)常用软件源码
常用的软件源码数据集可从代码仓库Github或常用软件的官网上获得,这些常用的软件包括Apache,Eclipse,ANT,JEdit等。但是,需要获得这些常用软件源码的测量数据集时,需要有更高的权限。在研究文献中,相对于开源数据集,占比大约23%。
(4)Android软件
Android软件数据集可从代码仓库Github和Android开源项目(https://source.android.com/index.html)获得。部分Android项目是比较常用且迭代版本较多的软件,如:Email,SMS,Mozilla。在研究文献中,相对于开源数据集,占比大约10%。
(5)Window软件
使用Window软件数据集的有2篇文献,且数据集都是用于恶意软件研究的文献,占比大约3%。
(6)其他
在研究文献中,其他类数据集使用较多。这些数据集都来自免费且公开的数据源,如:
检测僵尸网络的数据集来自http:www.uvic.ca/engineering/ece/isot/datasets/index.p,部分检测恶意软件的数据集来自Defects4J Dataset,部分检测恶意程序的数据集来自KDDCup99。在研究文献中,相对于开源数据集,占比为40%。
综上所述,研究文献中大多数的实验数据集是开源的,因此,在实验中应选择开源且被实验频率较多的数据集进行研究和实验,以避免偶然性误差,确保实验的可重复性。
2.2 特征提取与选择方法
特征提取与选择是机器学习流程中的重要阶段,有效的特征提取和选择技术能提高机器学习模型的预测精度。特征提取和选择技术一般分为两大类,一类是特征降维或特征提取,即组合不同的属性得到新的属性,改变原始特征数据集的特征空间;一类是特征选择,即从原始特征数据集中选择出子集,没有更改原始特征数据集的特征空间。其中特征选择又分为三大类:一类是Filter方法,即对每一维特征赋予权重,然后再依据权重排序,取TopK维特征;一类是Wrapper方法,即将特征子集的选择看作是一个优化问题;一类是Eembedded方法,即在模型确定的情况下学习出对提高模型准确性最好的属性。
表1详细列出了80篇文献中采取的特征提取和特征选择技术统计。其中,在所研究的文献中没有使用Eembedded方法,部分文献中使用了多种特征提取和特征选择技术。

表1 特征提取和特征选择技术统计Table 1 Technical statistics of feature extraction and feature selection
由表1可知,在研究文献中,在特征降维和特征选择的方法中,使用较多的是特征选择方法,特征选择中使用较多的方法是信息增益(IG)和基于相关性特征选择(CFS)。
2.3 类别不平衡处理方法
类别不平衡的处理方法大致可分为三类,一类是过采样,即增加类别较少的样本;一类是欠采样,即减少类别较多的样本;一类是再缩放,即为不同类别赋予不同权重的方式。部分文献采用过采样方式处理类别不平衡问题,过采样中最常用的工具是SMOTE;有的文献采用欠采样方式处理类别不平衡问题;没有文献采用再缩放方式。除此之外,有的文献在利用数据集进行训练时,选择的是类别相对平衡的数据集。其余研究文献未进行类别不平衡处理或文献中未提及是否进行类别不平衡处理。
2.4 机器学习算法
