考虑非对称用户偏好的推荐算法
2018-12-04邓永恒李晓光
王 永,邓永恒,李晓光
重庆邮电大学 经济管理学院,重庆 400065
1 引言
随着互联网技术及其信息科技的蓬勃发展,推荐技术已成功应用于电子商务领域,解决了如何从日益激增的互联网信息中挖掘出对线上用户有价值的信息,并快速高效地推荐给目标用户[1]。推荐系统(RS)的核心任务是通过分析目标用户对已评产品或项目的偏好行为,去预测该用户在未评产品或项目上的喜爱程度,以满足用户的个性化需求。协同过滤(CF)算法[2]因其拥有简单又高效的特点,在推荐系统中应用最为广泛,深受研究者的青睐,是传统推荐技术之一。算法假定用户过去的偏好行为将会对其未来的偏好行为有重大影响,且具有相同或相似兴趣偏好的用户信息需求也是相似的。
在推荐算法中,计算用户或项目间的相似性是算法的首要任务,也是最为核心的步骤。因此,相似性度量方法的选择将直接决定推荐系统的好坏,对用户体验有重大影响。常见的用户相似性度量方法,如余弦相似性、皮尔逊相关系数等,在一定时期取得了较大成功,但随着应用环境的变化,它们已无法满足用户对推荐系统的精度要求。为改善推荐质量,确保推荐系统的时效性,许多研究者在不同的应用环境下提出了一些新的用户相似性度量方法。为了解决启发式相似性度量方法PIP[3]未考虑用户对项目评分的全局偏好行为的问题,Haifeng Liu等人提出了一种新的启发式方法NHSM[4]。为了充分利用用户的所有评分信息,一些研究者从项目概率分布的角度提出了一种新的相似性度量方法[5-6]。程伟杰等人通过利用动态调节权重将基于全部评分信息的用户相似性方法与传统用户相似性相结合,提出了一种混合的用户相似性方法[7]。张沪寅等人将用户间的共同评分项数目和PCC相似度阈值作为条件,提出了一种基于多分段改进 PCC的相似度计算方法[8]。上述算法都对共同评分项的数量没有任何要求,能充分利用用户所有评分值,较好地解决了数据稀疏性问题。为了解决推荐系统中数据的高稀疏与高维度问题,陶维成等人首先将灰色关联度理论应用到协同过滤中去计算用户间的相似性,然后对用户进行灰色关联度聚类[9]。该方法具有良好的运算效率,有效缓解了用户冷启动问题。李道国等人[10]通过分析用户评分时间,并结合用户评分方差相似性来改进传统相似性方法计算不准确的问题,且优化了最近邻居集的筛选方式。王颖等人从邻居用户选择的角度出发,考虑数据稀疏度对邻居个数和对称关系的影响,提出了一种融合用户自然最近邻的推荐算法,该方法在邻居选择和推荐精准度方面具有一定优越性[11]。余以胜等人[12]将社群挖掘的思想引入到个性化情报信息推荐中,计算了在不同兴趣细粒度社群中的用户相似性,从而有效地提升了推荐算法的精确度。为了同时考虑用户兴趣偏好受时间和频率共同影响问题,李红巍设计了一种基于本体相似度和时间衰减的动态个性化推荐算法[13]。该算法不仅能计算用户兴趣点的时间衰减规律,还考虑了不同兴趣点访问频率对兴趣点关注程度的影响,从而提升了整个系统的推荐效率。
上述相似性度量方法均假定相似性是一种对称的模式,即sim(u,v)=sim(v,u)。这些方法使用共同评分进行计算,计算用户间的影响是对等的。在邻居群体选择阶段,依据这种对称的相似度作为筛选标准,会把一部分原本不相似的用户纳为邻居;而预测阶段又是以最近邻居集为基础的,从而使预测结果的准确性受到干扰。此外,用户在评分时存在某种偏好,如有的用户的评分普遍偏高,而有的普遍偏低。评分偏好的差异导致相同分数表示的兴趣度存在较大差别。若未考虑偏好因素,将来自不同偏好的用户的相同评分值视为价值相同,则计算得到的相似性结果不够客观。上述方法的设计中,并未考虑这些因素,所以,基于对称模式的相似性方法在度量的全面性、综合性方面存在不足。
本文在计算用户相似性时,为了考虑用户间的非对称关系和用户偏好行为,在常见的相似性方法上引入了两个权重因子,提出了一种考虑用户偏好的非对称推荐算法。非对称因子强调了目标用户与其他用户间的共同评分项所占比例,将对称的用户相似性转化为非对称的用户相似性,用于区分用户间在评分数量上的差别。偏好因子反映了用户对所评项目的某种评分偏好,用于解决某些极端用户习惯对项目评高分或低分的问题,使计算结果更为客观真实。在真实数据集上的实验结果显示,本文所提出的方法在一定程度上能缓解传统相似性度量方法所存在的偏好问题,降低了推荐误差,推荐结果更为准确。
2 问题分析
为了利用用户-项目评分矩阵中的数据去度量用户间的相似性,常见的用户相似性度量方法,如余弦相似性(COS)[14]、Pearson相关系数(PCC)[15]和均方差(MSD)[16]等被提出。但这些常见的相似性方法都存在同一个假设:每个用户都被分配同等权重的相似性,用户间不存在任何偏好,用户相似性完全对称,即sim(u,v)=sim(v,u)。然而,在实际情况下,用户间明显存在不同的偏好行为,即便两用户十分相似,用户间也有细微的评分偏好差别。因此,本文认为用户间的相似性应该是不对称,用户间存在不同的评分偏好。
为了更好展示一些常见的相似性方法所普遍存在的问题,设计了一个示例来加以阐述。在表1用户-项目评分矩阵中,共有5个用户和6个项目,其中“—”表示用户未对项目评分。根据表1数据,采用常见的相似性度量方法COS、PCC和MSD计算用户间的相似性,相关结果见图1,其中“*”表示用户相似性值无法被计算。

