一种基于改进果蝇优化的K-mediods聚类算法
2018-12-20王全民张帅帅
王全民,杨 晶,张帅帅
(北京工业大学 信息学部,北京 100124)
0 引 言
K-mediods算法是一种基于划分的聚类算法,改进了K-means算法对噪声和孤立点数据敏感的缺点,收敛速度较快且局部搜索能力较强[1]。但该算法聚类效率和精度较低、全局搜索能力较差等缺点仍需要改进[2]。文献[3]针对K-medoids算法对初始聚类中心敏感的缺陷,提出了有效的解决方案,提高了算法的性能。文献[4]提出了一种基于改进人工蜂群的K-mediods算法,由于结合粒计算和最大最小距离初始化蜂群降低了对噪声的敏感性,聚类效果较稳定。文献[5]提出了基于核的自适应聚类,该算法降低了K-medoids对初始值的敏感性。
针对K-mediods算法易陷入局部最优的缺点,提出了一种基于改进果蝇优化算法的 K-mediods聚类算法。将混沌映射思想应用在果蝇群体的初始位置生成,保证初始位置能够在全局更均匀的分布,算法后期根据群体适应度方差判断果蝇优化算法是否处于局部收敛状态,若是,利用禁忌搜索思想在最优值邻域内寻求更优解。将融入了混沌映射与禁忌搜索的果蝇优化算法与传统的K-mediods算法相结合,对每次聚类迭代中的簇中心进行寻优,以提高K-mediods算法的全局搜索能力和聚类精度。
1 基于Logistic映射的混沌技术
混沌映射的基本思想是:将优化变量(一个在[0,1]区间波动的变量)通过混沌映射规则映射到混沌变量空间的取值区间内,利用混沌变量的遍历性和规律性寻优搜索,最后将获得的优化解线性转化到优化空间[6]。通常其系统方程为:
x(t+1)=μx(t)(1-x(t))
(1)
其中,μ为控制参数;t为迭代次数,x(t)∈[0,1]。当μ=4时,系统出现混沌状态,即不重复地随机访问系统解空间。
式2为混沌变量Cxi的一种变换算式。
Cx(t+1)i=4Cx(t)i(1-Cx(t)i),
i=1,2,…,N
(2)
其中,Cx(t)i为第i个混沌变量经历i次混沌映射之后得到的变量值。当Cxi∈[0,1],μ=4且Cxi≠{0.25,0.5,0.75}时,系统出现混沌状态。优化变量xi∈[xmin,xmax],式3、式4为xi与Cxi∈[0,1]进行往返映射的过程。
Cxi=(xi-xmin)/(xmax-xmin)
(3)
(4)
2 禁忌搜索算法
