D-Reader: 一种以全文预测的阅读理解模型
2018-12-20赖郁婷曾俋颖林柏诚萧瑞辰邵志杰
赖郁婷,曾俋颖,林柏诚,萧瑞辰,邵志杰
(1. 台达电子股份有限公司 台达研究院,台湾 台北;2. 台达电子股份有限公司 知识管理部,台湾 台北)
0 引言
机器阅读理解是近年来自然语言处理的重点研究项目之一,我们相信当机器具备高水平的阅读理解能力时,将能大幅提升数据及知识检索的效率。近年来,多个机器阅读理解数据集的发布使得机器阅读理解的研究大幅增加,常见的任务形式包含填空题、选择题与简答题。其中,简答题最为接近实际的应用情境,相关的英文数据集有SQuAD[1]、MS MARCO[2],中文数据集则有DRCD[3]和DuReader[4]。
本文描述为了2018年举办的机器阅读理解技术竞赛所建构的模型,该竞赛采用DuReader数据集,其题型为简答题,每个问题提供最多五个文章段落,及人工整理的答案。本文基于经典模型BiDAF[5]进行数据分析与系统改良,提交机器阅读理解模型D-Reader。我们的方法加入了预训练的词向量,并组合多次训练的模型成为一个集成模型。也针对训练数据做了预处理及筛选,以确保训练数据质量,并对预测结果进行标点符号正规化与是非题分类处理,以提高答案分数。
本文结构如下,第1节介绍数据与预处理方法,第2节介绍本文使用的模型及实现细节,第3节介绍实验环境及实验结果,第4节为分析与讨论,第5节总结本文内容与发现。
1 数据
1.1 数据集描述
本文的实验数据采用的是2018年举办的机器阅读理解技术竞赛中公开的DuReader数据集,此数据集包含30万个问题,每个问题对应5个候选文档及人工整理的答案,所有的问题与内文都来自于真实的数据——百度搜索引擎数据和百度知道问答社群。
百度数据集可以从两个方面来分类: 问题类型与观点。第一类是问题类型,DuReader将问题类型分成Entity(实体)、Description(描述)和YesNo(是非)。实体类问题,其答案都是单一确定的回答或是一连串的字词,例如: “三国演义的作者有谁?”;对于描述类问题,其答案长度较长,是多个句子的总结,是一种典型的how/why的问题,例如: “如何在计算机安装Linux系统?”;对于是非类问题,其问题比较简单,通常回答是或否,比如: “怀孕可以吃姜黄吗?”
第二类是观点,即回答是事实(Fact)还是观点(Opinion),通过两个划分方法,DuReader的问题类型总共可以分成六类,如表1所示。

表1 DuReader问题类型

续表
1.2 数据预处理
数据预处理采用DuReader数据集提供的分词。另外,在数据集中,每一个问题匹配到多个参考答案。因此,我们对每一个参考答案皆取文档中最近似的区段,故一个问题会根据每一答案产生数笔训练数据。前述处理后,训练数据会比原先的30万笔还要多,预期扩充训练数据将会使准确率提升。参考答案与文章段落的相似度计算使用F1-score,计算预测答案与参考答案的平均重叠次数。
由于DuReader数据集的答案为人工产生,可能无法在文档中找到准确对应的句子,故滤除与标准答案之F1-score低于0.7的数据,以保持训练数据质量。同时,由于时间与设备的限制,本文并未使用完整资料,而是使用347 723个问题作为训练数据。
2 方法
本文的系统架构如图1所示。首先训练词向量,并基于词向量训练BiDAF模型,组合6个单一模型为一个集成模型,最后进行后处理,并对是非题的答案进行分类。下面将介绍各步骤的细节。