机器学习算法可分为监督学习、半监督学习和无监督学习,不同的场景需要使用不同类别的方法。表2详细列出了机器学习算法以及所研究文献在软件测试领域中所用到的机器学习算法的对比信息。其中,“百分比1”表示涉及到此算法的文献数/涉及到机器学习算法每个分类中总数,“百分比2”表示涉及到此算法的文献数/所有机器学习算法分类的总数。
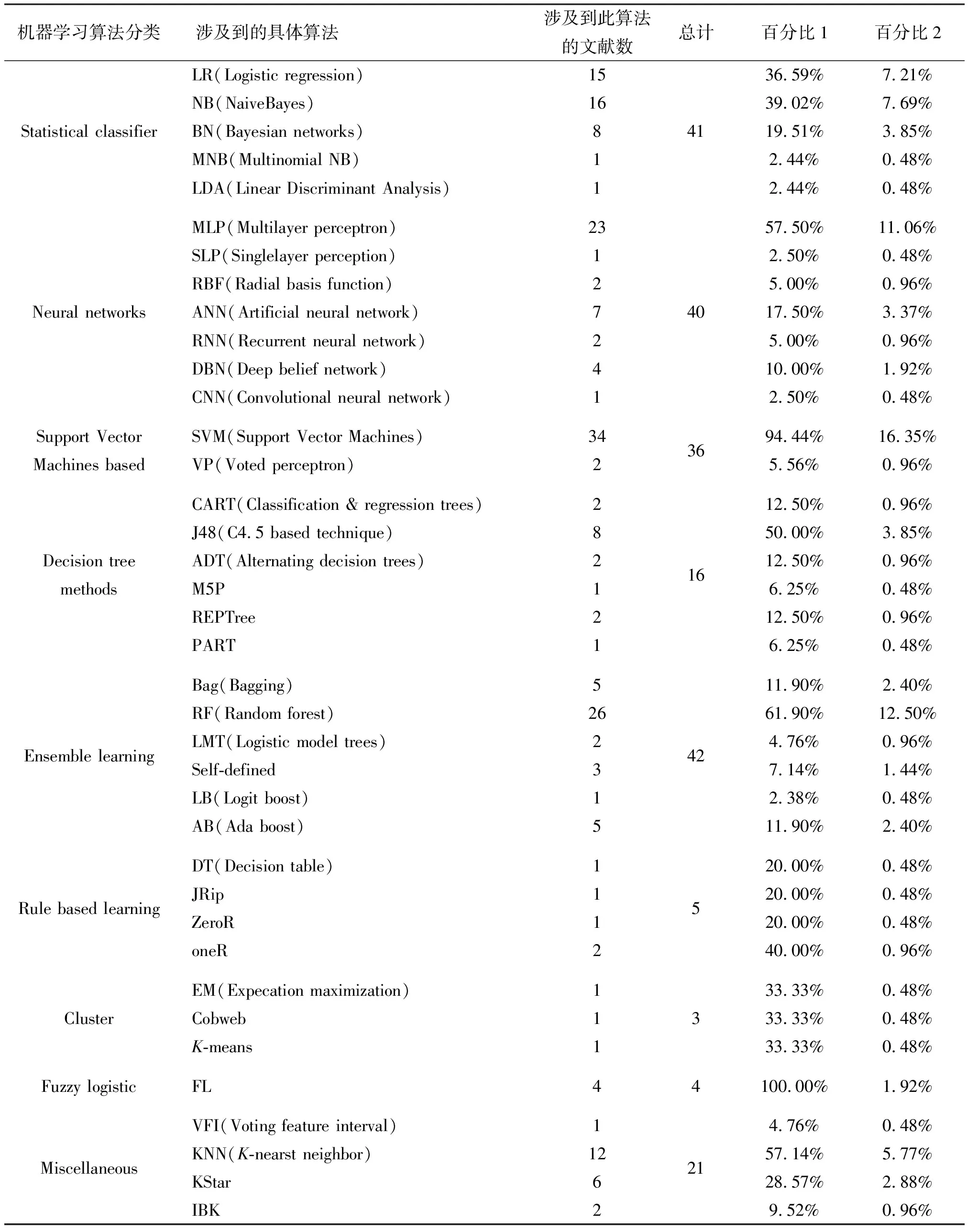
表2 机器学习算法详细信息Table 2 Algorithm details for machine learning
由表2可知,从机器学习算法分类上看,在统计分类中使用较多的算法是逻辑回归(LR)和朴素贝叶斯(NB);在神经网络中使用最多的是多层感知器(MLP);在基于支持向量的方法中使用最多的是支持向量机(SVM);在决策树的方法中使用最多的是C4.5;在集成学习中使用最多的是随机森林(RF);在混杂学习中使用最多的是K近邻(KNN)。从整体上看,在研究文献中,使用最多的机器学习算法是基于支持向量算法中支持向量机(SVM),随后是集成学习中的随机森林算法(RF),神经网络中的多层感知器(MLP)与随机森林(RF)使用的百分比差别不大。支持向量机(SVM)、逻辑回归(LR)、C4.5,朴素贝叶斯(NB)和随机森林(RF)在数据样本较少时也能具有较好的泛化能力,但是当数据样本过大时,训练时长会明显增大。其中朴素贝叶斯(NB)可以较为容易地处理多分类问题;随机森林(RF)可应用在大部分分类器上,无需参数调整,但是对离群点较为敏感。神经网络算法虽然能较好拟合数据,但是易造成过学习、欠学习或局部收敛问题。
2.5 评估准则
评估准则是用来评估机器学习算法的预测精度和泛化能力。预测精度是指利用机器学习算法对某一数据集预测结果的正确率或错误率,泛化能力是用来表征学习系统对新数据的适用性,提高泛化能力是机器学习的目标。表3详细描述了软件测试领域中对所用到机器学习技术的性能评估准则。

表3 性能评估准则使用总结Table 3 Summary of performance evaluation criteria
由表3可知,在研究文献中,在评估机器学习算法的预测精度方面使用较多的是Accuracy,Precision,Recall;在评估机器学习算法的泛化能力方面使用较多的是F-measure及AUC。部分文献对机器学习算法的训练和预测所耗费的时间进行了评估,以证明利用机器学习算法在解决软件测试问题方面的可行性。
3 总结
由于作者搜索的侧重点不同,因此可能有少数利用机器学习技术在软件测试领域的相关文献被遗漏,但是,从本文对机器学习技术在软件测试领域的应用总结来看,本文仍可反映机器学习技术在软件测试领域的应用趋势情况。
本文总结了近几年研究者利用机器学习在软件测试领域的研究和应用进展,同时,对基于机器学习在软件测试领域的研究进行了分类。根据本文对80余篇文献的总结与概述,目前机器学习技术在软件测试领域的研究热点主要是关于软件安全可靠性的研究和关于软件缺陷的研究,其中在关于软件缺陷的研究中,又以软件缺陷预测为主。通过对机器学习在软件测试领域的主要技术的分析和讨论,发现在特征提取、选择技术和机器学习算法等方面仍存在问题,因此,在未来的工作中,应着重关注如何优化特征提取、选择技术和机器学习算法以提高预测的精度。
