一种眼病发展趋势的自动预测方法
2018-12-07蒋杰伟刘西洋杨皓庆崔江涛
蒋杰伟,刘西洋,,刘 琳,王 帅,杨皓庆,崔江涛
(1. 西安电子科技大学 计算机学院,陕西 西安 710071;2. 西安电子科技大学 软件学院,陕西 西安 710071)
眼科疾病的发生和发展严重地影响着人类的健康和生活质量.据世界卫生组织统计,到2020年全球盲人数量将达 7 600 万人[1].眼病患者一旦错过最佳治疗时机,将会导致不可挽回的视觉损伤,因此对眼病的尽早诊断和预测是治疗的关键和必要前提[2].特别是,如能精准地预测眼病的发展趋势,将会有效地指导眼科医生规划治疗方案和提醒患者需注意的事项.通常,眼科医生借助裂隙灯图像进行眼病的分类、分级和预测.然而由于优秀的眼科医生严重不足并且区域分布极不平衡,致使一些偏远地区的患者往往得不到及时的诊断.同时,检查裂隙灯图像会耗费医生大量时间,不同医生之间的主观性差异很大,预测眼病的发展趋势还需要医生综合分析过往多次的检查结果,这势必会造成更严重的资源浪费和诊断结果不确定性问题.因此亟需探索合适的计算机辅助预测方法,实现客观的、高效的和自动的眼病发展趋势预测.
随着光学仪器和大数据技术的发展,眼科医院积累了丰富的医疗图像数据,使得借助人工智能方法实现眼病的自动诊断和预测成为了可能.如何准确地从丰富的眼科数据中挖掘出有意义的医疗结论成为当前研究的热点和难点[3].近些年,由谷歌DeepMind团队借助深度学习算法实施了糖尿病视网膜病变的自动诊断和分级[4].文献[5]基于卷积神经网络对裂隙灯图像进行了小儿白内障自动分类、分级和治疗方案研究,并开发了临床辅助诊断软件.文献[6]利用迁移学习和卷积神经网络研究了老年性黄斑变性和糖尿病黄斑水肿等致盲性视网膜眼病.但是,这些已有的研究都是针对已经发生的眼病进行的自动分类和分级诊断,对眼病的自动预测研究需要对患者进行长时间的跟踪和复查,整个过程非常困难,数据难以积累,因此目前还缺少对眼病发展趋势的自动预测研究.利用过往多次的检查结果预测眼病的发展趋势,将会有效地帮助医生规划治疗方案和提醒患者,具有重大的临床意义.
在前期研究基础上,笔者所在团队对上千名白内障眼病患者进行了长达两年以上的跟踪和复查[7],积累了丰富的裂隙灯时间序列图像,为眼病的预测提供了数据基础.白内障主要发生在晶状体区域,但是裂隙灯图像呈现出复杂的表型和大量的噪声.如图1所示,在多个裂隙灯图像上都存在着眼睑和睫毛等噪声,并且晶状体病灶的面积、密度和位置差异也较大.另外,临床上需要手术的严重病例往往较少,大部分是正常的或需随诊的患者,即存在着明显的非平衡数据问题,这些因素给笔者的研究提出了极大的挑战.针对以上问题,笔者首先使用坎尼边缘检测算子和霍夫变换方法[8]预处理裂隙灯图像,提取晶状体感兴趣区域;然后结合卷积神经网络(Convolutional Neural Network,CNN)和时间序列预测模型(Long Short Term Memory,LSTM)建立端到端的模型,抽取图像高层特征和挖掘时间序列特征之间的内在规律,实现对眼病发展趋势的预测;最后,针对非平衡数据问题,在优化目标函数交叉熵损失中加入代价敏感因子,通过调整代价因子的大小,以提升严重病例的预测准确率,从而满足临床上高敏感度的要求.

图1 眼病发展趋势变化示例图
1 实验数据和研究方法
1.1 实验数据
研究中共使用了 1 015 名白内障眼病患者术后的随诊数据,来源于中山大学中山眼科中心的定期检查.在白内障手术后,每个患者需按医学规定的时间定期到医院进行裂隙灯复查.在两年多的跟踪时间内,共进行了6次复查,从而搜集到了 6 090 张裂隙灯时间序列图像.如图1所示,复查的时间共包含6个阶段: 术后第3月、6月、9月、12月、18月和24月.临床上,术后恢复过程中又发生后发性白内障(Posterior Capsular Opacification,PCO)的患者定义为正样本,在复查过程中恢复良好的患者定义为负样本.在 1 015 名患者中,正、负样本的个数分别是367和648个,每一张裂隙灯图像标签都是由3名经验丰富的高年资眼科医生共同讨论来决定的.
1.2 眼病发展趋势预测流程
笔者提出的眼病预测算法流程如图2所示,共包含4个过程:输入图像.按照患者复查的时间顺序对图像进行排序,然后将 1 015 份数据随机划分为5等份,构建训练集和测试集;图像预处理.为了获得感兴趣的晶状体区域,同时最大限度地过滤掉睫毛和眼睑等噪声,利用坎尼边缘检测算子提取图像的边缘信息,然后使用霍夫变换获得晶状体外切圆;最优代价敏感因子搜寻.为了处理非平衡数据问题,笔者在损失函数中加入代价敏感因子,使用网格搜索方法寻找最优代价因子,以平衡敏感度和特异性,获得最佳性能;模型训练和评估.最后对最佳代价敏感因子的模型进行5交叉验证和性能评估.

