基于CRF和半监督学习的维吾尔文命名实体识别
2018-12-20王路路艾山吾买尔买合木提买买提卡哈尔江阿比的热西提吐尔根依布拉音
王路路,艾山·吾买尔,买合木提·买买提,卡哈尔江·阿比的热西提,吐尔根·依布拉音
(1. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2. 新疆大学 新疆多语种信息技术实验室,新疆 乌鲁木齐 830046)
0 引言
随着丝绸之路经济带核心区建设的推进,多语言信息处理是实现国际之间绿色健康通信的重要保障。维吾尔语作为我国的“一带一路”重大倡议中涉及的重要语言之一,对其进行信息抽取对多语言信息处理研究工作具有重要意义。维吾尔文命名实体识别(Named Entity Recognition, NER) 是信息抽取中的一个重要研究内容,其任务是针对文本中的基本单位(如人名、地名、组织机构名等)进行类别标注。
现阶段部分学者在维吾尔文的命名实体研究上已取得初步研究成果,主要集中在对命名实体中的某一个类别,即人名[1-3]、地名[4-5]或机构名[6]等单一类别的识别,对人名、地名、机构名同时进行识别的方法还未见研究。且现有研究方法较为传统,主要采用基于规则[4,6]或基于统计[1-4]的有监督方法。基于规则的方法依赖于人工编写的规则,可移植性差,应用范围受到限制,且随着规则增多,规则之间可能会出现冲突;基于统计的有监督方法依赖于标注语料库中的有监督特征,无法利用未标注语料库中的无监督语义和结构特征。维吾尔语属于资源匮乏语言,扩大标注语料库是有效提高命名实体识别性能的方法之一,但语料库标注成本较大。由于维吾尔语是黏着性语言,其丰富复杂的形态易造成严重的数据稀疏性,使得语义或结构特征无法用无监督学习特征来表示。例如,“Xinjangdiki(在新疆的)”的出现将会降低“Xinjang (新疆)”的重复率,从而导致未登录词增多。现有的维吾尔文命名实体识别研究通常是通过分析语言特有的特征以及形态结构在某种程度上缓解数据稀疏问题[1,5]。往往因依赖于标注语料库,而无法有效利用未标注语料库获取语义和结构表示信息。
基于以上问题,本文借鉴Guo 等[7]的工作。首先,利用大规模的未标记语料训练词向量;其次,将通过词向量获取的无监督语义和结构特征、词法特征、词典特征进行有效的结合,并以条件随机场为基本框架,提出一种基于半监督学习的维吾尔文命名实体识别方法。为了验证方法的有效性,本文从寻找每类特征的最佳特征组合出发,分别在三类中选取不同特征组合进行实验对比。其中词法特征组合对比实验体现了音节特征和一级词性的有效性;词典特征组合对比实验说明了同时引入四类词典特征能够提高命名实体整体上的效果;无监督学习特征组合实验突出了引入K-means聚类特征的优势。在此基础上,本文将无监督学习特征、词法特征、词典特征进行不同的特征组合进行对比,得出CRF融合词法特征比词典特征、无监督学习特征识别效果更佳;无监督学习特征能够从大规模的未标注数据集中获取词的语义信息,其F值与词法特征相当,并且与分析语言特有特征和形态结构相比,无监督学习可以大大减少工作量;最终,实验进一步表明了将词法特征和无监督学习特征有机结合,可以在大大降低人工选取特征的代价的同时提高维吾尔文的命名实体识别性能;此外,相比于神经网络模型,本文模型更适合于实际应用。
1 相关研究
