基于最长属性路径过滤的SPARQL查询优化
2018-11-20林晓庆程经纬
林晓庆,张 富,程经纬
(1.东北大学 计算机科学与工程学院,沈阳 110819; 2.辽东学院 信息工程学院,辽宁 丹东 118003)
0 概述
资源描述框架(Resource Description Framework,RDF)现已成为语义网数据表示和交换的核心模型,因此,可用的RDF数据越来越多。RDF数据是陈述的集合,形式为(Subject,Predicate,Object)三元组,其中,Subject为主语,Predicate为谓词,用于联结主语和宾语,Object为宾语。SPARQL是标准的RDF数据查询语言,因其可对RDF数据查询以获得有用的Web信息,故被广泛应用。但是在SPARQL查询执行处理过程中会产生大量冗余的中间结果,尤其在处理大规模的RDF数据时,这大幅降低了SPARQL查询的执行效率。因此,SPARQL查询优化处理成为了研究热点。
早期的RDF搜索系统是面向RDF三元组行存储的关系式数据库管理系统,例如Jena[1]及Sesame[2]等。这些系统利用关系式数据库管理系统的查询处理模块对RDF数据进行存储和处理。SW-store[3]、RDF-3x[4]、Hexastore[5]和gStore[6]能够有效地处理大规模的RDF数据,其中SW-store采用垂直分割存储,将三元组表按谓词进行分割,能够快速合并联接。目前多数SPARQL优化技术主要通过制定一个最优的查询执行计划来减少中间结果。文献[4]利用动态规划方法估计最优的查询执行计划,该方法需要指数级数量的时间和空间的开销,而且没有利用RDF数据图结构信息。文献[6]提出一种VS树和VS*树索引,利用子图匹配进行带通配符处理或精确的SPARQL查询处理。文献[7]通过RDF图属性路径索引过滤掉冗余的中间结果,取得了较好的效果,但该方法不处理包含文字和空节点的三元组模式,并且只利用了属性路径索引信息。文献[8]提出了一个对大规模RDF数据动态计算查询代价的查询优化方法,但该方法需要较大的存储开销。目前,基于分布式RDF存储的查询搜索引擎开发也吸引了很多研究者的注意[9-11],这些分布式RDF系统能够减少输入的联结,比集中式存储更能有效地提高查询性能,因为网络上传输查询中间结果的开销很大。文献[12]提出2个辅助的索引结构:ID-块位矩阵和ID-谓词位矩阵,通过查询处理器动态地产生联结执行的顺序以降低中间结果。文献[13]利用在原始的RDF数据图上提炼有效的RDF图索引,通过该索引进行中间结果过滤。文献[14]则结合哈希映射和选择策略树进行SPARQL的查询优化。
为提高SPARQL查询的执行效率,本文根据RDF数据图的结构特点,通过使用属性路径与基于关系的存储模型,提出一种两阶段SPARQL查询优化方法。第一阶段将SPARQL查询按所含的公共变量进行分块,第二阶段则利用选择度计算最长属性路径,从而过滤中间冗余结果。
1 SPARQL查询及查询执行
SPARQL[15]已经被W3C推荐为RDF数据的标准查询语言,是一种通过在RDF数据上进行三元组模式匹配来获取结果的查询语言。一个基本的SPARQL查询由SELECT子句和WHERE子句构成,其中,“pattern1”“pattern2”等都是三元组模式,操作符“.”联结2个三元组模式,每个三元组模式都由主语、谓词、宾语构成,这三项为文字或者为变量。在查询中,将已知的用文字表示,未知的用变量表示,如下所示。
SELECT ?variable1 ?variable2…
WHERE {pattern1.pattern2.… }
由LUBM基准给出的第9个查询实例Q9如下所示。在该实例查询中,查询所有学生、教师及课程并且满足课程由学生选择、教师教授学生、授课老师是学生的指导教师,“rdf”和“ub”都是前缀,“?X rdf:type ub:Student”等都是三元组模式。本文处理的SPARQL查询可以包含谓词为变量的三元组模式。
PREFIX rdf:
PREFIX ub:
SELECT ?X ?Y ?Z WHERE{
?X rdf:type ub:Student .
?Y rdf:type ub:Faculty .
?Z rdf:type ub:Course .
?X ub:advisor ?Y .
?Y ub:teacherOf ?Z .
