面向国产CPU的可重构计算系统设计及性能探究
2018-12-04彭福来于治楼陈乃阔耿士华李凯一
彭福来,于治楼,陈乃阔,耿士华,李凯一
山东超越数控电子股份有限公司,山东省特种计算机重点实验室,济南 250104
1 引言
现代社会信息量的暴增对计算机的计算性能提出了更高的要求,通过纵向提高CPU的处理性能已经遇到了制作工艺、功耗等技术瓶颈。大数据分析、机器学习、图像与视频处理、网络安全等计算密集型领域需要计算能力强大的服务器来支撑,单纯采用CPU来完成这些任务已经无法满足性能要求。为了提高服务器的计算性能,业界通常采用GPU或FPGA等并行处理能力较强的器件作为硬件加速器,形成CPU+协处理器的异构计算系统来对计算密集型任务进行加速。GPU由于具有强大的并行计算能力,已被广泛应用于图像处理[1-2]、人工智能[3-5]、数据安全[6-8]等领域。
虽然使用GPU来加速计算任务能够获得极佳的加速性能,但是GPU的功耗较高,无法满足一些空间、散热条件不足的应用场景。而采用FPGA可以获得较好的性能功耗比[9],因此许多学者研究利用FPGA来加速计算任务[10-12]。同时,由Khronos Group所维护的异构平台编程框架标准OpenCL为FPGA提供了高效的开发方式,开发者可以采用高级语言对FPGA进行开发,不仅降低了开发难度,缩短了开发周期,还能够满足FPGA的在线可重构功能。这使得FPGA在异构计算加速领域的应用得到了迅速的扩张。目前FPGA两大供应商Xilinx和Intel均推出了支持OpenCL开发的FPGA器件及软件开发工具包,且已在很多领域得到了应用[13-15]。
采用FPGA来加速计算任务能够获得极佳的性能功耗比,但是目前的CPU+FPGA异构加速系统绝大部分基于x86架构处理器。在国际关系日益严峻的形势下,关键核心领域必须能够自主可控,虽然我国在自主可控计算机基础软硬件研发方面已初见成效,但当前的自主服务器性能与x86架构服务器还存在较大差距,难以满足计算密集型任务对计算资源的需求。为此,本文将采用FPGA对国产CPU的任务进行加速,形成基于国产CPU的可重构计算系统,以提升国产平台的计算性能。
首先对基于国产CPU的可重构计算系统进行了介绍,然后介绍了本文采用的一个测试用例——AES加密算法,及其OpenCL的实现,最后采用AES加密算法对该系统的性能进行了测试,并与串行CPU的处理性能进行了对比分析。
2 OpenCL可重构计算系统
2.1 OpenCL
Open CL(Open Computing Language)[16-17]是由Khronos Group维护的一种为异构平台提供编程的框架标准。该异构平台通常由CPU、FPGA、GPU或者其他类型的处理器以及硬件加速器组成。OpenCL包括两部分:编写kernel函数(运行于OpenCL设备上)的语言(基于C99标准)和一组用于定义并控制平台的API。OpenCL将不同类的计算设备组成一个统一的平台,为软件开发者提供一种可移植的、高效的编程方法。

