基于关联规则的地方高校专业课程设置方法研究*
2018-12-07胡延雪怀丽波张振国崔荣一
胡延雪,怀丽波,张振国,崔荣一
(延边大学 计算机科学与技术学科 智能信息处理实验室,吉林 延吉133002)
一、引言
高校中的教学管理系统一般包括人才培养方案制定、学籍管理、课程编排、考试管理、成绩管理、毕业管理等相关模块,其中课程编排是一个重要环节。合理的课程编排方案不仅有助于学生保持良好的学习状态,也能极大地提高教学质量,达到事半功倍的效果。
目前,在教学管理系统中总会积存大量的学生历史数据,而通过传统的数据分析工具分析这些数据得出的结论总是很浅层的,数据信息不能充分发挥自身价值。随着数据挖掘技术的快速发展,其已被广泛应用在商业、金融业、电信业等各个行业,并取得了一定的成果,但在教育事业方面的应用并不多。[1]同时,从地理环境、生源情况以及专业特色等各方面来分析,不同高校的教学管理体制会具有自身鲜明的特色。因此,结合成熟的数据挖掘技术研究高校的教学课程设置有利于发现该高校的课程特色,也能进一步分析出学生的学习状态,可以因地制宜地调整人才培养方案、制定合理、高效的课程方案。
文中主要采用经典关联规则Apriori算法对高校的计算机专业学生的历年专业课学习成绩进行挖掘,根据获得的规则确定出各课程在该专业上的重要性,找出专业课程之间的相关性,进而分析目前的课程设置是否合理。
二、相关算法理论概述
1.关联规则简介
关联规则挖掘是数据挖掘技术中一种重要的分析方法。数据挖掘是从大量的、不完全的数据中提取出潜在有价值的信息和知识的过程。[2]常用的挖掘方法主要包括:关联规则挖掘、相关性分析、时序分析、分类、聚类等。[3]
关联规则最初被提出的动机是商家要了解消费者的购物习惯,根据“购物篮分析”得来的。[4]关联是指某种事物发生时其他事物也会发生的一种联系。关联规则的描述为:设 I={i1,i2,…,in}是项的集合,D 是事务的集合,每个事务T是某些项的集合,即T哿I,关联规则是形如A圯B 的蕴涵式,其中 A奂I,B奂I,并且 A∩B=覫。表示事务A与事务B的某种相关性,由支持度和置信度决定。
