基于特征加权贝叶斯神经网络的微博异常账号检测∗
2018-11-28邱秀连
王 峥 叶 维 邱秀连
(1.南京烽火星空通信发展有限公司 南京 210019)(2.武汉邮电科学研究院 武汉 430074)(3.南京烽火天地通信科技有限公司 南京 210019)
1 引言
随着web2.0技术的不断发展和完善,在线社交网络平台已经成为了现代人们生活中一种必不可少的娱乐和交流的方式[1]。国外的社交平台主要是Twitter、Facebook,国内的主要是新浪微博平台,这些社交平台的用户增长率连续翻倍。
目前国内最大、最流行的中文社交平台是新浪微博,该平台掀起了国内的微博潮流,带动了整个中国微博产业的蓬勃发展。微博具有高度实时性与互动性的特点,以多元化、平民化的传播方式逐渐成为网民上网交流、信息传播的重要途径。但是由于微博有着裂变式的传播方式,在传播正常信息的同时也很容易吸引大量的垃圾信息,比如广告、诈骗信息等,这些信息不仅影响用户对于正常的信息阅读,而且还严重伤害了用户体验度。一些垃圾信息发送者利用微博大量发布钓鱼网站和虚假链接,拦截用户的正常信息,推送大量的广告和恶意信息,有时甚至会发布危害国家安全和稳定的谣言[2]。但传统的垃圾信息过滤的方法在微博数量较少的情况下可以取得不错的效果,但是随着微博数量呈现爆炸式的增长,传统的垃圾信息过滤方法的识别正确率越来越低,并且计算开销也越来越大。因此,高识别率和低开销的垃圾信息识别方法已经逐渐受到了学术界的关注和重视。
2 垃圾信息过滤方法概述
相比于传统的垃圾邮件过滤技术,针对社交平台上垃圾信息发送者(Sammer)检测的研究现在仍处于初级阶段,而这其中的绝大多数研究者们又都以Twitter平台为研究对象,以中文社交平台为研究对象还是占少数。
从前很多从事于垃圾邮件过滤技术的研究者们,随着网络社交平台的快速发展,这些研究者们也将目光集中在了以Facebook为代表的社交平台,开始致力于社交平台上的垃圾信息过滤。其中较著名的反垃圾信息的会议有国外的TREC[3](Text Retrieval Conference)、CEAS[4](Conference on Email and Anti-Spam)以及国内的SEWM(Search Engine and Web Mining)会议。这些反垃圾信息会议不仅给研究者们提供了相互交流、论证的机会,也促进了反垃圾信息研究的发展。同时在微博异常账号检测领域,积累了大量的理论基础和完整的评价指标。
