ASM姿态矫正结合字典学习优化的人脸识别
2018-11-17钟小莉
钟小莉
(青海民族大学 计算机学院,青海 西宁 810007)
0 引 言
从二维图像中进行人脸姿态识别是图像处理领域中的一个热点课题,在人脸识别、人机交互中有很多应用[1]。然而,由于人脸图像中存在多种环境因素的影响,如面部表情、光照和图像分辨率等,对人脸姿态识别造成了很大的困难[2,3]。
目前,用于人脸姿态识别的主要技术有主动外观模型(active appearance model,AAM)[4],其基于学习形状和外观变化来预测面部姿态。但是,AAM的有效使用需要面部特征精确定位,在图像分辨率很低时难以实现。也有学者提出了一些基于回归的方法来进行姿态识别,例如利用支持向量回归(support vector regression,SVR)[5]来估计姿态,或者利用流形嵌入技术和回归方法的混合来进行姿态预测[6,7]。但是,这些方法容易遭受数据集中不规则分布的数据和噪声的影响。文献[8]提出了Gabor结合各向异性扩散(Gabor anisotropic diffusion,Gabor-AD)的方法。文献[9]提出了一种熵加权Gabor结合主动形状统计模型(active shape and statistical model,ASSM)的方法(Gabor-ASSM),在姿态变化较大的人脸数据库上可取得较高的识别率。然而,这些方法的计算复杂度比较高。
针对上述分析,提出一种主动轮廓模型(active shape model,ASM)融合字典学习优化的人脸识别方法。提出的方法主要创新点如下:
(1)利用ASM对人脸姿态进行矫正,可以明显提高对姿态变化人脸图像的鲁棒性;
(2)利用字典学习优化,可以更好地保留有用特征;
(3)在判断所识别图像是否为正确类别后,及时地对训练样本特征空间进行了更新操作,一定程度上提升了训练系统的识别能力。
实验结果表明,提出的方法能够准确地识别出人脸姿态,具有很好的鲁棒性。
1 提出的人脸识别方法框架
基于ASM、Gabor小波变换[10]、核主成分分析(kernel principal component analysis,KPCA)[11]和稀疏表示(sparse representation,SR)[12],提出了一种姿态识别方法。其基本思想是利用ASM提取人脸图像局部特征,对人脸进行矫正对齐。通过Gabor小波和KPCA构建一个人脸姿态特征字典,并进行字典学习优化[13],以此构建稀疏分类器。然而,由于训练图像的数量很大,并且存在可能影响最终分类结果的大量冗余姿态和噪声。为此,设计了一种更新方法,即用错误分类的面部图像来对训练集外观基础特征空间进行更新。提出的方法过程如图1所示。
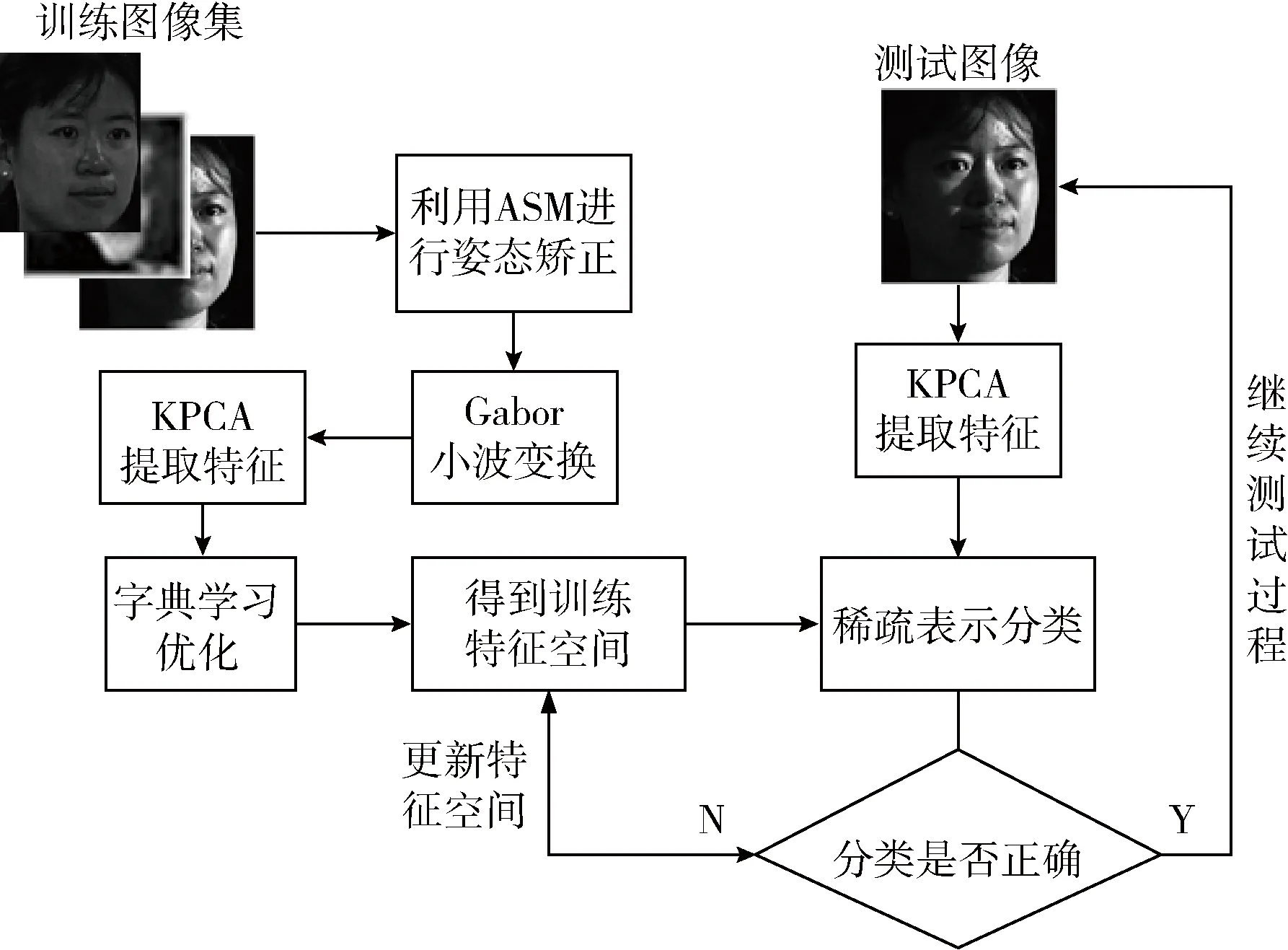
图1 提出的方法框架
2 脸姿态矫正
首先,利用ASM进行人脸姿态矫正,利用点集坐标向量将人脸目标形状定义为
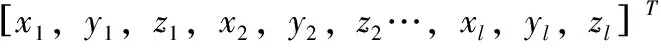
(1)
S可表示为平均形状S0,根据基向量的线性组合改写为
S=T(s,R,T;S0+Ψip)
(2)