定义1支持度:规则A圯B在事务D中成立,具有支持度support。其中support是D中事务包含A∪B的百分比,即 A∪B发生的概率 P(A∪B),如公式(1)所示。
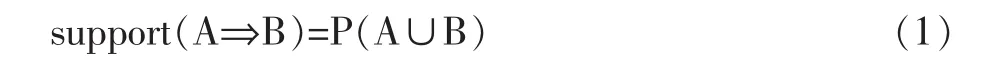
定义2置信度:规则A圯B在事务集D中具有置信度confidence,其中confidence是D中包含A的事务同时也包含B的百分比,即条件概率P(B|A)。如公式(2)所示。

关联规则挖掘有两个阶段,第一个阶段是收集数据,从数据库中找出所有的K-项频繁集,频繁项集是指项集支持度满足预定义的最小支持度阈值;第二个阶段就是由频繁项集产生关联规则,利用前K-项频繁集组产生关联规则,若规则满足最小置信度则称该规则为关联规则。
2.经典Apriori算法理论
Apriori算法是1993年由Agrawal等人提出的最早基于频繁项集的经典关联规则算法[5],包括寻找频繁项集和寻找强规则两部分,核心是寻找频繁项集,包含连接、剪枝两步操作。[6]
Apriori算法的基本思想是多遍扫描数据库D找出全部频繁项集,从1-项频繁集开始,递归地产生2-项频繁集、3-项频繁集,如此下去,直到产生所有的频繁项集。Apriori算法的重要性质是频繁项集的所有非空子集也是频繁的。算法实现流程如图1所示。
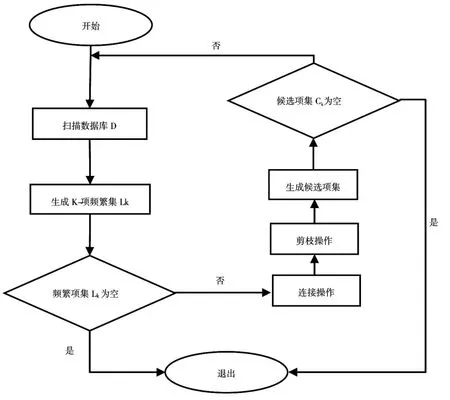
图1 Apriori算法流程图
主要实现步骤如下:
(1)首先找出所有频繁1-项集,记为L1;
(2)连接、剪枝:找出潜在的频繁2-项集记为C2,结合算法性质对C2中的项集判定,再挖掘出频繁2-项集的集合L2;
(3)重复上一步骤直到无法发现更多的频繁k-项集为止。
最后,利用频繁项集构造出满足最小置信度的规则。