图1 CPU+FPGA异构计算系统框图
OpenCL的核心思想包括四种方面:平台模型(Platform model)、内存模型(Memory model)、执行模型(Execution model)和编程模型(Programming model)。平台模型包括一个Host主机以及与其相连接的一个或多个OpenCL设备(在本文中OpenCL设备为FPGA),每个OpenCL设备可以分割为一个或多个计算单元(CU),每个CU又可以进一步划分为一个或多个处理单元(PE),PE是OpenCL设备最基本的运行单元。OpenCL将kernel函数运行所用的内存分为四种类型:全局内存、常量内存、局部内存以及私有内存。全局内存:所有工作节点均可以对其进行读写,容量较大,但访问延迟较高;常量内存:存放所有工作节点均可以访问的常量;局部内存:工作组内部的内存,工作组内的所有工作项均可以进行读写操作;私有内存:工作项独有的内存,只对其相应的工作项可见。执行模型包括两部分:一部分在Host主机运行的主程序,该程序负责创建上下文、缓存、对OpenCL设备下发任务及数据等,另一部分为运行在OpenCL设备上的kernel函数,kernel函数负责执行相关的计算任务。编程模型支持数据并行和任务并行两种模型,其中数据并行模式是OpenCL的首要模型。
OpenCL设计的大致流程为[18]:
(1)创建并初始化OpenCL设备和上下文环境,建立命令队列。
(2)创建并编译源程序,建立内核kernel句柄。
(3)分配数据所需内存空间,并将数据复制到OpenCL设备上。
(4)设置内核kernel参数。
(5)Host下发并执行内核kernel程序(通过下发不同的kernel程序可以实现不同的功能)。
(6)将计算结果从OpenCL设备复制到主机中。
(7)释放系统所占资源。
2.2 基于国产CPU的可重构计算系统
图1为CPU+FPGA架构的可重构系统框图,主要包括Host主机部分与FPGA加速单元。Host主机与FPGA加速单元通过PCIe总线进行通信。Host主机负责管理控制相关事务以及调度FPGA加速单元,并处理一些简单的串行程序。FPGA由于其具有强大的并行计算能力,负责处理Host下发的计算密集型任务。FPGA具有在线可重构功能以实现对不同应用需求的计算加速。FPGA内部分为两个区域:静态配置区和动态可重构区,静态配置区包括PCIe模块、DMA控制器以及Memory控制器等主要模块,该区域一方面向外提供PCIe、DDR等的通信接口,另一方面向动态可重构区的kernel IP提供接口。静态配置区通过AS(Active Serial)配置模式进行配置,系统上电后自动配置,配置完成后FPGA具备了基本的通信功能,能够接收Host下发的任务。动态可重构区负责布署Host下发的kernel IP并执行数据处理任务,kernel IP为具体应用的算法实现。当应用场景改变时,Host可通过PCIe通道下发新的kernel IP,重新配置动态可重构区,此过程无需FPGA加速单元重启,整个重配过程耗时仅为毫秒级,完全实现了算法的在线重构。
