基于不确定图的隐私保护方法研究
2018-12-20史武超吴振强
胡 静,史武超,颜 军,吴振强
(陕西师范大学 计算机科学学院,陕西 西安 710119)
1 概 述
进入大数据时代,随着移动互联网的发展,人们在生活中可以随时随地产生数据,例如聊微信、转发微博等。以微信为例,仅在2016年9月份,微信日登录用户达到了7.68亿。由于社交网络的发展与应用,越来越多的研究转移到社交网络,使得社交网络分析成为诸多学科的研究热点。然而,政府部门、商业机构对采集到的数据进行发布与共享时,会导致用户个人隐私的泄露。因此,在发布数据的同时保护用户的隐私信息就成了大数据环境下面临的一个重大课题。
近年来,学者们在隐私保护方面做了大量的工作,而且取得了丰硕的成果。如Sweeney提出的k-匿名技术[1],该技术要求发布数据对象个体在同一等价类中至少与其他k-1个对象不可区分,每个个体身份被识别出来的概率至多为1/k,从而降低了隐私泄露的风险。然而k-匿名技术不能抵抗同质性攻击。为了解决这一问题,Machanavajjhala等[2]提出了l-多样性,Li等[3]提出了t-紧密性等k-匿名技术的改进方法。但是这些方法难以定义攻击者拥有的所有可能的背景知识,容易遭到背景知识攻击且不能提供一种严格可证明的隐私保护程度。2006年Dwork提出的差分隐私技术解决了攻击者可能的背景知识问题,并对隐私保护水平提供了量化评估方法[4]。
现有隐私保护方法主要适用于关系数据或者统计数据。在统计数据中,每个个体在统计上是相互独立的;在关系数据中,关系隐私保护模型仅防范了将实体属性值作为背景知识的隐私攻击。然而,在社交网络中,不仅要防止实体属性值作为背景知识的攻击,还要防止实体属性值之间的关联攻击。因此,单纯的关系数据或统计数据隐私保护方法不能满足社交网络中数据的隐私保护要求,需要提出与社交网络数据特点相适应的隐私保护方法。在社交网络中,网络中个体间的关系、社交网络结构、个体在结构中位置的重要性等均可作为攻击者的背景知识进行隐私攻击[5]。因此,社交网络隐私保护一直是隐私保护研究的热点领域。
社交网络的隐私保护主要保护个体之间的关联关系,因此将社交网络抽象为网络图来进行研究。图结构下的隐私保护算法可分为5种。
(1)顶点标识符替换方法。BackStrom等[6]提出在发布真实图数据之前用合成标识符替换可识别属性的匿名隐私保护方法,但容易受到背景知识的攻击,攻击者可以根据顶点结构特征推断出顶点的身份信息。
