基于Hadoop的海量图像处理研究
2018-11-21郝林倩王明辉
郝林倩,王明辉
(1.福建船政交通职业学院,福建 福州 350007;2.四川大学,四川 成都 610065)
互联网的快速发展让我们进入了大数据时代,越来越多的人通过图像、文字和视频记录生活点滴,大量的网络图像信息有助于互联网公司准确把握商业营销和发展方向[1]。对于海量图像数据,单一服务器已经远远无法满足用户需要,互联网公司和科研机构亟需解决的一个问题就是存储和分析海量图像。Hadoop是一种开源的分布式处理平台,包括分布式文件系统HDFS和计算框架MapReduce,用户可以快速完成分布式任务。Hadoop平台具有良好的扩展性,集群构建与多台服务器上,可以同时管理上千台服务器,提供大容量存储服务,也可以将复杂的运算问题分发到不同服务器上操作,提升运算速度。在一个规模较大的服务器集群中,如果一台服务器出现问题,那么Hadoop能够自动从其他服务器上访问数据,提高数据存储的鲁棒性,容错性比较高。Hadoop平台具有高易用性,API服务非常丰富,例如文件操作、系统管理、MapReduce任务管理等等,用户分布式程序的开发相对容易。Hadoop在海量数据存储和计算方面具有突出的优势,本文借助OpenCV中的现有函数来完成图像处理,能够实现海量图像的存储、数据管理、计算和可视化展示。Hadoop平台并不能直接地用于处理图像,首先要设计适用于Hadoop平台的图像数据类型,然后借助OpenCV简化图像处理过程[2-3]。
1 Hadoop平台与数字图像处理
1.1 分布式文件系统
HDFS是Hadoop的文件存储系统,为Hadoop系统及其上层应用提供了稳定可靠的存储保障。HDFS的硬件来源于商业硬件,数据访问能力非常强,在容错和吞吐量方面具有突出优势,能够同时存储海量数据。
HDFS的基本架构为主从式,包括一个主节点以及多个从节点,主节点为NameNode,主要是完成元信息维护功能,从节点为DataNode是存储数据的区域,并且及时地报告节点状态给主节点。如果从节点超过固定的时间没有将节点状态发送给主节点,那么会自动判断从节点宕机,会被移出系统,并且自动将这个从节点的信息复制保存在其他节点[4]。
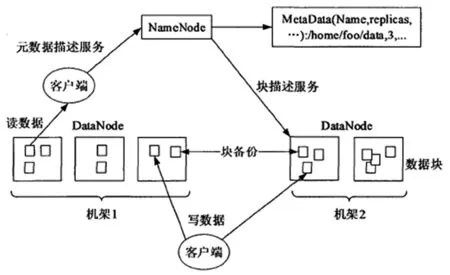
图1 HDFS框架结构示意图
HDFS可以将文件拆分成固定大小的块,然后按照负载均衡算法将这些块存储在不同的DataNode上,为了确保数据可靠,同样的块要分别存放在不同的DataNode上。数据块的存放原则是其中一个存放在输出节点上,同一个机架下的不同存储器上存储一份,不同机架上的存储器中存储一份。不同数据块对应不同的编号,所有镜像文件要存储在本地磁盘上。