(3)
为了使可变形模型与测试图像吻合,利用ASM对人脸图像进行拟合。优化T(s,R,T;·)的参数和基础Ψ的参数向量p,减小S每点处在斑块中计算的特征,并利用训练图像构建模型特征之间的差异,从原始灰度图像的斑块、图像梯度和局部二值模式中提取人脸特征。提出的方法对相关系数进行归一化处理,并利用ASM得到面部特征的拟合人脸形状,如图2所示[9]。
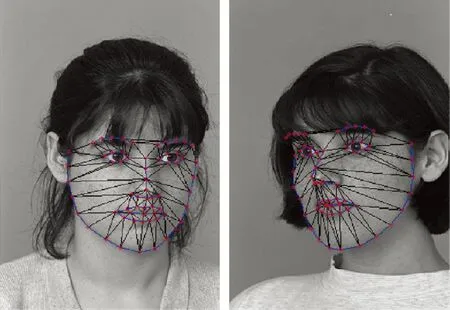
图2 利用ASM得到的拟合人脸形状
3 提出的人脸姿态识别方法
3.1 Gabor小波变换
Gabor小波是一种加Gauss窗口的Fourier变换,由多尺度和多方向的滤波器组成[10]。Gabor小波变换是分析图像的一种有效方法,可用来表达图像的在各个方向和尺度上的变化,且对光照变化具有很好的鲁棒性[14]。为此,以直方图序列形式将人脸图像转换为特征向量,应用Gabor滤波器在频域上获得初始特征。Gabor滤波器定义如下
(4)
3.2 利用KPCA进行特征提取
在上述Gabor小波变换后,对获得的小波系数进行降维以获得最终的特征。使用KPCA来对小波系数进行处理,建立基础Ψ,提取高阶统计特征。KPCA是传统PCA在高维特征空间的应用,使其能够捕获高维空间的非线性信息,以此提高性能。KPCA的特征值可通过式(5)计算[11]
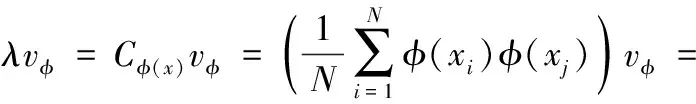
(5)
vφ的所有λ≠0的解都位于φ(x1),…,φ(xn)范围内,存在系数αi如
(6)
定义N×N核矩阵K,有
Ki,j=φ(xi)·φ(xj)
(7)
将式(6)乘以φ(xj),代入式(7),得到
NλKα=K2α
(8)
该特征值求解问题可表示为更简单的特征值问题
Nλα=Kα
(9)
特征空间的投影由下式执行

