基于深度学习的虚拟边界检测方法
2018-12-14赖传滨韩越兴
赖传滨,韩越兴,2,顾 辉,王 冰
(1.上海大学 计算机工程与科学学院,上海 200444; 2.上海大学 上海先进通信与数据科学研究院,上海 200444;3.上海大学 材料基因组工程研究院,上海 200444; 4.上海大学 材料科学与工程学院,上海 200444)(*通信作者电子邮箱hanyuexing@gmail.com)
0 引言
材料的性能和结构之间有着密不可分的关系。研究这层关系,有助于通过材料的已知成分和组织结构对其性能进行预测,反之亦然[1-2]。材料的微观图像能够反映材料的内部结构信息,因此,对微观图像的分析是研究材料结构特征的重要手段。传统的材料图像分析工作主要由人工完成,存在效率较低、劳动强度大、准确性不高的缺点, 因此,如果能利用计算机图像处理技术对材料图像进行自动化分析,就能加速材料性能和结构之间关系的研究,对推动材料科学的发展具有重要意义。其中,一个至关重要的问题便是图像的自动分割。计算机自动对图像进行了有效、准确的分割之后,才能进一步测定图像中不同组织结构的各项数据。
边界检测技术是一种很常用的图像分割手段,对于不同区域之间有着清晰实体边界的图像,通过边界检测往往能够取得很好的分割效果; 然而,在很多图像中,不同区域之间很有可能没有清晰的实体边界,这种情况在材料的微观图像中比较常见。如图1所示, 其中,图1(b)三张图像中的白色线条即为不同微观结构区域之间的边界,这些白色线条所标出的边界和传统意义上的边界不同,是没有实体的边界,本文称之为“虚拟边界”(Virtual Boundary, VB)。虚拟边界的检测是对这类图像进行有效分割的关键步骤。
虚拟边界不是简单的直线或某种特定形状,且虚拟边界和区域之间的界线不清晰,有的虚拟边界甚至和区域相连通,因此很难通过现有的边缘检测技术将其准确地检测出来; 另外,虚拟边界并不仅仅存在于微观图像中,在很多宏观的自然图像中也有存在虚拟边界的情况,实现虚拟边界的准确检测也能提高计算机在处理自然图像方面的能力, 因此,如何准确地检测出图像中的虚拟边界是本文研究的重点。

图1 图像中的虚拟边界
针对图像中虚拟边界的检测问题,本文提出了一个基于卷积神经网络(Convolutional Neural Network, CNN)[3-4]的深度学习模型用以检测虚拟边界,称之为“虚拟边界网络”(Virtual Boundary Net,VBN),该模型类似于VGGNet (Visual Geometry Group Net)[5]模型的结构,但是要比VGGNet小很多。本文将虚拟边界检测任务转换为二分类任务,即区分每个像素属于“虚拟边界类”还是“非虚拟边界类”。本文以图像中的每个像素为中心取图像块作为检测模型的输入,模型输出该图像块的类别作为图像块中心像素的类别。在两种具有虚拟边界的材料图像上进行了实验,实验结果证明本文提出的检测模型能够达到较高的准确率。
1 相关工作
边界检测的研究历来已久,相关算法也有很多。边界检测方法的发展可分为三个阶段:传统的基于梯度变化的边界检测方法、基于人工设计特征和有监督学习结合的边界检测方法以及基于深度学习的边界检测方法。传统的基于梯度的边界检测方法主要有Sobel算子、高斯拉普拉斯算子(Laplacian of Gaussian, LoG)[6]、Canny算子[7]等。这类方法主要利用边界附近有明显的灰度变化这一特点来检测边界,在纹理复杂的图像上检测效果不是很好。而人工设计特征则利用了除灰度变化之外,其他更多地表达局部纹理的特征,并结合有监督学习方法来判断像素是否属于边界,比如:Martin等[8]设计了能够反映图像在边界处亮度、颜色、纹理的变化的特征,并使用支持向量机(Support Vector Machine, SVM)结合这些特征构造了一个边界分类器;Dollar等[9]和Lim等[10]提出了一种名为sketch token的特征,并结合随机森林来构建分类器。