基于BiLSTM-CRF模型的汉语否定信息识别
2018-12-20陈世梅
陈世梅,伍 星,唐 凡
(1. 重庆大学 计算机学院,重庆 400044;2. 上海拍拍贷金融信息服务有限公司,上海 201210)
0 引言
否定是自然语言中一种常见的语言现象,用来否定事物的成立、存在或真实性。在评论挖掘[1]、情感分析[2-4]、信息检索[5]等自然语言处理任务中,如果不能正确识别否定信息,则会导致命题真假、情感极性和观点立场等被反转,从而降低此类任务的性能。如例1的句子中虽然包含“愉快”这个表示正向情感的词语,但是该句包含的否定词语“不”反转了正向情感的极性;例2是某网站中的一条商品评论,它被贴上的标签为“味道不好闻”,这是在用户评论标签抽取时由于否定覆盖域识别错误导致的分类错误。
例1我们将为您上次[不愉快的经历]scope1做出最大限度的弥补 。
例2味道很好闻[不是很浓那种]scope1。
否定信息识别包含三个子任务: 否定触发词识别、否定覆盖域识别和否定焦点识别,目前的研究主要集中在否定触发词识别和否定覆盖域识别两个子任务上。其中针对英语的否定触发词识别和否定覆盖域识别已取得初步成果,而汉语的否定触发词识别和否定覆盖域识别效果远不如英语[6]。
否定触发词是文本中含有否定意义的词语或短语,如例1和例2中波浪线表示的词“不”、“不是”。汉语否定触发词识别存在以下难点: 1) 英语单词之间有明显的分隔,汉语是以字为基本书写单位,词语边界模糊,而汉语否定触发词通常是由多个汉字组成的词语或短语,因此分词的准确度会影响到汉语否定触发词识别效果[7];2)汉语由“不”、“没”等含有否定意义的字加上其他字或词构成的否定触发词集合更大,在此不一一列举;3)现有的英文单词数量远大于汉语字数,汉语一词多义现象更频繁,比如,单独的“不”字不仅是表达否定,“好不吓人”中的“不”是助词,是用来加强语气的。
例3[我不知道[这里不能停车]scope1]scope2。
例4我询问前台工作人员附近有没有ATM机,回答说是[没有]scope1。
否定覆盖域是否定触发词的语义作用范围,如例1和例2中“[]”涵盖的部分。汉语否定覆盖域识别和英语否定覆盖域识别相比,除了由于汉语词语边界模糊,分词效果对汉语否定覆盖域识别有一定影响。还存在相同的难点: 1)一个句子中存在多个否定覆盖域嵌套的情况,如例3所示;2)否定触发词本身即为覆盖域的情况,如例4所示。
1 相关工作
1.1 否定触发词识别
否定触发词识别使用的方法有: 基于词表方法、基于统计机器学习方法和基于神经网络方法。
1)基于词表方法该方法是通过人工构造触发词集合来检测文本是否包含否定触发词。Chapman等[5]使用人工构建否定触发词和伪否定触发词集合结合正则表达式开发了NegEx系统,该系统在生物医学病例文本上取得了94.51%的准确率和77.84%的召回率。随后,Chapman等[8]又对该触发词集合进行了扩充,提升了NegEx系统的性能。基于词表方法虽然能够获得比较好的实验效果,但是需要费时费力构造触发词集合,该集合包含的触发词有限且具有文本领域倾向性,因此可移植性和泛化能力都较差。