对于NER而言,常用的方法主要是基于规则方法和基于机器学习方法等。基于规则的方法通常依赖于由领域语言专家编制的规则。如闫丹辉等[8]分析了越南语三类命名实体的构成规律,制定了152条规则。虽识别的准确率较高,但由于对规则库的依赖,应用范围受到限制,且大量规则编写之后,规则之间可能出现冲突。基于机器学习的方法是指通过已知模型用对人工标注的语料或者生语料进行训练和学习后对命名实体进行识别,实验结果大部分由机器完成,具有较强客观性以及移植性。其中,基于统计的机器学习方法主要包括隐马尔可夫模型(Hidden Markov Model,HMM)[9-10]、最大熵模型(Maximum Entropy, ME)[11]、支持向量机模型(Su-pport Vector Method, SVM)[12-13]、条件随机场模型(Conditional Random Field, CRF)[14-15]等;近年来,随着自然语言处理各项任务的深入研究,深度学习方法得到广泛应用,并成功应用在命名实体识别任务中。例如,Guo 等[7]利用未标注语料训练词向量实现了基于半监督学习的命名实体识别,并且取得了较好的识别性能;Huang等[16]提出了一种基于Bi-LSTM-CRF的序列标注模型,应用在多NLP任务上已实现精确的标注精度;Lample等[17]提出了一种基于以字符向量和词向量作为输入特征的Bi-LSTM-CRF的序列标注模型;Ma等[18]提出了一种基于Bi-LSTM、CNN、CRF相结合的端到端的序列标注模型,并消除了复杂的特征工程;Rei等[19]提出一种基于注意力机制的神经网络结构学习字符级信息;Dong等[20]提出了一种基于以字符向量以及偏旁特征向量作为输入特征的BiLSTM-CRF模型以实现中文命名实体识别;鲁亚楠等[21]学习词向量时引入位置信息,有效改善了位置信息导致的语义表示偏差;张海楠等[22]利用字词联合的DNN结构并引入词性特征使中文命名实体识别性能较大的提升。
从以上国内外研究现状看出,国内对中文命名实体识别的相关研究已取得了一定的成果,但是维吾尔文的命名实体识别研究还处于起步阶段[23],现阶段的研究主要集中在单类实体并且研究方法较为传统。例如,麦合甫热提等[6]提出了基于语法语义知识的方法对维吾尔文机构名进行识别的策略;塔什甫拉提等[3]从不同角度获取维吾尔语单词单元并结合CRF模型实现了维吾尔语人名识别方法,同时采用基于规则的方法识别汉族人名;买合木提等[5]在维吾尔文地名识别中引入不同特征的CRF与规则后处理的方法,F值达到了92.03%。
2 基于CRF的维吾尔文命名实体识别
本文利用新疆多语种信息技术实验室的未标注语料进行词向量训练,首先通过二值化[7]、K-mean聚类和余弦相似度等方法,根据不同词向量训练模型,获取每个词的二值化向量、聚类、相似词等无监督学习特征;然后引入词法特征、词典特征以及无监督学习过程获取的特征,通过对不同特征的组合进行实验,最终确定最佳识别效果的CRF模型。整体流程如图1所示。
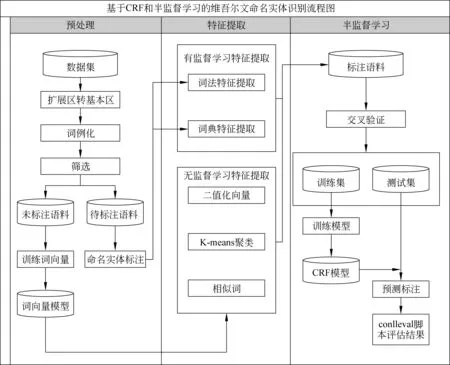
图1 维吾尔文命名实体识别流程图
2.1 CRF模型
条件随机场最早由Lafferty等[24]提出,其集合了最大熵模型和隐马尔科夫模型的特点,也称为马尔科夫随机场。它是一种以给定输入序列为条件预测输出序列的概率的无向图模型,当给定一组需要标记的观察序列的条件时,可以使用CRF模型预测一个待标记序列的联合概率分布。
命名实体识别可以定义为序列标注问题,即判断观察词是否在预先定义的标记序列内。条件随机场是常被用于自然语言处理领域进行序列标注识别和分割数据的条件概率模型。它使用全局状态的指数模型不仅实现了对所有特征进行归一化,还解决了标记偏值问题,所以CRF对命名实体识别研究很适用。