禁忌(Tabu search,TS)算法是一种启发式搜索算法,首先确定初始解,然后按照一定方向移动进行搜索试探。为了避免陷入局部最优的状况,在搜索过程中,禁忌搜索算法采用两个策略:禁忌准则和特赦准则[7]。禁忌搜索建立一个禁忌表,它有一定的长度,储存近期遍历过的最优解。根据邻域计算函数计算邻域内的最优值,查看禁忌表,以防近期遍历过的最优值重复遍历陷入局部最优,但若该解扩大了解空间的搜索范围,则特赦保留。
TS算法步骤如下:
(1)给定初始解x0,计算f(x0),令当前点x=x0,最优点xbest=x0,最优值f(x)best=f(x0)。
(2)计算点x邻域内所有点的f(x)。
(3)寻找邻域内最优值best(f(x))的对应点x'。
(4)检查是否满足特赦准则,若是,则令x=x',xbest=x',f(x)best=f(x'),执行步骤6;否则转入步骤5。
(5)判断禁忌准则:遍历禁忌表,若没有点x',则x=x',执行转入步骤6,否则在邻域中删除x'。转入步骤3。
(6)更新禁忌表。判断是否满足终止条件,若满足,则终止计算,否则转入步骤2。
算法中禁忌准则是指通过建立“禁忌表”模拟记忆,设定合适的禁忌长度,将近期遍历过的解存放进去,将搜索到的最优解与之比较,以防搜索陷入循环,从而避免局部最优。特赦准则是指在禁忌搜索算法的迭代过程中,若被访问的解再次出现在禁忌长度内,但搜索范围可以得到很大的优化时,为了保障全局最优,可以接触对该最优值的禁止,进行重新选择。
3 果蝇优化算法(FOA)
果蝇优化算法是一种群智能全局优化搜索算法[8]。果蝇能够通过特殊的嗅觉和视觉搜集空气中的各种气味以锁定食物的位置,飞到食物位置附近后亦可使用敏锐的视觉发现食物和同伴聚集的位置,并且向该方向飞去[9]。
果蝇优化算法的一般步骤为:
(1)初始化参数:最大迭代次数maxgen,种群规模sizepop,果蝇群体位置X_axis、Y_axis。
(2)根据式5、式6,果蝇个体通过敏锐的嗅觉搜寻食物,并向随机方向移动。
Xi=X_axis+Random Value
(5)
Yi=Y_axis+Random Value
(6)
其中,Xi和Yi分别为果蝇个体飞向的横纵坐标。
(3)根据式7计算与原点的距离(Dist),根据式8计算得到味道浓度判定值Si。
Disti=sqrt(Xi2+Yi2)
(7)
Si=1/Disti
(8)
(4)将味道浓度判定值Si代入味道浓度判定函数即适应度函数,计算该果蝇个体位置处的味道浓度Smelli。