?X ub:takesCourse ?Z}

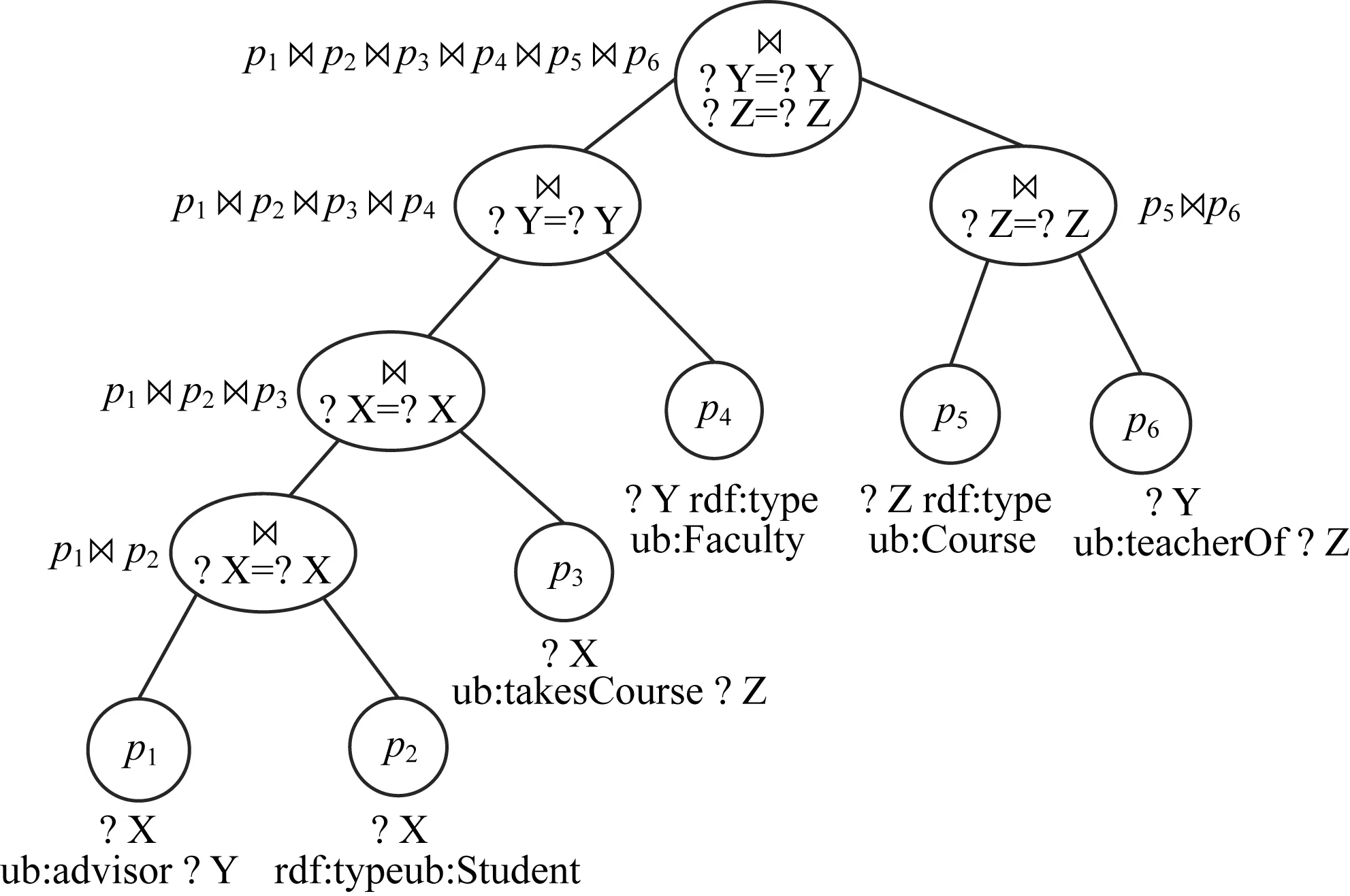
图1 Q9的一个查询执行计划

表1 不同联结产生的中间结果数量
2 SPARQL查询优化
本文优化方法流程如图2所示。在第一阶段,将SPARQL查询图进行分块,在块内按每个联结代价重新排序并执行部分联结,代价的估计根据联结产生中间结果的数量;在第二阶段,利用最长属性路径索引过滤掉冗余的中间结果,与文献[7]方法中的属性路径过滤类似,但本文在过滤时使用最长属性路径进行匹配过滤,而不是某一个路径长度范围内的所有属性路径进行过滤,避免了过多的重复计算。

图2 本文方法流程
本文的查询执行计划是一个图而不是一棵树,便于重用块内联结的结果。以Q9的一个查询图(见图3(a))为例,在第一阶段,将SPARQL查询图按含有相同的联结变量进行分块,图3(b)即为Q9查询图的一个分块,然后根据三元组模式都含有相同的联结变量“?X”划分为一块。
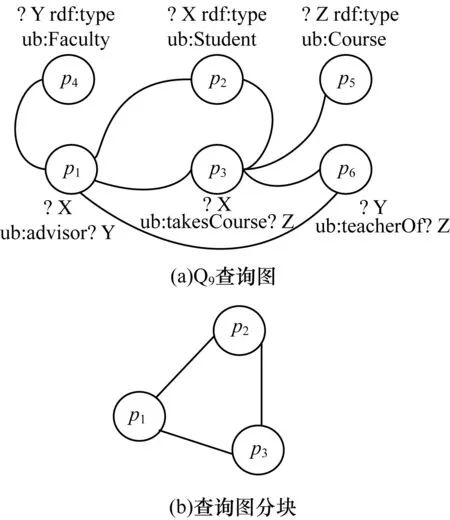
图3 Q9查询图及其分块
2.1 选择度计算
选择度根据匹配联结pn的三元组个数计算获得,匹配的三元组数量越多,选择度最小,计算公式如下:
SELECTIVITY=min(sel(p1),sel(p2),…,sel(pn))
如果#(p1)<#(p2)<#(p3),则sel(p1)>sel(p2)>sel(p3)。为节省空间和时间,选择度的计算针对至多含有一个查询变量的三元组模式。最频繁的一种三元组模式是(?S,P,O),即给定三元组的主语P、谓词O,返回对应三元组中主语S的值。
