大数据背景下的机器学习算法应用研究
2018-12-05童莲
童莲
(江苏海事职业技术学院,江苏 南京 211199)
1 引言
大数据(Big Data)又称为巨量资料,指需要新的处理模式才能具有更强的决策力、洞察力和流程化能力的海量、高增长率和多样化的信息资产。大数据概念最早由维克托·迈尔·舍恩伯格和肯尼斯·库克耶在编写《大数据时代》中提出,指不用随机分析法(抽样调查)的捷径,而是采用所有数据进行分析处理。大数据有4V特点,即Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)。小数据时代的样本为随机取样,用最少的数据获得最多的信息,而大数据时代的样本为总体数据。比如谷歌公司曾经通过分析整个美国几十亿条互联网检索记录预测流感趋势。对于小数据而言,最基本、最重要的要求就是减少错误,保证质量。比如追求更高精度的对时间、空间的测量。大数据允许不精确,放松了容错的标准,人们可以掌握更多的数据,利用这些数据做更多新的事情。如今采集和存储数据的数量和规模已经爆发式地增长,如何分析并利用这些数据是摆在众人面前的一道难题。
机器学习和数据分析是将大数据转换成有用知识的关键技术[1],并且有研究表明,在很多情况下,处理的数据规模越大,机器学习模型的效果会越好。因此,机器学习是大数据智能化分析处理应用中的重要手段。本文通过阐述机器学习算法的实际应用,探索如何利用海量数据。
2 机器学习算法背景知识
机器学习的定义可以理解为:如果一个“程序”可以在“任务T”上,随着“经验E”的增加,“效果P”也可以随之增加,则称这个程序可以从经验中学习。
机器学习的经典算法主要有五种类型,分别为:聚类算法、分类算法、回归算法、关联规则算法、降维算法[2]。机器学习又可以分为三类:监督式学习,非监督式学习,强化学习[3]。监督式学习需要提前进行数据分类,非监督式学习着重于挖掘规律,强化学习需要通过试错去找到解决方案。
以垃圾邮件分类为例阐述机器学习的定义:
一个程序:机器学习算法,比如回归算法;
任务T:区分垃圾邮件的任务;
经验E:已经区分过是否为垃圾邮件的历史邮件,在监督式机器学习问题中,这也被称之为训练数据;
效果P:机器学习算法在区分是否为垃圾邮件任务上的正确率。
3 机器学习算法的应用
经典的机器学习算法在应用时,可以分为三个步骤:特征维度提取[4]、特征模型建立、模型融合。特定领域的模型融合完成后,即可用来分析该领域的大数据,获取有用信息。
3.1 特征维度提取
所谓特征,通俗地讲,就是从这些“以前的数据”中提取出来的对于分类预测有价值的变量。比如电影、电视剧分类,书籍分类,垃圾邮件分类,动植物分类等。从维度上可以分为一维分类、二维分类、多维分类。
一维分类如图1所示,只需设定一个阈值,即可将数据分为A类和B类。
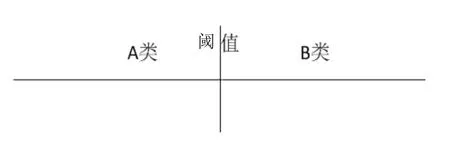
图1 一维分类
二维及以上的分类,通常采用欧几里得度量(euclidean metric)(也称欧氏距离)。这是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维及以上空间中的欧氏距离就是两点之间的实际距离。
二维空间的公式如式(1)所示:

三维空间的公式如式(2)所示:
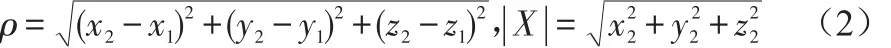
二维分类最终结果如图2所示:

图2 二维分类
维度越多意味着特征越多,需要处理的数据量级越大。在特征抽取的过程中,可适当去掉相关度不大的特征,将更少的特征应用于机器学习流程,即所谓的降维[5]。
3.2 模型建立
有了特征之后,我们要通过各种模型建立从特征到目标之间的关系。一个性能优良的模型,依赖于相关度大的特征的集合。如果我们针对的是一个预测问题,例如成绩排名的预测,我们通常把单个模型叫作一个预测器;如果我们针对的是一个分类问题,例如把在银行贷款的中小企业分为低违约风险和高违约风险两类,我们通常把单个模型叫作一个分类器。这样的模型可以是来自某种专家系统,或者把专家的知识翻译成模型,比如银行的风险控制专家的很多知识,都可以直接转变为模型。
模型在使用之前必须经过训练,模型训练过程中可能出现过拟合[6]、欠拟合两种情况,通过调整模型的特征维度个数,最终达到模型适中的目标。所谓过拟合(over-fitting)其实就是所建的机器学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。而欠拟合(under-fitting),则是在训练集上的判断准确率效果不佳。过拟合即特征维度过多,训练过程中需要减少特征维度;而欠拟合则是因为特征维度过少,需要增加特征维度。
过拟合、欠拟合、模型适中三种情况如图3所示:
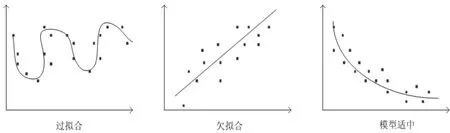
图3 模型训练三种情况
3.3 模型融合
单一模型的预测和分类结果往往不尽如人意,因此把每一个模型都叫作一个弱预测器或者弱分类器。当我们有了成千上万个模型后,我们就可以通过把这些模型融合起来,获得更好的预测或者分类效果,例如分类模型;针对每一个待分类样本,把每一个模型得到的结果都看成对这个样本分类结果的一次投票,最后根据得票高低确定最终分类结果,投票结果经常胜出的模型会被赋予更大的权重。
比如有两个模型:客户信用度评估模型1、客户信用度评估模型2,在模型融合时占有的权重,依据它们将客户特征维度进行的每一次分类结果所得的投票数。成千上万个模型融合时,各自所占的权重也是依据每一次分类所得的投票数。
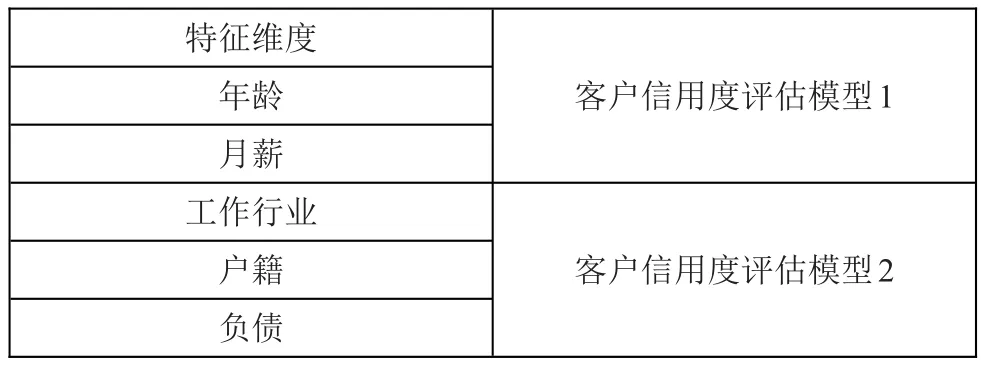
表1 模型融合
因为融合的方案较为固定,所以我们只需要维护特征库和模型库,而所有新的数据以及新的专家知识和专家系统,基本上都可以映射为对特征库和模型库的更新,包括对特征权重的修正。尽管专家知识和专家系统对于特征的选择和赋权,以及模型的建立都有作用,但实际上,即便没有任何专家知识和专家系统,仅仅通过一般化的特征学习和常用的机器学习模型,也能得到很不错的结果。这就使大规模数据下的机器学习,可以看作具有一般意义的解决方案。
4 结论与展望
目前,大数据技术已经在多个领域得到广泛应用,大数据技术的发展依赖于机器学习的进步。本文阐述了机器学习算法在一般领域应用的三个步骤,也为商业解决方案提供了参考依据。
未来机器学习的研究离不开软件和硬件的共同发展,提升机器学习算法并行性、降低算法复杂度是软件亟待解决的问题,而CPU+GPU混合计算则是硬件研究的方向。云计算、大数据、人工智能等关联学科的融合发展,更能为机器学习的研究增加助力。