对于维吾尔文命名实体识别,给定观察序列x={x1,x2,…,xt}和标注序列y={y1,y2,…,yt},其中t表示给定观察序列的长度,则定义一个线性条件随机场模型,如式(1)所示。
(1)
式(1)中,fj(yi-1,yi,x,i)是一个特征函数,通常情况下它是二值的。其中将句子x,当前状态的位置i和标记yi,以及前一个状态的yi-1作为输入;λj是通过模型学习训练获得的参数,即相应特征函数的权重;z(x)是归一化函数,使所有可能标注序列的条件概率之和为1,如式(2)所示。
(2)
2.2 特征集定义
文献[25]验证了上下文窗口大小对命名实体识别具有一定的影响,所以本文也采用上下文特征提高实体识别能力,其中上下文特征是指以当前词为中心的前n个词和后n个词的信息。例如,窗口大小是5,表示考虑当前词的前两个词和后两个词,即wi-2,wi-1,wt,wi+1,wi+2。本文通过对语料中的实体进行分析,可以从以下三个方面选取特征。
2.2.1 词法特征
a. 词性特征(POS)
词性特征通常作为语言独立特征,对维吾尔文命名实体识别可能有重要作用。新疆多语种信息技术实验室自然语言处理组制定标注集包含一级词性(15个)和二级词性(64个)。因此,本文将两级词性都考虑在内。其中,该组提供的维吾尔语自然语言处理工具包(网络服务[注]http: //202.201.255.248: 8088/xjuapi/uyghurtext/)中一级词性的准确率是98.20%、二级词性的准确率为95.55%[26]。
b. 音节(prefix _sylable)
维吾尔语的音节是由一个元音字母与一个辅音字母或者一个以上的辅音组成。在文献[26]验证了维吾尔语的不同音节对词性标注的贡献,且文献[5]在地名识别时验证了后音节对地名识别的影响。因此,本文针对每个单词选用前两个音节的和后两个音节作为此单词的音节特征;对于音节长度小于2的单词,取单词本身作为特征。其中,音节切分利用上述的维吾尔语自然语言处理工具包(网络服务)进行。
c. 词长度(len_word)
据统计,标注语料中的命名实体中单词长度大于3的数量占93.42%,所以在词形上,本文将词长度考虑在内作为命名实体识别的特征。
d. 单词音节个数(num_syl)
对标注语料统计发现命名实体中每个单词音节个数大于3的占55.04%,而非命名实体的单词音节个数大于3仅占42.85%。因此,本文将音节长度作为影响命名实体识别的实验指标。
2.2.2 词典特征
1) 共有词典(MD)
a. 名词词缀词典
命名实体本质上是名词,但在维吾尔语中名词常常伴随着名词词缀出现,故本文将维吾尔语51个名词词缀构建成词典,用于判断当前词是否是命名实体的尾词。如果当前词以词典中任何一个词缀结尾,则表示Y-NS。否则,表示N-NS。
b. 缩写词词典
维吾尔语人名、地名、机构名等经常会出现缩写词,如麻赫穆德·喀什噶里(M·Qeshqiri)、新疆维吾尔自治区(ShUAR)、中国共产党(JKP)等;此外,国际通用的缩写词依然按照拉丁文的书写方式。比如,WTO、BBC、OPEC。为了验证缩写词对命名实体的影响,建立了含有15个缩写词的词典。判断当前词是否在缩写词词表内,若在,则表示为Y-ABB。若不在,则表示为N-ABB。
2) 人名词典(PD)
a. 汉族人名姓氏词典
汉族人名以“姓氏”+“名字”命名,而其中的姓氏几乎都属于百家姓(共计504个)。维吾尔语中汉族人名是通过音译的,并且姓氏是单独一个词。本文通过建立汉族人名姓氏的维吾尔文词典提高汉族人名的识别率,该词典中共有301个。判断当前词是否在汉语人名姓氏词典中。若在,则表示为该类特征为Y-PLN。若不在,则表示为N-PLN。
