基于Tree-based CNN的关系抽取
2018-12-20陈鸿昶黄瑞阳
刘 伟,陈鸿昶,黄瑞阳
(国家数字交换系统工程研究中心,河南 郑州 450000)
0 引言
随着深度学习在人工智能领域取得突破性的进展,科技工作者们越来越相信以数据为驱动的方法能够在智能化研究的道路上大展鸿图。文本作为信息量最密集的数据形态之一,其优秀的处理方法也越来越受到重视。深度学习的方法自被引入到自然语言处理任务中来,在本领域的多项任务中均取得了相当可观的效果。特别是做实体关系抽取任务时,在引入了CNN和LSTM后,关系抽取效果有了明显提升。采用深度学习的方法相比传统方法有明显的不同: 传统方法更加注重分析语句和句法的结构,从而对关系进行判断分类,而基于深度学习的方法则更加注重词义及其表示。本文尝试通过在神经网络架构中引入句法递归结构,使得句法结构信息更有效地参与到关系抽取任务中,从而提高抽取效果。
实体(Entity),即真实世界存在的特定的事实信息。关系抽取(Relation Extraction,RE),是通过计算机手段自动寻找文本中所描述的特定的实体关系。例如,“吴恩达成为百度首席科学家”中就包含一个雇佣关系,可以用三元组(吴恩达,雇员,百度)表示,也可以根据需求将关系更加具体化,用三元组(吴恩达,首席科学家,百度)表示。
当前实体关系抽取的主流系统一般采用有监督的学习方法。这类方法往往需要大量的人工标注数据,而人工标注数据的获得往往需要消耗大量的人力物力资源。2007年Auer等建立了DBpedia[1],Suchanek等建立了YAGO[2],2008年Bollacker等建立了Freebase[3]等语义数据集,被广泛应用在自然语言处理的各项任务中。尽管这些数据集中包含了大量的关系实例,但对于同一关系实例的数据往往不足以训练成熟的关系模型。2009年,Mintz等提出了远程监督的关系抽取算法[4],能够自动关联远程数据库中相应的训练数据。该算法假设如果两个实体E1、E2存在特定关系R,那么关系R将在所有包含实体E1、E2的文本材料中体现。这个假设在很多情况下是成立的,但并不绝对。例如,“吴恩达表示,现在全世界范围内,百度在使用超级计算机发展人工智能的公司中是最优秀的”。这句话中虽然也同样包含“吴恩达”、“百度”两个实体,但并不能体现“雇员”这层关系,不过该模型仍然会将其标注为该关系的支持语料。针对上述错误标注问题,2010年Riedel等[5]、2011年Hoffman等[6]、2012年Surdeanu等[7]基于自然语言处理的相关工具提出了多示例学习的方法及改进方法。
近年来,深度学习方法被应用到关系抽取的工作中。2012年Socher等在句子级的人工标注数据上搭建了深度神经网络分类器[8],但由于数据不易获得因而难以应用在大规模数据集上。因此,2015年Zeng等[9]将远程监督数据的思想应用到神经网络的训练中,取得了突破性进展。这种方法假设在包含两个实体的所有语句中,至少有一个语句可以表达它们之间的关系。然后,选择最能表达该关系的语句进行训练和预测。这个过程可以有效地排除那些对关系表达毫无作用的语句,但同时也放弃了可能包含重要信息的语句。为了能够抗干扰,同时更充分地利用有效语句,2016年Lin等[10]将注意力模型与CNN结合来处理关系抽取任务。这种方法可以将选出的几个有用关系的语句信息进行加权组合,提炼出对于关系抽取更准确的信息,有效地提高了关系抽取的准确率。由于该方法在语句编码阶段仍然对句法信息表达不足,故本文设计了一种基于句法树的CNN网络,来提高对句法信息的利用。
本文主要工作是在句子级的水平上基于注意力机制的远程关系抽取中的注意力模型进行了优化。如图1所示,本文利用CNN方法构建句子的语义信息。为了更准确地构建注意力机制模型,通过两层相关性分析将语义信息投影在抽取关系上,又通过利用来自《纽约时报》的实际数据对模型进行训练和测试。实验表明,本文所提出的方法可以有效提升关系抽取的效果及运算效率。