图1 模型架构
2.1 词向量
本文使用Joulin等于2016年提出的fastText[6]模型进行词向量训练。此模型基于Word2Vec[7],通过上下文的信息来训练词汇的语意表示,并同时考虑子词的信息,将词汇中N-gram的子词向量加总作为该词汇向量。此作法有别于过往,能获取未登录词之词向量。此外借助子词的信息,也能有效提升低频词的词向量质量。fastText的训练也相当快速,是当前的主流方法。
我们选用其中的Continuous Bag-of-Word (CBOW) 算法,其以中心词汇的前后文词汇来预测中心词汇,在优化语言模型的同时更新词向量。
2.2 BiDAF
Bi-Directional Attention Flow (BiDAF)[5]是由Minjoon Seo等发表于2017年的一个分层多阶段的训练网络。其引入不同级别的文章粒度,包含字符级及词级,对段落上下文进行模型的训练。并计算问题到内文与内文到问题之间两种关注(Attentions),来获得query-aware的特征向量,最后使用双向LSTM[8]进行语义信息的聚合,得到答案的开始位置以及结束位置为预测结果。
BiDAF网络包含六层:
①CharacterEmbeddingLayer: 使用CNN将问句和内文的每个字符映像到一个多维向量空间。
②WordEmbeddingLayer: 将问句和内文的每个词映射到一个300维的向量空间,使用的是前面提到的预先训练好的fastText的CBOW词向量模型。 双层 Highway Network会形成两个一维矩阵,包含内文的矩阵X和问句的矩阵Q。
③ContextualEmbeddingLayer: 将X和Q向量分别输入一个双向的长期短期记忆网络(LSTM)[12],并连接双向LSTM的输出,捕捉X和Q各自的特征来优化向量。此层输出为两个二维的矩阵,内文的矩阵H和问句矩阵U。
④AttentionFlowLayer: 将向量H和向量U链接,做 context-to-query 以及 query-to-context 两个方向的关注 (Attention),输出为内文中的每个单词的查询感知特征向量(query-aware vector),以及前一层传过来的内文与问句向量。双向关注做法是,先计算矩阵的相似性,利用内文和问句的相似度矩阵S∈RT*J,相似度计算方法如式(1)所示。
Stj=α(H:t,U:j)∈R
(1)
其中,
(2)
Stj表内文的第t个字和问句的第j个字的相似度,α是一个可训练的scalar function,H:t为H的第t列向量,U:j为U的第j列向量,w是一个可训练的权重向量,⊙为逐元素的乘积,“;”表示在向量上做拼接,计算后得到双向的关注向量S。

(3)
at=softmax(St:)∈RJ
其中,at表示第t个内文的词对问句的词的关注权重。
2)Query-to-contextAttention(Q2C): 计算对每一个内文的词而言,哪些问句词与它最相关,当作为此问句的关键回答。取得相似性矩阵每列的最大值,并做softmax得到关注权重b,即:
b=softmax(maxcol(S))∈RT
(4)
归一化计算关注的内文向量。
(5)