b. 维吾尔人名特征词缀词典
维吾尔人名大多数由两个单词组成。第一个词表示名字,第二个词表示姓氏。而名字和姓氏本质上都属于名字,这些名字中经常出现“古丽(gül)”、“江(jan)”等词缀。本文收集该类维吾尔人名特征词缀共27个,建立相应的词典,以作为命名实体识别一个特征。如果当前词中包含维吾尔人名特征词缀,则表示该特征为Y-PS,否则为N-PS。
c. 人名指界词词典
在人名后经常出现“先生(ependi)”、“女士(xanim)”、“书记(shuji)”、“主任(mudir)”等。本文收集了99个称呼词或者职称词,为验证该特征是否对命名实体识别有影响,本文依据此类词构建了人名指界词词典。如果当前词是该词典中任何一个,则表示当前词的人名指界词特征为Y-PF。否则,为N-PF。
3) 地名词典(LD)
a. 常用地名词典
基于各级城市名构建了规模大小为3 013的常用地名词典,用于识别在命名实体中常出现的地名。例如,机构名“北京市国家税务局(B⊇yjing sheherlik döletlik baj idarisi)”、地名“北京海淀区海淀街道(B⊇yjing xeydiyen rayoni xeydiyen kochisi)”中的“北京(B⊇yjing)”。如果当前词是常用地名,则表示为Y-LN。否则,用N-LN表示。
b. 地名特征词词典
本文依据地名中出现的“省(ölke)”、“市(sheher)”、“县(nahiye)”、“乡(y⊇za)”等区域划分单位建立地名特征词词典(词典规模为126个词),并依据此词典对命名实体进行识别。以当前词是否在地名特征词词典中为特征,如果是,则当前词的地名特征词特征值为Y-LF。否则,为N-LF。
c. 地名特征词缀词典
在维吾尔文中部分地名是具有共同的地名词缀[5],如“韩国(Koriye)”和“英国(Engiliye)”中的“ye”是相同的词缀,本文将此类地名词缀特征进行整理,总计31个,并生成词典。以当前词是否以地名特征词缀词典中任何一个后缀结尾为特征。如果是,则当前词的地名特征词缀的特征值为Y-LS。否则,为N-LS。
4) 机构名词典(OD)
a. 机构名特征词词典
对于明显表示机构名的名词词尾如“大学(uniw⊇rsit⊇t)”、“局(idare)”、“厅(nazaret)”、“办公室(ishxanisi)”、“公司(shirkiti)”、“集团(guruhi)”等,本文建立机构名特征词词典,共包含1 243个特征词。若当前词在机构名特征词词典中,则当前词的机构名特征词存在特征表示Y-OF。否则,为N-OF。
b. 机构名修饰词词典
对于部分机构名内存在的“有限(cheklik)”“附属(qarmiqidiki)”“驻(turushluq)”等机构修饰词,本文通过建立包含63个机构名修饰词的词典来提高机构名识别精度。如果当前词出现在该词典中,则当前词的机构名修饰词存在特征为Y-OIW。否则,为N-OIW。
2.2.3 无监督学习特征
词向量有助于优化NLP多种学习任务,使其拥有更好的性能[27],它是将句子中的单词映射成低维空间的数值向量。因此本文考虑使用大规模的未标记数据来训练词向量模型。本文使用基于Gensim[注]https: //radimrehurek.com/gensim/index.html的Word2Vec开源工具获取词向量,然后根据词向量获取不同的特征以供实验选择。Word2Vec的词向量包含两种模型,分别是CBOW和Skip-gram。其中,CBOW模型的目标是由上下文来预测当前词的概率,Skip-gram模型是根据当前词来预测上下文的概率。因此,本文将两种模型都考虑在内,以判断哪种模型的影响力较大。