Smelli=Function(Si)
(9)
(5)找出该果蝇群体中的最佳味道浓度值bestSmell。
[bestSmell bestIndex]=max(Smell)
(10)
(6)保留最优位置坐标和最优味道浓度值,果蝇群体利用视觉向该位置方向飞去。
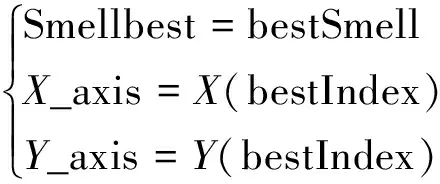
(11)
(7)进入迭代寻优,重复执行步骤2~5,判断味道浓度是否优于最佳味道浓度值,若是则执行步骤6,直至当前迭代次数达到最大迭代数maxgen或已达到精度要求,则停止迭代。
4 基于混沌映射与禁忌搜索的果蝇混合优化算法(LGTS-FOA)
混沌映射思想保证在解空间范围不重复地访问所有状态,因此利用这一系统构造果蝇群体初始位置可以很好地使果蝇群体较为均匀地分布在解空间。而禁忌搜索思想对于初值有很高的要求,因此考虑在FOA算法的后期引入该算法。将后期收敛解作为TS算法的初始解,采用果蝇群体的适应度方差σ2来判断后期收敛情况[10],当算法进入后期局部收敛状态时,利用禁忌搜索算法跳出局部最优。
4.1 LGTS-FOA算法
LGTS-FOA算法步骤如下:
(1)设置种群规模sizepop、最大迭代次数MCN和适应度方差阈值δ。
(2)利用logistics多次映射的结果作为果蝇种群的初始位置。
(3)执行FOA算法中的步骤2~5。
(4)利用式13得到当前迭代中种群的适应度方差。
(12)
(13)
(5)若σ2<δ,说明算法已进入后期收敛状态,则执行禁忌搜索算法的步骤2~6。否则执行步骤6。
(6)如果当前迭代得出的bestSmell优于Smellbest,保存最佳浓度和最优位置坐标。判断是否达到最大迭代次数,若是结束算法,否则,转入步骤3。
4.2 有效性测试
文中采用4个经典标准函数进行有效性测试:
(1)Sphere函数:
(2)Rosenbrock函数:
(3)Griewank函数:
(4)Rastrigin函数:
实验参数设置:群体规模sizepop=30,最大迭代次数maxgen=1 000,适应度方差δ=0.000 01。用4个经典标准函数分别对改进的LGTS-FOA算法和经典FOA算法进行测试,在相同的实验条件下,各运行50次,比较二者的最优值(best)、优化均值(median)和标准差(std),结果见表1。

表1 FOA与LGTS-FOA算法性能比较