图2 眼病发展趋势预测算法流程
1.3 基于代价敏感的时间序列预测模型
笔者提出的眼病发展趋势预测模型如图3所示.由图像输入、残差卷积神经网络、长短时记忆网络和预测输出模块组成.除此之外,笔者还使用了迁移学习和数据扩增方法.模型的输入是从第3月到第18月共5个时刻的序列图像,输出是第24月复查图像的标签.序列图像按时间顺序依次输入到卷积神经网络中抽取图像的高层特征;然后使用长短时记忆模型分析时序数据之间的内在规律;最后使用Softmax分类函数来预测眼病发展趋势.代价敏感因子起到了调整正负样本在预测中重要性的作用.

图3 基于代价敏感的时间序列预测模型
残差卷积神经网络主要使用了卷积层、最大采样层、残差连接、块正则化和修正的非线性函数等技术[9].卷积神经网络在视觉竞赛和医疗诊断上表现出了优异的性能[4-6, 10].在前期研究中,笔者使用了包含残差连接在内的卷积神经网络进行了白内障自动诊断和预后评定研究,取得了满意的临床效果[5, 11-12].笔者使用50层的残差连接,该网络具有很强的函数表达能力,从图像像素特征开始层层处理以提取高层特征和降低维度.时间序列处理方法包括递归神经网络和长短时记忆网络,笔者选用长短时记忆网络[13],因为它使用了图3(c)中的连接,解决了长期困扰递归神经网络后向传播优化的梯度消失和爆炸问题.
假设残差神经网络第t时刻抽取的特征为xt,长短时记忆模型前一时刻的隐含状态和记忆单元是ht-1和ct-1,当前时刻的输入门、遗忘门、输出门和输入调制门分别为it,ft,ot和gt,则长短时记忆模型的更新过程为
(1)
其中,⊙代表两个向量的哈达玛积;φ(x)和σ(x)为非线性映射函数,分别为φ(x)= [exp(x)- exp(-x)]/ [exp(x)+ exp(-x)] 和σ(x)= [1+ exp(-x)]-1.当前时刻的记忆单元ct是前一时刻记忆单元ct-1、隐含状态ht-1和当前时刻的输入xt三者的函数.在运算过程中,ft和it起调节作用,使记忆单元ct选择性地遗忘先前记忆单元ct-1和学习新的输入单元xt,从而使长短时记忆模型学习到了复杂的时序关系,达到对眼病发展趋势精准预测的目的.

(2)
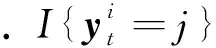
为了获得最优参数θ*,需要最小化损失函数J(θ),即J(θ)对参数θ求偏导,其表达式为
(3)
2 实验结果与分析
2.1 实验环境和评价指标
笔者基于Caffe深度学习框架使用4块英伟达泰坦X图像处理单元进行模型的训练.在每块图像处理单元上设置序列大小为25,从而每次迭代中共有100个序列图像,计算这些样本的平均值来更新待训练的参数.学习率初始设置为0.01,每迭代500次,学习率减少到原值的 1/10,总迭代次数为 2 000 次.这些参数是笔者通过多次实验获得的最佳参数.为了方便其他医疗机构对疾病自动预测的研究和参考,笔者在Github上公开了模型的源代码:https://github.com/Ophthalmology-CAD/CSLSTM-ResNet.
为了充分评估算法的性能,笔者使用以下分类器评估指标: 准确率(ACC)、特异性(SPE)、敏感度(SEN)、精度(PRE)、F1-measure (F1M)、G-mean(GM)和受试者工作特征曲线下的面积(AUC)[11-12],其计算方法为
(4)
其中,TP、FP、TN和FN分别表示真正类、假正类、真负类和假负类的个数.
2.2 裂隙灯图像预处理
由于HSV颜色空间(H为色度,S为饱和度,V为亮度)比RGB空间(R为红色,G为绿色,B为蓝色)更适合以人的视觉系统来感知彩色特性的图像处理算法,笔者首先把裂隙灯图像从RGB空间转换到HSV空间,然后在H和S两个分量上先后进行坎尼边缘检测和霍夫变换.图4是其在正负样本上处理过程的示例图.其中图4(a)是原始图像、图4(b)和图4(c)是在H分量上的坎尼边缘检测和霍夫变换结果,图4(d)和图4(e)是在图4(c)处理基础上对S分量进一步细化的结果,通过H和S两次检测,最终得到图4(f)所示的晶状体分割效果.从图上可以看出,裁剪后的图像排除了晶状体外围大部分噪声的干扰,同时也最大程度地保留了晶状体区域.进一步,笔者使用定量指标(即交并比Iou= (Bp∩Bt)/ (Bp∪Bt))来评价预处理方法的准确性.具体地,从所有数据中随机选择了100张图像,由高年资眼科医生手工标注晶状体区域,以此作为晶状体真实区域Bt,预处理方法得到的区域为Bp,这两个区域交集和并集的比值定义为交并比Iou.通过计算,其平均准确率为82.53%,说明预处理方法是相当精确的,可获得大部分晶状体区域.接下来,笔者把预处理的图像输入到代价敏感的时间序列模型中以预测眼病的发展趋势.