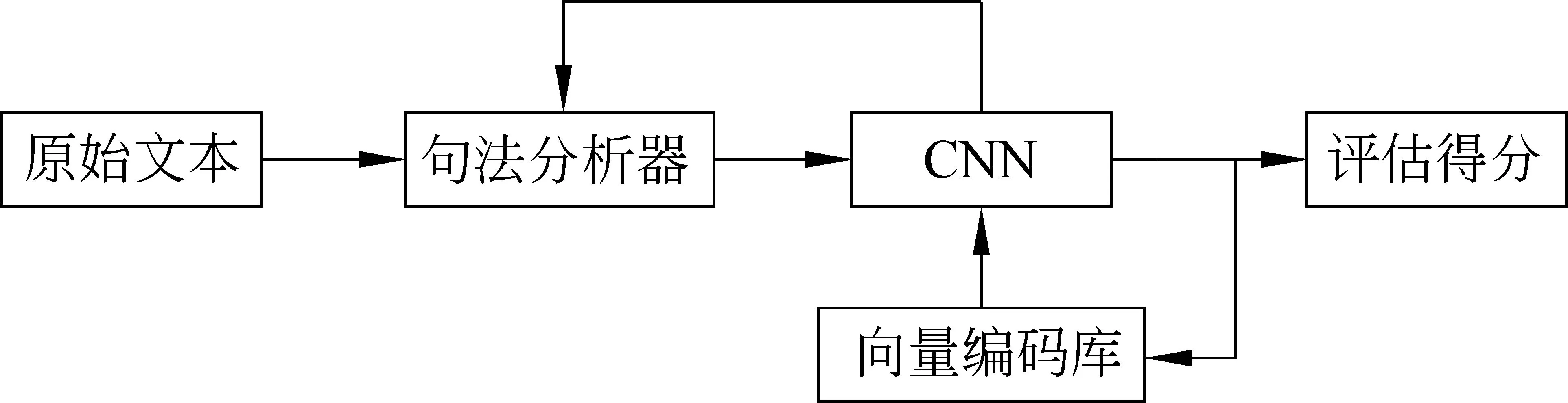
图1 算法结构框图
1 相关研究
关系抽取是自然语言处理领域最重要的任务之一。 远程监督关系抽取由于其基于远程数据库关联的特点,是近年来热门的研究方法。但是远程监督关系抽取常常伴随着错误标注的问题。为了解决这个问题,科研人员做出了不懈地努力。2010年Riedel等提出了解决多示例单标签问题的远程监督模型[5];随后,Hoffmann[6]和Surdeanu[7]等在多示例多标签远程监督模型上提出了各自的方法。
自2009年以来,深度学习已经在包括计算机视觉、语音识别等领域取得了突破性的进展,在自然语处理领域也是如此。2013年Socher等的句法分析是深度学习在自然语言处理领域的成功应用。深度学习应用在关系抽取工作中是从Schoer等将句法分析树结点表示为向量开始的。Zeng等在2014年将端对端卷积神经网络应用到关系抽取中[9],Lin等在2016年将注意力模型应用在卷积神经网络之上,提高了关系抽取的准确率[10]。
但是,难以获得充足的人工标注训练数据,一直是关系抽取任务的困难之一。因而2015年Zeng等尝试用远程监督数据训练了多示例关系抽取的神经网络模型[9]。但是该模型假定只有一条语句可以表达实体对所对应的关系,大量有用信息被应用丢失。2016年Lin等利用注意力模型对其进行了改进,以充分利用所有语料信息。该模型认为通过这种方法可以充分利用所有的语料信息,从而有效地进行关系抽取[10]。在远程监督关系抽取时无法避免地会引入各种各样的噪声,注意力模型具有一定的抗噪声能力,我们希望能够提高这种能力。并且,我们希望将更多的信息应用到关系抽取中,除了语料本身的信息之外,其语言环境、社会环境信息是不可以忽略的,我们尝试将这部分信息应用到关系抽取中。
2014年,Mou等[11]使用树形结构的卷积神经网络(Convolutional Neural Network,CNN)对程序语言进行了分析处理,取得了很好的效果。但程序语言有严格固定且相对简单的语法结构,因而并不能直接应用在自然语言上。2016年,Dligach等[12]使用CNN和LSTM在病例语料上尝试了短时关系抽取,发现CNN可以取得更好的效果。我们希望在此基础上更进一步,通过对自然语言的时态等进行预处理后,在自然语言的句法树上建立可控深度的CNN迭代模型,并将其和一般CNN和LSTM进行比较,取得了良好效果。
2 算法模型
给定包含指定实体对(e1,e2)的语句s及关系集Re={r1,r2,…,rm-1,NA},其中NA表示没有关系或其它关系。本文所提出模型最终将给出(e1,e2)在语句s中存在关系r的概率P(ri)=Pe1,e2(ri|s),其中1≤i≤m,rm=NA,ri∈Re。模型主要由以下两个部分组成。
(1) 语句编码: 给定标出目标实体对(e1,e2)的原始文本语句s,模型利用基于树形结构的卷积神经网络(Tree-Based CNN)将文本语句s表达为与(e1,e2)相关的分布式向量s,该过程记为s=Encoder(s)。
(2) 注意力机制: 利用已经表示好的句向量进行自适应加权,与关系向量进行匹配。
2.1 Tree-based CNN语句编码
如图2所示,在对文本语句进行向量编码时,我们将CNN在句法树上进行逐级应用。即每级CNN只对语句中的一部分短语进行编码,然后再将短语的编码代入到CNN中,按照句法树对语句进行逐级编码,直到整个语句被编码为一个单一的向量为止。
对于每一层短句的编码方法则如图3所示,我们利用前级输出的向量(或词向量)及该向量在本短语中的相对位置表示向量作为输入,然后采用一层卷积神经网络对其进行编码,经过卷积层、最大池层及非线性层,最终得到该短语的向量表示。