从表1可以得出,在同等条件下,对于单峰函数(f1、f2)和多峰函数(f3、f4)来说,LGTS-FOA算法在均值和标准差上较经典FOA算法都不同程度的改善,优化均值精度提高了8~9个数量级,其中f1函数甚至提高30个数量级,说明LGTS-FOA在寻优精度上有显著提高;标准差的降低,说明LGTS-FOA比FOA的稳定性要强;计算多峰函数Griewank函数和Rastrigin函数最优值上LGTS-FOA算法的寻优精度数量级提高了10个左右,说明其在高维多峰函数上的效果显著。
观察4个经典标准函数迭代1 000次的果蝇群体适应度进化过程。为方便显示,纵坐标选取以10为底适应度的对数。在4个标准函数上经典FOA算法表现为迭代前期收敛速度较快,之后陷入局部最优,从而导致寻优精度不够高,而LGTS-FOA在保证了收敛速度的情况下,在陷入局部最优时能够迅速跳出,继续寻优,精度数量级有大幅提高。在Rosenbrock函数的优化过程中虽然两者精度都不高,但是FOA迭代初期就陷入局部最优,寻优速度减缓;而LGTS-FOA在迭代过程中,寻优速度较快,LGTS-FOA性能总体优于FOA。在Griewank函数、Rastrigin函数优化过程中,由于初始位置采用混沌映射生成,因此适应度的起始值要优于FOA,有利于帮助LGTS-FOA更快速精确的寻优。综上所述,LGTS-FOA的适应度收敛速度和精度均优于FOA。
5 K-mediods聚类算法
K-mediods聚类算法的出现是对经典K-means算法的一种改进,避免了K-means算法对噪声和孤立点的敏感程度[11]。典型的K-mediods算法步骤如下[2]:
(1)随机选取k个样本作为初始聚类中心点集。
(2)依次计算数据集中所有样本点到中心点的距离(欧几里德距离),将样本点放入距离最近的中心点代表的簇中。
(3)在各簇中,计算与簇内各样本点距离的绝对误差最小的点,替代旧中心点。
(4)如果聚类中心点集保持不变,算法终止;否则,更新中心点,重复执行步骤2~4。
6 基于改进果蝇优化算法的K-mediods聚类算法
6.1 适应度函数
采用类内距离衡量聚类的内聚程度[12],公式如下:
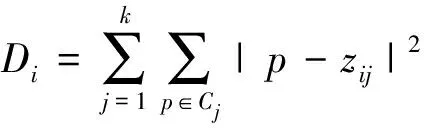
(14)
其中,zij表示第i个蜜蜂所表示的第j个聚类Cj的中心点;p表示类Cj中的非聚类中心点。