(6)
其中,G:t表第t个列向量,对应于第t个内文的词,β为一个任意可训练的向量函数,dG是β的输出维度。β采用的方法是如上面α所述的拼接方式。
(7)
⑤ModelingLayer: 建模层的输入为G,对G做编码,经过双向LSTM后得到M∈R2d×T,M的每个列向量包含关于整个内文段落和问句的词的交互信息。
⑥OutputLayer: 使用上一层的M做分类得到内文每个位置为起始位置的机率p1,然后将M输入双向LSTM得到M2,再将M2分类得到结束位置的机率p2。
训练: 其中W是一个可训练的权重向量,定义训练损失函数为真实答案的开始和结束的负对数概率总和,并对所有例子取平均值。
(9)
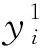
本文以Wei He[4]等人实现的BiDAF作为基线系统。在该程序代码中,在训练与测试阶段,对每篇文章挑选出最具代表性的一个段落,以改良效能。其挑选的方法为,在训练阶段,比较答案与段落的recall。而在测试阶段,因答案不可取得,则是与问题进行比较。然而,我们发现在测试阶段若以段落与问题的recall来筛选,将会导致许多正确答案所在的段落落选,反而选择复诵问题但无内容的段落。另外也发现,有部分文章被切割为数个段落,若只取一个段落,将取到不完整的文章。因此,为了提升召回率,我们将文章段落以句号串接起来,以整篇来预测答案。
2.3 集成模型
本节将6个BiDAF单一模型的开始与结束位置的机率取平均值,再计算机率乘积最大的区间作为答案,如果候选答案区间为空或为单一句号,则视为无效答案,将跳过并取下一个答案直至找到有效答案。
2.4 后处理
由于在2.2节中以句号串接段落文章,在此处将清除多余的标点符号和移除换行符号“ ”和“ ”,并于句尾补上句号,使答案句更加完整。
2.5 是非题答案分类
因MRC 2018主办方规范的评价指标,增加了对正确识别是非题答案类别的得分奖励。故我们对BiDAF模型预测过后的是非题结果进行分类。是非题答案共有四个类别: Yes、No、Depends和No_Opinions。
本文的分类模型基于LSTM设计了两种不同的模型架构: Attention Text Classifier和Deep Text Modeling Classifier,前者采用注意力机制,后者采用相似度机制。因两种模型侧重的特征不同,该分类模型采用集成的方式组合两者,以提升模型的泛化能力。
两个分类模型都采用相同的预处理动作,先对问题与答案进行分词,使用清华大学推出的中文词法分析工具包THULAC[9],其在简体中文分词中具有准确率高及效能佳的特点。
2.5.1 Attention Text Classifier
此模型分成五个部分: Embedding Layer、Bi-LSTML Layer、Attention Layer、Merge Layer与Softmax Layer。模型的架构如图2所示。

图2 Attention Text Classifier模型
①EmbeddingLayer: 使用fastText,以DuReader的数据集训练一个300维词向量模型。
②BiLSTMLayer: 利用LSTM模型累加的线性形式,处理序列数据的信息,避免梯度消失的问题也能学习长周期的信息。将Question和Answer分开表示,透过双向LSTM结合上下文信息,分别学习Question和Answer的表示向量,分别将两个表示向量传递给后面。
③AttentionLayer: 透过注意力(Attention)机制,增强关联性较强的词权重并降低关联性较低的词权重,将Question和Answer的表示向量,采用点积(Dot)方式进行计算,产生答案对于问题的注意力(Attention)的表示向量。
④MergeLayer: 保留问题的信息并加入特定词汇的权重,把Attention及Question的表示向量进行加总运算,将结果传递给后面。
⑤FeedforwardLayer: 使用Softmax回归模型,针对Merge Layer传递过来的信息进行学习,计算待分类数据归属于各个类别的机率,Softmax 回归模型是Logistic 回归模型的一种形式,拥有良好的数学特性。
模型的参数设定为: 采用Adam 算法进行优化、词向量维度为300,batch size设定为256,LSTM units设定为128,Hidden Layer Number设定为1,dropout rate设定为0.3。
此模型在开发集的正确率可达72.71%。
2.5.2 Deep Text Modeling Classifier
此模型参考Basant Agarwal[10]等人提出的分类模型修改而成,分为五个部分,依序为Embedding layer, CNN layer, RNN layer, Interaction layer, Feed forward layer,模型的架构如图3所示。