2)基于统计机器学习方法随着BioScope语料库[9]的发布,对否定触发词的研究大部分转移到该方法上。①否定触发词识别首先被看作分类问题, Lapponi等[10]、Zhu等[11]都采用支持向量机(Support Vector Machine,SVM)分类器结合词性等其他特征来识别否定触发词;Morante等[12]采用k近邻算法并结合词形、词元、词性以及前后三个单词的标记信息等特征来识别否定触发词,在BioScope语料上取得F1值为94.40%。②由于触发词可能由连续的词组成,这一问题也被转化为序列标注问题来解决,Abu-Jbara等[13]以条件随机场(Conditional Random Fields,CRF)为训练模型,词元、词性、前缀、后缀等为特征来识别否定触发词,在*SEM2012评测中,Chowdhury等[14]使用CRF方法识别否定触发词获得该评测最高的F1值93.29%。在汉语否定触发词的识别上,Zou等[15]构建了中文否定与不确定信息语料库(Chinese Negation and Speculation,CNeSp)并使用CRF模型和扩展策略识别该语料中的否定触发词,在CNeSp三个子语料上分别获得F1值为69.78%、85.43%、76.99%。
3)基于神经网络方法该方法结合词向量能避免统计机器学习方法中人工提取特征的问题。He等[7]以双向长短期记忆网络(Bi-directional Long-Short Term Memory,BiLSTM)为模型,字向量为输入特征对汉语否定触发词进行识别,在整个CNeSp语料上获得F1值为77.16%。
1.2 否定覆盖域识别
否定覆盖域识别主要使用的方法有基于统计机器学习方法和基于神经网络方法。
1)基于统计机器学习方法Morante等[12]首次提出使用机器学习的方法解决否定触发词的全覆盖域识别问题,在BioScope语料上使用K近邻算法结合词性、块标记等特征,添加已知触发词特征获得F1值为85.78%,添加预测得到的触发词特征获得F1值为78.60%,;James等[16]以CRF序列标注模型结合词性、触发词的语法树路径为特征识别否定覆盖域;Chen等[17]和邹等[18]也对汉语否定覆盖域识别进行了研究,其中邹等提出了基于元决策树的分类方法和基于依存句法规则的后处理方法,在CNeSp三个子语料上取得精确率分别为69.84%、54.10%、69.07%。
2)基于神经网络方法Lazib等[1]使用LSTM、BiLSTM、GRU三种循环神经网络对评论文本中的否定覆盖域进行识别,实验表明循环神经网络模型取得了比CRF模型更好的效果;Fancellu等[19]使用BiLSTM模型结合词向量、已知触发词、词性等特征识别否定覆盖域,在Conan Doyle’s Sherlock Holmes语料[20]上取得F1值为88.72%。
1.3 现有方法存在的问题
CRF序列标注模型识别否定触发词和覆盖域时,需要依赖人工提取特征,繁杂的特征工程需要耗费大量人力且要求提取特征的人具有相关知识背景;BiLSTM模型输出标签之间没有建立依赖关系,预测得到的标签只由神经网络的输入和隐藏层计算决定,无法利用标签上下文信息,即只能获得每个标签对应的最优解,无法获得全局最优结果。
因此,本文采用BiLSTM-CRF模型来识别汉语否定触发词和覆盖域。该模型中BiLSTM部分能获取和保留长远的上下文信息,CRF部分对BiLSTM输出建立依赖关系,学习标签的上下文信息和利用BiLSTM网络输出的结果,考虑输出标签序列的全局概率,得到最优解。
2 模型
2.1 BiLSTM-CRF模型
BiLSTM-CRF模型由词嵌入层、BiLSTM网络层和CRF层组成。网络结构如图1所示。

图1 BiLSTM-CRF模型网络结构