文件读写同时涉及到DataNode、NameNode和客户端之间的交互,建立RPC通信通道,现有系统中已经封装了简单的通信接口,所以通过客户端实现文件读写比较简单。文件读写的流程分别如图2中的a和b所示。
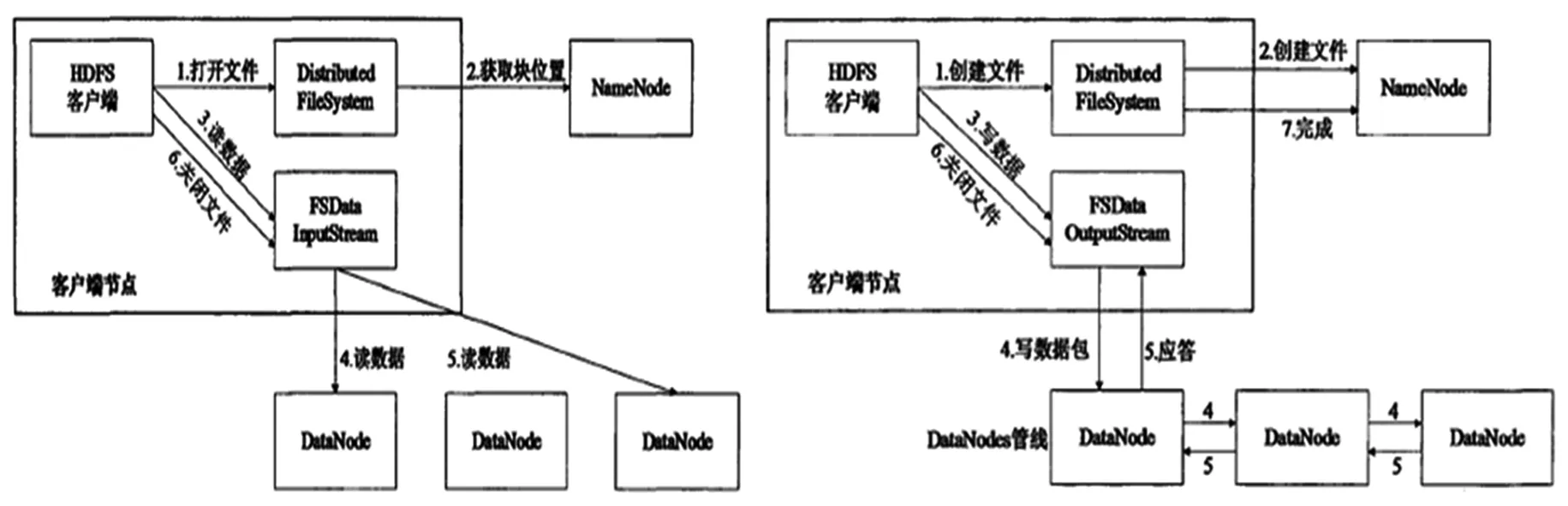
图2(a) HDFS读操作流程示意图 图2(b) HDFS写操作流程示意图
1.2 分布式计算框MapReduce
MapReduce属于Hadoop海量数据处理时的基础模型,能提供分布式计算服务。MapReduce编程模型中,底层具有良好的程序封装。用户在实践过程中,将需要的运算算法转换成为MapReduce的程序,就可以完成计算。MapReduce模型的各项操作都是在明确的框架中自动完成的。MapReduce可以让每一个节点都参与到大数据运算过程中,通过分布式运算方式有效提升效率,节点越多,运算能力越强。
为了拓展MapReduce的使用范围,降低编程的难度,系统不仅能够支持Java编程语言,同时也支持Streaming运行。Streaming运行方式下,Ruby和Python脚本语言都能够运行。Unix的标准输入和输出能够与其他程序建立交互接口,可以通过其他语言来读取和输出数据[5]。MapReduce按照分而治之的思想建设,其工作可以分为两个部分,分别是Map和Reduce。
1.3 数字图像处理
数字图像是指用工业相机、摄像机、扫描仪等设备经过拍摄得到的一个大的二维数组,该数组的元素称为像素,其值称为灰度值。当今社会,信息化发展迅速,计算机在信息处理过程中发挥着重要作用,计算机数字图像处理技术的发展也越来越快,在生活和生产中应用逐渐普及。例如,指纹识别打卡系统、售票机自动识别纸币、电影特效等领域都随处可见图像处理技术。
在互联网快速发展的背景下,互联网上积累了大量来自于用户的海量数据,如何挖掘这些图像背后的数据就显得非常重要。图像数据挖掘是从大量图像数据中挖掘和提取有用信息,这一技术在医疗、遥感等领域应用非常广泛。数据挖掘算法首先需要提取待挖掘数据的特征。图像特征可以分为三大类:统计特征、视觉特征、变换系数。统计特征包括图像的灰度直方图特征、矩特征。视觉特征可以分为三种:颜色特征、纹理特征和形状特征[6,7]。
2 图像键值类型和格式设计
2.1 图像键值类型
MapReduce编程模型包括Map和Reduce两个过程,每一个环节的输入输出都是键值。如果Map的输入值是键值,那么输出的是一个或者多个键值对。Reduce过程就是输入的键是现有键的对集合,然后对现有键值进行归集操作,最终输出一个或者多个键值对。