表1 用户-项目评分矩阵
从图1的相似性结果可知,这三种相似性度量方法各自都存在一些问题。对这些问题详细分析如下:

图1 不同方法的用户相似性值
(1)问题1:仅利用共同评分项
从图1中可知,所有用户相似性矩阵都是对称的,即对任意两用户而言,存在sim(u,v)=sim(v,u)。其原因在于这些方法只利用了两用户间的共同评分项,而忽略他们的其他评分的影响。从表1可以看到,用户U1和U3的评分分别为(4,4,—,—,—,—)和(4,4,5,5,3,3),用户U1的所有评分和用户U3完全对应相等,但用户U3只有1/3的评分能和用户U1完全匹配。存在这种差异的原因在于,这些相似性度量方法所计算出的相似性值往往只由评分数量较少的那个用户决定,而忽略用户各自的评项目数量也对相似性结果有重要影响。因此,本文用一种非对称方法去计算用户间的相似性更为合理。
(2)问题2:未考虑用户评分偏好
这个问题主要为了凸显PCC方法的缺陷。从PCC的结果矩阵图1(b)可知,用户U1和U3的相似性值为0,这意味着用户U1和U3完全不相似。然而,从表1中可发现用户U1和U3在项目I1和I2上有相同的评分,说明用户U1和U3间其实存在一定的相似性,而PCC方法却计算出了一个完全错误的相似性结果。
此外,从表1中还可看出,用户U2和用户U3应该比用户U1和用户U3更为相似,而从图1中的所有相似性方法的值上看,COS和MSD的结论正好相反,且PCC的两结果过于极端。由此说明,这些方法仅考虑用户间的共同评分项而忽略用户本身的评分数量,会造成相似性结果不准确。本文认为用户U3对用户U1的影响和用户U1对用户U3是完全不同的,用户相似性的值不应该是1或0。因此,本文将用户评分偏好的问题考虑在内。
3 考虑用户偏好的非对称推荐算法
本文算法包括两个核心步骤:(1)计算考虑用户偏好的非对称用户相似性;(2)产生推荐列表。本文主要在常见的相似性方法(COS、PCC和MSD)上,引入两个权重因子到用户相似性计算中,有效地弥补了改进前相似性方法未考虑用户间共同评分项在目标用户所评项目中的比例以及用户评分偏好的问题,降低了预测误差,提高了推荐质量。
3.1 权重因子
(1)非对称因子
对于用户u和v,对称模式的相似度算法可概括为sim(u,v)=sim(v,u)。由表达式可知,对称的算法对输入内容和次序不敏感。同时,实际上参与运算的是共同评分项的分值信息,这组信息是数值的、等长的,不会直接影响对称性。若用户u和v的评分总数不同,其共同评分数占二者评分总数的比例也是不同的。由此,可利用绝对数量、占比等方面的差异,构造一个作用于算法外部的因子,从而调节对称性。
用Iu,Iv分别表示用户u和v所评分项目的集合,用户u的评分总数用|Iu|表示,共同评分的数量占用户u评分总数的比例为:

Sigmoid函数具有单调性、非线性等性质,且对于差异较大的自变量,输出值之间有很高的分辨度,因此在式(1)的基础上,结合Sigmoid函数设计非对称因子如下:

(2)偏好因子
不同用户对项目进行评分时,都存在一定的个人标准和偏好取向。例如,有的用户对所评项目的评分普遍偏高,而有的普遍偏低。由于这种偏好的作用,不同用户之间,即使评分的分值相同,实际的兴趣度可能有较大的区别。如前面的示例中,用户U3和U4对项目I5的评分均为3分,在U3的所有评分中3为其最低评分,代表其最低的兴趣程度;而对于U4,3分是最高评分,表示U4对该项目可能最感兴趣。可见,正是评分偏好的存在,分值不能直接等同于用户的感兴趣程度。
对于用户u的所有评分数据,其均值rˉu反映了分值样本的一般水平;标准差δu反映的是偏离均值的平均距离,是一种集中程度的体现。通过这些统计量,可发现用户评分偏好的存在:u的均值越高(或越低)、数据分布越集中,其评高分(或低分)的偏好就越明显。
为了消除评分偏好对用户相似性度量的影响,引入用户评分的均值和标准差去构造偏好因子,使得最终的相似性结果更为客观。其公式为:
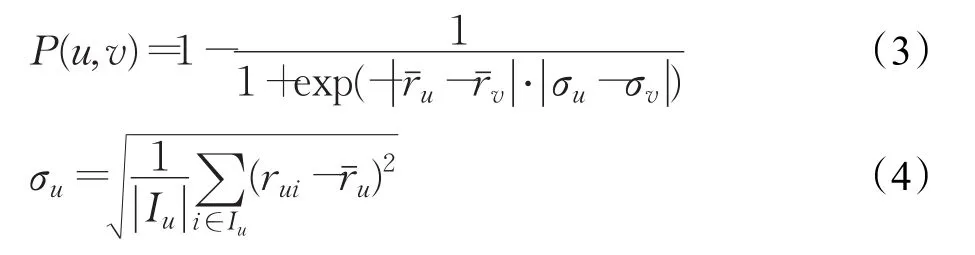
其中,rui表示用户u对项目i的评分值。
将上述两种权重因子引入到第二部分所提到的常见的用户相似性中,得到修正后的公式如下:

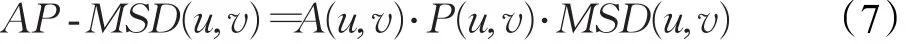
3.2 产生推荐列表
推荐的过程如下:
步骤1形成最近邻居集(见图2)。根据修正后的公式可计算出任意两用户间的相似性值,进而获得用户间的相似性矩阵S。根据相似性矩阵中值的大小,得到用户u的前K个相似性值最大的最近邻居用户,最终形成最近邻居集Ku={u1,u2,…,uk}。
步骤2计算预测值。设用户u的最近邻居集为Ku,则用户u对未评分项目i的预测评分值Pui的计算公式如下:

步骤3产生推荐列表。根据项目预测值,系统可为目标用户进行项目推荐,即取项目预测值最高的前N个项目作为用户感兴趣的推荐列表。
4 算法分析
(1)考虑用户评分数量
在本文算法中,引入一个非对称因子A(u,v)去评估用户v对用户u的影响。在式(2)中,利用用户u和v的共同评分项在目标用户u所评数量中的比例去度量用户u和v间的非对称性。若共同评分的比例较大(接近1),则用户v对用户u有十分重大的影响;若共同评分的比例较小(接近0),则用户v对用户u几乎无影响。对于A(v,u),共同评分的比例值取决于用户间的共同评分项和用户v所评项目的数量。显然,sim(u,v)≠sim(v,u),即用户u和用户v的相似性值有别于用户v和用户u的值。因此,式(1)为相似性度量方法提供了一个高效的方案去强调用户间的相似性是非对称的,使得这些相似性方法计算出的结果更加符合实际情况。
(2)消除极端用户评分偏好
为了加强所提算法的精确度,本文算法引入偏好因子去消除极端用户评分偏好的影响。在式(3)中,通过利用用户的平均评分和评分标准差去衡量用户间的偏好差异。若用户间的平均评分或评分标准差较大,则用户间的偏好存在很大差异。根据式(3)可知,P(u,v)计算出的值很小,能较好地削弱极端用户评分偏好的影响。
(3)优化邻居用户的选择
最近邻居集的选择是通过用户相似性值进行筛选的,因而邻居集的选择将直接影响后续对项目值的预测以及推荐。若用户u和v的相似性是对称的,且相似性的值很大,则这两用户必互为最近邻居。但依据式(2),假设用户u的评分数量远大于用户v的数量,则A(u,v)≪A(v,u),最终可能会导致用户u是用户v的最近邻居,而用户v未必是用户u的最近邻居,以达到获得优化邻居的目的。
根据所提算法的公式(5)~(7),本文利用表1中的评分数据计算得到相应的相似性矩阵。从图3相似性结果可知,加入两个权重因子后,用户相似性的值变动幅度不大,消除了各自评分偏好的影响,且用户相似性是非对称的。引入因子后的模型修正了常见的相似性方法所存在的缺陷,能更好地突出每个用户的偏好行为。然而,不可否认的是改进后的模型计算出的相似性值仍存在一定问题,这是由这些相似性度量方法本身所引起的。因为这些常见的方法太过于依赖用户间的共同评分项,而不能充分利用用户的所有评分信息。若将本文的两个权重因子加入到更佳的相似性模型中,其推荐精度将会更高,这里将不再对比。
(4)算法性能分析
时间复杂度是评估算法效率的一种方式。表2列举了原算法和改进算法的时间复杂度,结果所示,这些方法的时间复杂度均为线性阶,即O(n)。

表2 各对比算法的时间复杂度

图3 引入权重因子后的用户相似性值
调整后的算法与原算法相比,时间复杂度保持不变,时效上的波动较小;但调整后的算法在度量全面性、削弱偏好影响、邻居集优化等方面的提升是可见的;所以,加入非对称因子和偏好因子进行改进,可以获得更优的综合性能。
5 实验结果与分析
5.1 数据集
为了验证本文所提算法的高效性,使用MovieLens数据集(http://www.grouplens.org)——ML-1M和Yahoo提供的公开数据集Yahoo Music(https://webscope.sandbox.yahoo.com)作为本文算法测试和验证的数据集。其中MovieLens数据集包括了6 040位用户的基本信息,如性别、年龄、职业等;3 900部电影的基本信息,如电影名称、电影类别等;1 000 209条电影评分,评分区间为1~5,且每个用户至少评过20部及其以上的电影。Yahoo Music数据集包括15 400位用户和1 000首音乐的基本信息和183 179条音乐评分。为了测试推荐算法的性能,将数据集划分为两部分:训练集和测试集,大小比例为8∶2。
5.2 评估指标
衡量推荐算法好与坏的指标常用平均绝对误差MAE(Mean Absolute Error)和根均方误差RMSE(Root Mean Squared Error)去度量预测评分值和实际评分值间的偏差,以此来反映推荐算法的准确性。误差值越小,推荐精度越高。其公式如下[5]:

其中,rui和分别为用户u对项目i的实际评分值和预测评分值;n为待预测项目的个数。
为了对以下公式描述方便,首先介绍两个变量,分别是IRup和IRua。IRup表示推荐系统为目标用户u提供的预测推荐列表。IRua是在测试集中用户u的真实推荐列表。下面,本文将介绍评估算法预测准确性的三个重要指标:Precision、Recall和F1-Measure值。