针对新浪微博独有的数据特点,于然等提出一种基于多视角特征融合的中文微博垃圾信息检测方法[5],计算每条微博中出现的形容词、动词和名词的比例和长度,“我”出现的次数等基于潜在语意计算的词性特征。针对获取到的微博数据信息稀疏性大和特征偏移严重,且微博数据的噪声干扰项多等特性,孙建旺等提出了一种基于微博转发集的微博垃圾信息过滤方法[6],该方法通过微博数据构建三元组(转发时间差、子串、频次),然后将知网作为补充语料库,进而构建知识元,之后形成候选文本集合,对其进行进一步筛选,最后得到用户需求的微博。针对在网络虚拟社区中出现的文本信息复杂且不规则的特点,张磊等使用正则表达式对待过滤文本进行过滤匹配[2],从而获得非常规词或符号的基本特征。将文本进行分词处理,并且建立停用词表,之后使用IF-IDF进行特征选取,最后选取出235个词作为文本过滤的特征项。针对传统垃圾信息过滤方法在过滤过程中会出现随时间变化而发生概念漂移的问题,夏虎等提出了一种基于反馈的不良网站过滤的方法[7]。
在传统的账号检测方法当中,大多都是单一地针对微博账号的行为特征或者针对微博账号的发布内容进行研究,从而导致账号检测的正确率不高。本文将微博的行为特征和发布内容相结合,并且通过特征加权贝叶斯神经网络,解决了账号检测的正确率不高的问题。
3 理论研究
3.1 特征加权贝叶斯
贝叶斯分类算法是一类分类算法的总称,是统计学的一种分类方法,这类算法均以贝叶斯原理为基础。由于类条件概率需要计算出所有属性上的联合概率分布,在实际过程中,每个属性之间都有着或多或少的联系,因此从有限的训练集中难以直接估计得到类条件概率。为了解决这一困难,我们假设待分类项的各个属性相互独立的情况下,构造出来的分类算法就称为朴素的,即朴素贝叶斯算法。朴素贝叶斯为在基于属性条件独立的前提下的同时还包含了一个条件,即每个条件属性的权重值均为1,也就是说每个特征对于决策分类的重要性是相同的,但是在实际应用中,各条件属性对分类的贡献程度不是完全相同的[8],因此这个条件会降低模型的分类正确率。从朴素贝叶斯属性加权基本思想出发,在微博账号的所有行为特征当中,其中必定有一些行为特征会对决策特征起着决定性的作用,同样也会有一些行为特征对于决策的影响相对来说比较小,也就是噪音干扰项,那么对于前者就可以给予一个相对较大的权值,而对于后者则给予一个较小的权值。为了更加准确地确定每个行为特征的的权值,本文通过计算行为特征与决策特征之间的相关概率来确定其行为特征的权值[7]。