本文建立一个OPS(宾语,谓词,主语)索引[5]计算选择度。指定宾语和谓词可以获取对应的主语id列表和匹配的三元组个数,以此来实现块内最优执行计划,索引结构如表2所示,其目的是先执行联结次数较少的联结,减少不必要的联结。
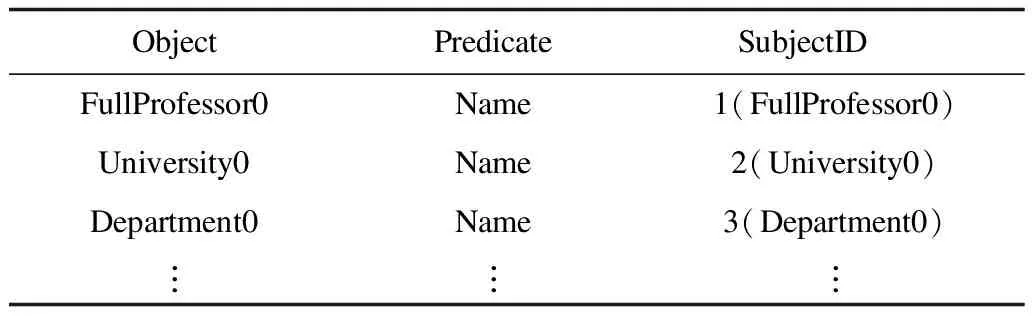
表2 OPS索引结构
2.2 属性路径索引
本节介绍属性路径索引,对第二阶段剩余联结进行过滤。属性路径索引是从RDF数据图中提取的,本文的RDF数据图的定义采用文献[16]中的定义:
定义1一个RDF数据图是一个三元组(V,L,E)。其中:V是一个有限的节点集,VE表示实体节点,VC表示类节点,VV表示数据节点,构成不相交的并集VEVCVV;L是一个有限的边标签集合,L=LRLA{type,subclass},LR代表实体之间的边,LA代表实体和数据值之间的边;E是一个有限的边集,边的形式为:e(v1,v2),v1,v2∈VE,e∈L,只有v1,v2∈VE,e∈LR;e∈LA,当且仅当v1∈VE且v2∈VV;e=type当且仅当v1∈VE且v2∈VC;及e=subclass当且仅当v1,v2∈VC。
本文定义一个RDF实体关系图以用于建立属性路径索引:
定义2一个RDF实体关系图G’是一个三元组(V’,L’,E’),其中,顶点V’=VE,边标签L’=LR,且E’⊂E,E’联结2个实体节点。VE表示实体顶点的集合(例如IRIs),只有RDF数据中存在边e(v1,v2)∈E’并且v1,v2∈VE,RDF实体关系图中存在边e(v1,v2)∈VE。
