基于Spark的多阶空间权重矩阵STARIMA交通流预测分析方法*
2018-12-05李欣
李欣
(河南财经政法大学中原经济区“三化”协调发展河南省协同创新中心∥河南财经政法大学资源与环境学院,河南 郑州450046)
近年来,随着中国城市化率的提高,人口不断向城市聚集,各种城市管理问题不断出现,其中交通拥堵问题是一二线城市普遍存在并愈发严重的重要问题。因此,在加大城市基础设施建设投入的基础上,还迫切需要利用新的技术手段和数据资源,优化管理水平,提高管理能力,缓解交通拥堵问题。利用大数据和空间信息技术建立智能交通管理系统,可以有效利用通信、传感、控制和信息技术,将海量交通流数据中隐含的信息提取出来,更加实时、准确、高效的进行车辆优化管理和诱导,是当前空间信息技术领域的一个热门研究方向。
目前,已产生一些大数据和空间信息技术结合的研究成果。利用分布式技术管理空间信息数据方面,如MapReduce框架下的空间数据管理方法[1-4],基于关系型数据库的分布式空间数据管理系统等[5-8]。其在效率方面较传统空间数据管理方法有一定提升,但其计算框架和结构本身还有一定缺陷,如MapReduce的频繁读写和任务调度问题,关系型数据库的延时高、字段扩展能力差问题等。因此需要进一步运用新的框架提高效率完成智能交通管理任务。交通流预测分析方面,较为成熟的模型包括神经网络模型[9-10]、历史平均模型[11]、状态空间模型[12]、时间序列模型[13]等,一些学者在此基础上也进行了一些优化改进[14-24]。以上研究虽然实现了交通流预测的基本功能,但应用条件限制较多,对于交通流在路网中的时空相关性考虑不够充分,分析结果与真实运行状态存在一定差距,而且交通流数据正随着通信、传感等技术的进步实时海量增长,这也对数据处理效率提出了更高的要求。
本文拟在Spark[25-27]架构基础上,利用分布式空间数据库对城市多源传感器采集的交通流大数据进行高效处理和管理,设计并利用时空自回归移动平均模型STARIMA (Space-time Autoregressive Integrated Moving Average)模型[28-32]中的多阶空间权重矩阵模拟交通流在路网中的时空相关性,使用已有交通管理平台采集的交通流数据进行分析实验,建立更加可行准确的交通流预测方法,为下一步建设城市智能交通管理平台提供理论依据。
1 交通流预测分析总体框架
基于Spark的分布式交通流预测分析总体框架如图1所示。

图1 分布式交通流预测分析总体框架Fig.1 Distributed traffic flow prediction analysis framework
总体框架分为分布式运算节点和中心管理节点2个层次:
1)分布式运算节点。利用Shark作为数据仓库对交通流数据进行分布式存储,使用高效的Spark作为计算引擎,将数据处理时的查询语句转换为Spark上的弹性分布式数据集(RDD)操作,通过RDD进行交通流大数据清洗和统计内存运算。相对于MapReduce方法,此方法的优点在于使用高速内存存取取代低速磁盘I/O操作,有利于分布式系统整体运行效率的提升。