图4 晶状体感兴趣区域自动分割示例图
2.3 代价敏感因子寻优

图5 准确率和敏感度随代价敏感因子变化的曲线
为了满足临床上高敏感度的要求,笔者使用网格搜索的方法对代价敏感因子进行寻优.设置正、负样本的错分代价分别为C和1,对参数C在[1~20]之间以步长1为单位进行遍历,以获得最佳的代价敏感因子.使用这个方法,一共训练了20个模型并对它们进行性能测试,得到了图5所示的准确率和敏感度随代价因子C变化的曲线.从图中可以看出,随着代价因子C的增加,敏感度得到了不断提升; 准确率开始比较平稳,在代价因子大于10之后,准确率急剧下降.在[6~10]区间上,敏感度和准确率两者都达到了较优值(大于87%)且比较平稳,从而得到了代价敏感因子适合的范围.这里,笔者选择中间值8作为代价因子,进行后面详细的对比实验.
2.4 性能对比
为了说明文中所提算法的优势,笔者首先构建了不带代价敏感的时间序列模型来预测眼病的发展趋势;然后在损失函数中加入了寻优后的代价因子,形成了代价敏感的时间序列模型,并对比了两者的性能差异.具体地,使用五交叉验证的方法来计算评价指标的均值和方差,得到了表1所示的结果.从表1的对比中可以看出,虽然无代价敏感模型的特异性较高,但敏感度非常低,仅达到76.74%.在损失函数中加入代价因子后,敏感度指标提升到了88.01%,方差由原来的3.58%降到了0.57%,稳定性较好.同时特异性下降不明显,整体准确率还得到了提升,F1M,GM和AUC指标也得到了不同程度的提升.这充分说明代价因子在模型预测中起到了关键性的作用,可有效地处理医疗非平衡数据集问题,满足临床高敏感度的要求.
进一步,笔者探索了用代价敏感时间序列模型预测不同长度序列数据的鲁棒性和稳定性.在交叉验证中,对测试的数据分别以长度2、3和4为单位进行截断重组,形成另外3组测试数据,其预测的标签分别是第3、4和5时刻复查图像的诊断结果.把这3组数据输入到模型中,以衡量模型对不同长度数据预测的能力,得到了表2所示的对比结果.经过分析,笔者得到了以下的结论:模型对长度为5的序列预测性能是最优的,对长度为2的序列预测最差;随着序列长度的减少,预测性能是逐渐递减的;当序列长度为3和4时,其准确率、特异性和敏感度指标都在80%以上,同时方差也较小,可以满足临床预测要求.

表1 不同预测算法的性能对比

表2 模型对不同长度序列数据的预测性能对比
综合而言,笔者提出的算法可同时对长度为3~5的序列图像进行预测,其鲁棒性和稳定性较好.
2.5 临床应用
目前,眼病发展趋势的自动预测系统已经在中山大学中山眼科中心临床使用,辅助眼科医生监控和预测白内障患者的恢复情况.在半年多的临床应用中,其运行效果良好.
3 结 束 语
笔者提出了一种眼病发展趋势的自动预测方法.该方法在坎尼边缘检测算子和霍夫变换预处理裂隙灯图像基础上,使用残差卷积神经网络提取晶状体病灶区域的高层特征;然后使用长短时记忆网络分析时间序列特征之间的内在规律,进而实现对眼病发展趋势的预测;最后在优化目标函数交叉熵损失中加入了代价敏感因子,有效地处理了医疗非平衡数据问题,实现了临床高敏感度指标的要求.实验结果验证了笔者所提算法的有效性和稳定性,可高准确率地预测眼病的发展趋势,同时为其他疾病的预测起到了借鉴作用.