本文的属性路径索引是建立在RDF实体关系图上,不包括数值类型的三元组,如图4所示。包含数值的三元组在第一阶段进行处理。
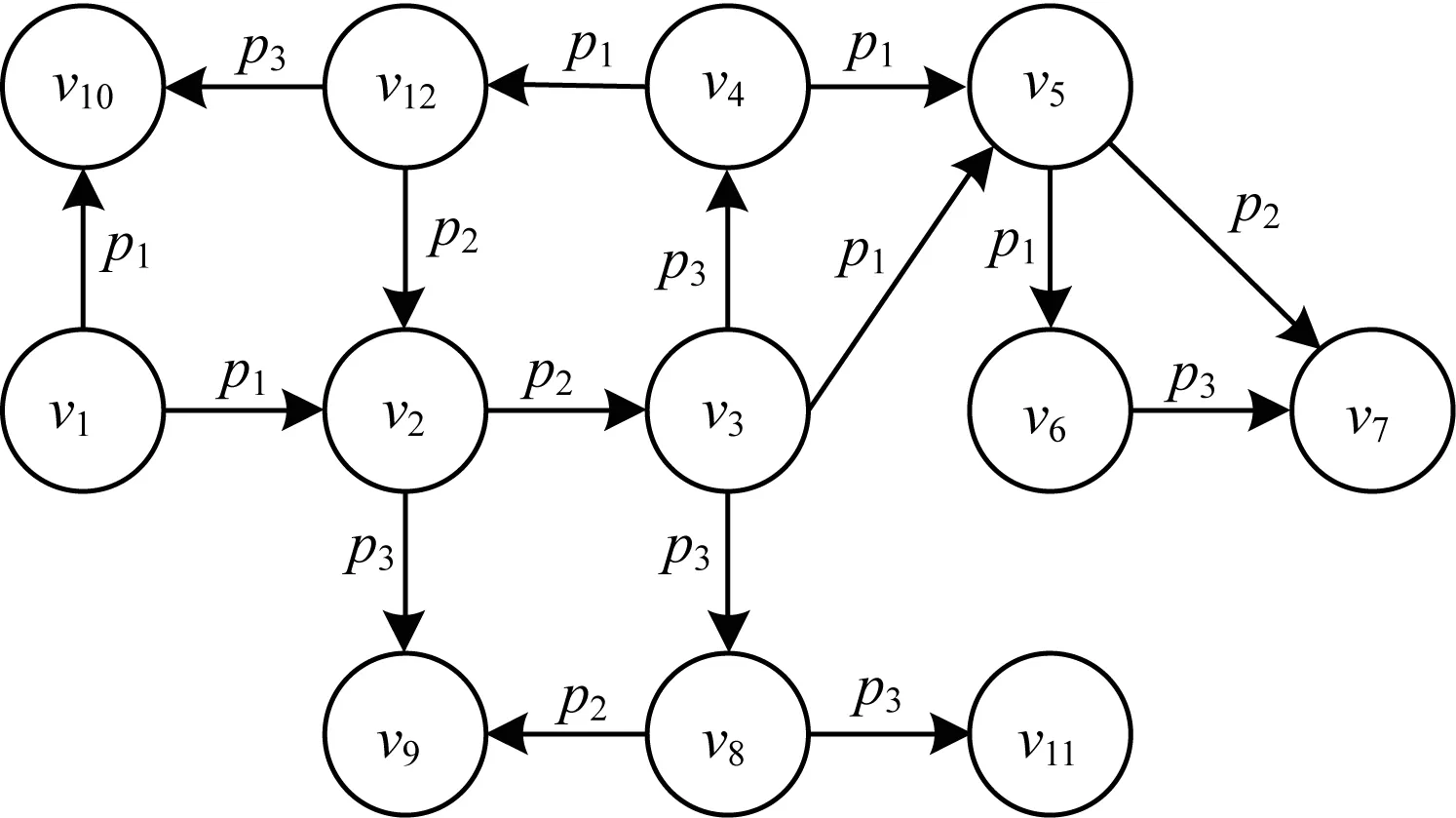
图4 RDF实体关系示意图
定义3入边属性路径是一个三元组谓词的序列,如果一条路径的终端节点是n,则称这是一条节点n的入边属性路径。
例如,Q9中的“?X ub:advisor ?Y.?Y ub:teacherOf ?Z”联结,存在一条“?Z”的入边属性路径“ub:advisor→ub:teacherOf”。表3显示了图4中的属性路径索引指向的顶点列表。例如,如果某一个SPARQL查询中存在联结“?n1p1?n2.?n2.p2?n3.?n3?p3?n4”,可以通过找到属性路径“
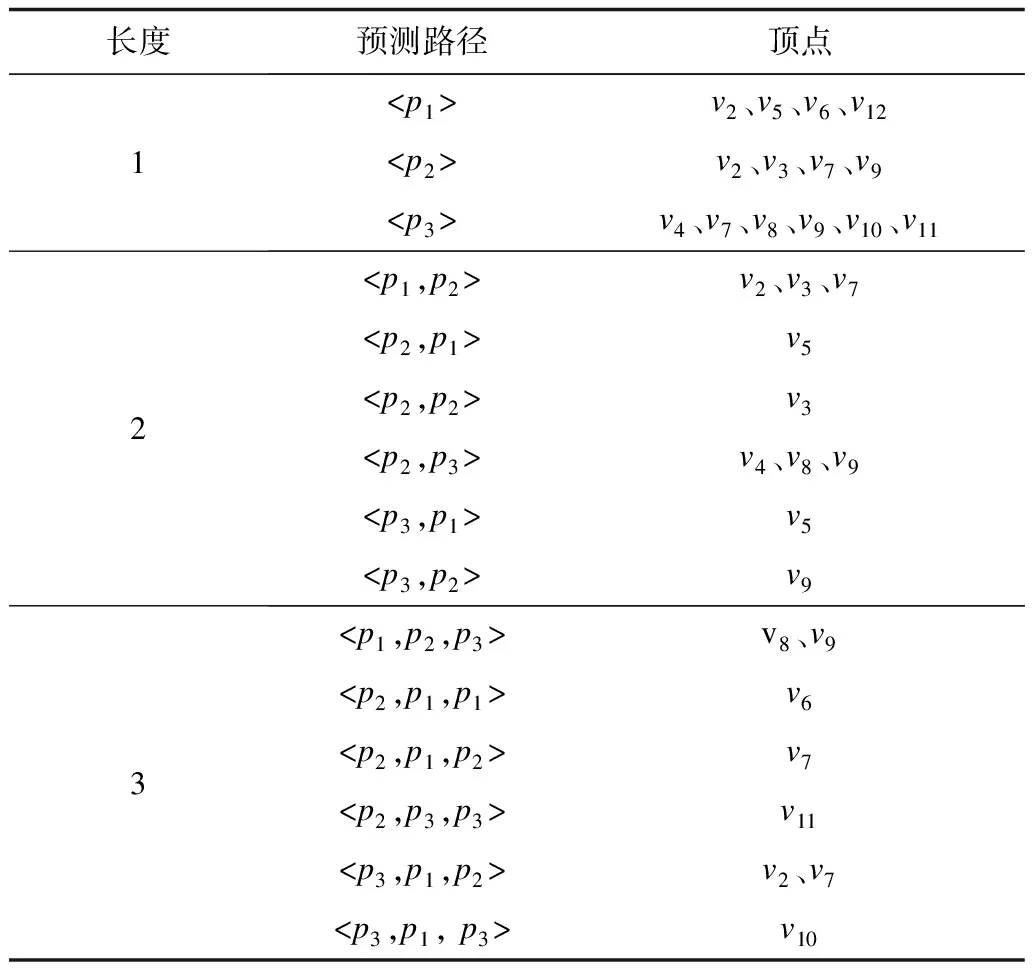
表3 属性路径索引指向的顶点
本文使用前缀树结构存储属性路径索引,前缀树中的每一节点有一个指向对应谓词路径的节点列表的指针。该属性路径索引结构与信息检索中的倒排索引有些类似。每个入边属性路径可以看作是倒排索引的一个单词,节点列表相当于倒排索引中排序的文档ID号。属性路径索引中有大量重复的部分,如图5所示,

图5 属性路径索引的前缀树
图6所示为当SPARQL查询中含有谓词为变量的联结的情况。把谓词变量当作一个特殊的谓词处理,用pv代替。例如,在图6中,顶点“?v4”的所有入边属性路径为
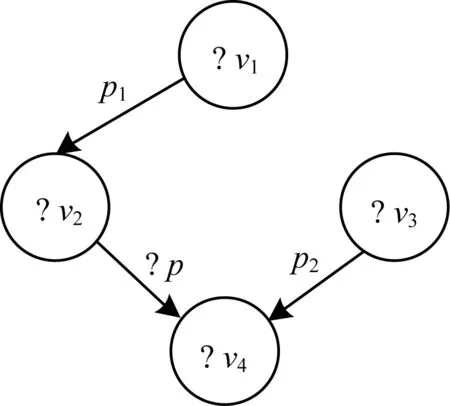
图6 含有谓词变量的SPARQL查询
本文的两阶段查询处理算法描述如下:
算法两阶段SPARQL查询优化算法
输入SPARQL查询queryStr,属性路径前缀树Trie
输出合并联结后的结果集Results
1.Parse queryStr;
2.Block queryStr into n blocks;/*对所有的联结进行分块,把含有公共变量的联结划分为一块*/
3.For i←0 to n-1
4.Filter out joins with (?S,P,O) by get Variable Selectivity(queryStr.variable[i]) in order;/*对每个分块中(?S,P,O)的联结利用选择度进行过滤*/
5.end For
6.For each variable v∈Variables
7.filterList←getVertexList(Trie,v);
8.Combine Results using filterList;/*Variables存放queryStr中的所有变量,通过前缀树Trie,用每个变量的最长入边属性路径过滤冗余的节点,并对过滤后的结果集Results进行合并*/
9.end For
10.Output Results;
该算法主要分为3个部分:
1)对输入的SPARQL查询进行分析并分块(算法第1步和第2步)。
2)对于块内的每个形如(?S,P,O)的三元组模式,利用选择度函数getVariableSelectivity进行过滤(算法第3步~第5步),在该阶段内利用选择度函数将对形式为(?S,P,O)的联结进行重新排序,首先执行当前查询模式中联接代价最小的查询模式,尽可能地降低在查询过程中产生的中间结果的数量。