(10)
可见,只需利用核函数就可以从原始图像中提取出k个非线性主成分,无需较大的计算量。
3.3 非约束字典学习优化
得到最优矩阵K∈RN×N后,利用优化程序对每个原子项进行优化,令dj∈Rm为K的第j原子项,假设xj*∈R1×N的行向量为K的第j行,固定K和所有原子项,构建下面的优化问题[13]
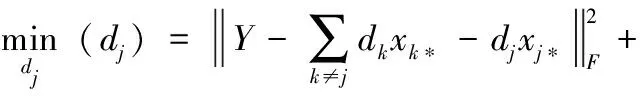
(11)
设置E=Y-∑k≠jdkxk*,消除不相关项,上式可简化为
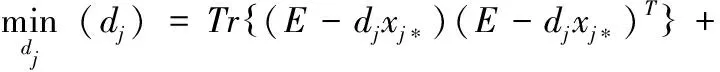
(12)
由于H(dj)为凸,H(dj)关于dj的梯度设为零,得到最优解
(13)

3.4 基于稀疏表示的分类
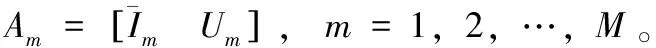
A=[A1,A2,…,AM]
(14)
使用字典A,任何新的测试图像y∈Rd×1可以由与其类m相关联的训练特征空间的线性度来近似表示
y=Amam
(15)
实际上,测试图像y可能被部分破坏或遮挡。在这种情况下,式(15)中的模型可被重写为
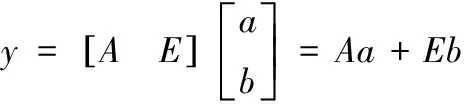
(16)

(17)

(18)

(19)
3.5 算法过程
提出的姿态识别算法如算法1所示。
为了给KPCA提供合适的训练集,对于每个类m,将训练样本划分为两个子集。第一个子集包含少量的人脸图像nm,并且其通过Gabor小波变换和传统PCA构建初始特征空间。第二个则被用于KPCA学习。所有姿态类的本征空间用于稀疏表示分类,作为过完备字典。然后,在稀疏表示分类器出现分类错误的情况下,通过应用KPCA,将新的训练样本添加到基础特征空间中。因此,SR的字典会随着每次错误分类而更新。结合不正确分类的姿态能够改善稀疏表示分类器的适应能力,提高分类精度,特别是当图像分辨率非常低或光照条件动态变化时。
算法1:提出的人脸姿态识别算法
(1)输入:来自M类的训练图像矩阵I={I1,I2,…,IM},其中Im∈Rd×nm表示类m的图像集,d为每个图像的维度(以向量形式表示),nm为类m中图像的数量。