(2)边修改方法。该方法主要操作是随机增减边或交换边,根据不同条件又分为无约束的边修改和有约束的边修改。前者如Hay等利用随机添加/删除边策略提出随机扰动方法来匿名图[7],Bonchi等[8]提出基于熵匿名等级量化及Sparsification方法;后者如Liu等[9]提出基于边修改方法的k-度匿名,龚卫华等[10]提出保持网络结构稳定的k-度匿名隐私保护模型。
(3)顶点和边的聚类方法。该方法将图中的顶点和边经过泛化或聚类,变为超级顶点和超级边,从而使某个顶点和边的信息隐藏在这些超级顶点和超级边中,如谷勇浩等[11]针对动态社交网络数据发布提出一种基于聚类的动态图发布算法;姜火文等[12]提出一种基于顶点连接结构和属性值属性图聚类匿名化方法。
(4)顶点和边的差分隐私方法。如Hay等[13]提出节点差分隐私和边差分隐私的概念;文献[14]综述了社交网络中的差分隐私以及差分隐私在社交网络中的应用发展;兰丽辉等[15]提出一种基于差分隐私的随机扰动方法实现边集边权重的保护。
(5)边的不确定性方法,即不确定图方法。该方法通过对原始图数据进行处理,将图中所有边出现的可能性变成[0,1]区间内的某个概率值,将确定的网络图以不确定图的方式进行数据发布,从而保护了网络图中用户的隐私信息。
将不确定图引入隐私保护是近年来提出的新的图结构数据隐私保护方法,该方法存在如下优势:对个体间的关系进行了模糊化,将个体之间的确定关系变为不确定关系;相对于边修改方法,保护了图结构数据中实体之间的关系;没有破坏数据的效用性,在保护隐私的基础上不影响用户进行数据挖掘的数据效用。
2012年Boldi等[16]提出给原始图中的边加入不确定性的方法,所提出的(k,ε)-混淆算法在抗顶点身份攻击的同时也保证了图结构数据的最小化失真;2013年Mittal等[17]提出了基于随机游走的不确定图数据发布方法,防止了链接攻击;Nguyen等[18]在2014年提出基于方差最大化的方法来衡量隐私与效用之间的关系;2015年Nguyen等[19]在前期工作的基础上又提出了基于不确定邻接矩阵的通用匿名模型UAM,并将UAM引入到方差最大化算法中。综上,文中主要研究已有的不确定图隐私保护算法,通过对每种算法分析和对比,总结了每种算法的优缺点及各自的适用范围,为隐私保护方法工程化实现提供技术参考[20]。
2 基础知识
本节主要介绍不确定图,(k,ε)-混淆,顶点唯一性和共性,随机游走的转移矩阵,不确定邻接矩阵等概念。