3)对剩余的三元组利用属性路径索引Trie进行过滤(算法第6步~第9步),这是第2轮的中间结果过滤,因为属性路径至少包含一个三元组模式,所以利用属性路径过滤能够比单个三元组模式过滤掉更多的中间结果,最后输出显示合并后的结果(算法第10步)。
本文算法的时间复杂度主要由第6步~第9步决定,为O(n×e),其中,n为输入的SPARQL查询中变量的数量,e为SPARQL查询中每个变量的平均入边数量。算法的时间受SPARQL查询中变量的数量以及变量的入边数量影响。
3 实验与结果分析
本文实验使用公开数据集LUBM、YAGO2、SPARQL基准数据集(SP2B)[17]及DBpedia SPARQL 基准数据集(DBSPB)[18],并用开源的RDF-3X[4]系统(0.3.5版本)、TripleBit[12]做比较。通过LUBM的generator,产生了10 000个大学的LUBM数据集。表4是这4个数据集的统计信息。其中,
YAGO2包含94个谓词,LUBM和SP2B分别包含17个和77个谓词,DBSPB包含39 675个谓词。DBSPB是多个领域数据集的合并,YAGO2是一个异构数据集Wordnet和Wikipedia的合并,而LUBM和SP2B则是关于同类领域关系的描述。
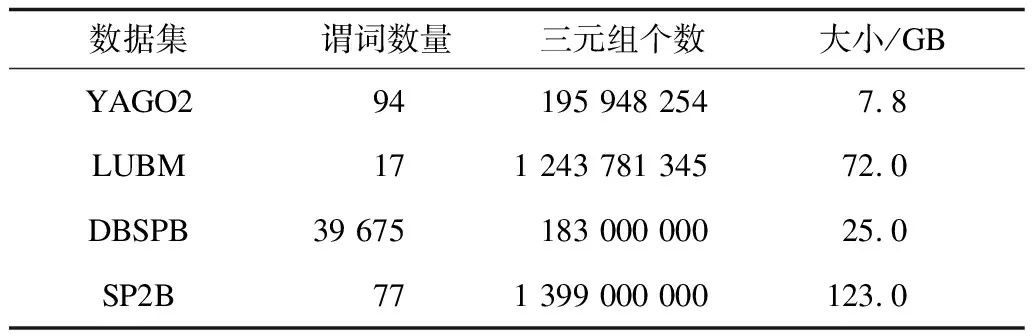
表4 数据集信息
表5显示了最大长度为3的属性路径索引信息,包括属性路径索引指向的节点数量以及整个索引的大小。因为LUBM数据集具有相对单一结构化的模式特点,所以其包含较少的节点。