2)中心管理节点。利用HDFS和空间数据库结合的方式管理经过清洗统计后的交通流中间数据集,通过用户自定义函数UDF实现高效空间数据查询,基于用户语义查询结果使用交通流预测模型进行计算,最终生成阶段性预测结果。
2 交通流预测分析相关关键技术
2.1 分布式节点中的数据处理方法
多源传感器采集的交通流大数据和其他类型的大数据一样具备4V的特点,要对其进行预测分析,则必须利用最为高效的方式完成数据的采集、清洗、统计和存储。
2.1.1 基于Spark的交通流数据清洗 利用多源传感器采集到的交通流数据可以通过有线或无线网络传输至分布式节点进行存储和管理。而由于设备、网络、信号等因素的影响,采集到的数据可能包含大量冗余、无效或错误数据,即“脏数据”。因此,必须对此类数据进行清洗修正,才能保证后续预测分析的准确性。
本文设计了基于孤立点检测算法的交通流数据清洗规则,在Spark框架下完成对交通流数据集的清洗,其步骤如图2。

图2 交通流数据清洗步骤Fig.2 Traffic flow data cleaning steps
孤立点检测算法的优点是清洗效果较好,对冗余、无效和错误类型的“脏数据”的识别率达90%以上,但其缺点是运算复杂度较高,对于持续增长的海量数据效率较低。因此本文根据交通流预测分析的特点,将传感器采集的交通流数据按照时间周期进行缓存,并利用Spark将其转换为RDD,在分布式运算节点上部署运行孤立点检测算法,可以有效减少单个清洗算法处理的数据量,减轻运算压力,可以在一定程度上弥补此算法复杂度较高的缺陷。在清洗过程中,由于需要对每一条数据记录进行遍历检测,因此检测同时即可完成信息统计,为交通流预测建立基础。
2.1.2 并行交通流数据注册与存储 由于交通流数据分布式存储在网络中的不同节点,而且数据记录数量庞大,因此为了实现高效数据访问,需要创建并行服务,对数据进行负载均衡处理,并在元数据库中对各个分布式节点的数据进行分区注册,以此实现海量交通流数据的快速访问和提取。此方法的优点在于可以减轻分布式节点的访问和存储压力,减少节点故障产生的损失。
图3为并行数据存储与注册流程图。首先依据城市交通网各个路段所处空间位置,以及对应的交通流数据量设置负载均衡分配规则,交通流数据进行清洗处理后,按照分配规则传输至对应分布式节点进行存储,分配和存储过程由分布式节点并行执行,同时对本节点的元数据信息进行更新。在中心管理节点创建数据分区元数据库,内容包含数据空间范围、时间范围、传感器类型和数据规模等,各个分布式节点的元数据信息按照时间周期发送至中心节点元数据库进行存储。

图3 并行数据存储与注册流程Fig.3 Parallel data storage and registration process
大数据环境下,节点故障被视为常态,因此为保证系统稳定运行,必须对数据进行镜像和备份。目前数据复制技术已较为成熟,本文所使用的方法是在各个物理节点构造多个虚拟节点,并存储不同数据集,再对不同物理节点上的虚拟节点进行相互镜像备份。在系统运行过程中,可使用节点探测机制进行扫描,并将更新的节点状态信息发送至客户端,如节点状态正常则从元数据库中提取分区信息并访问数据,如状态异常则自动将数据源切换至镜像备份节点。