定义1[16]:给定一个图G(V,E),如果映射p:V2→[0,1]是边集中每条边存在的概率函数,那么图G'=(V,p)是关于图G的不确定图,其中V2表示集合V中所有可能的顶点对,即V2={(vi,vj)|1≤i 从定义1可知,确定图G是不确定图G'的一种特殊情况,确定图G中的每条边存在的概率均为1。 为了描述不确定图,使用文献[16]中的概率数据库模型—可能世界模型(possible world model),将生成的不确定图G'的所有可能世界表示为W(G'),则对于某一不确定图W=(V,EW)∈W(G')的概率为: (1) 其中,E'为引入不确定性的顶点集合,E'⊆V2;p(e)为边存在的概率,且不确定图中不同的边的概率分布是相互独立的。 假定攻击者知道某些顶点的属性P,将属性P的所有取值用ΩP表示。若属性P是图中所有顶点的度,则ΩP可以表示为:ΩP={0,1,…,n-1}。 给定一个不确定图G'和某一个属性P,对于每一个顶点v∈G'和ω∈ΩP,顶点v∈G且具有属性P的概率Xv(ω)为: (2) 对于式2,可以根据式1得到Pr(W),而χv,ω(W)是一个[0,1]区间的变量,用来度量W中的顶点v是否具有属性P。也就是说,Xv(ω)是所有可能世界模型中顶点v具有属性P的概率之和。同时可以得到图G中具有属性值ω的顶点v在G'中像的概率Yω(v)为: (3) 定义2[16]((k,ε)-混淆):已知P是一个顶点属性,k(k>1)是所需要达到的混淆级别,ε(0<ε<1)是一个容忍参数,如果G'中顶点的分布熵大于等于log2k,那么就说不确定图G'是关于属性P在顶点集合v属于G上的k-混淆,即:H(YP(v))≥log2k。如果图G'至少在混淆图G中具有属性P的(1-ε)n个顶点,那么就说不确定图G'在属性P中是(k,ε)-混淆的。 根据顶点在图G所处位置及属性的不同,文献[17]给出了顶点唯一性和共性的定义,具体见定义3。 定义3[16]:已知P是定义在图G顶点集合V上的一个属性,P:V→ΩP,θ是一个大于0的参数,对于任意属性值ω∈ΩP,则它的θ共性Cθ(ω)和θ唯一性Uθ(ω)为: (4) (5) 在定义3中,距离函数d为属性P在ΩP范围内的值。因此,对于每一对ω,ω'∈ΩP,总有d(ω,ω')>0。对于顶点度的属性P1,距离函数d的值为P1中两顶点度的差的绝对值。同时,Φ是高斯分布,见式6: (6) 在该定义中顶点属性值的ω的共性是指,ω值在图中顶点属性中是否具有代表性的一种测量,唯一性是共性的逆。