设 A={A1,A2,…,An}为行为特征变量集,n为行为特征的数目。对于某个行为特征Aj,用akj表示该行为特征的一个具体的取值,其中k∈[1,m],表示行为特征Aj有m个可能的取值,那么对于一个具体的微博账号X来说,当X的行为特征Aj取值为时,对于每一个类Ci来说,行为特征Aj都有一个关于Ci的相关概率 p(Aj|rel)和不相关概率p(Aj|norel):
其中,COUNT表示行为特征的数量。
由于某个行为特征的权值可能会出现等于零的情况,因此将p(Ci)的概率调整为
式(3)中 ||Ci表示训练集中属于类Ci的微博账号数, ||C训练集中包含的微博账号总数。对于每一个行为特征的具体取值,其权值按照如下公式计算:
因此最终的特征加权贝叶斯算法的计算公式如下:
特征加权贝叶斯是通过计算行为特征的相关概率和不相关概率的比值来确定行为特征权值的大小。对于一个给定的微博账号来说,在计算其属于某个类标签下的后验概率时,对每一个行为特征的条件概率来说,将为该行为特征的当前取值确定一个权值,其权值大小为当前类标签的相关概率。由此可以看出,在同一个行为特征中,该特征取值的不同,其权值是不同的;并且同一个行为特征的同一取值,当它们在不同类标签下的权值也是不同的。
3.2 贝叶斯神经网络(BNN)
传统的神经网络模型是通过控制输入与输出数据之间的误差来进行网络权值的更新[10],其输入输出关系可以表示为

式中f(x|ω) 为近似函数,E为误差项。
贝叶斯神经网络对于网络权值的更新是通过计算网络权值的后验概率,最后给出的是网络权值概率分布的范围,因此由Bayes定理可以得到[11]:
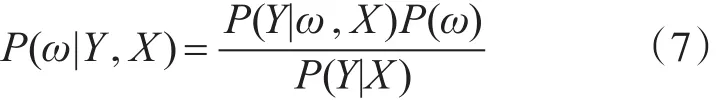
其中 X=(x1,x2,…,xn),Y=(y1,y2,…,yn)。
式中X为输入矢量,Y为目标矢量。
P(Y|X)= ∫P(Y|ω,X)P(ω)dω是目标输出矢量 yi的边际分布。P(ω)是权值ω的一个先验分布,而P(Y|ω,X)是似然函数。其中,边际分布是一个正则化的常数。权值ω的先验分布是一个已知的值。因此yn+1预测性分布为
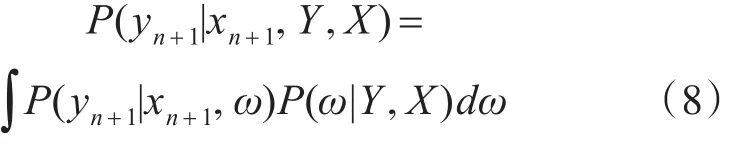
式中xn+1,yn+1表示下一次输入和输出数据的集合。由式(8)可以看出,yn+1预测性分布的积分十分的复杂,无法用传统的解析或数值积分的方法求得[12]。
为了计算出贝叶斯神经网络预测性分布,需要计算出贝叶斯神经网络的权值的先验分布[13],但是在实际过程中网络权值的先验分布通常是十分复杂的,为了方便计算,通常权值的先验分布是由一个建议分布来产生权值矢量,因此该分布通常是一个局部的高斯函数。MCMC方法可以从连续的先验分布中随机产生多个权值,由于建议分布取决于前一次迭代的权值,因此最开始需要从权值的先验分布中任意选取一个权值,之后的权值就可以通过MCMC来随机产生,并且这些权值应该满足:
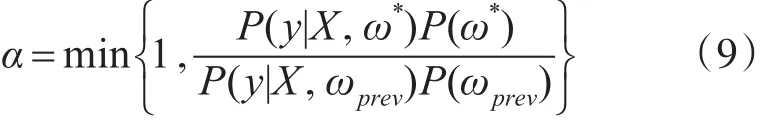
式中,ωprev为前一次迭代的权值,α为建议分布。
如果通过马尔可夫链确定的新权值ω*被接受,那么ωprev就被ω*替代,开始下一次的迭代。而权值被接受率在30%~70%之间被认为是最优的。
4 基于特征加权贝叶斯神经网络的账号检测模型
4.1 算法模型建立
对于账号检测(Ci(i=1,2))的分类问题,对第k个微博账号有n维的输入行为特征向量xk,1维的输出yk表示属于C1的概率,而属于C2的概率为(1-yk)。假定有网络模型H,此网络相应的权值ω=(ω1,ω2,…,ωw),W为权值的总个数,则对于数据集 D={(xk,yk),k=1,2,…,K}(K为样本总数)和网络模型H来说,传统神经网络方法通过最小化误差函数ED=-ln(p(D/w)),调整权值ω,找到合适的网络模型。这种方法的缺点是当训练的微博账号有限时,难以找到适合微博账号检测的模型。在贝叶斯神经网络中[14~15],同时考虑权值的先验分布和微博账号的似然分布,通过引入超参数控制权值的分布,最小化误差,实现权值的优化[16]。
根据特征加权贝叶斯神经网络的原理[17],整个过程要经过以下步骤:
1)在给定神经网络模型H,微博账号检测数据D,及超参数α和 β的初始值的条件下,计算网络权值ω的后验概率,求得满足后验概率最大的权值。
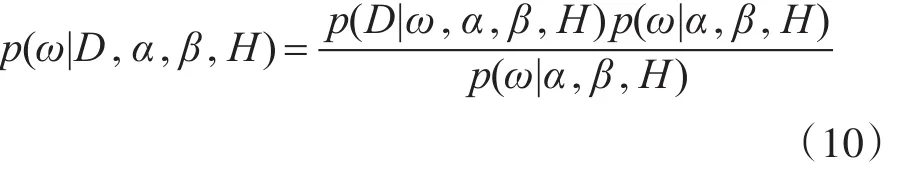
2)结合微博账号数据D,计算超参数的后验概率,更新超参数α和β。
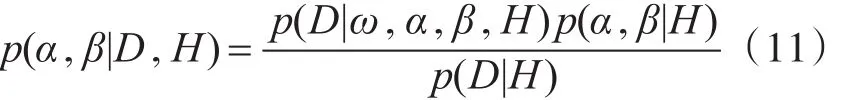
3)计算各个模型的显著度,选择后验概率最大的模型,从而确定最优网络。
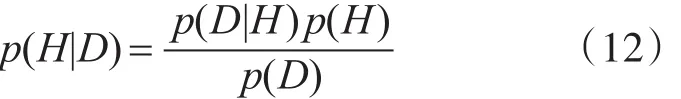
在假定网络权值的先验分布和微博账号的似然均服从指数分布的情况下,可以得到网络权值的后验分布为
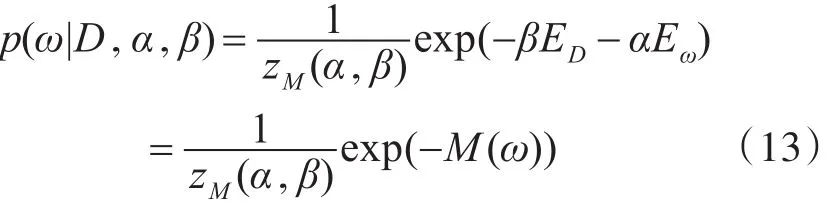
在贝叶斯神经网络中,微博账号的所有行为特征的初始权值都是一样的,但是在实际生活中,微博账号的行为特征与决策特征的密切关系是不一样。因此本文在贝叶斯神经网络(BNN)的基础上加入了特征加权贝叶斯算法,构成了特征加权贝叶斯神经网络(WBNN)。特征加权贝叶斯神经网络的整体流程如图1所示。