(4)使用式(19),将重建残差最小的类m来标记新训练图像。
(5)判断新图像是否用正确的类别标记?
是,则返回步骤(3);
否,继续执行步骤(6)。
(6)通过KPCA更新训练图像所属类的本征空间。
(7)返回步骤(3)。
4 实验及分析
在UMIST低分辨率姿态数据库上进行实验,以评估提出的方法对低分辨率图像的鲁棒性。然后,在CMU-PIE数据库和户外人脸(LFW)数据库上进行实验,评估其对姿态和光照变化的鲁棒性,并将其与现有方法进行比较,提出的方法利用MATLAB和C语言混合编程。
4.1 在低分辨率人脸图像上的性能
为了测试所提出的方法对于低分辨率图像的性能,在UMIST人脸数据库上进行实验。UMIST人脸库由英国曼彻斯特大学创建,包括20人的564张人脸图像。
利用人脸图像的平面角度偏差,将脸部图像分类为5个姿态类别(即正面人脸、全左脸、全右脸、1/4左脸、和1/4右脸)。正常面部图像为36×36像素,为了进行低分辨率实验,将原始图像从36×36的像素向下采样到30×30、24×24、18×18和9×9像素。UMIST数据库中各种姿态的一些低分辨率图像如图3所示。

图3 来自UMIST数据库中的低分辨率姿态图像
表1给出了人脸识别结果的混淆矩阵。其中,L、QL、F、QR、R分别表示全左脸、1/4左脸、正面人脸、全右脸、和1/4右脸。可以看出,提出的方法对各种人脸姿态的正确识别率都较高,分别达到了91.36%、91.55%、94.38%、90.53%和91.36%。整体准确率达到了91.84%。其中,L和QL,R和QR由于比较接近,所以误分类相对较多。

表1 UMIST上不同分辨率人脸姿态分类的混淆矩阵/%
为了研究对不同分辨率脸部图像的分类效果,在不同分辨率图像集合下进行姿态分类实验,获得的平均分类率见表2。可以看出,提出的方法对于18×18和24×24分辨率的姿态图像分别获得了87.53%和88.24%的分类率,对于正常36×36分辨率获得了90.21%的分类率。这个结果表明,在分辨率下降时,所提出的方法的分类率并没有明显降低,这验证了其在低分辨率图像上是有效的。

表2 不同图像分辨率的分类率/%
4.2 光照变化的人脸姿态识别的性能
为了评估提出的方法对光照和姿态变化的鲁棒性,在CMU-PIE数据库上进行实验。CMU-PIE数据集包含70个不同的人在13种不同姿态、43种不同的光照以及4种不同的表情下的68张面部图像。其使用了13个相机,每个相机定位在不同位置以提供特殊的相对姿态角,从而获得不同姿态的人脸。从CMU-PIE数据库中选择出70个人的8260张图像组成实验数据集,如图4所示。