1) 词嵌入层: 该层将样本中的词语映射为低维稠密向量,该向量是词的分布式表示,通过词语与上下文的关系来刻画词语之间的语义距离。由大规模无标注数据训练出词向量模型再根据词表构建出词向量矩阵Ev×d,其中v表示词表大小,d表示词向量维数,首先将文本信息转换为词表对应的id,然后将文本信息的id通过Ev×d映射为该文本的词向量矩阵Is×d,s表示该文本信息中包含的词语数。
2) BiLSTM网络层: 该层由前向LSTM层和后向LSTM层组成,能够获取长远的过去和未来的上下文信息。该层将词嵌入层得到的词向量矩阵分别输入前向和后向LSTM,前向和后向LSTM输出按位置拼接得到BiLSTM网络层的输出。LSTM单元包含了一个记忆状态和3个“门”节点,记忆状态用于存储长远的历史信息,3个“门”节点分别是输入门、输出门和遗忘门,用于更新记忆状态中的信息。
3) CRF层: 该层能学习标签上下文信息,结合BiLSTM网络层的输出,考虑标签序列的全局概率,从而预测出最大概率的标签序列。该层是以BiLSTM网络的输出Ps×k作为输入,其中s表示当前样本中词语个数,k表示标签数,以状态转移矩阵作为其中一个参数,对标签信息进行学习预测,从而计算出当前样本句子的最佳标签序列。它的计算如式(1)所示。
(1)
其中,A是转移矩阵,Ayi,yi+1表示从yi标签转移到yi+1标签的概率,Pi,yi表示第i个词语被标记为标签yi的概率,score(X,y)表示输入的句子序列X被标记为标签序列为y的概率分数,求得最大的score(X,y)的值,即可得到当前样本句子X的最佳标签序列。
2.2 否定触发词识别
本文在识别否定触发词时,以词语为基本单位。在对否定触发词识别进行训练时,例如,以X={市场,没有,出现,调整}中词语在词表的id作为模型的输入,标签y={ out, cue, out, out }将作为模型的标准输出。其中,out表示不是否定触发词,cue表示否定触发词。
将句X中词语的id输入,经过词嵌入层,映射得到对应的词向量矩阵;在训练中为防止过拟合,本文将得到的词向量矩阵进行一次dropout操作之后再分别输入到BiLSTM层的前向LSTM和后向LSTM中。经过隐藏层单元的计算,将前向和后向LSTM输出按位置拼接得到BiLSTM层的输出序列。
在训练时,CRF层以转移矩阵为参数,BiLSTM的输出序列为输入,使用对数函数对标签序列进行优化,调整转移矩阵的值。在预测句子标签时,将训练得到的转移矩阵和BiLSTM输出作为参数,使用viterbi算法解码求得最佳序列。
2.3 否定覆盖域识别
覆盖域是触发词的语义作用范围,因此覆盖域的识别效果依赖于触发词的识别效果,在本节实验的覆盖域识别中,为避免触发词识别的错误传递,添加已知触发词为特征。是否为触发词用{0,1}标记,若该词语为触发词,则标记为1,否则标记为0。例如,以句子X={我,知道,她,不,喜欢,这种,味道}中词语在词表中的id和触发词标记f={0,0,0,1,0,0,0}作为模型的输入,标签y={ out, out, scope, scope, scope, scope, scope}作为模型的标准输出。其中,out表示不在否定覆盖域内,scope表示在否定覆盖域内。
在词嵌入层,分别映射得到词语的词向量矩阵和触发词标记对应的向量矩阵,将两个矩阵拼接后的结果作为该层的输出。
在BiLSTM网络层和CRF层的步骤同否定触发词识别中的步骤相似。
3 实验
3.1 否定触发词识别
3.1.1 数据分析及预处理