通过Python爬虫获取微博账号的行为特征和发布内容,最终得到2194个微博账号的行为特征和发布内容。在微博账号的行为特征和发布内容中一共选取了12个特征,其中包括微博的粉丝数、关注数、是否认证、微博内容相似度、点赞数、评论数、转发数等等。然后将这些特征进行归一化处理。为了验证本文组合模型的有效性,通过建立BNN和BP神经网络(BP-NN)模型来进行对比分析。
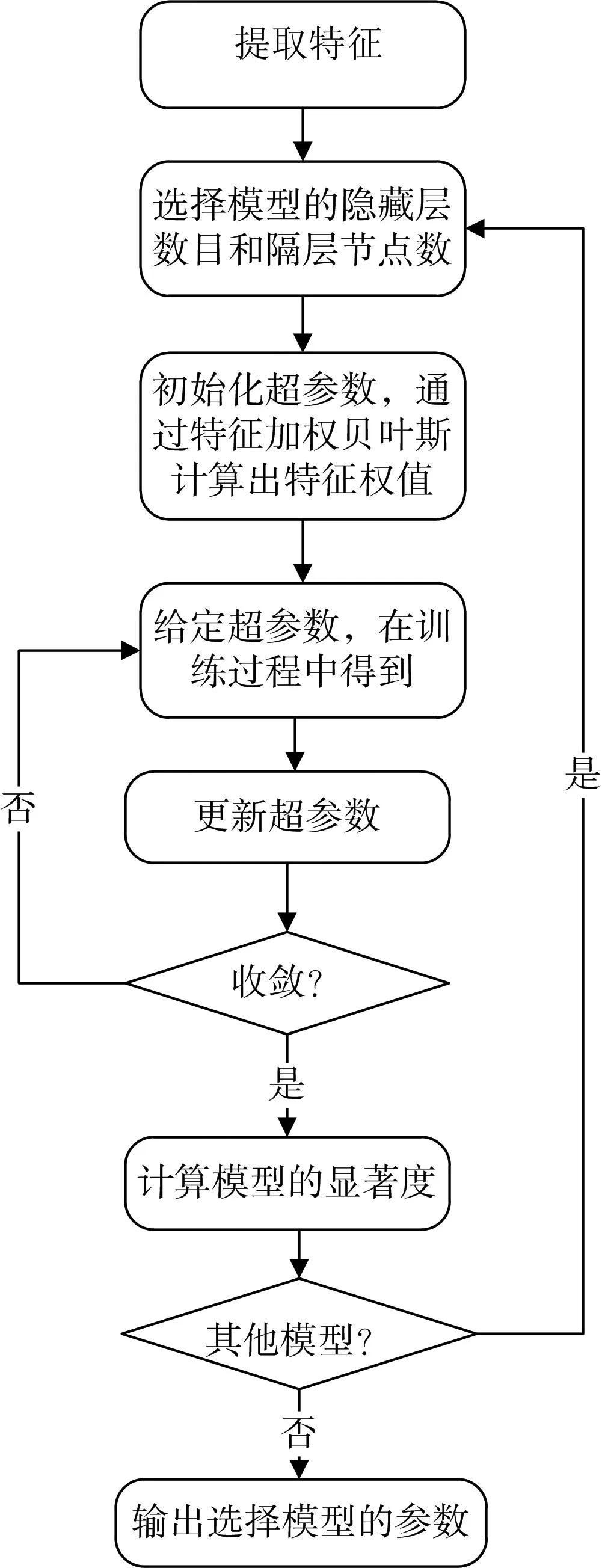
图1 特征加权贝叶斯神经网络的流程图
4.2 结果分析
WBNN,BNN和BP-NN的结构均为“12-200-2”形式,训练集与测试集的比例为4∶1,学习率设置为0.1,目标误差为0.01,训练最大次数为500。本文的所有实验都是在Python3.6环境下进行的。最后将预测的类别与正确的类别作对比,计算出各个模型的预测正确率。为避免随机性对预测结果的影响,各模型每次实验均独立运行5次,表1给出了WBNN,BNN和BP-NN的预测准确率。
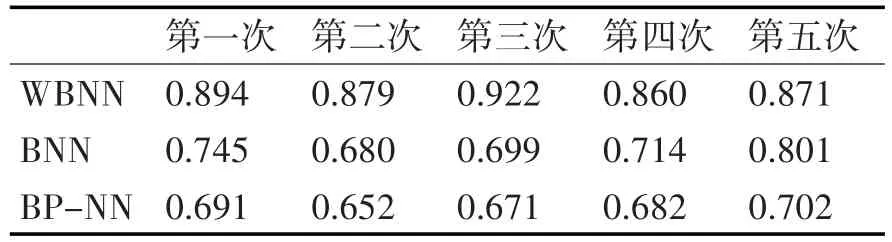
表1 WBNN,BNN和BP-NN的预测准确率
由表1可知:
1)WBNN的平均预测准确率为88.5%,BNN的平均预测准确率为72.8%,BP-NN的平均预测准确率为67.9%。
2)对比BP-NN和BNN可知,后者的预测准确率提高了4.9%,说明BNN与BP-NN相比,有着更高的预测精度,具有更强的泛化能力。
3)对比BNN和WBNN可知,后者的预测准确率提高了15.7%,说明使用特征加权贝叶斯优化BNN的网络权值可以有效地提高模型的预测精度。
为了更好地评测WBNN的分类性能,计算出WBNN和BNN的召回率,并且画出两种模型的ROC曲线。
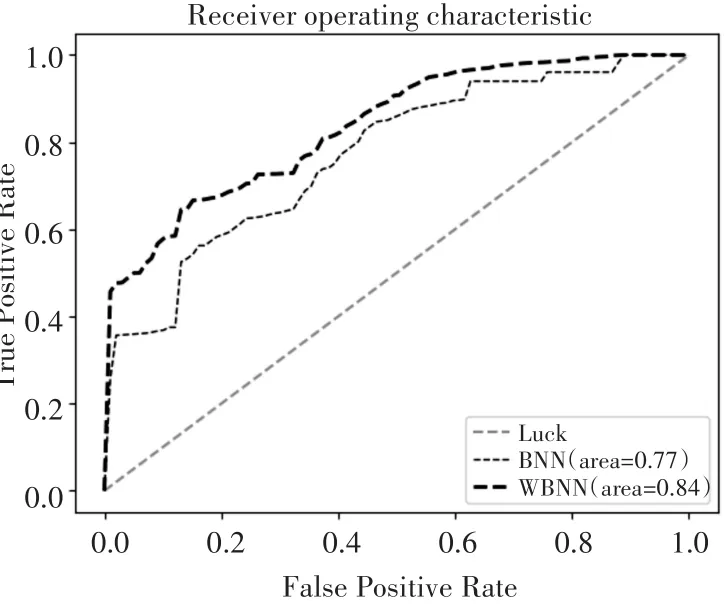
图2 WBNN和BNN的ROC曲线
由图2可知:对比WBNN和BNN的ROC曲线可知,WBNN的AUC值提高了7%,说明WBNN有着较高的预测精度,具有更强的泛化能力。
5 结语
针对微博异常账号的检测,提出了一种基于特征加权贝叶斯神经网络的组合检测模型,实例研究表明:
1)贝叶斯神经网络比传统BP神经网络具有更高的预测精度,显示出其在微博异常账号检测中的应用潜力;
2)与贝叶斯神经网络相比,采用特征加权贝叶斯神经网络对神经网络进行权值和阈值寻优时预测精度更高,表明WBNN具有更优良、更稳定的全局寻优能力;
3)与其他模型相比,WBBN具有更优良的预测性能,有效地提高了预测精度。本文所提出的组合模型能取得较高精度的微博异常账号检测结果。