图3 短句编码示意图
2.1.1 输入向量表示
对于每个词或短语,我们通过向量库查询的方法找到其对应的向量表示,同时在其基础上嵌入位置表示。每个词的表示向量由两部分嵌入组成: 词义嵌入和位置嵌入。词义嵌入是为了捕捉词的词义信息,位置嵌入的作用是捕捉词相对实体的位置信息。
(1) 词义嵌入: 若查询矩阵为Q,Q∈Rlw×|V|,其中lw表示词义嵌入的长度,V表示所有词的集合,则每个词的词义嵌入可以通过该矩阵进行编码。在图3中,词义嵌入对应词表示的word embedding部分。
(2) 位置嵌入: 为了跟踪词与目标实体的位置关系,词的位置信息需要嵌入到词的表示中去。若位置嵌入函数为pe(·),则对于相对两实体位置分别为p1,p2,位置嵌入表示为pe(p1,p2)。其嵌入编码只与词与目标实体的相对位置有关。在图3中位置嵌入对应词表示的position embedding部分。
这种词表示的方法在实体关系抽取任务中可以有效地同时捕捉词的词义信息和位置信息。该方法2014年曾被Zeng使用[9],2016年被YanKai Lin延用[10]。
2.1.2 短语向量表示
我们认为短语的向量表示和词的向量表示在向量结构上并没有差异,即词向量与短语向量具有相同的维度。这样,当我们通过词向量表示整个句子的时候,可以按照句子结构通过对短语向量进行迭代分析,从而有效关注到句子的结构信息和词义信息。
本文对于短语的编码方法,采用基于门卷积的CNN方法。对于给定的一个短语,若其每个词的向量表示分别为w1,w2,…,wn,其中n表示短语的长度,每个词向量表示的长度为l=lw+lp,lw和lp分别为词义嵌入和位置嵌入的长度。卷积核为W,W∈Rl×c,其中c表示卷积核的宽度。那么在图3中卷积层(convolutional layer)的计算过程如式(1)所示。
p=W*[0…0w1w2…wn0…0]
(1)
其中[0…0w1w2…wn0…0]为词表示向量按序排列并在前后分别补(c-1)个零向量后组成的矩阵,其大小为l×(2c+n-2),表示矩阵间的卷积运算,p为行向量。
为了保证短语向量与词向量在维度上兼容,对每条语句,我们取l个卷积核进行卷积运算。于是我们得到l个行向量,如式(2)所示。
pi=Wi*[0…0w1w2…wn0…0]+bi
(2)
若经过最大池层的输出的向量为v,v∈Rl,则v的第i个元素可以表示为式(3)。
vi=max(pi)
(3)
其中max(pi)表示求pi中值最大的元素。
最后经过非线性层,若非线函数取双曲正切函数,最后输出的短语表示向量为x,x∈Rl,则x的第i个元素可以表示为式(4)。
xi=tanh(vi)
(4)
这个表示过程可以用图3表示,最后我们得到一个与词向量同维度的短语表示向量,进而可以将每条短语和词代入同一个语句表示过程进行一并计算。
2.1.3 语句向量表示
语句向量表示是按照语句结构对短语向量表示过程的一个迭代运算。给定任意一条语句,可以分为m条短语,若对于每条短语都已经得到一个向量表示则整个语句可以看作一条短语,进而用短语的向量表示方法将其表示为一个向量。若上节的短语向量表示方法用encode_phrase(·)表示,语句为x1,x2,…,xm,则整个语句的表示向量s可以表示为式(5)。
s=encodephrase(x1,x2,…,xm)
(5)
这个表示过程的迭代过程可以用图2表示,通过该方法,每条语句将被表示为一个长度固定为l的向量。
此外为了防止其过度迭代而破坏语句的基本结构,因而设置迭代深度控制参数γ。当迭代器迭代到指定深度时,直接将现有短语表示序列按照CNN的方法表示为一个向量。当γ=1时,本实验中所提的方法将退化到基于普通CNN的关系抽取方法。