经典的Apriori算法易于理解和实现,但当数据库太大时,算法的时耗太大,效率较低。因此很多学者都在进行Apriori算法改进的研究,在文献[7]中提出了一种并行化改进算法Apriori-TMC,将事务数据库转换成布尔矩阵,通过压缩事务数据库有效降低了时间复杂度。文献[8]中提出了基于MapReduce计算模型的Apriori算法以提高大量数据的候选集生成效率。文献[9]中提出了基于前缀项集的候选集存储结构,并用哈希表的快速查找优势,使得Apriori算法在连接和剪枝步骤的效率大大提高。
三、基于关联规则的课程拓扑排序
目前,高校中的课程体系存在课程之间的衔接和关联考虑不够的问题,使得课程之间的内容不能相互融合,学生难以形成对专业全面的、系统的认知[10-11]。
通过挖掘课程之间的关联规则来进行课程的拓扑排序,一般选择以学生的成绩数据为研究对象。对成绩数据进行挖掘分析,找出课程之间的相关性,根据结果指导优化课程的拓扑排序[12-13]。一般获取的原始成绩数据如表1所示。
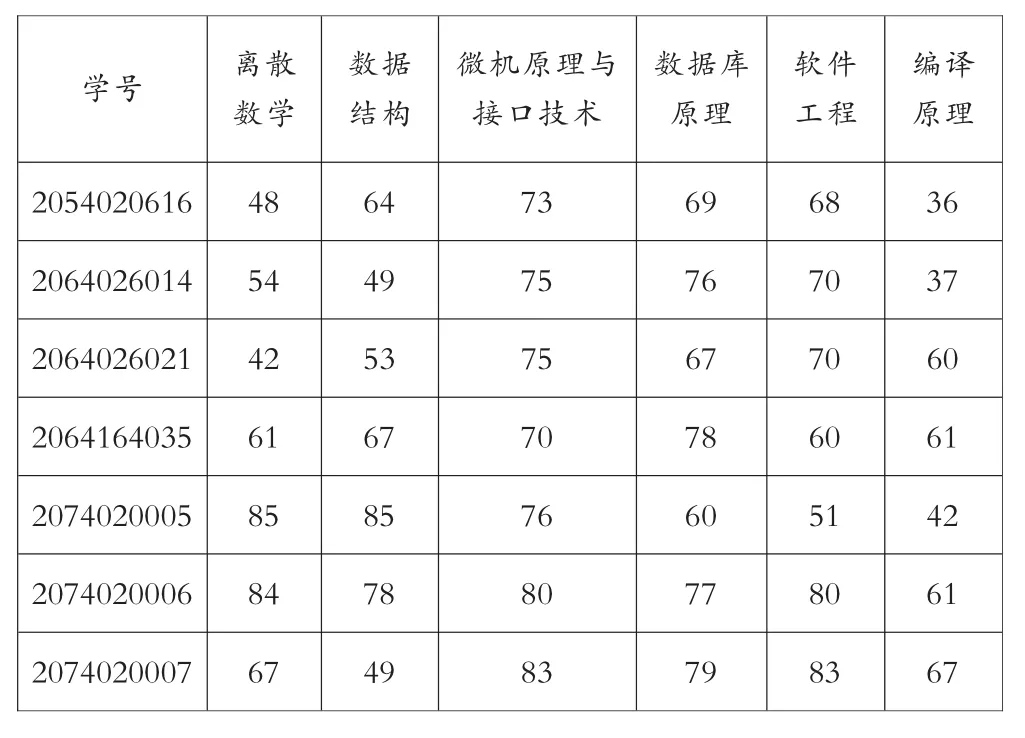
表1 原始的数据表
从表1可以看出,一条记录即代表了一个事务,并且表中含有大量的属性-值,如 “离散数学-96”、“数据结构-91”等,这些属性对完全相同的概率非常低,如果直接对数据进行挖掘,结果会不理想,所以需要对原始数据相关属性进行数据预处理。数据的预处理包括数据集成、数据清理、数据归约等步骤。
数据集成是将来自多个数据源的数据规范整合处理的技术和过程,可以快速锁定预处理的对象范围。学生成绩数据一般是按照学期存储在数据库中的,所以在数据预处理时,因此需要将待挖掘的课程成绩数据集成在一起,在集成时应去除“学分”、“学号”等挖掘过程不需要的冗余字段。
数据清理是对事务数据库中的空白、重复、噪音和不一致的数据进行处理。由于学生退学、休学、缺考等原因造成绩数据空缺和重复情况的,应考虑去除这些数据或采取课程平均分进行数据的填补。而补考、重修导致数据的重复,应考虑保留原首次成绩,以达到正确的挖掘结果。
数据归约通过概念分层和离散化等方法减少分析数据的规模,提高数据挖掘的效率,但不影响最终的数据挖掘结果。数据的离散化可以采取多种不同的方式,可将成绩数据按人数比例进行划分等级,也可以采用以每一门课程的平均分为划分基准,将成绩划分为不同的等级,这样成绩数据便进行了概念分层,为了简化分析过程,同时需要对课程名进行编号设置,依次以A、B……M等字母进行标记。