图3 Deep Text Modeling Classifier模型
①Embeddinglayer: 使用Word2Vec,以DuReader的数据集训练一个300维词向量模型。
②CNNlayer: CNN通过不同大小的filter撷取重要的特征,对于抽取局部特征有优异的表现。使用不同长度的filter同步进行卷积,视为不同长度的N元组语意信息,最后通过Max pooling将卷积后的重要信息撷取出来。
③RNNlayer: 上述CNN的输出除了将重要信息撷取出来外,同时也保留文字的顺序关系,因此将之作为LSTM的输入,将序列数据基于文字顺序迭加以获取文字语意信息。两个输入字符串分别经过CNN, RNN layer后相减,此方法可视为句对间语意的差异信息。
④Interactionlayer: 将句对的词向量作内积,内积可作为向量在另一向量的投影,因此通过词向量的内积了解句对间词汇的相似程度,视之为相似矩阵Similarity Matrix,最后将结果经过CNN的特征撷取来表示句对间重要的语意信息。
⑤Feedforwardlayer: 将前述方法所得之结果串联后通过Feed forward layer,通过Softmax来仿真各标签的机率,采用Cross Entropy作为损失函数,最后通过Adam进行参数更新。
3 实验
3.1 系统运行的环境及硬件条件
本节实验以Wei He[4]等人实现的BiDAF为基线,进一步组合我们提出的改良方法。实验中BiDAF模型的超参数设置如下: batch_size设为64, dropout_keep_prob 设为1, embed_size设为300, epochs 次数为2, hidden_size为 150, learning_rate为0.001, max_a_len设定为250, max_p_len设定为500, max_p_num设定为5, max_q_len设定为60。
实验环境为: CPU Intel Core E5-2698; GPU NVIDIA DGX-1 搭载 Tesla V100; 显存128GB; 操作系统为64 位元Ubuntu 16.04 LTS。
3.2 实验结果
实验以MRC 2018主办方规范的ROUGE-L[11]及BLUE-4[12]作为评价指标,并以ROUGE-L为主要参考指标。主办方适当增加了正确识别是非题的答案类型及匹配实体的得分奖励,以弥补传统ROUGE-L和BLEU-4指标对是非题和实体类型问题评价不敏感的问题。
3.2.1 后处理实验
本节比较答案后处理,包含是非题答案分类及标点正规化的效果,具体说明及参数设置见节2.4与2.5,实验结果如表2所示。加入了Yes/No标签(cls)后使ROUGE-L提高了0.42%,BLEU-4提升0.35%。标点正规化(norm)则使ROUGE-L再提高了0.16%,BLEU-4的提升则更为显著,有0.56%,这可能是源于BLEU-4在短答案上的波动较大的特性。在本节后续的实验中,都会加上cls+norm的后处理。
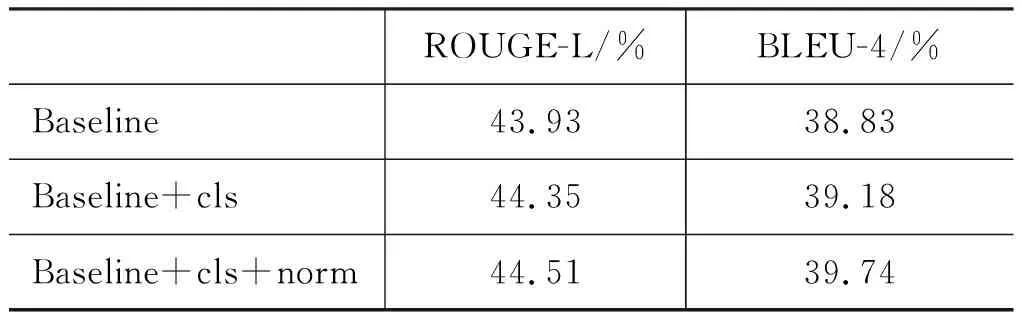
表2 后处理实验数据
3.2.2 词向量比较
基于上一节最佳的后处理设置,我们进一步实验不同的词向量。训练语料使用DuReader的全部分词文本。算法为CBOW,模型窗口设定为3,维度设定为300,学习速率设定为0.5,训练5轮。N-gram的最大值设定为2,最长子词则设定为4字符,最小为1字符。损失函数选用hs。
结果如表3所示,可以看出使用fastText算法预训练词向量较随机词向量效果有显著提升,ROUGE-L提高了3.93%,BLEU-4提高了2.57%。