a. 二值化词向量特征

其中,nj+表示第j维中Mj>0的行数,nj-表示第j维中Mj<0的行数。则离散值的矩阵向量可以通过式(5)进行转换:
(5)
b. 基于词向量的K-means聚类特征
由于命名实体及其前后的单词存在一定的规律,本文将对词表中的词进行聚类,并将其所属类别作为特征。K-means聚类算法是一种典型的聚类算法,采用距离作为相似性指标。其主要思想是: 给定数据集,选取数据集的k个对象为初始中点,每个对象代表一个簇的中心;按照样本中数据对象和聚类中心之间的相似度指标将数据进行划分;不断地更新离聚类中心的最近均值。本文在词向量的基础上,用sklean的K-means算法对词向量进行聚类,将相似度较高的词聚成一簇。
K-means聚类个数的不同对实验结果影响也会有所不同,因此,我们采用不同的聚类个数K,来反映不同粒度层次对命名实体识别的影响。
c. 相似词特征
词向量可以获取单词的潜在特征及相关的词汇和语义信息。因此,能够通过词向量获取指定单词的相近词。相似词可通过计算每个单词向量和所有其他单词的余弦相似度获得。假如单词word1、word2的向量表示分别是n维的向量A和B,即向量A=(A1,A2,…,An),B=(B1,B2,…,Bn),则word1和word2的余弦相似度计算如式(6)所示。
(6)
其中,sim∈[-1,1],sim值越大,表示word1和word2关联度越高,即sim越接近1代表word1和word2越相似。
不同词向量模型获取的相似词可能对实验结果影响有所不同。本文通过余弦相似度方法获取每个词的基于不同模型的相似词,并选用相似度最高的10个词作为实验数据。由于CBOW模型和Skip-gram模型的原理不同,为了充分结合两种模型的优势,本文分别将CBOW和Skip-gram获取的相似词合并,并按照相似度进行降序排序,同样提取相似度最高的10个词(同一个相似词仅出现一次)。此外相似词的个数可能对实验结果具有一定的影响。因此针对相似词的三种提取方式,本文以不同相似词个数展开实验分析,来反映相似词对命名实体识别性能的影响。
2.3 特征模板的选取
融合不同特征对于命名实体识别的影响不容忽视,因此特征模板的筛选对识别具有极其关键的作用。命名实体识别需要考虑上下文环境, 而CRF模型能综合上下文信息以及外部特征。
本文采用CRFSharp开源工具[注]http: //github.com/zhongkaifu/CRFSharp构建维吾尔语命名实体识别模型,利用定义的特征模板获取特征并进行学习。在模型中,不仅要包含原子特征(一元特征)模板,还需要定义复合特征模板。本文的特征模板定义如表1所示。
表1中,w表示语料的第一列,F表示除词语以外的其他特征列;其中复合特征中的Fi-1|Fi|Fi+1(i=0)表示三元特征组合,其他三个表示二元特征组合。

表1 特征模板
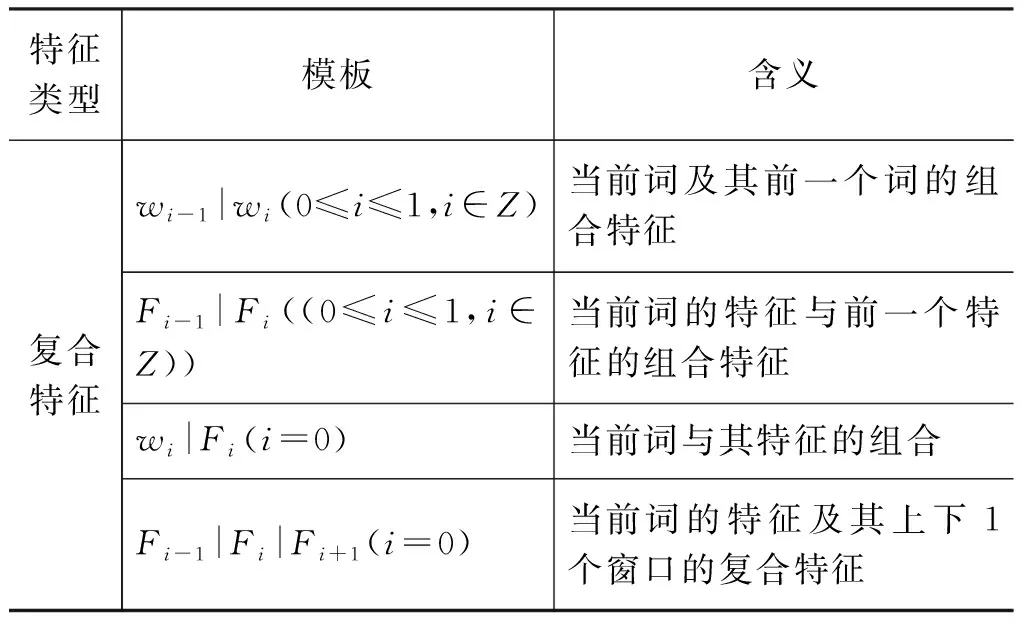
续表
3 实验与结果分析
3.1 数据源
在无监督学习方法中,本文使用新疆多语种信息技术实验室自然语言处理组搜集的四百万句以上的单语语料(词空间大小为1 309 109),主要来自政府网站新闻以及天山网。利用该组的维吾尔语自然语言处理工具包(网络服务)[注]http: //202.201.255.248: 8088/xjuapi/uyghurtext/,首先对文本进行扩展区向基本区的转换,然后对数据集进行词例化、分句、分音节等一系列处理。