图4 CMU-PIE图像
对于训练,使用来自30个人(每人180个样本)的不同姿态的图像。将人脸区域下采样到24×24的像素点。KPCA的初始特征空间由来自2个人的360张图像(每个人包括9个姿态和20个光照)构建,然后通过应用KPCA将训练集中的其它28个人的图像添加到基础本征空间中。对于9种不同姿态的分类混淆矩阵见表3。
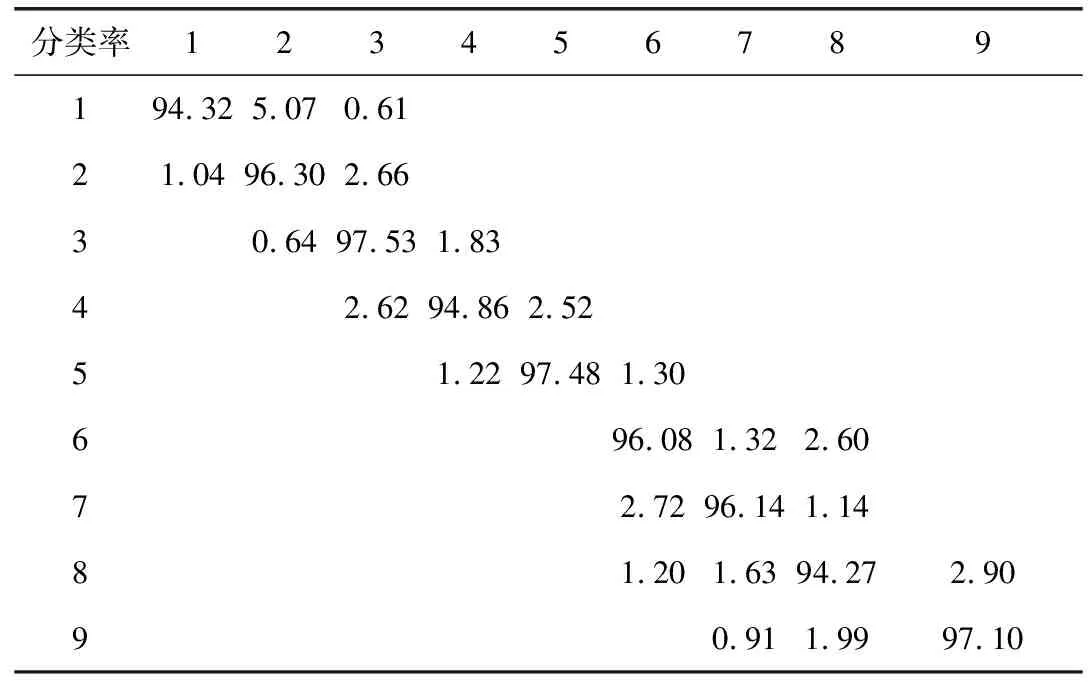
表3 在CMU PIE中对9种姿态人脸的分类混淆矩阵/%
从表3可以看出,提出的方法对不同光照下各种姿态图像的分类率都较高,表明提出的方法利用ASM姿态矫正有助于提升姿态变化的鲁棒性。
接着,将提出的方法与其它姿态识别方法进行比较,包括文献[7]提出的基于姿态相似性特征空间和AdaBoost的方法(PSFS-AdaBoost),文献[8]提出的Gabor结合各向异性扩散的方法(Gabor-AD),文献[9]提出的熵加权Gabor结合ASSM的方法(Gabor-ASSM),在CMU-PIE数据库上执行对比实验,为了公平比较,借鉴文献[7]的实验设置,训练集中包括15个人、4个对应于光源01、04、13和14的光照变化,且表情变化有平常、微笑和眨眼。来自53人的其它图像用于测试。表4给出了几种方法的识别率。
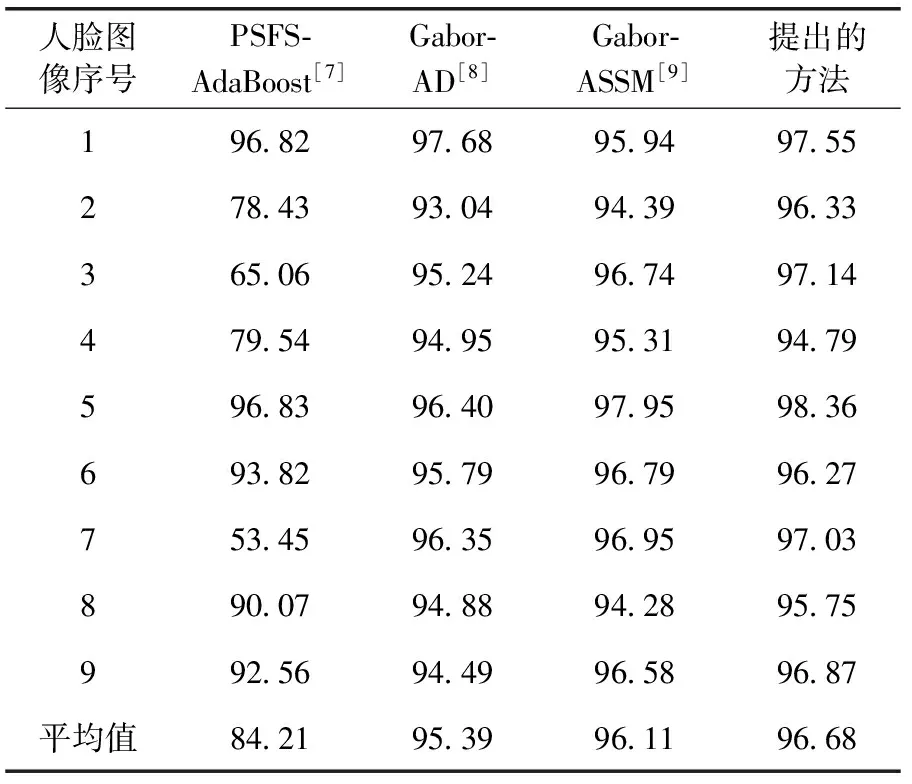
表4 CMU PIE数据库上9个不同姿态人脸的识别率
从表4可以看出,在大部分图像上,提出的方法具有较高的识别率,极少数图片上低于其它几种方法。比较平均识别率可以看出,提出的方法平均识别率最高。
4.3 LFW数据库上的识别性能
LFW人脸数据库[9]是无约束人脸识别最常用的数据库之一,该数据库中含有13 223张来自5729位对象的不同表情、不同姿态以及不同程度遮挡的人脸图像。人脸识别性能以平均精度的形式给出,严格地只使用LFW样本,不使用外部数据。图5为LFW人脸库上的图像示例。