图4 MAE的结果比较
Precision定义为同时包含在IRup和IRua中的项目数与IRup中的所有项目数的比值。而Recall表示为同时包含在IRup和IRua中的项目数与IRua中的所有项目数的比值[6]。其表达式如下:

其中,m表示待预测的目标用户数量。在实验中,算法假定出现在推荐列表的项目的评分值必须高于目标用户的平均评分,否则不予推荐。
F1-Measure值是一个综合评估Precision和Recall结果的指标,使得最终计算出的实验结果更为可靠。其公式如下:
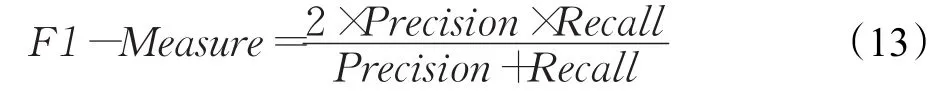
5.3 结果分析
选取常用的相似性模型(COS[12]、PCC[13]和MSD[14]),首先分别测试每个因子引入到模型中后对预测结果的影响,之后再测试综合两因子后的预测效果,并与一些近年来提出的相似性方法(JMSD[4]、PIP[3]和NHSM[4])作对比。由于不同的邻居个数K对测试结果有不同的影响,因此在实验中设置K值从20增加到100,间隔为20。实验结果如图4至图6所示。
MAE和RMSE主要反映的是推荐系统的预测误差精度。在图4中,在两个数据集上,引入两个权重因子后的相似性方法的MAE值均优于其他对比方法,且AP-PCC方法的误差值比其他任何相似性方法都低,推荐效果最佳。随着K值(用户邻居数)的增加,所有方法的误差均在逐渐降低。Movielens数据集上,引入两因子后,AP-PCC方法表现最佳,其误差范围为:0.704≤MA E≤0.716;在Yahoo Music数据集上,当 K 值大于120时,AP-COS的MAE最小,范围为:1.251≤MAE≤1.265。在图5中也可以得出类似的结论,表明本文提出的两个权重因子有效改善了预测模型的RMSE误差。预测误差较低,有效提高了推荐系统的质量。

图5 RMSE的结果比较

图6 F1-Measure的结果比较
F1-Measure主要是用于评估推荐质量的好坏。从图6可知,每个相似性方法的F1值都随着K值的增加而增加。图6(a)所示,在Movielens数据集中,AP-PCC的F1值最高且基本维持在0.726水平上;AP-COS、AP-MSD方法的F1曲线有所重合,接近0.718;而其他如COS、MSD、PIP和NHSM等方法的F1值均低于0.63。图6(b)所示,在Yahoo Music数据集上,改进后方法的F1曲线均处于更高的区间,AP-PCC表现最优,其值分布在0.277到0.282之间。上述结果说明,两权重因子的引入能有效地提高相似性模型的推荐结果。
综上所述,引入两权重因子后的相似性方法在各个评估指标上均优于其他对比方法。因此,本次实验结果验证了本文提出的两个权重因子对改进相似性模型有积极的作用,可以有效提高推荐系统的综合性能。
6 结论
为了解决相似性度量方法普遍所存在的用户偏好问题,本文在常见的相似性方法中,引入两个权重因子到其相似性计算中,提出了一种考虑用户偏好的非对称推荐算法。第一个权重因子(非对称因子)将目标用户与其他用户间的共同评分项所占的比例考虑在内,将完全对称的用户相似性转化为非对称,这弥补了相似性方法为每个用户都分配同等权重的相似性,即考虑了不同用户对所评项目的数量。
第二个权重因子(偏好因子)利用用户间的均值和标准差去消除极端用户的评分偏好。在引入这两个权重因子后,与引入前的方法相比,引入后的方法有效地缓解修正前方法所存在的用户偏好问题,能更为精准地为目标用户筛选邻居用户,实现最佳的项目推荐。在数据集MovieLens上的实验结果表明,引入两因子后的相似性方法要优于其他所对比的相似性方法,其中APPCC方法能极大地降低了预测误差,有效地提高了推荐系统的质量。