2.2 中心管理节点中的查询预测方法
2.2.1 分布式交通流数据语义查询 Spark框架使大数据应用的计算效率得到较大提升,但框架本身并未实现地理信息应用相关的空间查询功能,因此必须空间查询通过自定义函数UDF实现,以完善系统功能。同时,分布式应用的查询功能多为模糊查询或语义查询,需要对查询语句进行解析,将其分解为针对各个分布式节点的查询任务,待分布式节点完成任务后,返回查询结果。图4是基于语义的空间查询流程图。
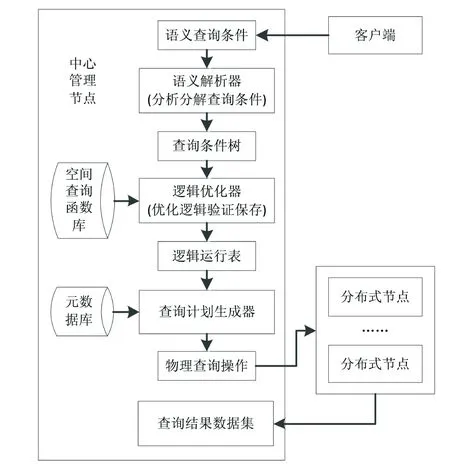
图4 基于语义的空间查询流程Fig.4 Spatial query process based on semantics
分布式交通流数据语义查询流程如下:① 客户端输入语义查询条件。② 由语义解析器完成查询条件分析,将其拆分为基本查询单元,对查询单元进行逻辑排序,生成查询条件树。③ 由逻辑优化器完成查询条件树基本单元和已注册的空间查询函数匹配,对冗余或失效的查询单元进行优化调整,生成查询条件逻辑运行表并验证保存。④ 由查询计划生成器遍历各个分布式节点的元数据信息,结合逻辑运行表,将实际查询操作分解为分布式节点的物理查询动作,并交由分布式节点执行。⑤ 分布式节点完成查询之后将结果返回中心管理节点,并合并为查询结果数据集。
2.2.2 基于多阶空间权重矩阵的STARIMA交通流预测方法 通过语义查询可以快速海量数据中将符合时空与属性查询条件的交通流数据提取出来,根据需求对目标区域使用预测算法进行分析。城市道路网络的拓扑关系反映了各个路段之间的连通关系,任意两路段之间的关系一种是在某路口直接邻接,另一种是通过多条其他路段和路口间接邻接。由于车辆在典型十字路口存在直行、左转和右转三种情况,因此交通流在某路口的分配关系即为该路口在某方向上的转弯率,在最短路径即为车辆运行路径条件下,可以使用路径上n个路口的多阶转弯率体现上下游路段的空间相关性。图5为上下游路段中交通流方向示意图。
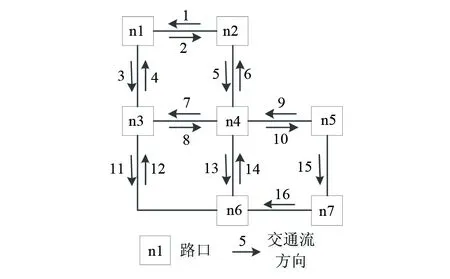
图5 上下游路段中交通流方向示意图Fig.5 Traffic flow direction in upstream and downstream of the sections
此时可以使用以下公式表达上下游路段的时空相关性。设上游路段i到下游路段j的最短路径为Rij={li,l1,l2,…,ln-1,lj},当前交通流预测分析时间周期为[k,k+1],则路段i与路段j之间的时空相关性表达式为:
rij(k)=θij(k-1)
(1)
(2)
公式(1)中的rij(k)为路段i和j直接邻接时的时空相关性,θij(k-1)为前一周期内由i到j的路口转弯率。
通过公式(1)和(2)可以看出,由于路口转弯率θ≤1,因此中间路段越多,重分配阶数越多,上下游路段之间的时空相关性越小。通过实验,2阶以内上游路段分配至下游的交通流量较多,其时空相关性也较高,而3阶以上路段在路网中的复杂性较高,计算量较大,不但会耗费更多的运算时间,其相关性也较低,因此忽略不计。