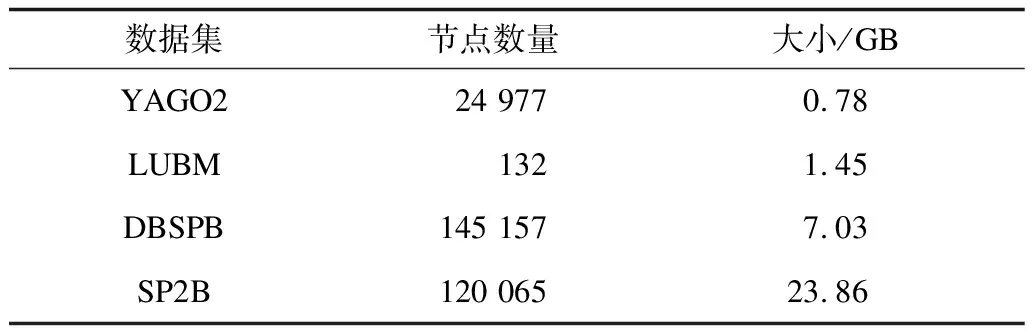
表5 属性路径索引信息
本文使用LUBM数据集基准中Q1~Q9进行比较实验。表6显示了2种方法对Q1~Q9产生的中间结果数量。通过比较可知:无论是简单结构查询还是复杂结构查询如Q2和Q9,本文方法都比RDF-3X产生更少的中间结果;在查询Q1与Q5上,本文方法与TripleBit方法产生的中间结果数量比较接近,因为没有找到可过滤的属性路径索引。

表6 LUBM数据集中间结果数量
从YAGO2中,挑选属性路径长度为3~7的查询各10个,计算平均查询执行时间和中间结果数量。图7显示了平均执行时间和中间结果的数量随着属性路径长度的变化情况。从中可以看出:除了属性路径长度为3时外,本文方法的执行时间和中间结果数量整体上都要低于RDF-3X,而且本文方法的执行时间和中间结果数量随着属性路径长度变化增加缓慢;3种方法的执行时间曲线都随着属性路径长度的增加而上升;本文方法虽然不是整体上都超过了TripleBit方法,但在路径长度为3、4时本文方法与TripleBit方法的曲线非常接近,但本文的执行时间曲线比方法RDF-3X和TripleBit都平滑。TripleBit每次选择最小的选择性变量所对应的查询模式执行,以此来降低在查询过程中的中间结果集的大小,TripleBit性能降低的主要原因是查询中包含更多联结或者访问更多选择度索引块。所以,对于属性路径长度较小的查询,本文方法与TripleBit方法过滤效果相差不大,但对于属性路径较长的查询,本文方法优于TripleBit方法。
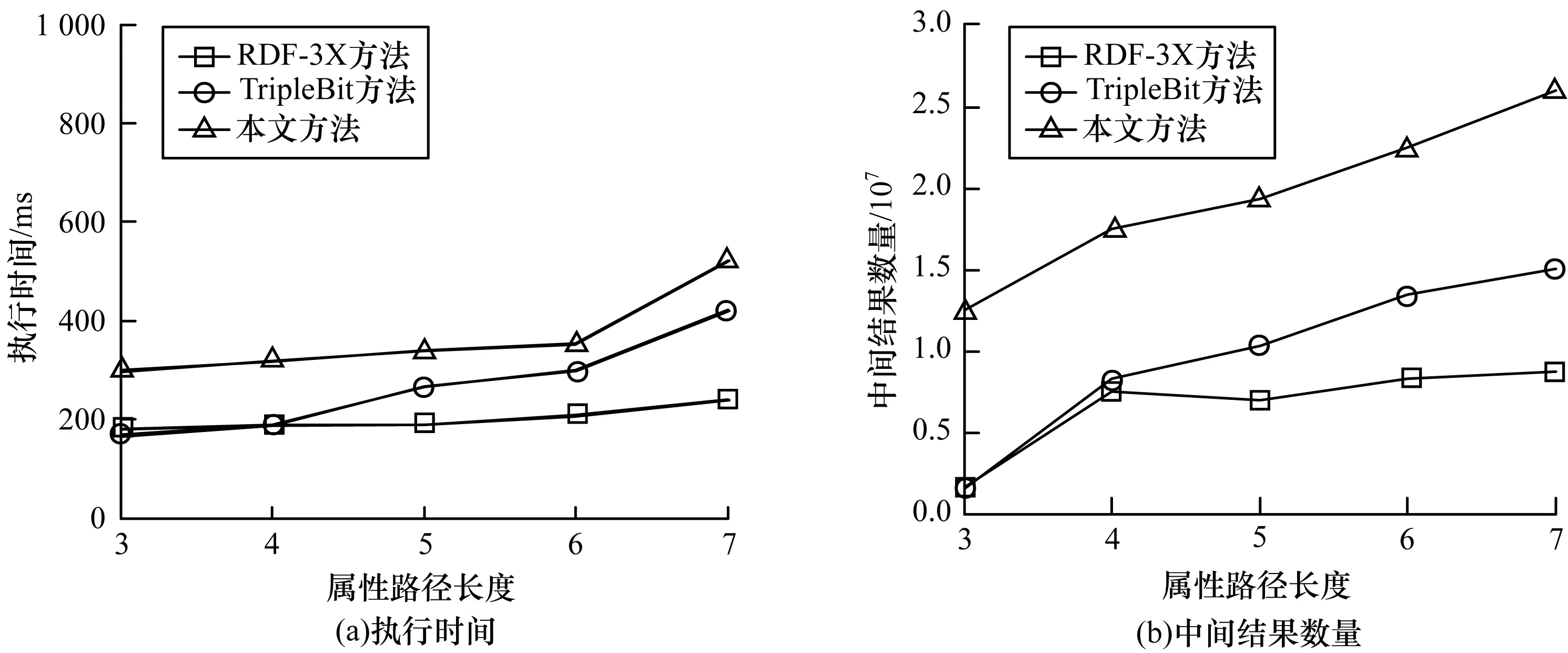