课程项集即{A、B、C......M},由课程字母与等级标识值组合成新的元素,由这些元素构成的不同集合即代表事务,通过关联算法进行挖掘获得课程之间的强规则,对获得的强规则进行分析,进而安排课程,实现课程的拓扑排序。例如A=>B,B=>C,说明课程A的学习情况对课程B的学习产生极大的影响,同理课程B又对课程C存在影响,那么课程的安排顺序为A-B-C时是最合理的,可以提高学习的效率。
四、实验结果与分析
实验的研究数据来源于延边大学教务系统,选用了计算机专业2007级和2008级共96名学生的专业课程成绩。实验以Eclipse环境为平台,用Python作为开发语言,采用经典Apriori算法对预处理后的数据进行挖掘。
在学生成绩表中,有很多字段是挖掘过程不需要的,在课程上只对《离散数学》、《数据结构》、《软件工程》等专业课程进行数据分析,因此保留学生的编号、专业课程名和成绩信息,其余字段采用删除冗余数据的方法进行去除,针对空缺值采用课程平均分进行填补。最终确定总共有13门课程用于数据的挖掘。其中,课程编码对应表如表2所示。
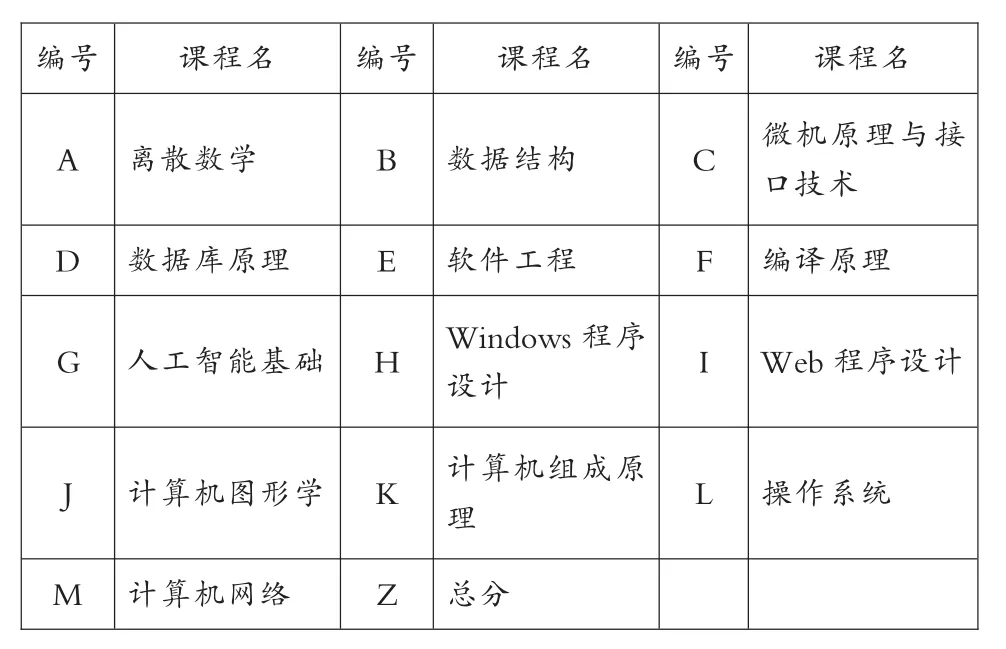
表2 课程编码对应表
实验中采用人数比例划分成绩数据,按从高到低划分为等级 1、等级 2、等级 3,人数比例为 1∶1∶1,即不同的课程有三个不同层次的成绩等级,有利于进一步挖掘。通过数据预处理,便可以获得一个较好的数据集,如表3所示。

表3 离散化数据表
将离散化后的数据导入Mysql数据库中。实验中多次输入阈值进行测试对比后,确定设置最小支持度20%,最小置信度为70%时显示的规则效果最好,获得的科目信息比较完整,能反映出各专业成绩间的关系,得到的部分强规则如表4所示。

表4 关联规则
获得的置信度越高,说明重要性越高,规则越重要。