在有监督学习方法中,训练集和测试集使用的语料是新疆多语种信息技术实验室自然语言处理组搜集的汉维平行新闻语料。首先,针对汉语语料利用哈工大自然语言处理pyltp工具[注]https: //pypi.python.org/pypi/pyltp筛选出包含命名实体的句子。然后,获取对应的维吾尔语句子并组织人员进行标注。其中,该语料的每个token使用BIO的标记信息。本文采用交叉验证将标记语料按照比例5∶1分为训练集、测试集,有关数据集的信息见表2和表3。其中,NE表示命名实体,OOV表示测试集不在训练集的实体,Roov表示OOV的比例。

表2 维吾尔语命名实体识别数据集的统计信息
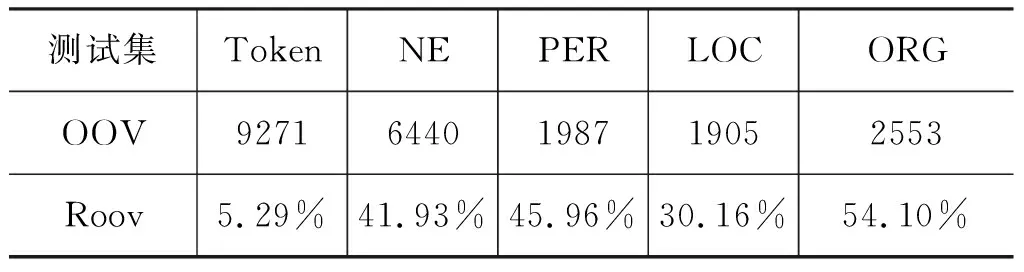
表3 测试集OOV统计信息
3.2 评测指标
本文将F值(F1)作为评测指标以客观地衡量命名实体识别效果并且选用conlleval脚本来计算。
3.3 实验设置与结果分析
2.2节中提出了三类特征可能会对识别起到一定的作用。为了进一步验证每类特征对维吾尔文命名实体识别的影响大小,先按照不同类别(词法、词典、无监督)分别选取不同特征组合进行实验对比,寻找每类特征的最佳特征组合。再将三类特征有机结合进行实验对比,确定最佳的识别结果。
3.3.1 不同的词法特征组合的对比实验
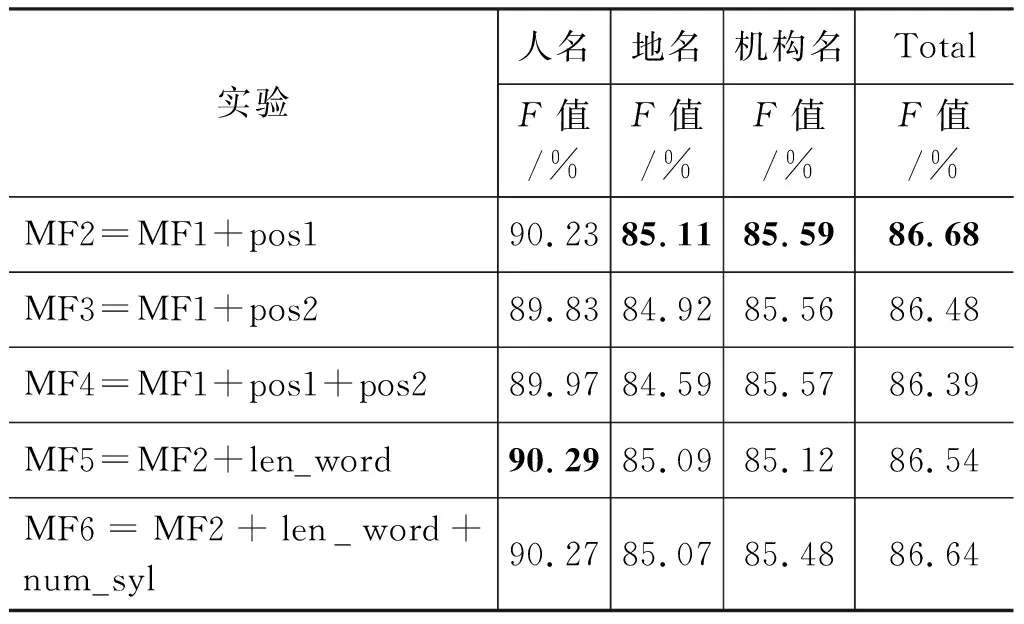
为了判断不同的词法特征(MF)对维吾尔文命名实体的影响,首先引入基本的语言特征(word)。然后,在此基础上逐渐加上前音节(syl1)和后音节(syl2)、一级词性(pos1)、二级词性(pos2)以及词长(len_word)和单词音节个数(num_syl)。表4是不同词法特征组合的实验情况。从表中可看出,相比于基线实验,前音节和后音节对识别效果影响较大,总体的F值提升了6.24%;而在此基础上,分别引入一级词性、二级词性以及两级词性,发现一级词性的贡献稍大,而二级词性的贡献较低,可能是二级词性的自动标注正确率较低所致;然后,依次加入词长、音节个数,发现总体对识别效果作用不大,而对人名的识别有微微上升的趋势,可以忽略不计。
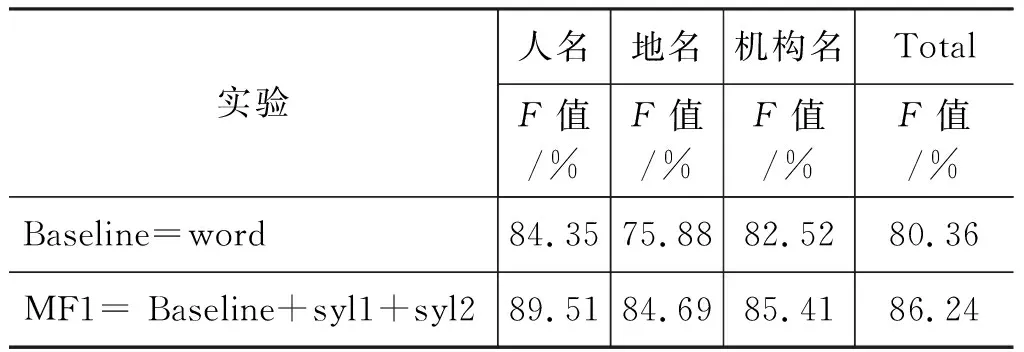
表4 不同的词法特征组合的对比实验(MF)
续表
3.3.2 不同的词典特征组合的对比实验
词典主要包括共有词典(MD)、地名词典(LD)、机构名词典(OD)、人名词典(PD)等。为了对比不同的词典特征组合(DF)对实体识别的贡献,本文首先在共有词典的词典特征上进行实验,然后分别引入其他类别词典特征以及组合。不同词典特征的实验如表5所示。可看出共有词典的词典特征相对于基线实验,在人名、地名、机构名的识别效果的F值均有上升。分别提高了2.1%、3.29%、0.35%,由此说明共有词典的词典特征有效地提高了识别效果;随着加入不同的单类实体词典特征,发现其对应的单类实体识别效果都有明显的提升,人名、地名、机构名的F值在共有词典基础上分别提高1.24%、2.97%、0.75%;然后将单类实体的词典特征进行融合,发现全部词典特征在命名实体识别效果上影响最大,F值已达到84.63%。

表5 不同的词典特征组合的对比实验(DF)
3.3.3 无监督学习特征组合的对比实验
为了对比两种模型的不同,本文在三种无监督学习特征中针对两种模型分别进行了实验分析。