通过以上分析,本文利用公式(1)和(2)对时空自回归移动平均模型STARIMA的空间权重矩阵进行赋值,用于体现路网中的交通流在时空上的相关性,并用此模型进行交通流预测,STARIMA模型公式如下:
(3)
公式(3)中,Z(t)表示t时段内的交通流量向量,k为时间延迟;h为空间间隔;p为时间自回归延迟;q为移动时间平均延迟;mk为第k个时间自回归项的空间间隔,nl为第l个时间移动平均项的空间间隔;φkh为时间延迟为k并且空间间隔为h的自回归参数,θlh为时间延迟为l并且空间间隔为h的移动平均参数;ε(t)为随机误差;W(h)为h阶空间权重矩阵。
依据空间权重矩阵W(h)的限制条件,本文定义的矩阵元素表达式为:
(4)
使用此模型进行预测分析时,输入项为经过采集、清洗和统计得到的某时间周期内分析区域的路段交通流量信息,经过基于多阶空间权重矩阵STARIMA模型分析,可输出下一时间周期各个路段的交通流预测值。此空间权重矩阵在道路拓扑关系的基础上,更加准确的体现了多阶交通流分配规律,因此可以在一定程度上提高交通流预测分析的准确性。
3 实验与分析
3.1 实验数据与运行环境
本文数据来源为智能交通综合管理平台,它已在河南省部分地市实现了交通指挥、联网监控、流量监测、车辆诱导等子系统。其中郑州市运营系统中,利用了地磁、微波、视频和车辆GPS进行交通流数据采集,运营至今数据日均增量约2 000万条,累计数据量230亿条。本文选用2016年12月5-18日郑州市郑东新区龙子湖高校园区路网数据进行实验,该园区由15所高等院校组成,占地面积约22 km2,湖心岛规划有为高校配套服务的商场、超市、宾馆等公共设施和学术交流中心、大型图文信息中心等公益性设施,此区域内交通流量稳定,适宜进行预测分析实验。
实验设备为5台服务器,中心管理节点1台,完成分配数据处理任务,整合数据处理结果,预测交通流周期变化等工作。分布式运算节点4台,完
成交通流数据分布式采集、清洗、统计、存储任务。各个节点所使用服务器配置相同,为Intel XeonE5-2640 2.6 GHz,8核,16 GB内存。
3.2 交通流大数据处理实验
交通流数据通过多源传感器采集实时海量增长,因此必须验证对其进行处理的效率是否可以满足预测分析的需要。
以往的成果表明,15 min为进行交通流预测较为合适的时间周期,因此必须在15 min内完成对上一周期采集数据的清洗和统计工作。按照运营系统中日均2 000万条交通流数据计算,15 min内的数据量约为21万条,考虑到交通高峰时段的数据量可能达到平均数据量的2倍即42万条左右,以及系统的可扩展性,交通流数据处理的速度每15 min应达到50万条~100万条。
实验借鉴已有研究成果,使用了基于MPI的方法、基于MapReduce的方法和基于Spark的方法对交通流数据进行处理,并对其运行效率进行了比较分析:
1)基于MPI的方法。在分布式节点设置4个从进程,完成交通流数据清洗任务,在清洗过程中按照时间周期统计数据,发送至主进程;在中心节点设置1个主进程,完成各个分布式节点统计信息的合并,利用基于多阶空间权重矩阵的STARIMA模型进行预测分析。