首先,从获得的结果如 “E1=>Z1 ”、“C1=>Z1”、“B1=>Z1”等规则,分析可知《软件工程》、《微机原理与接口技术》、《数据结构》、《离散数据》、《人工智能》、《数据库原理》、《计算机图形学》、《操作系统》等课程在计算机专业中比较重要,往往这些课程学习得好,总评也会比较好,所以在学习中应注重这些课程的学习,有利于提高专业技能,另一方面,在设置课程学分时,可适当提高这些课程的学分权重,可以更合理地选拔出优秀学生。
其次,从获得的规则中可以得知课程的安排合理性,例如从“L3=>J3”和“J3=>M3”两个规则我们可以推测出操作系统学习成绩为中,那么计算机图形学课程成绩也很可能为中。如果《计算机图形学》课程的学习效果还行,那么计算机网络课程也就可以顺利掌握了。由此可知,在课程安排时,应按照“操作系统-计算机图形学-计算机网络”这样的顺序来安排课程比较合理,循序渐进,可以有效地提高学生的学习效率。又如“C1=>D1”、“D1=>H1”、“H1=>G1”等可推出“微机原理与接口技术-数据库原理-Windows程序设计-人工智能”这样的排课顺序。根据获得的多条规则就可以对比原始的课程设置表,进行调整和改进。已知原始课程如表5所示。
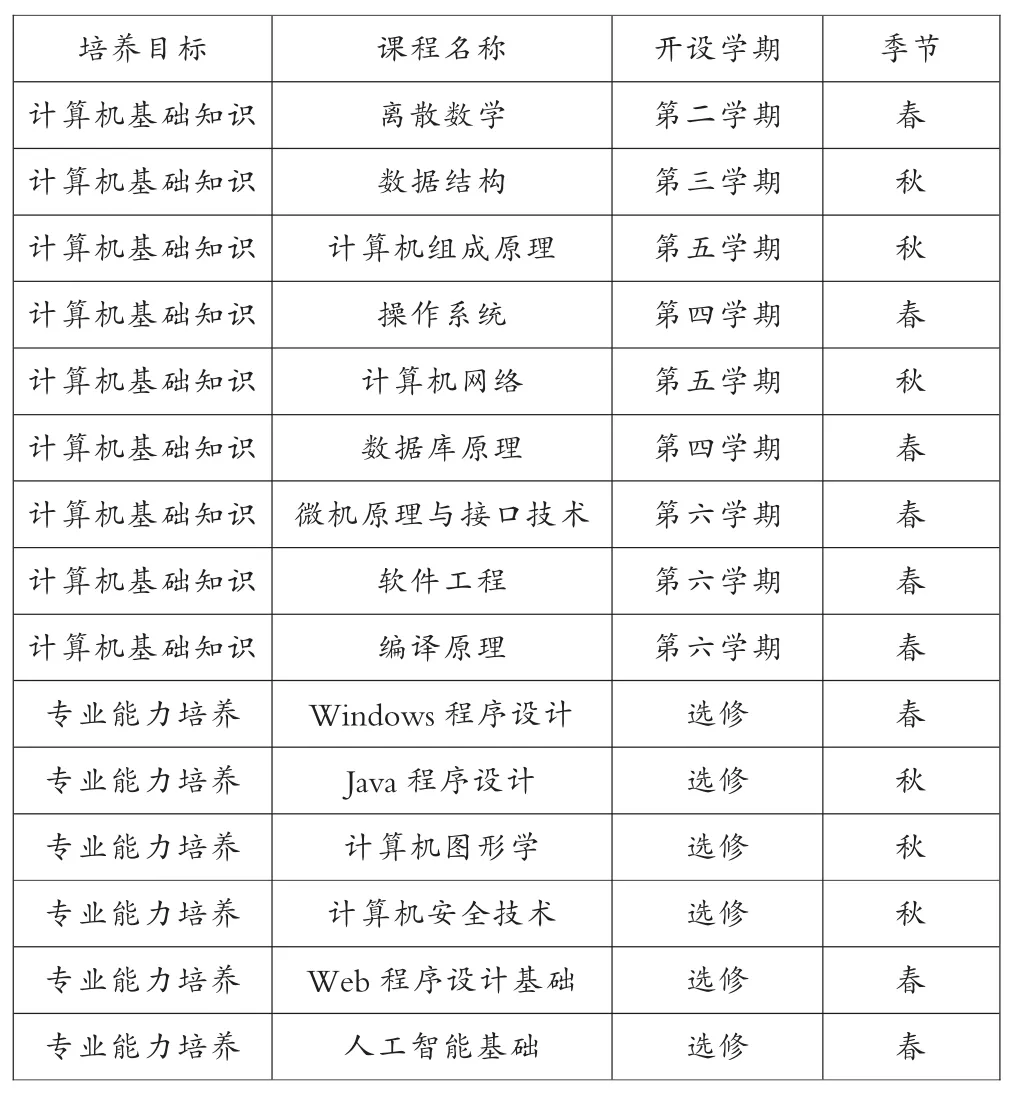
表5 原始课程安排表
对照表4和表5,可知《操作系统》、《计算机网络》等基础专业课程的安排还是比较合理的,而针对《计算机图形学》、《Windows程序设计》等选修课,可以适当安排到前几个学期,不需要将选修课程集中在某一两个学期,可以适当分散开,只要先行课程学习后,就可以安排选修课程的学习,这样可以充分利用时间,也可以兼顾学习的效率。
五、结束语
本文通过收集高校计算机专业学生的专业课程成绩数据,用经典的Apriori算法找出课程与课程之间的相关性,为计算机学科专业课程设置的合理性进行了客观分析。但由于经典Apriori算法的固有缺陷,获得的部分规则存在冗余,如A=>B,B=>A,这样的规则对于排课方案没有太大的指导作用,所以下一步需研究改进Apriori算法,限定规则的产生条件,去除不必要的规则,提高算法的效率。