(1) 不同维度的二值化向量对比实验
词向量中的每一维向量值都表示着词的一个潜在语义特征,维度的大小严重影响着识别效果。在2.2.3中可知,二值化向量是由不同维度的词向量转换而来的离散值。因此,需要对不同维度进行实验,如图 2所示。从词向量维度的角度上看,不同模型的F值随着维度的增长并未呈现上升趋势。然而,两种模型的二值化向量都在50维时,识别性能最好;从模型的角度来看,Skip-gram模型在人名和地名实体上识别效果较好。CBOW模型的维度为50维时,在机构名识别上效果较为明显。而在100维和200维时,几乎和Skip-gram持平。因此,本文选用50维的向量的基础上,进行其他的无监督实验。
(2) 不同K-means聚类个数的对比实验
聚类个数会严重影响识别性能。本文根据获得的50维向量分别对聚类个数128、256、……、4 096、8 192等进行K-means聚类,如图3所示。从整体的识别上看,当聚类个数在3 072时,效果最佳;从单类实体识别上看,当聚类个数大于2 048时两种模型均达到较高的F值。其中,CBOW模型在人名、地名、机构名的最佳识别结果对应的聚类个数分别为2 560(F值88.49%)、3 072(F值82.51%)、2 560(F值84.89%), Skip-gram模型在人名、地名、机构名的最佳识别结果对应的聚类个数分别为3 200(F值90.09%)、2 048(F值84.39%)、3 072(F值85.56%);从模型上看,Skip-gram模型的聚类效果优于CBOW模型。 故在本文的后续实验中,选用Skip-gram模型的聚类结果且聚类个数为3 072。

图2 不同维度的二值化向量对比实验
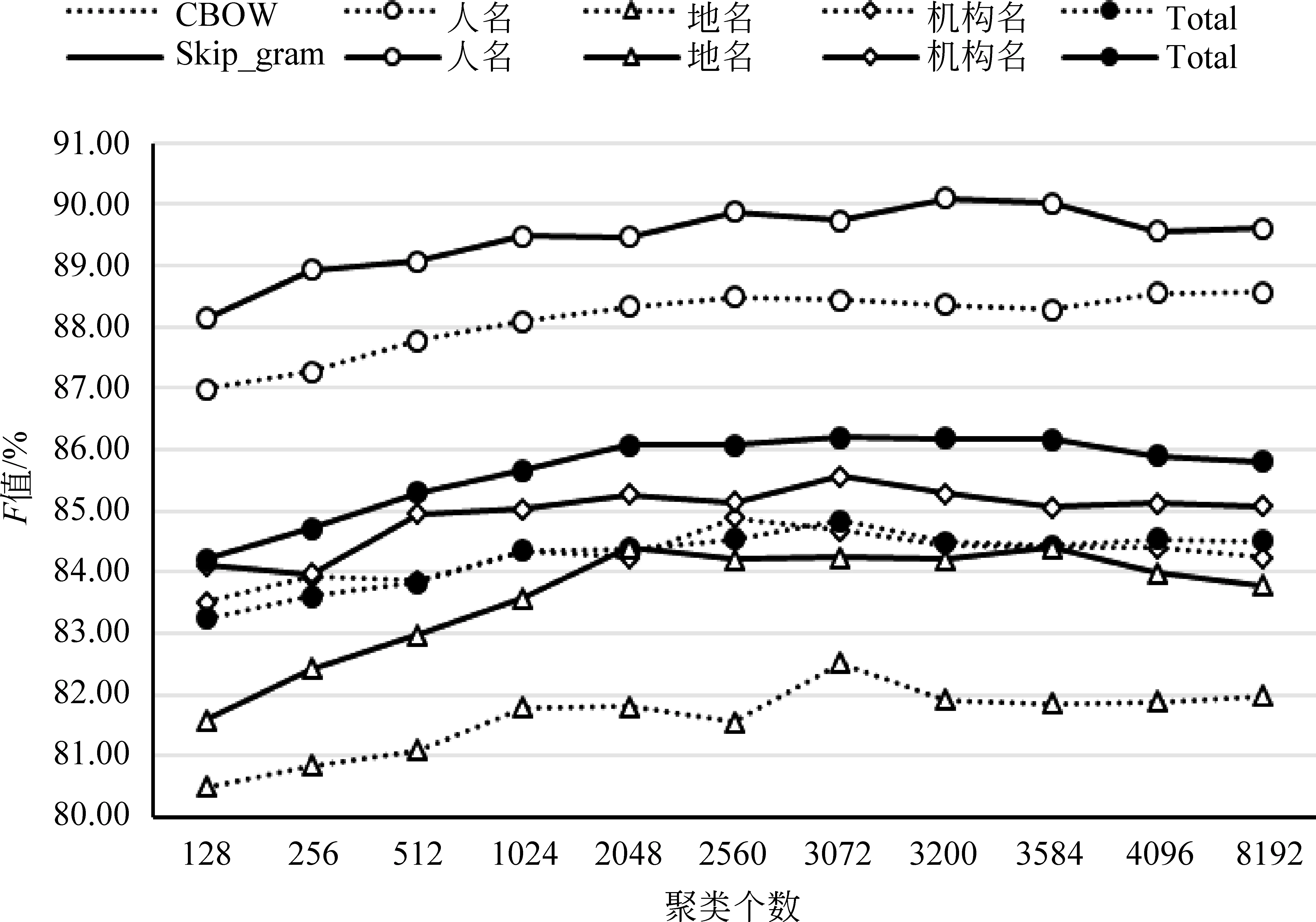
图3 不同K-means聚类个数的对比实验
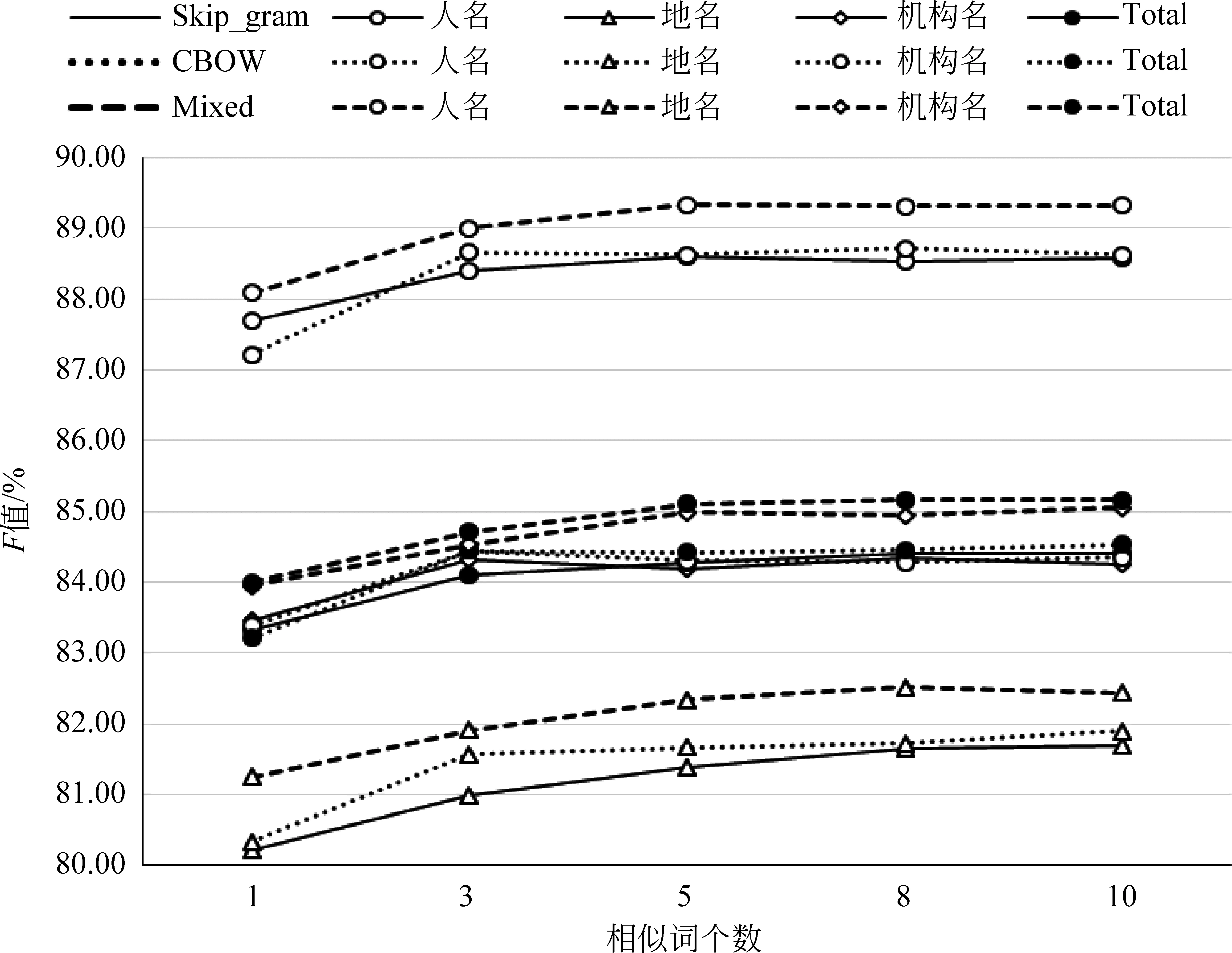
图4 不同相似词个数的对比实验
(3) 不同相似词个数的对比实验
依照2.2.3中所述的相似词特征分别对不同模型的相似词个数为1、3、5、8、10进行实验,结果如图4所示。三种方法在相似词个数大于5时,命名实体识别效果都趋于平稳状态。其中,在人名识别上,相似词为5时,结果较好;在地名识别上,相似词为8时,效果较佳;在机构名识别上,相似词为5时,效果较佳。三种方法相对比,发现两种模型的相结合(Mixed)的方法无论在哪类实体上,识别效果都优于CBOW模型以及Skip-gram模型。并且,Mixed方法在相似词个数为8和10时在整体的命名实体识别上效果最佳,其F值为85.16%。
(4) 不同的无监督学习特征组合的对比实验
为了客观地评价三种无监督学习方法对命名实体识别性能,本文研究并比较了在单个特征、组合特征情况下的命名实体识别性能。实验结果如表6所示,可以看出,无论引入哪种的无监督学习特征,在Baseline的基础上都有所提高;仅引入K-means聚类特征的性能明显优于引入其他两种特征,同时,聚类和相似词的结合,可以获得最好的识别性能,可见在实体识别中引入K-means聚类特征的优势。
3.3.4 混合特征组合对命名实体识别性能的影响
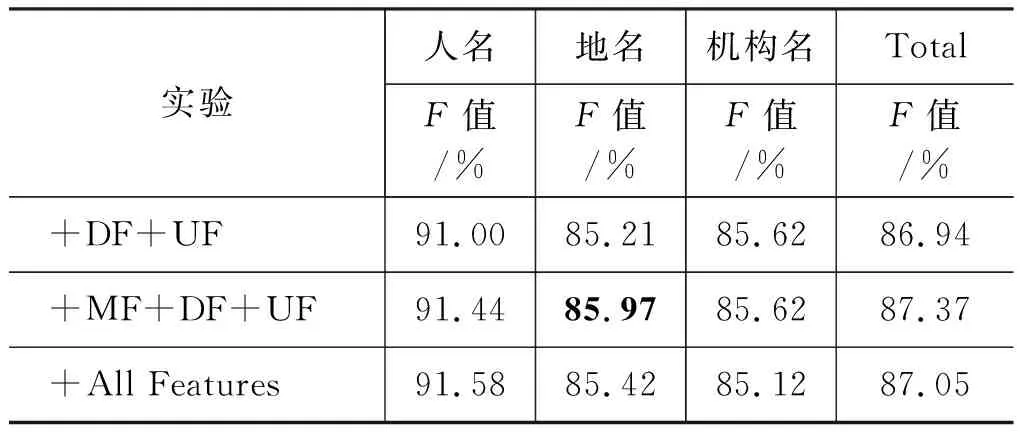
在上述实验的基础上,对融合多类特征的维吾尔文命名实体识别进行探究,其不同的识别结果如表7所示。
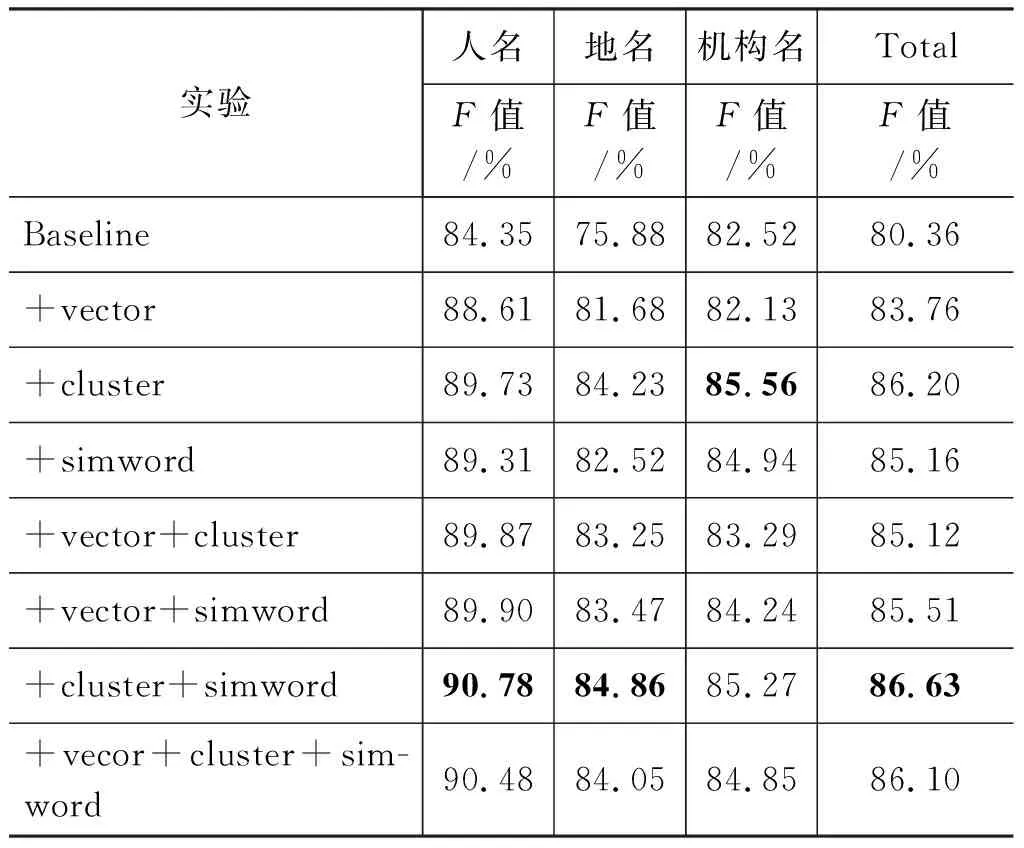
表6 不同的无监督学习特征组合的对比实验(UF)

表7 混合特征组合的对比实验