文中将类内距离的倒数作为适应度值。当类内距离最小时聚类效果最优,此时适应度值最大,表示如下:
fiti=1/Di
(15)
6.2 新聚类中心
每次迭代果蝇群体寻找出的最优解并不能保证落到某个样本坐标上,因此需要确定新的聚类中心vij,表示距离聚类中心最近的样本[13],如式(16)。
(16)
其中,i=1,2,…,SN,j=1,2,…,k;n表示数据集个数;xt表示果蝇个体;zij表示第i只果蝇的第j维(聚类中心)。
6.3 算法步骤
6.3.1 果蝇编码
初始化种群每一个体对应一组聚类中心向量Zi=(zi1,zi2,…,zik),其中zik表示第i个果蝇表示的第k簇的中心向量。
6.3.2 具体步骤
(1)初始化聚类个数k,群体规模sizepop,迭代数maxgen,味道浓度方差阈值δ。
(2)利用Logistic映射产生的混沌序列作为初始果蝇群体的位置编码,利用式16将分别距离序列最近的k个样本作为初始聚类中心点。
(3)根据欧几里得距离计算,将剩余样本加入到距离最近的聚类中心所代表的簇中。
(4)执行LGTS-FOA算法步骤3~6,适应度函数如式15所示。
(5)将此时最佳适应度位置编码利用式16得出新的聚类中心。
(6)对数据集进行一次K-mediods聚类,得到新的聚类中心,更新果蝇位置。
(7)若达到最大次数Maxgen或者聚类中心收敛,则停止算法;否则转入步骤3,M=M+1。
7 实验结果与分析
为了验证文中算法的有效性和可行性,分别采用K-mediods、文献[14-15]提出的算法及文中算法,分别在随机生成的人工数据集、Iris、Wine和Seeds数据集上进行测试。在10次实验中,参数设置分别为:蜂群个数sizepop=30,最大循环次数Maxgen=100,δ=0.000 01。
7.1 人工数据集实验
随机生成的人工数据集属性维度为2,样本个数为300,类个数为3。人工数据集的样本分布如图1所示,算法在人工数据集上的聚类结果分别为图1~5所示。
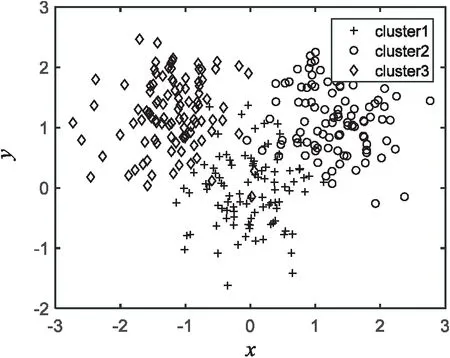
图1 人工数据集分布
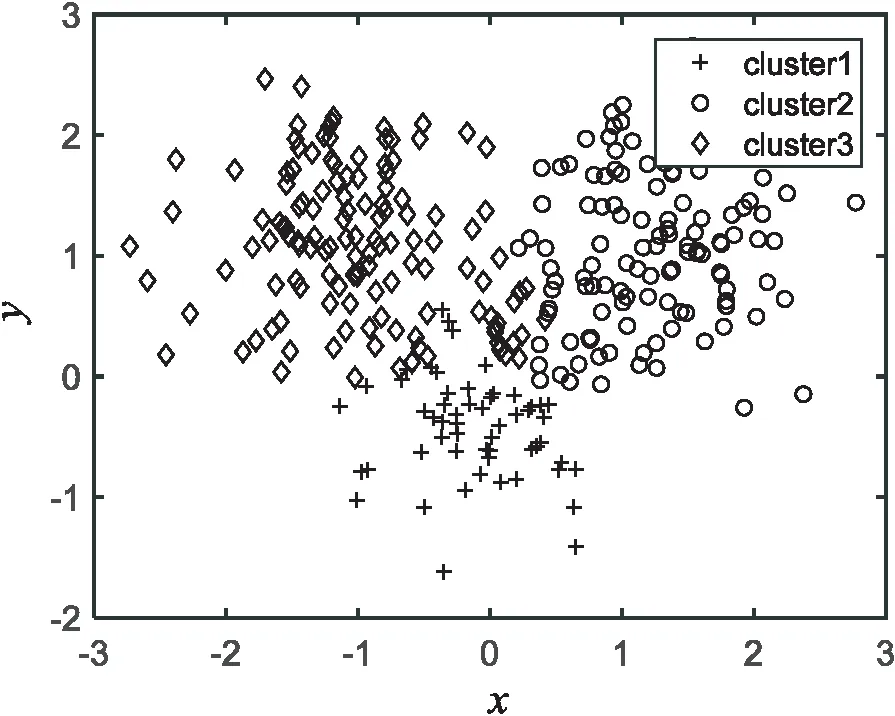
图2 K-mediods聚类结果
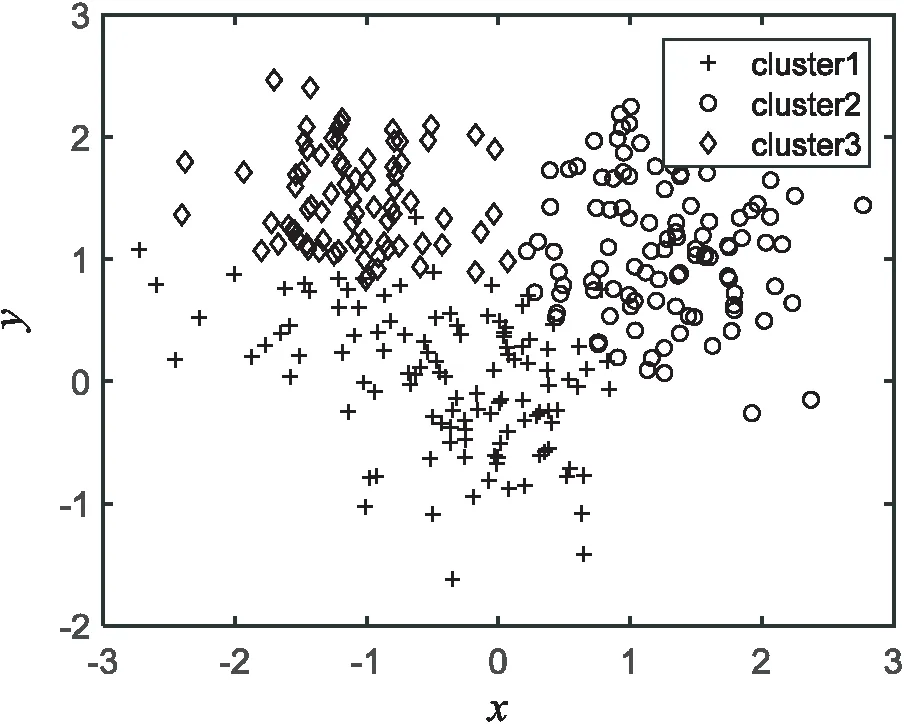
图3 文献[14]算法的聚类结果
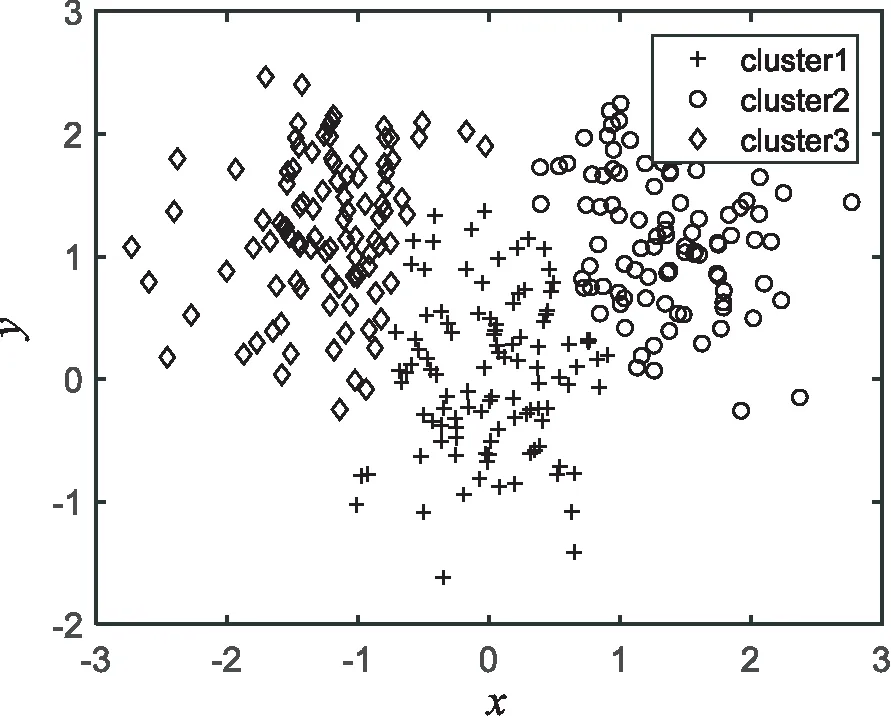