在分布式计算过程中,键值对在不同服务器之间传送,处理之后的新的键值写入本地磁盘。所有的键值对之间需要建立序列化的接口,可以将结构化的数据转换为字节流,持久保持在磁盘中,也可以支持网络传播。从Map到Reduce输出数据的过程被称为Shuffle,Hadoop平台中的所有键值类型必须实现WritableCmparable接口,键值必须实现Writable接口。
Hadoop中并没有提供图像的数据类型,所以要改编数据的类型。在MapReduce程序设计的过程中,键为图像名,值为图像的内容。按照文件名称也就是键可以将图像分组,并且图像名称较小,可以实现高效排列。在Java语言中没有涉及用于图像处理的数据类型和函数,所以需要从最基础的图像像素开始进行底层处理,这是非常复杂的。因此,在本文研究中,将第三方的软件OpenCV引入到Hadoop平台中,便于进行图像的预处理、图像的特征提取以及图像数据挖掘等。
图像数据类型包括RawImage和MatImage。RawImage类用于存储图像文件的二进制数据,输入流或者本地的图像路径都可以作为其函数构造参数,可以将读取到的图像数据存储到Rawdata数组中,然后利用Getrawdata函数获取二进制数据。MatImage类是集成于OpenCV,能够实现Writable接口,可以实现对于Mat的序列化,支持在Hadoop平台上存储图像或者矩阵数据。RawImage存储的所有图像都是经过压缩编码的二进制数据,占磁盘空间比较少,适用于处理海量图像。MatImage能够存储矩阵,不需要图像编码,存储的元素类型比较多样,但是比较适用于少量图像集。在实际应用中,可以按照需要选择合适的数据类型。
2.2 图像输入输出的格式
MapReduce在执行Mapper操作时,必须通过输入格式将信息解析为键值才能传送给Map,在执行Reducer操作时,需要通过图像输出格式将键值输出到存储设备中。InputFoamat是输入格式的基类,其中方法GetSplits负责将输入的数据分片处理,方法CreatRecordReader负责将被分片解析为键值对。
MapReduce的输出格式基类为OutputFoamat,属于抽象类,如果方法CheckOutputSpecs负责检测是否设置好输出路径、是否存在输出文件,GetRecordWriter方法负责将输出的键值持久化保存。
3 Hadoop数字图像处理平台设计
基于Hadoop的海量图像处理平台,能够实现图像的基本处理、分析以及信息挖掘任务。本文采用比较成熟的Hadoop平台,利用本系统设计,简化开发工作。
3.1 平台技术架构设计
基于Hadoop的海量图像处理平台的底层为分布式文件系统,HDFS为上层应用提供分布式存储,处理结束后的图像也保存在HDFS上。图像梳理部分提供图像数据类型,并且结合第三方软件OpenCV,直接引用其中的图像处理函数。图像输入和输出格式将图像解析为键值,然后利用MapReduce来处理图像,然后通过图像输出格式将新图像存储起来。MapReduce提供的是分布式框架,先分片化处理输入的图像集,然后进入Mapper处理环节,对运行全过程进行监控。在分布式计算框架这一层,可以结合OpenCV实现图像处理。最上层的是Mabout,为图像分析和图像信息挖掘提供支撑。