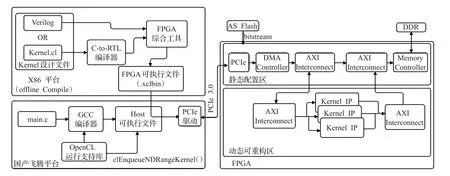
图2 基于国产CPU的可重构系统实现框图
由于kernel函数的编译时间较长,且kernel函数的编译需要用到FPGA综合工具,而这些工具并不支持国产平台,因此,本文将采用x86平台对kernel函数进行离线编译,事先生成FPGA可执行文件。基于国产CPU的可重构计算系统实现框图如图2所示,系统的运行环境包括国产飞腾平台和FPGA加速单元两部分,国产飞腾平台负责main函数的编译、运行以及对FPGA的管理控制、任务分配等工作。Main函数的编译与运行需要OpenCL运行支持库支持。当需要对FPGA可重构区进行配置时,Host会将事先生成的FPGA可执行文件通过PCIe总线下发到FPGA中,以实现FPGA的在线可重构功能。
3 AES算法性能瓶颈分析及OpenCL实现
3.1 AES算法原理
AES是由美国国家标准与技术研究院(NIST)提出的用于替代数据加密标准(Data Encryption Standard,DES)的新一代密码标准。它采用一种对称分组密码算法,加密与解密过程使用相同的密钥。AES加密对象的数据块分组长度为128 bit,密钥长度可以为128 bit、192 bit以及256 bit三种。AES的加密过程是对128 bit的数据块进行多轮的迭代运算,得出相同长度的密文。不同长度的密钥所需的轮数不同:128 bit长度的密钥需要10轮,192 bit长度的密钥需要12轮,256 bit长度的密钥需要14轮。由于每轮的运算步骤基本相同,本文以128 bit密钥长度为例来介绍AES加密过程。每轮加密的对象为16 Byte(128 bit)的数据,可以表示为一个4×4的矩阵。
加密流程如图3所示,除了第10轮与第1轮前的轮密钥加,其余各轮的运算步骤相同,包括字节替换(SubBytes)、行移位(ShiftRows)、列混合(MixColumns)以及轮密钥加(AddRoundKey)四个步骤。字节替换是通过非线性的替换函数,利用查表的方式将每个字节替换成相应的字节;行移位将矩阵的每行进行循环移位;列混合是通过线性变换的方式来混合每列的四个字节数据;轮密钥是将矩阵中的每个字节与该次的轮密钥进行异或运算。每个轮次所用的密钥由上一轮密钥按照密钥扩展方法生成,其中第一组密钥为原始密钥。

图3 AES加密流程图
3.2 AES程序性能瓶颈剖析
程序运行过程中,大部分的执行时间往往花费在某些关键函数上,这些函数经常具有大量循环、数学计算等操作,这些函数对程序的执行效率有着关键性的影响[19]。如果能找到这些性能瓶颈,通过一些加速设备对其进行优化、加速,以缩短执行时间,将会大大提升程序的整体性能。