2)基于MapReduce的方法。按照数据量将交通流数据集平均分为48个数据块,同时在4个分布式节点每个配置12个Map运算和1个Combine运算,在Map运算中实现数据清洗,在Combine运算中实现数据统计,按照时间周期将统计数据发送至中心节点的Reduce运算将统计信息合并,最后执行预测模型进行分析。
3)基于Spark的方法。使用本文研究的基于Spark的分布式交通流数据处理方法,利用Shark作为数据仓库对交通流数据进行分布式存储,使用高效的Spark作为计算引擎完成数据清洗和统计,在中心管理节点将统计信息合并,并执行预测模型进行分析。
实验在2万、5万、10万、20万、50万和100万条的数据量下使用3种方法进行处理,其中50万和100万条已超过目前平台在15 min时间周期内需要处理的最大数据量。图6为3种方法处理效率对比图:
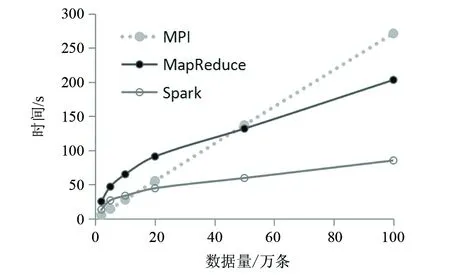
图6 三种算法数据处理效率对比图Fig.6 Comparison diagram of three algorithms for data processing efficiency
通过对比可以看出:
1)MPI方法在处理的数据量较小时所用时间比其他两种方法少,随着数据量增大,其耗费时间线性增加,其原因在于MPI分布式框架结构简单,框架本身所占用运算时间很少,因此系统总体运算时间与数据量线性正相关。
2)MapReduce方法在处理的数据量较小时,效率低于MPI方法,原因在于MapReduce框架应用架构比较复杂,框架本身在运算过程中所消耗的时间在总体耗时中比重较高,而伴随数据量的增加,框架耗时比重降低,数据量成为运算耗时的主导因素,总耗时在数据量达到50万条时反而比MPI方法更少,而且随着数据量增大,其优势更加明显。
3)Spark方法与MapReduce方法的时间曲线形状较为相似,但所用时间明显少于MapReduce方法,Spark方法利用内存计算和迭代计算的方法,避免了MapReduce方法中多次申请计算和存储资源,以及大量的磁盘I/O操作,此方法用于实现较为复杂的交通流大数据清洗和统计算法效率更高,通过实验可以看出,其耗费时间约比MapReduce方法减少60%左右。
对比3种方法,基于Spark的方法具有效果稳定、技术成熟、效率较高的优势,可以为交通流预测分析提供数据基础。
3.3 交通流大数据预测分析实验
经过上一实验对交通流数据的清洗和统计,可得到路网中各个路段在某一预测周期内的交通流信息,此时即可利用本文设计的多阶空间权重矩阵的STARIMA模型进行交通流预测分析。如图7为郑州市龙子湖高校园区路网抽象化示意图。
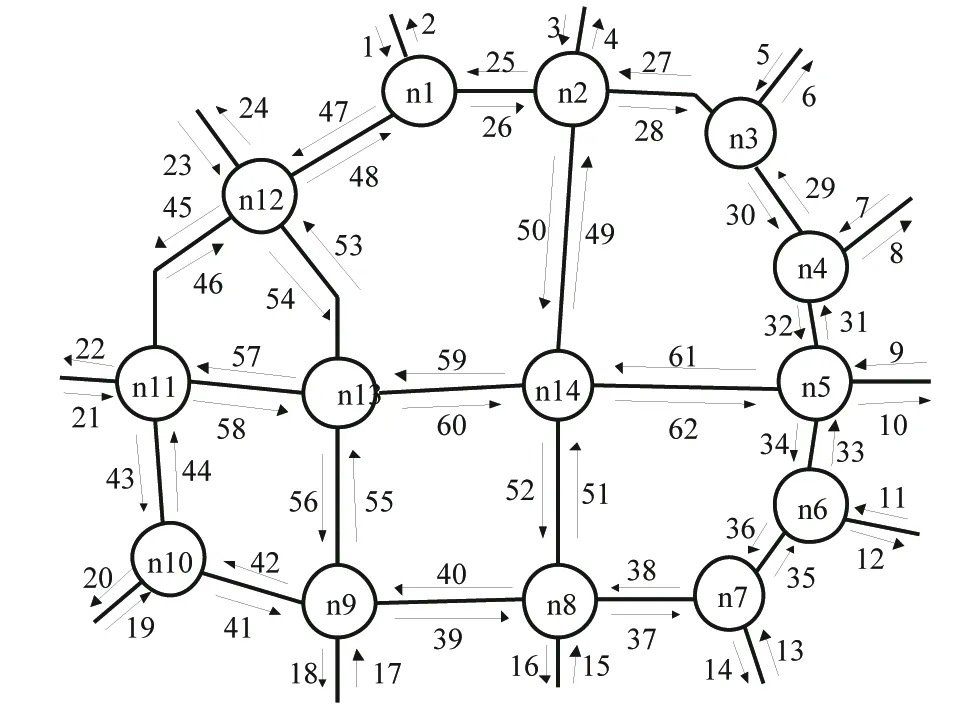
图7 郑州市龙子湖高校园区路网抽象图Fig.7 Abstraction of area road network in Zhengzhou Longzi Lake college