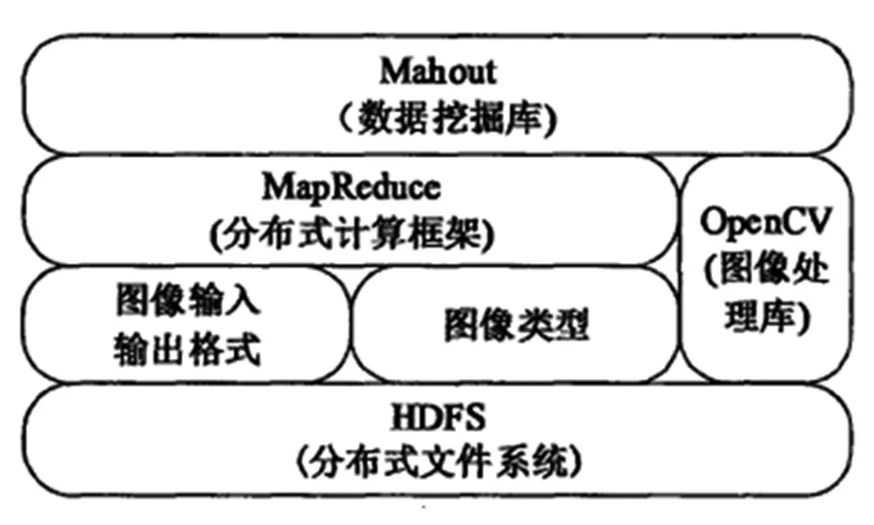
图3 基于Hadoop的海量图像处理平台技术架构示意图
3.2 模块设计
图像处理平台共包括四个模块,分别是图像导入层、图像管理层、图像计算层以及展示层。
图像的导入模块负责将图像接入到集群上,将待处理图像存储到HDFS上。这些待处理图像位于服务器上,可以通过网络收集图像,然后通过API将图像写入集群。可以采用多线程同时运行的方式来提高图像传输效率。如果待处理的图像位于本地,那么也可以利用Hadoop的命令直接上传图像文件。
图像管理层主要是对存储图像进行删除、更新以及合并等操作,每一个导入的图像都是独立的小文件,如果图像为海量图像,就将这些小文件合并成一个大的SequenceFile文件。图像较多时,可以采用MapReduce程序来处理。图像导入和管理层负责存储与管理,图像计算层是核心计算部分,主要完成图像处理任务,例如图像的初始化、图像变换、图像特征提取等,基本都是通过MapReduce程序来完成任务。图像展示层是用于展示存储的图像,可以将图像文件直观地呈现出来,便于观察和分析输出结果。
3.3 计算层图像处理
Hadoop平台上的图像处理流程,第一环节是通过独立存储或者打包图像的方式输入图像,然后进行图像计算,最终输出图像处理结果,输出的图像可以通过独立存储、打包、输出图像特征的方式输出。
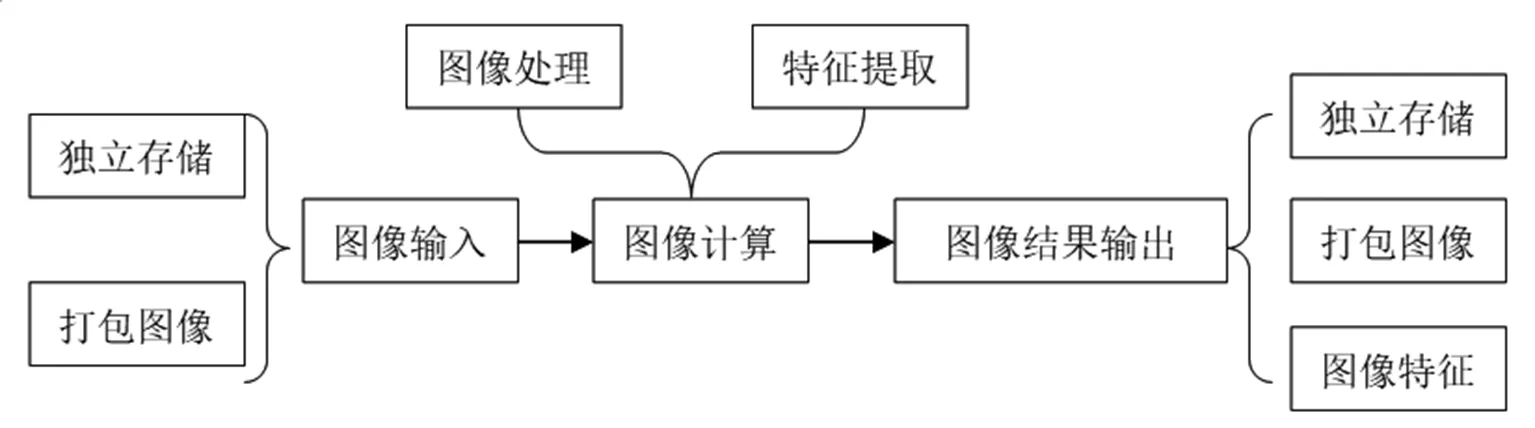
图4 图像处理流程示意图
3.4 验证分析
在实验室环境中配置一个服务器,通过桥式连接的模式安装9台虚拟机,集群为分布式模式,内存4G,硬盘500G,操作系统为Ubuntu12.04,开发环境为Hadoop2.4.0和jdk1.6.0_32。将图像分别分为大小不等的分片,通过系统运行验证其运行速度和任务时长。

表1 不同分片方案对应的处理结果
可以看出,分片大小增加的同时,片数会减小,每个Map的平均运行时间会增加。不管分片大小如何改变,最终输出的总量不变,Reducer个数也不变,平均的Reducer时间基本不变。
4 结论
基于Hadoop的海量图像处理平台能够完成图像基本处理,结合Mathout也能够完成更深层次的数据挖掘,系统具有良好的通用性,该平台适用于大多数图像处理场景,这种分布式的图像处理平台相对于单机图像处理具有更好的效率,能处理海量数据,满足生产需要,适应大数据时代的发展潮流。