2.2 关注点选择方法
针对同一对实体(head,tail),若被n条语句s1,s2,…,sn提及,且假定在这个n条语句中的实体对有相同的关系r,r∈Re,Re为已知的关系集合。
首先,我们对这n条语句进行加权融合,如式(6)所示。
(6)
其中αi为关注系数。
由于并不是所有的语句s都能准确地对目标关系r进行描述,因此对于不同的语句应有不同的权重。关注系数αi可由式(7)获得
(7)
其中r为关系向量,A为参数矩阵。
最后我们将得到的融合语句向量s送入全连接层,输出向量y可表示为式(8)。
y=Ms+b
(8)
其中b为偏置向量。于是我们可以对神经网络的输出得用softmax分类器进行分类,从而找出该实体对最可能存在的关系r的概率为式(9)。
(9)
其中yi,yj分别为y的第i,j维的值。
此处我们延用2015年Zeng等提出的假设,即在给定的语句中至少有一条语句可以反应出给定实体对存在的关系。经过该式的计算,对于融合向量s中蕴含的关系,该式会趋向于1。而对于其他不能描述该关系的语句,该式将趋向于0。
2.3 优化方法
我们采用交叉熵作为该算法的损失函数,其定义如式(10)所示。
J(A,M,b)=-∑ilog[P(ri|Si,A,M,b)]
(10)
其中A,M,b分别对应式(7)和式(8)中的同字母参数,是需要训练的神经网络参数。
为确定模型中的参数,我们需要用标注数据对其进行训练。为了加速训练,训练方法采用随机梯度下降法(SGD)。每次随机选择数据对其进行训练,直到收敛。
另外,每次在训练数据时需要对数据进行小的随机变动,以防止过拟合。
3 实验结果及分析
本文实验中将在广泛采用的来自《纽约时报》(NYT)的数据集进行测试,并和基于CNN和LSTM的典型方法以准确率和召回率作为评价指标进行对比。
3.1 数据来源及评测指标
本文采用一个在实体关系抽取领域广泛采用《纽约时报》(NYT)的公开数据集。该数据集曾在2010年被Ridel等[5]、在2011年被Hoffmann等[6]、在2012年被Surdeanu等[7]、在2016年被Yankai Lin等引用[10]。该数据集是结合《纽约时报》中的语料和Freebase中的实体集和关系集,利用斯坦福的命名实体识别工具,匹配结合而成。这个数据集被分为两部分,一部分是2005~2006年的语料,包含522 611条语句和281 270对实体,存在18 252种关系实例。另一部分是2007年的语料,包含172 252条语句,96 678对实体,存在1 950种关系实例。本文实验中,将用前一部分语料进行训练,并用后一部分语料进行测试。与过去的评测关系抽取结果的方法相同,本实验中我们采用准确率和召回率进行评价。
3.2 实验参数设置及数据预处理
为了更好地验证提升效果,我们将分别对基于Tree-based CNN方法和基于普通CNN的方法和基于LSTM的方法进行实验,并在准确率和召回率两个指标下进行比较。
算法中存在一些经验参数设置,本实验中对于所有方法(Tree-based CNN /CNN/LSTM)的优化参数设置相同。根据以往的实验经验,同时借鉴Yankai Lin等[10]的参数值设置,我们手动确定了一些可调参数。它们分别为SGD学习率λ=0.01,词句表示维度lw=50,位置嵌入维度lp=5。此外,基于CNN的和Tree-based CNN方法中卷积核的宽度都为c=3,且Tree-based CNN的迭代深度控制参数γ=3。事实上,与其他模型相比,这样的参数设置在实验中也的确使模型表现出了不错的效果。
另外,为了剔除一些不必要的词语信息干扰,我们除去了语料中包含出现次数少于100次的单词的语句。同时我们按照所提的标准,对语句进行了统一规范化的处理。
3.3 语句语法解析树及词向量