本文采用Google perftools性能瓶颈剖析软件对AES加密程序进行性能剖析。该分析软件通过采样的方式统计程序中各函数对CPU的使用情况,函数的耗时长短与采样次数成正比,即采样次数多的函数耗时较长。通过该分析软件,可以对程序中各函数的耗时情况一目了然,进而得出程序的瓶颈所在。图4为采用kcachegrind软件对Google perftools剖析结果进行显示的结果图像,图中方框内为程序中各函数的名称以及该函数的执行时间占总时间的百分比,箭头旁的数字表示箭头所指向的函数被采样的次数,采样次数越大,表示执行时间越长。由图4可见,占据AES程序执行时间的主要是MixColumns(列混合)、AddRoundKey(轮密钥加)、SubBytes(字节替换)以及ShiftRows(行移位)四个函数,其中MixColumns执行时间最长,而密钥扩展函数KeyExpansion在图中并未出现,表明该函数执行时间非常短。

图4 AES程序性能瓶颈剖析结果图
鉴于上述分析,本文将对AES的列混合、轮密钥加、字节替换和行移位操作函数进行加速,而密钥扩展函数通过CPU实现。
3.3 AES算法的OpenCL实现
基于OpenCL的AES程序实现包括两部分:一部分是运行于Host主机的main函数,另一部分为运行于FPGA上的kernel函数。Main函数主要包括:平台、设备信息的获取,上下文的创建,Buffer的创建,命令队列的创建,kernel参数设置,kernel文件及数据下发等过程。由于密钥扩展函数执行时间较短,因此将密钥扩展也放在Host主机运行,并将扩展的密钥存放在全局内存,以供kernel函数使用。相关程序如图5所示。

图5 密钥扩展及其传输代码示意
Kernel函数为AES加密的关键部分,主要包括SubBytes函数、ShiftRows函数、MixColumns函数以及AddRoundKey函数。为了提高加密吞吐率,对kernel函数进行优化设计,采用多级流水并行的方式,保证kernel的每一个处理单元都能全速运行。相关程序如图6所示。

图6 Kernel函数代码示意
4 实验数据测试及实验结果讨论
4.1 实验条件
本文所用测试环境配置如下:
Host主机参数:CPU型号:phytium FT-1500A
CPU主频:1 GHz
内存:16 GB DDR3
PCIe接口:PCIe x8 Gen3
FPGA加速单元:NSA-121A,配置参数请见表1。
软件环境:4.4.13-20170210.kylin.5.desktop,Xilinx SDAccel 2016.3,gcc/g++。

表1 FPGA加速卡NSA-121A配置参数
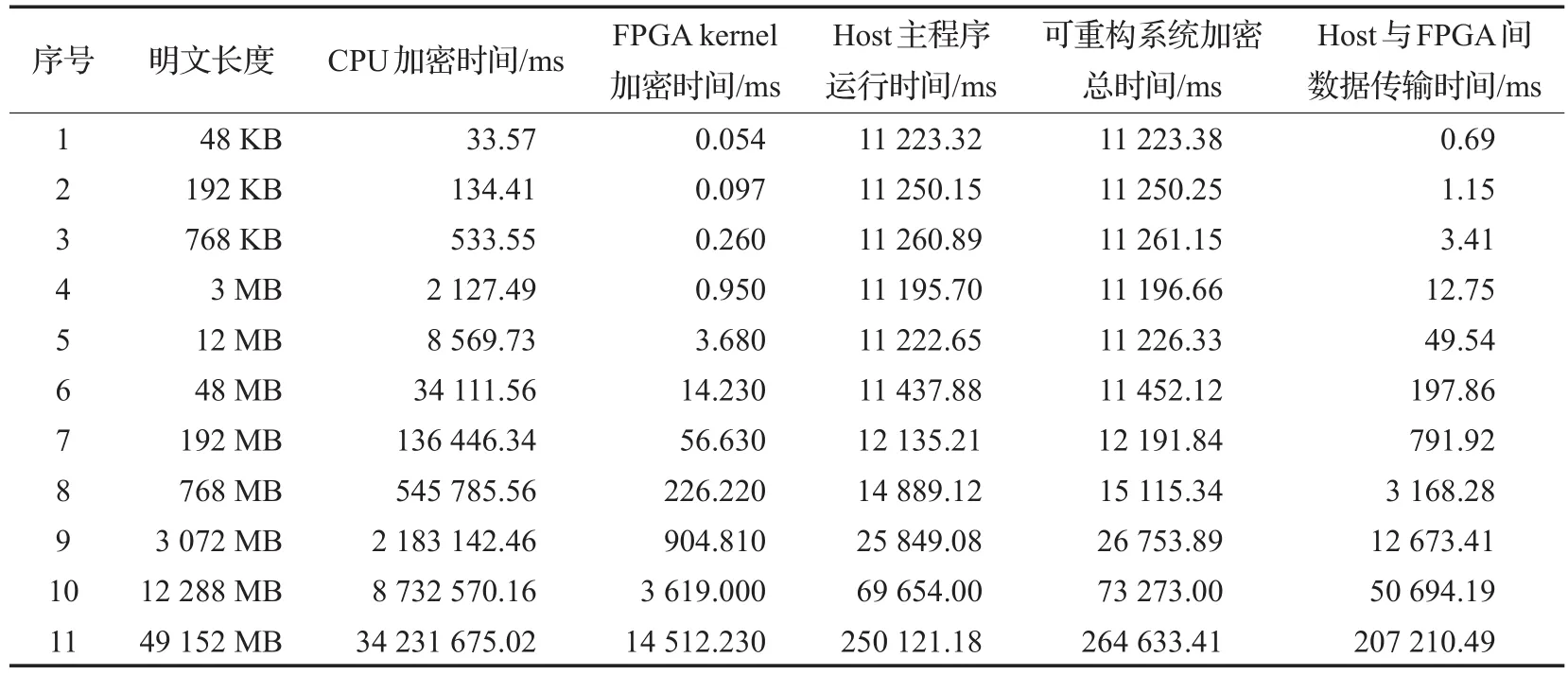
表2 国产平台测试环境加密性能对比
4.2 实验结果与讨论
实验对bmp图片进行加密实验,为了提高实验结果的可靠性,每种长度的明文均加密三次,然后取中间值作为最终结果。分别采用本文设计的可重构系统与CPU串行程序对不同长度的明文进行加密,以获得AES加密性能对比,其中在CPU上运行的加密程序为单线程程序。所得实验结果如表2所示。