共性与唯一性的大小取决于θ值的大小,θ越大,不确定性越大,属性值的取值范围ΩP越广,顶点属性的共性越小,则唯一性越大。 定义4[17]:随机游走的转移概率矩阵为: (7) 其中,deg(i)表示顶点i的度。 定义5[19]不确定邻接矩阵UAM(uncertain adjacency matrix):给定原始图G及其对应的不确定图G',如果矩阵A满足以下三点,则称A为不确定图G'的邻接矩阵。 (1)Ai,j=Aj,i; (2)Ai,j∈[0,1]且Ai,i=0; 本节主要对(k,ε)-混淆算法、随机游走算法、优化的随机游走算法和基于UAM模型的方差最大化算法进行对比研究。首先从算法的执行流程图、算法功能等角度进行分析,然后从保护程度、数据效用性和图结构失真程度等方面进行了对比,最后总结了四种算法的优缺点及其各自的适用场景。 3.1.1 (k,ε)-混淆算法 (k,ε)-混淆算法主要包括两个部分,主算法(见图1)和子算法(见图2)。 图1 (k,ε)-混淆算法流程 主算法的目的是找到符合条件的具有最小不确定性的(k,ε)-混淆图;子算法是在给定的标准差参数,即不确定预算σ的情况下,找到原始数据图G的(k,ε)-混淆图G'。为了更好地利用不确定预算σ,需要对图中的数据进行预处理,即选择唯一性最大的「ε/2|V|⎤个顶点组成筛选集合H,H作为未加入不确定性顶点集合,因此,该算法不针对图中所有顶点。 图2中顶点唯一性的计算见定义3,顶点的唯一性值越大,该顶点中需要引入的不确定性越大,因此与唯一性大的顶点相邻边的采样概率Q(v)就越大。根据采样概率Q(v),按比例缩小集合V中的顶点v的唯一性级别。对于子算法,对于E'中的每条边e,根据边的唯一性σ(e)重新分配不确定性级别。 图2 子算法流程 对于E'中边e=(u,v),它的σ-唯一性级别为: (8) σ-不确定性集合为: (9) 对于大多数顶点对,边随机扰动参数re服从随机分布Rσ(e)(见式10);对于少数顶点对,边随机扰动参数re服从[0,1]均匀分布。 (10) 其中,Φ0,σ为高斯分布的密度函数,见式6。 3.1.2 随机游走算法 随机游走算法(RandWalk,RW)是通过对原始数据图中添加噪音,将原始图结构转化为不确定性的图结构,即通过随机游走方法遍历图中的顶点和边,删除一些原始数据图中真实存在的边和添加某些不存在的边。在RW算法中,为了避免顶点自环或者多条重复边的出现,该算法设置了实验次数的阈值M。RW的处理流程如图3所示。 