图5 LFW人脸库图像
从LFW人脸数据库中选取300个对象、每个对象10张人脸图像进行实验。实验对偏航角大于10°且正镜面脸偏航大于40°的样本进行不可见区域填充。随机选取5张用于训练,剩余的5张用于测试,将几种方法分别进行20次实验,记录每次实验所得识别率,并计算标准差,几种方法的识别结果见表5。
表5表明,相比PSFS-AdaBoost方法、Gabor-AD方法和Gabor-ASSM,提出的方法识别率最高。提出的方法利用ASM进行姿态矫正,可以明显提高对姿态变化人脸图像的鲁棒性。利用字典学习优化,可以更好地保留有用特征。此外,提出的方法在判断所识别图像是否为正确类别后,及时地对训练样本特征空间进行了更新操作,一定程度上提升了训练系统的识别能力。

表5 几种方法在LFW上的识别结果
提出的方法在标准差方面与Gabor-AD相当,明显低于Gabor-ASSM方法,略高于PSFS-AdaBoost方法。AdaBoost算法是一个非常稳定的分类算法,PSFS-AdaBoost方法将AdaBoost算法用于分类,故相对于其它分类算法具有更加稳定的性能。而Gabor-ASSM方法在分类过程中一定程度上依赖先验分布和随机过程,故在稳定性方面逊色于其它几种方法。
4.4 性能比较
仅在识别率方面优于其它几种方法,不足以表明提出的方法的优越性,故记录了几种方法在LFW上的训练总完成时间、测试1张图像所需时间。在配有Intel酷睿i5双核处理器、2.49 GHz主频、4 GB RAM的PC机上进行实验,采用MATLAB 7.0和C混合编程,结果见表6。

表6 几种方法在LFW上的运行时间
从表6可以看出,提出的方法所需训练总完成时间高于其它几种方法,与Gabor-ASSM方法相当,明显高于其它两种方法。提出的方法所需步骤比较多,在ASM姿态矫正方面需要花费一定时间,测试完更新训练系统的特征空间也需要花费一定时间。比较测试时间可以发现,提出的方法识别一个样本仅需1.05 s,明显低于其它几种方法,且完全符合现实应用中的实时性需求。
通常人脸识别系统的训练过程都是离线完成,故训练时间多不会影响识别系统的性能。提出的方法训练时间高于其它几种方法,测试一个样本所需时间均低于其它方法,表明提出的方法在识别方面更具优势。
5 结束语
针对低分辨率、光照强度和人脸表情变化下的人脸姿态识别,提出了一种融合ASM姿态矫正和非约束字典学习优化的人脸识别方法。在UMIST、CMU-PIE及LFW人脸数据库上进行了实验,分析了低分辨率、不同光照、表情和姿态下人脸图像对识别方法性能的影响。结果表明了提出的方法能够有效应对这些环境变化,平均识别率都能达到90%以上,具有可行性和有效性。此外,提出的方法识别一个样本仅需1.05 s,完全符合现实应用中的实时性需求。
未来会将提出的方法进行改进,应用于其它类型的图像识别数据库,例如人体动作识别、手势识别等,并结合最前沿的深度学习、机器学习技术,进一步优化训练系统和测试系统,降低所耗时间,在提高识别率的同时,更好地满足实时性需求。