由于利用了更多的信息,这类方法的检测结果要比传统基于梯度的检测方法好很多,其效果主要受限于人工设计特征的好坏。由于深度学习能够从数据中自动学习特征,并且学习到的特征和传统人工设计的特征相比有更强大的表达能力,近年来有越来越多利用深度学习进行边界检测的研究,比如N4-fileds[11]、 Deepedge[12]和Deepcontour[13]等都是利用CNN来进行边界检测。但是,上述边界检测方法针对的都是区域或物体之间实体边界的检测,目前还未有针对虚拟边界进行检测的相关研究。
针对材料微观图像进行分割的相关研究也有很多,比如:Ananyev等[14]和Lopez等[15]利用形态学滤波的方法对陶瓷图像进行分割;Haha等[16]使用阈值分割法提取陶瓷扫描电子显微镜(Scanning Electron Microscope,SEM)图像中具有不同灰度的微观结构;赵曌等[17]使用谱聚类的方法对陶瓷背散射电子成像(Back Scattered Electron imaging,BSE)图像进行分割,该方法对一些具有复杂纹理的陶瓷图像也能取得较好的分割效果;Chen等[18]对分水岭算法进行了改进,改善了传统方法在陶瓷图像上的过分割问题。同样的,以上这些方法仍然都是针对区域间有实体边界或是区域间有高对比度的图像, 对于图1所示的每个区域间的界线是虚拟边界的情况,这些方法无法进行有效的分割。
2 数据准备
为了对本文提出的深度学习模型进行训练,需要准备训练集和验证集。具体来说,对于每一张图像,首先通过人工的方法将虚拟边界标注出来。然后对属于虚拟边界的每一个像素点,以该像素点为中心,提取一个48×48大小的图像块,作为类别“虚拟边界”的样本;对于其他不属于虚拟边界的像素,则以这些像素为中心提取48×48大小的图像块作为类别“非虚拟边界”的样本。由于图片中属于“非虚拟边界”的像素点个数通常要远远大于属于“虚拟边界”的像素点个数,这样容易造成类别不平衡的问题。为此,本文对属于“非虚拟边界”的样本进行欠采样,使得“虚拟边界”类别和“非虚拟边界”类别的样本数量比例接近于1∶2。具体来说,假如“非虚拟边界”的样本个数为sum1,“虚拟边界”的样本个数为sum2,则在“非虚拟边界”样本集中每隔⎣sum1/(sum2×2)」个样本取一个样本作为新的“非虚拟边界”样本集; 另外,对于处于图像边界附近的像素,以这些像素为中心取48×48的图像块会超出图像的范围, 对此,本文对超出范围的部分以黑色进行填充。图2展示了属于“非虚拟边界”类别和“虚拟边界”类别的样本。
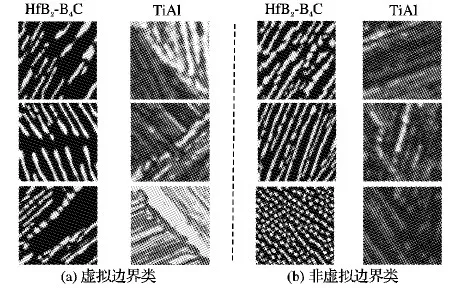
图2 不同类别的图像块
本文在实验中使用的数据集包含两种材料的微观图片,分别是20张共晶HfB2-B4C的图片和20张钛合金TiAl的图片,并分别对两种图片进行处理。对于共晶HfB2-B4C的图片,本文从前15张图像中一共提取了797 693个图像块,其中90%的图像块用来作为训练集,10%的图像块用来作为验证集,并且将第16~20张图片保留作为测试数据。对于钛合金TiAl的图片,本文从前15张图像中一共提取了226 471个图像块,同样将其中90%的图像块作为训练集,10%的图像块作为验证集,并将第16~20张图像保留作为测试数据。
3 VBN的网络结构
3.1 基本定义
本文提出的深度学习模型是基于CNN以及一些改进策略进行构建的,整体结构则是参考了VGGNet模型,并对其进行了简化。在描述模型的整体结构之前,先给出基本的符号解释和定义。
卷积层 卷积层对输入的数据采用线性卷积核进行卷积,如式(1)[19]所示:
(hk)ij=(Wk*x)ij+bk
(1)