本节实验采用的语料是中文否定和不确定信息语料库(CNeSp)。语料共分为三个部分,财经文章(Financial article,Fin.)、科技文献(Scientific literature,Sci.)和酒店评论(Product review,Prod.)。去除CNeSp语料中不确定信息部分后,语料的详细信息见表1,将语料按照7∶2∶1的比例随机划分为训练集、验证集和测试集。本文对否定触发词识别进行4组实验,即对Fin.、Sci.和Prod.三个子语料分别做实验,再将它们合并为一个语料(All)做实验。对语料进行分词时,由于中文是以字作为最小粒度,词语边界比较模糊,分词时可能如例5所示,“不太强”被分词为“不/太强”,但是在语料中,“不太”被标注为否定触发词,“强”不是否定触发词。因此为了避免分词后在一个词语中出现其中一个字属于否定触发词,另一个字不属于的情况,采取将语料中被标注为触发词的字和其余字分开后再进行分词的处理方法。
例5年线的支撑力度相对来说不太强。
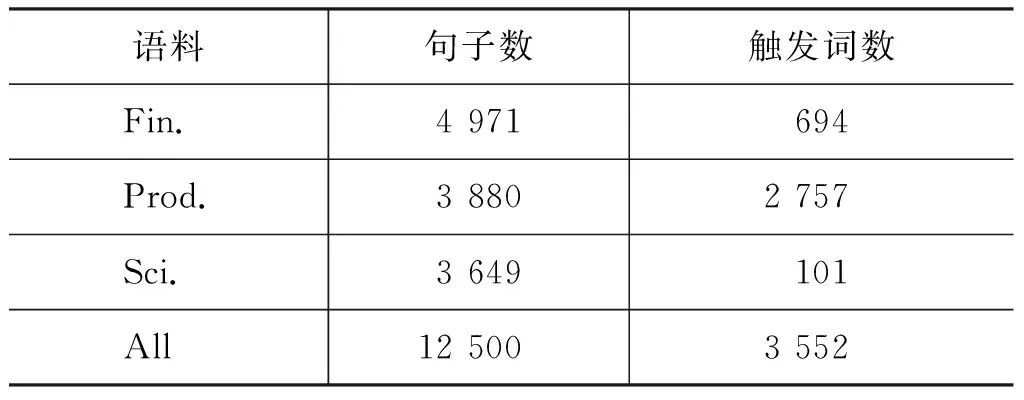
表1 语料库的详细信息
本文采用搜狗实验室提供的搜狐新闻和数据集CNeSp作为词向量模型的训练语料,该训练语料大小为2G。将语料进行分词后使用Word2Vec工具训练得到词向量模型,根据语料库的词表构建词向量矩阵Ev×d,其中v表示词典的词语个数,d表示词向量维数。训练词向量时,维数选择200,窗口选择5,由于每个否定触发词在文本中相对稀疏,出现的次数并不多,因此选择skip-gram模型[21]。
3.1.2 评价指标
准确率P、召回率R、准确率和召回率的调和平均数F1值作为评价指标。评价指标定义如下:P=TP/(TP+FP),R=TP/(TP+FN),F1=2PR/(P+R)。其中,TP表示语料中否定触发词被系统正确判定为否定触发词的集合,FP表示语料中非否定触发词被系统错误判定为否定触发词的集合,FN表示语料中否定触发词被系统错误判定为非否定触发词的集合。
3.1.3 实验结果及分析
实验在测试集上的结果如表2所示,实验结果表明: 1)在汉语否定触发词识别任务中,本文采用BiLSTM-CRF为实验模型,词向量为输入特征的方法在Fin.语料和Prod.语料取得了比Zou等的CRF模型和He等的BiLSTM模型更好的效果,F1值高10%左右; 2)在Sci.语料上,本文实验结果比He等的BiLSTM模型结果好,比Zou等的CRF模型方法结果更差; 3)在All语料上,实验获得F1值为91.61%,比He等的BiLSTM模型结果更好;4)本文实验在Prod.语料上取得的结果优于其他语料。

表2 触发词实验结果
实验结果分析如下: 1)在BiLSTM网络中通过LSTM单元来实现对文本长远上下文信息的保留,并且添加的CRF层能够很好地利用句子层面的信息,结合BiLSTM输出计算出最佳标签序列,因此能获得更高的F1值; 2)结合表1语料库详细信息可以看出,Sci.语料中的否定触发词太稀疏,在训练的过程中,实验需要大量的样本数据进行学习,然而该语料包含的3 649个句子中只包含了101个否定触发词,达不到学习效果。而否定触发词在Prod.语料中更加稠密,学习效果更好,因此识别效果更好。
3.2 否定覆盖域识别
3.2.1 数据分析及预处理