本文提出的算法,首先对语句进行了语法解析,其解析工具来源于斯坦福的自然语言处理工具[注]https: //github.com/stanfordnlp/CoreNLP。而对于词向量,我们则应用谷歌的Word2Vec[注]https: //code.google.com/p/word2vec工具对经过预处理后的NYT语料进行了训练。
3.4 实验效果
为了方便比较不同的方法对关系抽取的效果,我们分别利用CNN、LSTM和本文应用的Tree-based CNN方法在同一数据集上进行训练和测试。
表1记录了分别利用CNN、LSTM和本文应用的Tree-based CNN方法时,召回率分别为0.2、0.3和0.4时的准确率。必然的,当提高准确率时,三种方法的准确率都会有所下降,但是可以看出在这三个召回率下,本文所应用的方法都明显优于传统的CNN和LSTM算法。TBCNN相对LSTM,当召回率设置为0.2时,准确率提高最大,为0.054;TBCNN相对于CNN,当召回率设置为0.4时,准确率提高最大,为0.036。
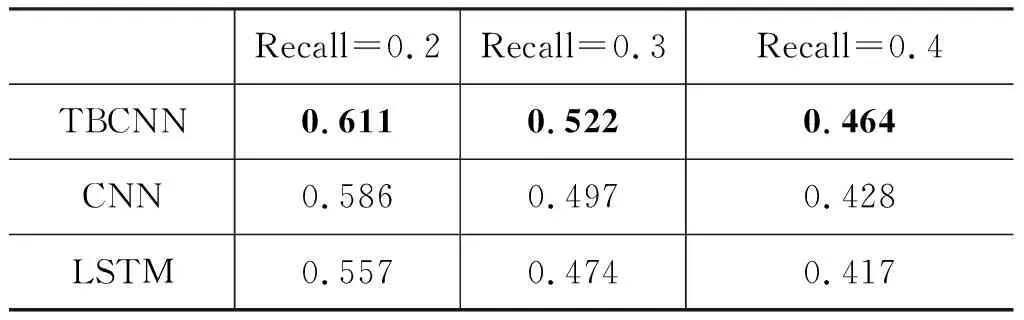
表1 不同算法准确率(Precise)对照表
图4中,我们以准确率和召回率为横纵坐标画出了precise-recall曲线。从该图我们可以看出,Tree-based CNN整体优于一般的CNN和LSTM方法: 一般的CNN方法,在提高召回率的同时,会伴随准确率的急剧下降,而LSTM在要求高准确率的情况下,召回率则明显不足;而应用Tree-based CNN处理时,则兼顾了准确率和召回率。无论是在准确率还是在召回率水平上,Tree-based CNN方法都能够发挥其优势。并在召回率为0.3时,Tree-based CNN相对于CNN和LSTM明显占优,其准确率相对于CNN和LSTM分别提高了约3%和5%。

图4 precise-recall曲线
图5和图6分别展示了三种方法的F1值和F0.5值曲线。可以看出,无论是F1值还是F0.5值在所有相同召回率控制条件下,Tree-based CNN处理结果都不低于CNN和LSTM的处理结果。且当召回率控制在0.3~0.45之间时,Tree-based CNN的处理结果有明显优势。

图5 F1-recall曲线

图6 F0.5-recall曲线
3.5 深入分析
基于Tree-based CNN的关系抽取方法是从基于CNN的关系抽取方法发展而来,其本质上是对CNN方法按照句法树的递归调用。当迭代深度控制参数γ=1时,Tree-based CNN方法将退化到CNN方法。因而当召回率控制较低时,Tree-based CNN与CNN在性能上表现出了相似性。但随着召回率的增加,其能够融合更多句法信息的优势则体现了出来,因而可以达到更高的准确率。
并且其递归调用的方法,将原来层状结构的神经网络变为了树状结构。由于其递归调用的方法,可以使得其对更长距离的文本信息进行融合提炼,在一定程度上讲,其与LSTM有一定的相似性。因而在控制高召回率时,Tree-based CNN和LSTM在性能上表现出了相似性。当召回率控制较低时,Tree-based CNN在关系抽取方面继承了CNN的优势,因而可以在准确率上相对LSTM达到更高。
4 结束语
本文在句子级水平上针对句子的句法树结构提出了利用Tree-based CNN对语句进行编码,并在关系抽取任务中,提高了3%~5%的精度。Tree-based CNN是一种兼容CNN的递归神经网络,通过控制迭代深度可以退化到一般CNN模型。通过实验结果分析可知,基于Tree-based CNN的编码方式,可以在实体关系抽取任务中兼具CNN和LSTM的优势。
下一步,我们将继续发展Tree-based CNN的动态结构优势,并希望其在自然语言的其他任务中发挥优势。