其中:k=1,2,…,K;hk是卷积层输出的第k个特征图;i和j是卷积输出的神经元节点在第k个特征图上的索引;x代表输入数据;Wk是第k个卷积核的参数;bk是第k个特征图的偏置; 符号*则代表空间二维卷积操作。
池化层 池化层是一个非线性的下采样层,取输入数据每个局部邻域内的最大值(最大池化)或平均值(平均池化)作为输出。本文模型选择最大池化作为池化层,最大池化能够使特征图对输入数据轻微的扰动保持一定程度的不变性。
全连接层 全连接层是经典神经网络中每一层的组成方式,当前层的每一个神经元节点都是上一层所有神经元节点输出的线性组合,如式(2)[19]所示:
(2)
其中:ym代表第m个输出神经元节点,xl是上一层第l个节点的值,Wml是第ml个权重,bm是第m个输出神经元的偏置。
激活函数 激活函数的引入为深度神经网络添加了非线性因素,使得模型能够解决更复杂的非线性问题。常用的激活函数有sigmoid函数和线性整流单元(Rectified Linear Unit,ReLU)。本文模型采用ReLU作为激活函数,其函数为f(x)=max(0,x)。ReLU激活函数和sigmoid激活函数相比,能有效避免梯度爆炸和梯度消失。
分类层 分类层通常是整个网络的最后一层,计算输入的数据属于每个类别的概率。本文采用softmax函数作为提出模型的分类层。对于输入向量X,其属于第j类的概率P由softmax函数计算得到:
(3)
其中:n是类别数,Wj和bj分别是权重和偏置。
损失函数 损失函数用来在训练模型过程中衡量预测值和真实值之间的差距。本文模型采用交叉熵作为损失函数,其定义如式(4)所示:

(4)
其中:q(x)为输入x的真实概率分布,p(x)为模型对输入x进行预测的概率分布。交叉熵越小说明p(x)和q(x)越接近,这也是整个训练过程的优化目标。
dropout[20]dropout是训练模型过程中采用的一种训练策略,通过在训练过程中随机忽略一部分神经元节点及其对应的参数来提升整个模型的泛化能力。在具体训练中可以通过调整dropout率,即每个神经元被保留的概率来实现。
Adam优化算法 Adam算法[21]和传统的随机梯度下降不同,能自适应地为每个权重选择不同的学习率,收敛速度更快,能有效地改善局部最优问题。
3.2 网络整体结构
图3展示了本文使用的深度学习模型VBN的整个框架结构,一共包括四个阶段。首先模型的输入是一个48×48的单通道灰度图像块。
第一阶段包括两个卷积层和一个池化层,每个卷积层包含64个卷积核,每个卷积核的大小为3×3,卷积步长为1×1,并使用ReLU激活函数。接下来是一个最大池化层,池化模板大小为2×2,步长为2×2。整个第一阶段采用dropout,且dropout率设为0.25。
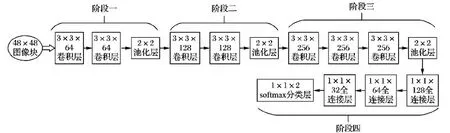
图3 VBN模型的整体架构
第二阶段同样包括两个卷积层和一个最大池化层。此阶段每个卷积层包含128个卷积核,每个卷积核大小为3×3,卷积步长为1×1,采用ReLU激活函数。池化层的模板大小为2×2,步长为2×2。第二阶段的dropout率同样设为0.25。
第三阶段包括三个卷积层和一个最大池化层。此阶段每个卷积层包含256个卷积核,每个卷积核大小为3×3,步长为1×1,使用ReLU激活函数池化层模板大小为2×2,步长为2×2。该阶段的dropout率设为0.5。
第四阶段包括三个全连接层以及最后的分类层。三个全连接层的节点个数依次为128、64和32,均采用ReLU激活函数,最后的分类层采用softmax函数。由于分类任务为二分类,即“虚拟边界”类和“非虚拟边界”类,所以最后的分类层为两个节点。
模型训练时选择交叉熵作为损失函数,并采用Adam优化策略进行模型参数的更新策略。
4 实验与结果
本文使用第3章提出的深度学习模型分别在共晶HfB2-B4C的图片数据和钛合金TiAl的图片数据上训练了虚拟边界检测模型,并且在测试数据集上验证了模型的检测效果。