续表
注: MF、DF、UF分别表示上述三种实验中最佳的特征组合。
从表中可看出各类特征在Baseline的基础上都有大幅度的提高。其中,词法特征较高,无监督学习特征几乎达到了和词法特征相当的水平。相比于分析维吾尔语形态结构和命名实体结构的方法,本文模型减少大量的工作量;将三类特征(选择上述实验中每类特征的最佳特征组合)分别组合,当三类特征相结合时,F值达到87.37%。而词法特征和无监督学习特征结合时,F值达到了最高值87.43%。由此说明词法特征和无监督学习特征的有机结合,可以大大降低人工选取特征的代价。同时,提高维吾尔文的命名实体识别性能。
3.3.5 不同特征对OOV识别效果的对比实验
为了进一步对比不同特征,本文针对OOV的识别进行了对比实验,结果如表8所示。三类特征相比较时,词法特征的识别效果最佳,无监督学习特征识别效果优于词典特征。其中,词法特征在地名、机构名识别上较有优势,而无监督学习特征在人名识别上性能较好。在对三类特征进行组合分析时,发现所组合后的特征对OOV的识别能力更强。由此说明该特征组合在OOV的识别上具有一定的优势,但依据表7可看出,对非OOV的实体识别可能具有一定的副作用。
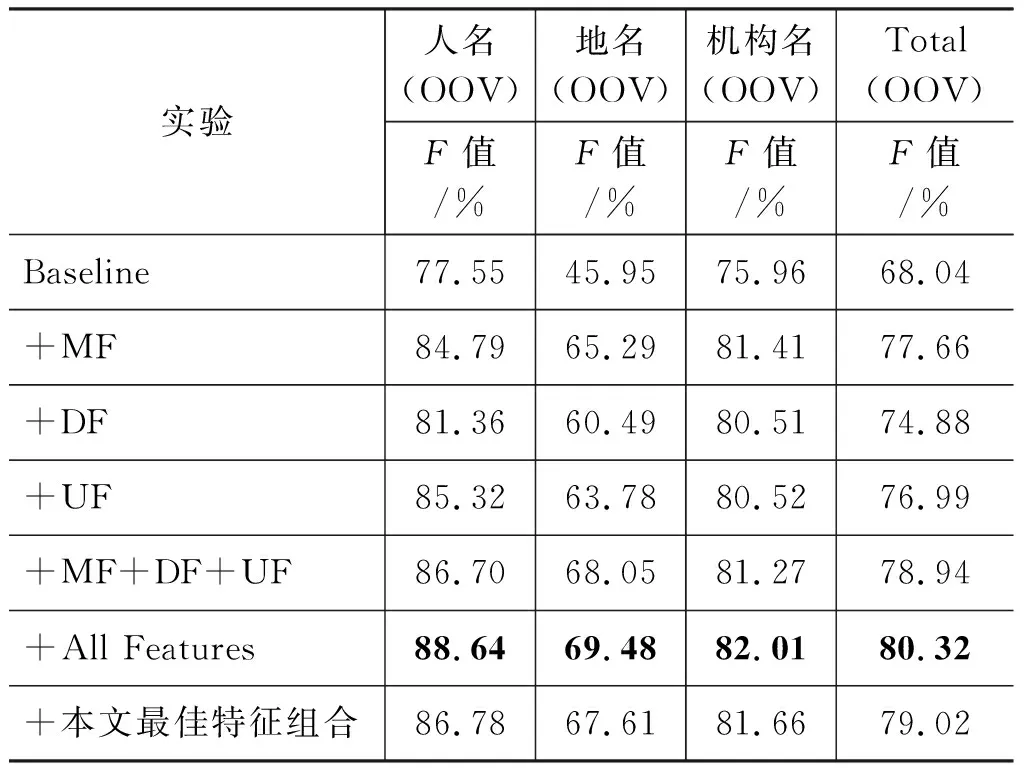
表8 不同类型特征命名实体识别结果对比
3.3.6 CRF模型与神经网络模型的对比实验
目前,深度学习方法已经广泛应用到自然语言处理任务中。本文利用Lample[17]提出的Bi-LSTM-CRF模型以50维的词向量作为基本的输入特征,并在此基础上加入最佳的特征组合(词法特征和无监督特征)。其中,两类特征维度都采用30维,如表9所示。从表中可以看出仅引入词向量时F值达到84.47;若引入上文中最佳的特征组合时,F值达到88.19,仅比上文中最佳的CRF模型上高出0.76%,说明两种模型F值相差不大。
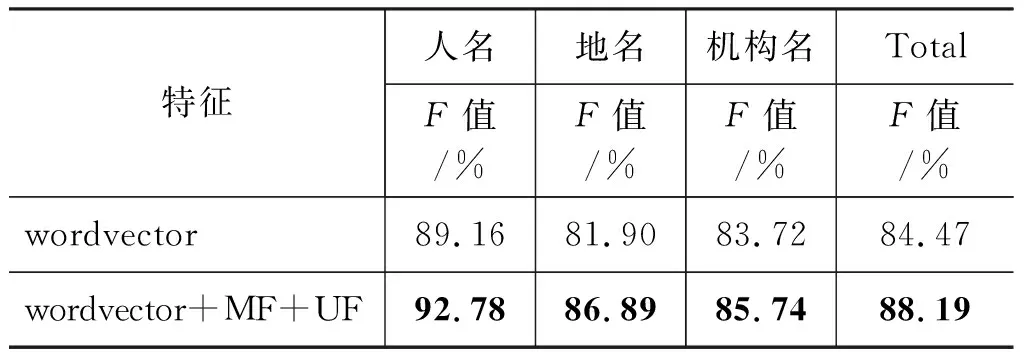
表9 基于Bi-LSTM-CRF模型的识别结果
为进一步验证哪种模型更适合用于命名实体识别实际应用中,本文在性能方面进行了对比,CRF模型、Bi-LSTM-CRF模型(迭代次数为50)分别在CPU、GPU的情况下进行训练与测试,具体如表10所示。从总体上看,CRF模型在性能明显优于Bi-LSTM-CRF模型;此外,GPU价格昂贵。因此,虽然CRF模型的准确率稍低,但更适合用于实际应用。
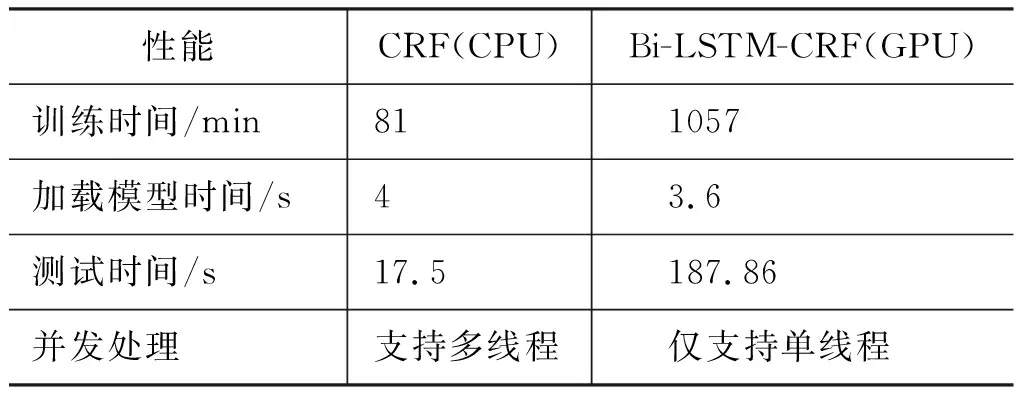
表10 不同模型的性能对比
4 结语
本文针对维吾尔语命名实体识别,利用大规模的未标注数据集,根据词向量获取不同的无监督学习特征。然后,采用CRF模型作为统计机器学习模型,选取词法特征、词典特征、无监督学习特征分别进行单独或者组合进行命名实体识别性能的对比实验。实验表明,三类特征在识别性能都有所提高,且CRF模型融合词法特征比词典特征、无监督学习特征识别效果更佳;无监督学习特征能够从大规模的未标注数据集中获取词的语义信息,并且相比于人工构建领域特征,无监督学习可以减少大量的工作量;引入词法特征和无监督学习特征,可以大大降低人工选取特征的代价,提高维吾尔文的命名实体识别性能;CRF模型相比于神经网络模型,更适合用于实际应用中。由此说明本文提出的方法在维吾尔语命名实体上取得了较好的识别效果。本文的研究尚不完善,进一步的研究工作拟开展自动特征选取算法实现最佳的特征组合。此外,在词向量的基础上开展更深入的神经网络机器学习方法,例如,引入字符向量、音节向量等。