本节实验选择CNeSp语料中包含否定信息的句子作为语料,分词规则和否定触发词处理语料过程一致。针对语料中存在的否定覆盖域重合的情况,为了正确识别出每一个否定触发词所对应的覆盖域,本文将样本处理为每个句子仅包含一个否定触发词和其对应的否定覆盖域。如表3所示,将原句经过处理后变成句1和句2。经过处理后的语料详细信息如表4所示。

表3 处理数据结果

表4 语料库的详细信息
为了验证BiLSTM-CRF模型在否定覆盖域识别上的效果,避免触发词识别错误的传递,本节实验将已知触发词作为特征。表征触发词的词向量矩阵构建为Ed,其中d表示词向量维度,该词向量矩阵中只包含两个向量,一个表示触发词向量,另一个表示非触发词向量。
3.2.2 评价指标
评价指标采用准确率P、召回率R、准确率和召回率的调和平均数F1值和精确率(accuracy,Acc),精确率以句子为单位,要求样本句子的预测标签和真实标签完全匹配。P、R、F1同否定触发词识别的评价指标定义相同。
3.2.3 实验结果及分析
本节实验以BiLSTM-CRF为模型添加已知触发词为特征的实验结果对比如表5所示。实验结果表明: 在都以已知触发词为特征情况下,1)本节实验在除Sci.语料之外的子语料上获得了更高的精确率; 2)Fin.语料获得的精确率最高。根据实验结果分析认为: 1)基于BiLSTM-CRF模型结合词向量和已知触发词特征的方法,能够更好的利用和学习到否定覆盖域和否定触发词的文本特征以及它们标签之间的关系。 但Sci.子语料稀少,只有101个句子,因此达不到学习的目的。2)尽管Prod.语料比Fin.语料包含的否定句更多,但是Fin.语料是财经新闻数据,句式更加标准,表达更加准确,Prod.语料是酒店评论数据,包含更多口语化句子、错别字和繁体字等,因此Fin.语料上获得精确率更高。

表5 覆盖域识别结果(Acc.)
4 错误分析
4.1 否定触发词结果错误分析
在否定触发词识别实验测试集结果中,否定触发词识别错误大致有以下几类: 1)分词不同带来结果不同,如“并不乐观”在语料中“并不”被标注为触发词,当分词为“并/不”,只识别出“不”属于否定触发词,当分词为“并不/”时,识别出“并不”属于否定触发词。2)语料标注错误,如“灾难没有特别严重”中“没有”属于否定触发词,在测试集中被识别出来,但语料中未标注。
4.2 否定覆盖域结果错误分析
在否定覆盖域识别实验测试集结果中,否定覆盖域识别错误大致有以下几类: 1)跨句难以识别完整,例如“不存在好的财报先公布,坏的财报后公布的规律”,该句覆盖域只正确识别到前半句。分析原因认为,在覆盖域实验中只以触发词特征和词向量作为输入,可能需要融入更多外部句法层面的信息更进一步提高覆盖域实验中跨句识别能力。2)语料标注错误,如“电梯内不许吸烟”语料只标注“不许吸烟”在覆盖域内,但是该方法识别出整句都在“不许”的覆盖域内,因为否定触发词“不许”的主语是“电梯内”,所以应该包含。
5 总结
本文采用BiLSTM-CRF作为实验模型,预训练的词向量作为输入特征识别否定触发词,在此模型的基础上添加已知触发词特征识别否定覆盖域。否定触发词识别实验结果显示,在CNeSp语料上除Sci.子语料外,否定触发词识别获得的F1值均高于现有汉语否定触发词识别模型效果。否定覆盖域识别实验结果显示,在CNeSp语料上除Sci.子语料外,否定覆盖域识别获得的精确率高于现有处理汉语否定覆盖域识别的系统。实验结果表明,本文采用的BiLSTM-CRF模型在处理汉语否定触发词识别和覆盖域识别时能够克服CRF模型和BiLSTM等循环神经网络模型中存在的缺点,取得更好的实验效果。