表2中CPU加密采用串行单线程,FPGA kernel加密时间为FPGA执行AES加密任务所占的时间,Host主程序为可重构系统中在Host上运行的程序,包括获取设备信息、创建上下文、由二进制kernel创建Program、创建Buffer、数据传输、密钥扩展等函数。
由表2可以看出:
(1)FPGA加密时间远远小于CPU加密时间。
(2)在明文长度较短的情况下,可重构系统加密的总时间要大于CPU加密时间,但是随着明文长度的增大,CPU加密所耗的时间要远远超过可重构系统。
(3)CPU加密时间随着明文长度的增加成比例线性增大。
(4)在明文长度较短(小于192 MB)的情况下,Host主程序运行时间没有显著增大,但当明文长度继续增加时,Host主程序运行时间会呈现出增大趋势。这是由于在明文长度较小时,Host主程序中clCreateProgram-WithBinary和clCreateContext为主要耗时函数,分别耗时6 750 ms和4 400 ms左右,而这两个函数所占时间与明文长度无关。当明文长度增大时,主程序中的数据拷贝函数clEnqueueWriteBuffer和clEnqueueReadBuffer函数所占时间将会占主导地位,这些函数的执行所占时间与明文长度成比例线性关系。
图7为可重构系统加密总时间与CPU串行加密时间对比图,由图可见,在明文长度较大时,可重构系统的加密总时间要远远小于CPU加密时间,且CPU加密时间会随着明文长度的增加而线性增大,而可重构系统的加密时间增长缓慢。

图7 可重构系统加密总时间与CPU串行加密时间对比
图8 为AES串行加密与FPGA并行加密的吞吐率对比图,由图可见,明文长度在48 KB~3 MB之间时,FPGA并行加密吞吐率增长较快,明文大于3 MB后,FPGA并行加密吞吐率趋近于稳定,而CPU串行加密吞吐率在整个阶段都远远小于FPGA并行加密。
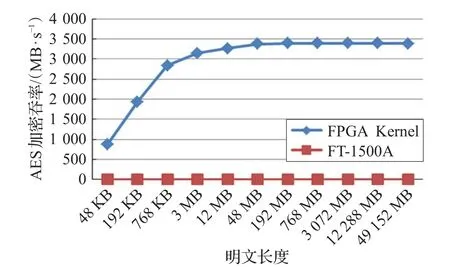
图8 AES串行加密与并行加密吞吐率比较
图9 为可重构计算系统并行加密相比于CPU串行加密的加速比,可见,加速比随着明文长度的增加而增大,在明文长度为49 152 MB时,加速比可以达到120多倍。
5 结束语
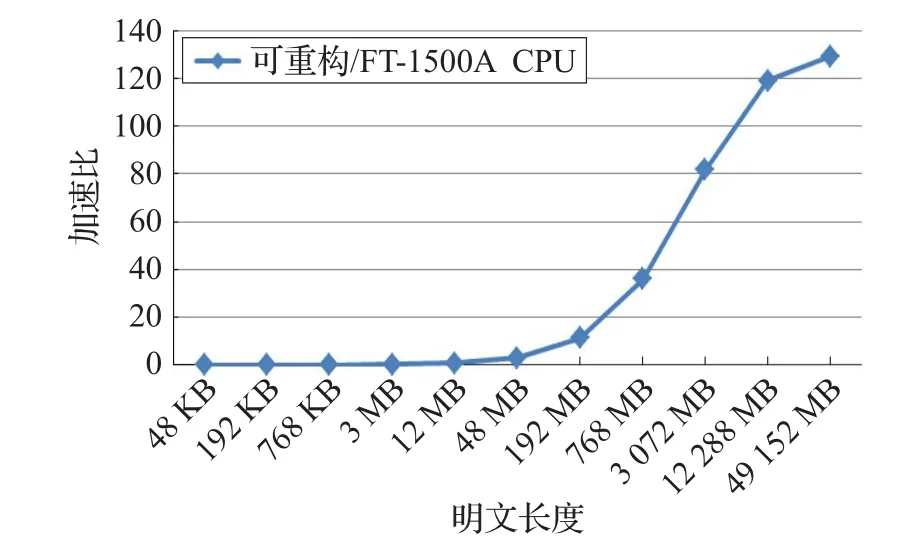
图9 可重构计算系统相比FT-1500A串行加密的加速比
为了提升国产计算平台的处理性能,本文设计了基于国产CPU的可重构计算系统。该系统包括基于国产CPU的主机单元和FPGA可重构加速单元,主机单元负责逻辑判断与管理调度等任务,FPGA负责对计算密集型任务进行加速,并支持基于OpenCL框架标准的编程方式。通过采用AES加密算法来测试本系统的计算性能,并与CPU串行处理结果进行对比,得出:相比于FT-1500A CPU串行加密,采用可重构计算系统并行加密能够获得120多倍的加速比,且在明文长度较大的情况下,可重构系统总的加密时间会远远小于CPU串行加密时间。实验结果表明:本文设计的基于国产CPU的可重构计算系统能够大幅提升国产平台的计算性能。