图7 YAGO2数据集上的查询性能比较
为验证本文方法能够适用于各种不同的RDF数据集,对数据集DBSPB和SP2B分别构建查询Q10~Q13和Q14~Q17,查询结果如图8所示。这些查询都有4次~5次的联接次数并且有较长的属性路径。查询的执行时间分别显示在图9(a)和图9(b)中。从中可以看出,除了查询Q10与Q17外,本文方法在这两个数据集上实现的查询执行时间都优于RDF-3X与TripleBit方法。查询Q11、Q12、Q13、Q15、Q14及Q16在执行时间上明显少于RDF-3X与TripleBit方法,主要原因是本文通过最长属性路径索引过滤掉大量无用的中间结果,TripleBit方法对于联结比较多的查询需要动态计算最优选择性的三元组模式并且需要访问更多的索引块。对于查询Q10与Q17,虽然没有TripleBit方法执行效率高,但是相差不大,没有超过的原因是在前缀树索引结构中没有找到可过滤的属性路径。
图8 本文方法在DBSPB和SP2B数据集上的SPARQL查询结果
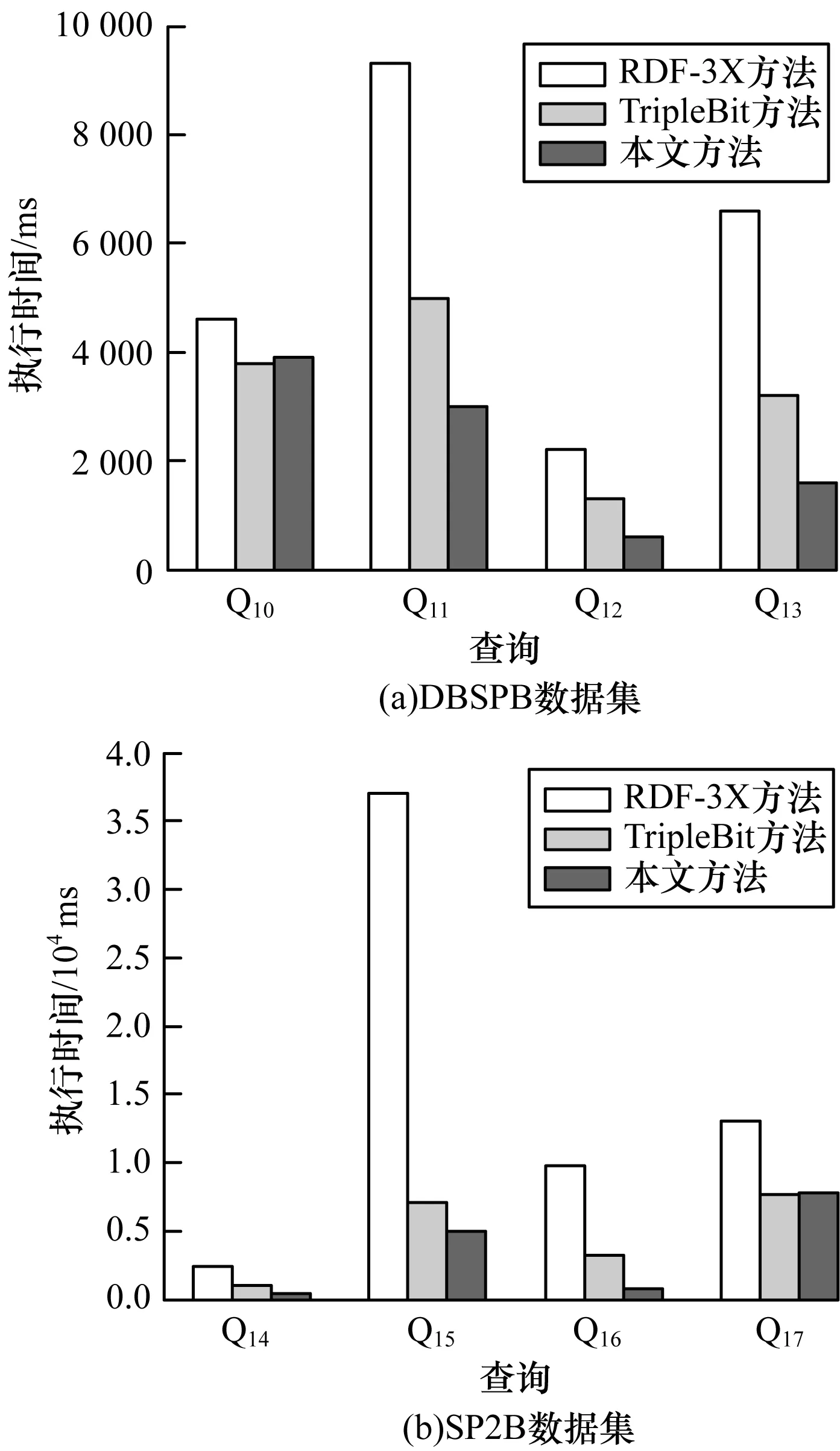
图9 查询执行时间比较
4 结束语
本文提出一种两阶段的SPARQL查询处理方法,一方面通过计算选择度找出联结数最小的联结,另一方面利用属性路径索引过滤冗余中间结果。虽然属性路径索引的存储耗费了一定的存储空间,但大幅提高了SPARQL查询的执行效率。在不同的数据集上的实验结果验证了本文方法对中间结果过滤的可行性、有效性。未来将进一步提高联结选择度计算的准确度,并将本文方法运用到MapReduce等并行及分布式环境中。