以龙子湖高校园区路网为例,实验使用15 min为一个预测周期,选用2016年12月5-8日共4 d384个周期的交通流数据作为历史数据集,对后续10 d 960个周期的交通流进行预测,利用实际数据与预测结果进行对比,并用均方误差判断预测结果的准确性。
本文利用2种方法进行对比试验,表1为两者预测结果的均方误差:
1)动态STARIMA预测模型。利用时空自回归移动平均模型STARIMA将交通流在路网中在时间和空间维度上的相关性一体化体现出来,此模型只分析了一阶邻接路段,对于交通流的实际运行特征体现不够准确,预测分析结果的准确性也会受到一定影响。
2)基于多阶空间权重矩阵的STARIMA模型。本文研究的预测模型实现了空间权重矩阵的优化扩展,在以往成果基础之上,考虑了多阶上游路段对下游路段的影响,通过分析和实验,二阶以内路段空间相关性较大,将其加入预测分析可提高分析结果的准确性,而三阶以上路段相关性小、计算量大,为了保证系统整体运行效率,将其忽略不计。
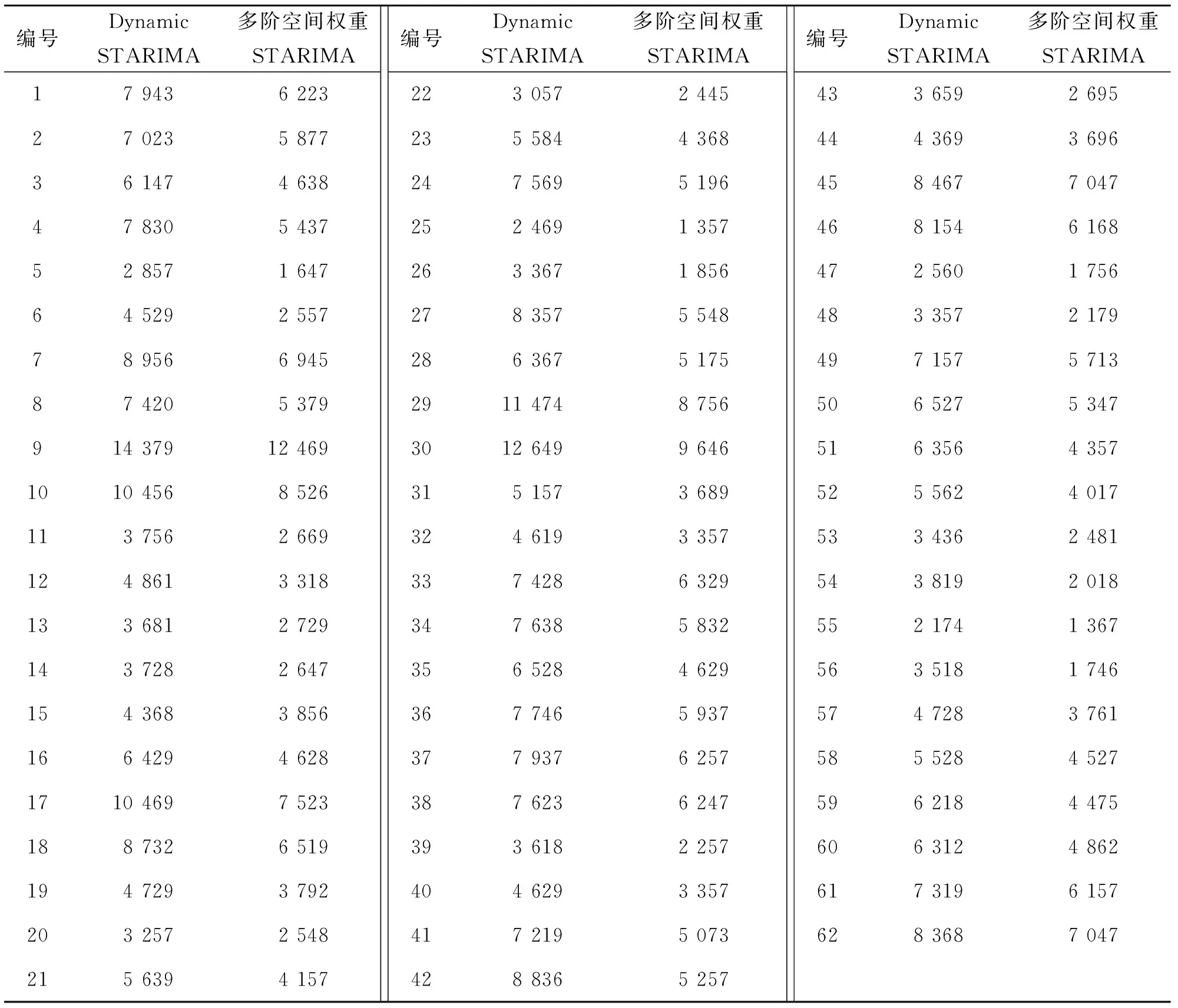
表1 预测结果均方误差(MSE)对比Table 1 The MSE comparison of the prediction results
通过表1的误差对比可看出,本文研究的模型准确程度高于动态STARIMA模型。其原因在于,本文模型在保证系统整体计算工作量和运行效率的基础上,更加充分的分析了交通流在路网中的相关关系,将真实的交通流分配规律体现的更为准确,因此预测结果的准确定也更高。
4 结 论
1)本文设计了基于Spark分布式交通流预测分析总体框架,利用Spark RDD对交通流数据进行缓存,借助框架的高效内存计算和迭代计算优势,使用孤立点检测算法完成交通流数据的清洗和统计,为后续预测分析排除“脏数据”的干扰。进行数据存储时,根据交通流数据空间范围、时间区间、流量密度和数据规模等因素设计了负载均衡分配规则,并将分布式节点的数据分配信息在元数据库中注册,用于提高分布式语义查询的检索效率。通过MPI、MapReduce和Spark三种方法对交通流大数据的处理实验证明,本文设计的Spark方法由于避免了反复申请计算存储资源和进行大量磁盘I/O操作,因此在进行数据清洗、统计和注册时的效率较高,数据量超过50万条时,耗时比其他两种方法减少约60%左右,并且随着数据量不断增大,其效率优势越发明显,可以在预测周期内完成数据预处理工作。
2)本文设计了基于语义解析、逻辑优化的分布式交通流数据语义查询方法,利用分布式节点的元数据信息,实现高效的预测分析语义查询。进行预测分析时,在量化分析多阶路段上下游相关性的基础上,设计了基于多阶空间权重矩阵的STARIMA交通流预测模型。通过动态STARIMA模型和多阶空间权重STARIMA模型的预测分析对比实验证明,本文使用的二阶相关性方法优点在于,和一阶相关性相比,更加准确的体现了交通流的实际运行规律,同时避免了三阶相关性的大量计算导致的效率降低,在保证整体运算效率的基础上,实现了更加准确的预测,可以为交通诱导信息发布提供参考依据。