图3 RW算法流程 RW算法保护了原始图中的局部图特征,防止了恶意攻击者对网络数据图中某个子图的链接攻击。在真实数据库中进行验证时,该算法对原始数据不进行预处理。随机游走次数t越小,社交网络上的社团结构保护效果越好,并且与引入噪音的大小无关。 3.1.3 优化的随机游走算法 由于RW算法中存在误差实验次数M值的设置,使得算法难以进行对比分析,Nguyen等对RW算法进行了优化,提出了RandWalk-mod算法(RW-mod)。RW-mod算法通过增加参数α来消除RW算法中的M参数,其中α是介于0和1之间的一个值。RW-mod执行流程如图4所示。 3.1.4 方差最大化算法 基于定义5中的UAM矩阵,Nguyen等提出了方差最大化算法,该算法是高隐私保护算法RW和高数据可用性算法(k,ε)-混淆之间的一个均衡。方差最大化方法包括三个阶段,该方法可阐述为:先将原始图G分为s个子图,每个子图sG有ns=np/s条与附近顶点(顶点之间的默认距离为2)相连的边数;在顶点的度不变的条件下,每个子图sG形成一个有最大边方差的不确定子图sG'的二次规划;最后将不确定子图sG'合并成G',并发布一些样本图。算法流程如图5所示,在该算法中,可以利用二次规划中的目标函数来计算原始数据图的隐私保护程度。 (1)(k,ε)-混淆算法利用顶点的唯一性和分布熵对图中的顶点进行筛选,然后对筛选后的顶点进行边混淆;RW算法和RW-mod算法利用马尔可夫过程和转移矩阵对原始图进行边的不确定化;方差最大化算法先利用图分割技术将原始图划分为多个子图,每个子图对应一个二次规划。 图4 RW-mod算法流程 图5 方差最大化算法流程 (2)(k,ε)-混淆算法的隐私保护程度最小;RW算法的隐私保护程度最大;RW-mod算法的隐私保护程度同RW算法;方差最大化算法的隐私保护程度介于(k,ε)-混淆算法和RW算法之间。 (3)通过(k,ε)-混淆算法,数据的可用性较高;通过RW算法,数据的可用性较差;RW-mod算法的数据可用性同RW算法;方差最大化算法数据可用性介于(k,ε)-混淆算法和RW算法之间。 (4)通过(k,ε)-混淆算法,图结构失真较小;通过RW算法,保护了图中的局部特征;RW-mod算法同RW算法;通过方差最大化算法,图结构失真较大。 (5)(k,ε)-混淆算法中顶点的度保持不变;RW算法忽视了变换前后顶点度的关系;RW-mod算法中顶点的度保持不变;方差最大化算法中顶点的度保持不变。 (6)(k,ε)-混淆算法不允许自环;RW算法不允许自环,在构造不确定图时造成了边的丢失;RW-mod算法和方差最大化算法允许自环。 (7)(k,ε)-混淆算法和RW算法不允许两顶点之间存在多条边;RW-mod算法和方差最大化算法允许两顶点之间存在多条边。 (8)(k,ε)-混淆算法和RW算法符合定义5中的条件1和条件2;RW-mod算法在条件(1)中α=0.5时,符合定义5中的条件1和条件3;方差最大化算法符合定义5中的条件1~3。 (9)(k,ε)-混淆算法适合低隐私保护程度,高数据可用性的场景;RW算法和RW-mod算法适合高隐私保护程度,低数据可用性的场景;方差最大化算法适合高隐私保护程度,高数据可用性的场景。 在(k,ε)-混淆算法中,存在两点不足之处:(1)σ最小化带来的问题。σ越小,边随机扰动参数re大部分值集中在0附近,原始数据图中真实存在的边的概率1-re接近于1,不存在的边的概率re接近于0,攻击者可以根据舍入方法,将发布的不确定图还原为原始数据图;(2)该方法选择顶点对,构造原始数据图中不存在的边时,没有考虑到顶点的局部性,即顶点在子图中所处的位置,好的子图扰动可以减少图结构的失真。RW算法是为了防止链接攻击而提出的,是一种高隐私保护模型。但是RW算法中的试验次数M及M值如何确定,使得算法难以进行比较分析。RW-mod算法不适合度为1的顶点,若顶点的度为1,则与该顶点相连的边在原始数据图上是真实存在的,在构造不确定图时添加该条真实存在的边的概率为1,而在RW-mod算法中,添加该边的概率为0.5。方差最大化算法在子图分割时造成了原始图中边的丢失,使得图结构失真较大。 四种算法的比较见表1。 综上所述,基于不确定图的隐私保护方法在隐私保护中具有重要的使用价值。通过对(k,ε)-混淆算法、RW算法、RW-mod算法及方差最大化算法进行分析和比较,为基于不确定图的隐私保护方法的改进和应用提供了技术支持。下一步重点研究将以上算法应用到有向图或加权图隐私保护中,同时引入新机制,如差分隐私,设计新的基于不确定图的隐私保护方法。 表1 四种不确定图实现算法的比较3 基于不确定图的隐私保护算法
3.1 算法流程分析
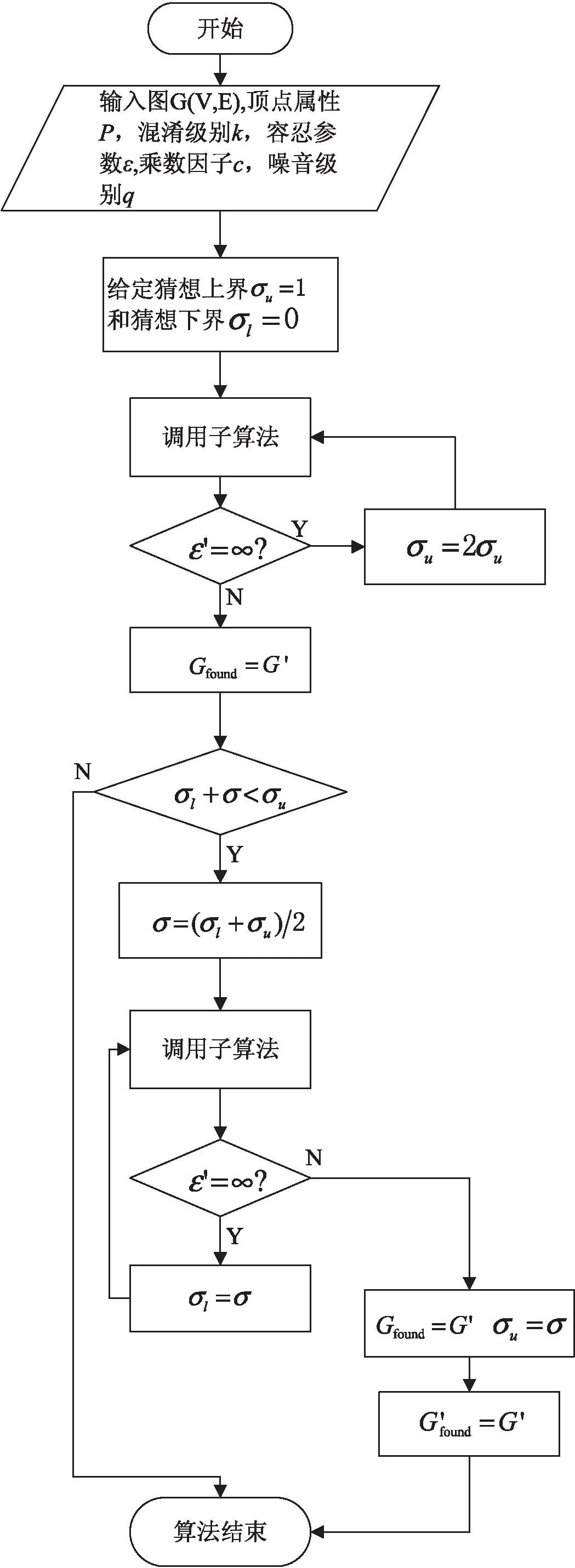
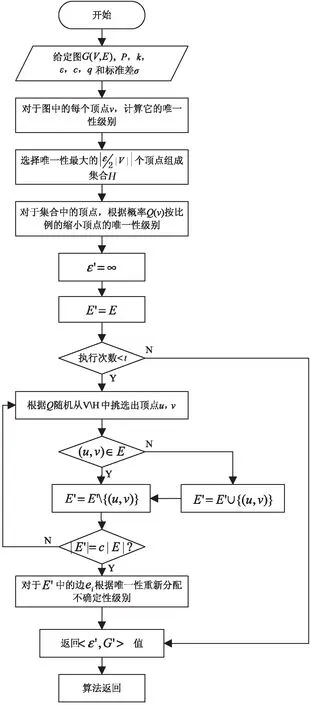

3.2 算法比较
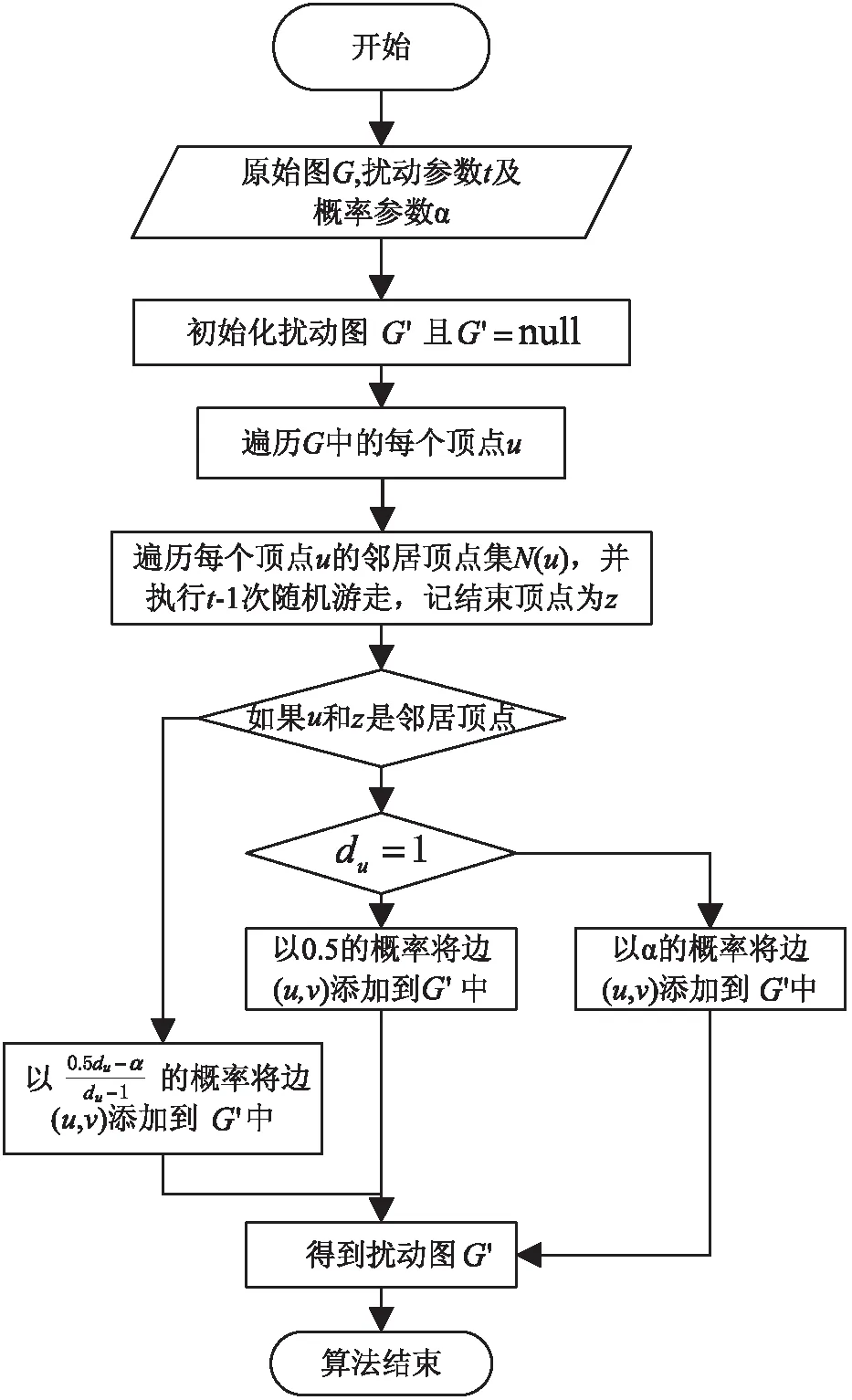
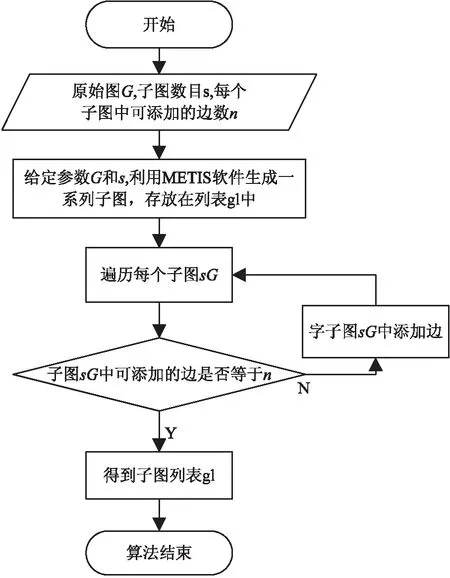
4 结束语