4.1 模型实现和模型训练
本实验的硬件环境为处理器Intel E5-2620 v4,主频为2.1 GHz;显卡为Nvidia M5000,8 GB显存;内存为32 GB。模型使用python2.7进行编程实现,采用Keras深度学习框架,后端使用Tensorflow。
在共晶HfB2-B4C图片数据上的训练过程分为两个部分:预训练和正式训练。预训练使用的图像块样本是从两张具有较高辨识度虚拟边界的图像中提取的,一共有30 326个图像块,属于第2章提到的15个图像中的797 693个图像块的一部分,而正式训练则是在剩下的767 367个图像块上进行的。预训练和正式训练分别都训练了10轮,但在钛合金TiAl图片数据上的训练过程则没有预训练,直接在第2章提到的15张图像中的226 471个图像块上训练了10轮。
4.2 度量标准
为了衡量模型的检测性能,本文使用了多个度量标准:精确度、召回率、F-score。下面将简单介绍这几个度量标准。首先引入几个符号的定义:TP为样本属于类别C,并且被预测为类别C的个数;TN为样本不属于类别C,并且没有被预测为类别C的个数;FP为样本不属于类别C,但是被预测为类别C的个数;FN为样本属于类别C,但是没有被预测为类别C的个数。
下面是所用到的度量标准的说明。
精确度(Precision)是指被预测为类别C的样本中,真实类别也为类别C的样本占的比例:
(5)
召回率(Recall)是指被正确预测为类别C的样本数占类别C样本总数的比例:
(6)
F-score是一种将Precision和Recall结合的度量标准:
(7)
其中:β用来调整Precision占的比重,实验中将β设为1。可以看出,Precision和Recall的值越高,F-score的值也越高。
4.3 实验结果
对在共晶HfB2-B4C图片数据上训练的模型,本文从保留的第16~20张共晶图片中随机选取5 000个属于“虚拟边界”的像素和5 000个属于“非虚拟边界”的像素共10 000个像素,并以这些像素为中心提取了10 000个图像块作为测试样本。同样的,对于在钛合金TiAl的图片数据上训练的模型,从保留的第16~20张钛合金的图片中随机选取5 000个属于“虚拟边界”的像素和5 000个属于“非虚拟边界”的像素共10 000个像素,并以这些像素为中心提取了10 000个图像块作为测试样本。这两个模型在测试数据上的检测结果如表1所示。图4则展示了部分测试图片的检测结果。
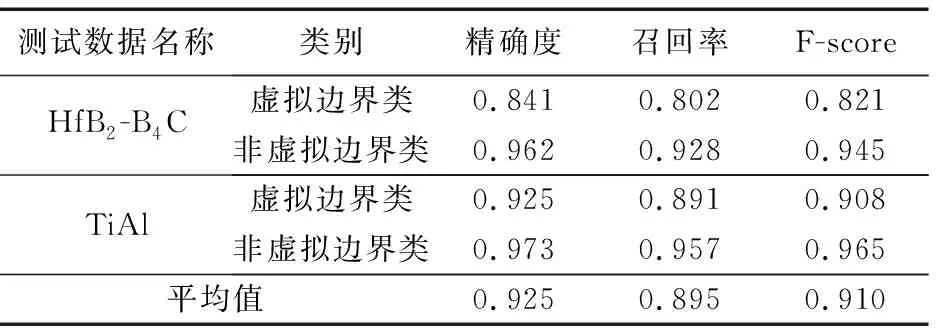
表1 模型在两种测试数据上的实验结果

图4 虚拟边界检测模型在图像上的检测结果
从表1可以看到,模型在两种图像上的平均检测精度和平均召回率以及平均的F-score都在90%左右,检测结果较为准确。结合图4的结果可以看出,模型在共晶HfB2-B4C图片上的检测精度更低的主要原因是该类图片有很多非常细的虚拟边界,反映了模型在检测细小虚拟边界方面存在不足。图4还反映出模型检测的虚拟边界存在不连续的问题,此问题主要存在于图像中虚拟边界不明显的区域。这些问题还有待改进。
总之,本方法在测试图像上都取得了较为准确的检测结果,在一定程度上解决了虚拟边界自动检测的问题,并且由于卷积神经网络强大的特征提取能力,认为本文方法能够很好地适应很大一部分图像的虚拟边界检测任务。
5 结语
针对图像中虚拟边界的检测任务,本文提出一种基于卷积神经网络的检测模型VBN,利用卷积神经网络强大的特征提取能力,实现虚拟边界的准确检测。实验结果表明,本文提出的方法能够达到较高的准确度,并且适用范围广,是一种可行的替代人工分析的手段。考虑到实用性,今后的工作还需考虑像素间的相似性,以对虚拟边界的不连续问题以及模型的检测速度进行优化。