图4 文献[15]算法的聚类结果
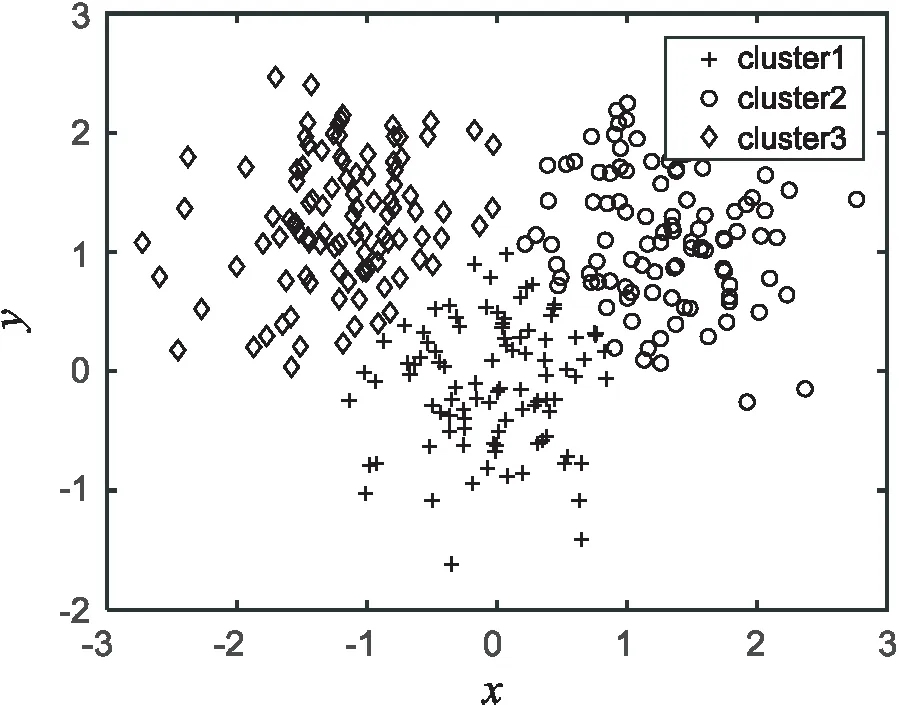
图5 文中算法的聚类结果
实验结果表明,K-mediods、文献[14-15]的算法及文中算法在人工数据集上的聚类准确率分别为79.13%、82.56%、89.41%、93.79%。相比其他几种算法,文中算法有较好的聚类效果,不但聚类准确率较高而且聚类效果稳定。通过比较图2~5可知,文中算法对类边界的处理最为精确。其他算法在边界处理上出现较大偏差导致聚类准确度不够高,与原始数据样本分布有较大偏差。
7.2 UCI标准数据集实验
采用UCI标准数据集中的Iris、Wine和Seeds。各类算法在上述几种标准数据集中得到的平均正确率以及迭代次数如表2所示。
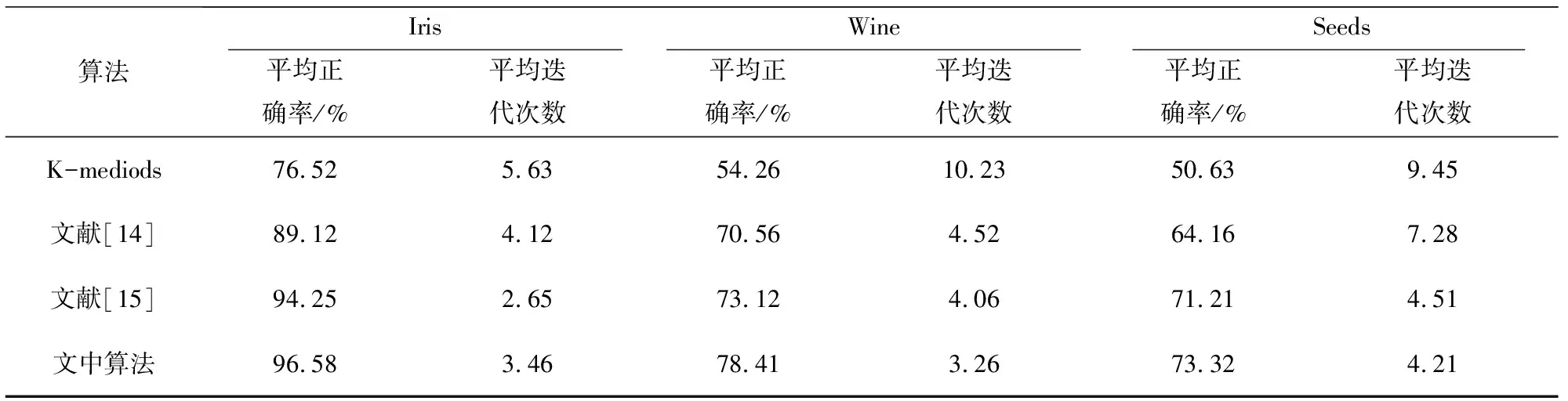
表2 不同算法对UCI数据集聚类结果的比较
通过比较表2发现,文中算法在迭代次数上与其他几种算法相比有所减少,说明了采用映射思想初始化果蝇群体时,能够将初始值较为均匀地分散在解空间,避免了初始聚类中心分布不理想对K-mediods算法的影响,改善了K-mediods算法对初始值敏感的缺点,从而减少了迭代次数;使用禁忌思想能够避免陷入局部最优解,提高聚类正确率;在Iris数据集上表现尤为明显,聚类最高正确率达到97%,平均准确率比K-mediods提高20%。相比Iris,文中算法在Wine和 Seeds数据集上的平均准确率相对较低,但其平均正确率和平均迭代次数仍然优于其他几种算法,同时实验数据也表明基于LGTS-FOA的K-mediods算法同样适用于高维数据集的聚类研究。可见,文中算法在聚类准确率、效率以及稳定性等方面有明显的改进。
综上所述,对不同的数据集,在相同的实验条件下,相比其他几种算法,文中将改进的果蝇算法和 K-mediods相结合,改善了传统K-mediods算法易陷入局部最优的缺点,缓解了其对初始值的敏感,在聚类准确度和效率上均有所提高,对于高维数据集同样具有较好的适应性。
8 结束语
提出一种基于改进果蝇优化算法的K-mediods聚类算法,将融合了混沌映射与禁忌搜索思想的果蝇优化算法与K-mediods算法相结合,使用类内距离的倒数作为适应度函数,在人工数据集和UCI数据集上进行实验,结果表明文中算法既能保证聚类准确度又能有效提高效率,且对于高维数据集具有较好的适应性。