表3 词向量实验数据
3.2.3 预测方式比较
基线系统为了提升效能,以先挑选文章中最具相关的段落来加速预测。而我们使用以句号串接的完整数据来预测,实验结果见表4,在ROUGE-L上提高了7.23%,BLEU-4提高了6.75%,进步非常显著,可见基线系统以问题与段落相似度来代表其相关度的假设并不合理。这也是本文模型分数大幅提升的关键,虽然会使预测阶段的运算时间拉长,但通过平行处理,运算时间约两小时,并不至于太慢。

表4 预测方法实验数据
3.2.4 集成模型
表5是不同集成模型的实验结果,此实验中的每个单一模型所使用的参数设置皆相同。从实验数据可看出,集成模型确实能优化结果,并且表现比单一模型稳定,由7个模型的集成在ROUGE-L上较单一模型提高了0.96%,可推测越多的集成模型表现越佳。此实验中的模型以相同权重集成,我们认为线性加权应可再提升结果。
表5也针对不同前处理的训练数据进行实验,“标准数据”指的是原始训练数据集,经筛选后有242 132个问题。“扩充数据”则是在1.2节重新预处理过所得之数据,共有347 723个问题。
因上传次数限制,没有足够数据进行同基准的比较,但可看出扩充数据在ROUGE-L上有显著提升效果,但其BLEU-4下降。我们推测,扩充数据也可能混淆训练方向,会有同一个题目却对应到不同的答案的矛盾情形。又因时间关系,扩充的数据并不完整,这也可能是导致分数下降的原因之一。

表5 集成模型实验数据
4 分析与讨论
由于该数据集答案为人工产生,以区段的方式难以表示结果,因为答案可能摘要自原段落的不同位置。在实体类问题中尤为明显(表6)。我们认为也许可以尝试生成式模型,或是将多个答案进行合并。

表6 摘要式答案之范例
预测答案时,我们使用以句号串接的方式预测完整数据。这个做法虽能一定程度上提高命中率及改善段落被错误切割的情形,但在段落很短时,很大机率会取到跨段落的答案。表7中,框起来的句号为串接处,问题1串接了数个段落的答案,使其更完整,但问题2却因为串接了两个独立答案,计分受到长度惩罚。
此外,可以观察到被误切为数段的多为列点或步骤描述,也许可以此为线索合并段落,将有类似格式的内文在预处理时串接起来,以修正数据。至于预测时则可改用特殊符号为分隔符,降低预测到跨文章结果的机率。

表7 串接段落对答案的影响之范例
最后,DuReader数据集中三种问题类型的特性迥异,我们认为应对三种类型分别训练。最初虽曾尝试训练个别模型,但性能变差,推测原因是数据量下降,故未继续研究这个方向。但也许可以尝试多任务学习,通过共享信息来放大数据,降低拆开训练的不利影响。
5 结论
机器阅读理解是近年来自然语言处理的研究重点,随着更多中文阅读理解数据集的发布,中文阅读理解的技术将能更好地发展。本文为DuReader数据集设计一基于BiDAF的阅读理解系统。除改良数据前处理及使用fastText预训练词向量,亦发现基线系统为简化运算而以问题与段落之相似度筛选文本的假设并不合理,故改用全文预测,获得大幅度的性能提高,为本文系统分数提高的主因。本文亦以集成学习降低单一模型的偏差,使模型效果更佳,也更稳定,有效地提升正确率。并使用两种分类模型,分别基于注意力与相似性,对是非题答案进行分类。
本文实现的方法在MRC 2018的评比中得到了ROUGE-L 56.57%与 BLEU-4 48.03%的结果,说明该方法是可行且有效的。
本文研究也存在不足之处,首先,由于时间与设备限制,资料扩展并没有完整完成。对于预测时的段落串接,虽然大幅改善结果,但也造成一些多抓的情况,应可再尝试其他的处理方式。另外,未能针对各问题类型及不同资料来源进行实验,也是可惜之处,我们认为DuReader的三种问题类型各有不同特性,这可以是今后继续研究的方向。
