Web环境下语义挖掘模型的构建
2018-11-14刘爱琴赵慧敏山西大学经济与管理学院
刘爱琴,赵慧敏,尚 珊(山西大学经济与管理学院)
1 问题的提出
Web是一种将超文本、多媒体信息、HTTP集中在一起的能动态交互的分布式环球资源信息网络。Web信息以计算机可辨别的形式存储在互联网中某个节点上,而且能够根据服务器发出的请求实现节点之间信息的传递。传统的Web挖掘模型降低了Web挖掘获取知识模式的工作效率,所获取的数据信息是非结构化甚至是无结构的,很难保证信息的质量,急需对传统的Web挖掘模型进行优化,构建一种新的Web挖掘模型,准确又高效地对海量、繁琐、异构且广泛的Web信息资源进行组织。领域本体和语义Web相关技术与理论体系的出现为该探究提供了充分的技术支持和理论依托,促进了这一愿望的实现。[1]
2 相关研究
2.1 语义Web的研究
语义Web是一种从语义层面理解词语、概念以及它们之间逻辑关系的智能网络,使人机交互成为可能。WWW之父TimBerners-Lee在20世纪90年代末期对语义Web的诠释认为,它实际上相当于一种基于各种技术与知识表现的综合。20世纪60年代末期,Collins、Quillian、Loftus等人开创了语义Web研究的先河。Simon、Schamk、Minsky等学者也不断地提出一些理论上的研究成果。在我国,2002年语义Web技术被纳入“国家高技术研究发展计划”重点技术之列,得到了政府的大力支持和援助。随着XML、RDF、Ontology等语义网关键技术的成熟,其在人工智能领域的应用也更加普遍。具有代表性的人机互动工具真正意义上实现了由计算机通过“智能代理”将人类从各种繁琐的工作中解放出来。
2.2 面向Web的语义挖掘研究
澳大利亚Griffith大学开展的WebKB项目,借助WordNet设计了以本体论为主导的Web语义检索系统,清除句子歧义、进行词汇拓展,提升用户信息检索的准确度。[2]德国 Karlsruhe大学设计的 Onto-broker系统主要是使用语义恰当的标签,使整个Web页面有良好的结构,Web页面有含义,方便人机理解,从而实现用户检索信息的自动推断。基于语义Web技术和相关理论,Plumbaum提出了一种运用JavaScript引擎跟踪用户与Web站点会话的新思路,用来挖掘高质量的用户信息。[3]LiYuefeng开发了一种综合运用语义Web本体映射技术和基于关联规则的数据挖掘算法,改善Web挖掘中的语义歧义,提高挖掘效率的机制。[4]纪明奎与黄丽霞构建了一个把语义Web作为核心的个性化信息检索模型,能够为用户提供符合自身个性化信息需求的全方位资讯服务。[5]赵良和张云婧探究了以语义层次为基础的Web个性化资源推荐的方法,具体分析了确定Web页面重要度的途径,并详细阐述了Web个性化资源推荐的过程。[6]蔡皎洁等学者提出对Web文本实行分词与词性标注的基本思路和处理过程,并深入探究综合运用各种数据挖掘技术提供的算法和语义分析技术实现Web文本特征抽取的方法。[7]
面向Web的语义挖掘模型是将传统的知识发现流程进一步优化的成果。经过将Web页面元素语义化处理使Web页面有良好的内容布局,页面元素有含义,便于计算机更容易理解,极大地改善了最终获取到的知识模式的质量。本文借鉴以往相关研究的结果,着重强调了本体映射技术对于发现Web中特定学科领域概念间相似程度的关键性,以及知识模式的语义修正和扩充对于提高知识模式质量的重要性。通过将本体技术与各种数据挖掘工具提供的算法相结合构建Web语义挖掘模型,解决Web环境下数据异构问题,实现知识的互享和重用以及质量的提升。
3 语义挖据模型
3.1 理论支撑
3.1.1 数据挖掘技术
数据挖掘是从数据集中识别并提炼隐藏在其中的、有效的及最终可理解的模式进而形成高质量语义知识模型的关键过程。它不是自动完成的,需要依赖各种算法。数据挖掘需要有信息抽取、信息资源整合、数据预处理、数据形式转换、挖掘过程实施、知识模式形成、模式评价等过程。在Web挖掘实施阶段使用决策树方法,将Web资源有目的地分成Web文本数据、Web链接数据、Web使用数据,从中抽取一些有意义的、隐含的信息组合成网络文件,为数据预处理环节提供数据源。神经网络算法将信息转化具有适应性的处理元素(神经元)进行逻辑推理,是一种模拟人脑思维进行动态信息处理的抽象算法,在解决数据挖据问题上非常适用,主要用于数据的分类、预测以及知识模式的识别等过程。遗传算法作为一种通过模仿自然界中物种进化的基本规律来实现任意搜寻最优解的数学方法,它与BP神经网络算法正逐渐相互渗透和契合,通过建立两者之间的联系能够从数据库中抽取潜在有效的知识模式。关联规则算法首先从原始数据集中寻找全部高频项目组,之后根据已设定的支持度和置信度的最低临界值,选择合适的数理统计与多元分析工具给出的算法,探索各个高频项目组之间的关联规则。总之,在当今信息爆炸的时代,各种数据挖掘技术对于从海量的信息中发掘有效的信息资源仓库有很明显的促进作用。
3.1.2 领域本体构建
领域本体是语义挖掘过程中所获取的知识模式准确度的一个参照,对实现数字内容有效组织、语义检索和语义导航等具有重要作用。因此,为了提高语义挖掘获取知识模式的准确度和有效性,首先要构建领域本体。[8]构建领域本体的途径比较多,现在比较流行的是通过借鉴Gruber提出的本体构造规则以及斯坦福大学的NatalyaFNoy和DeborahLMcGuinness提出的建议。领域本体的构建过程包括:① 确定本体的领域和范围,为了尽可能地降低本体构建的成本,要优先考虑重复使用已存在的本体;② 列举出领域中的关键术语、概念,并对领域中的类、类的层次结构以及类的属性进行定义,这部分是对概念模型的描述,需要利用OWL描述语言并借助Protégé+OWL插件的本体开发工具来完成;③ 创建实例;④ 检验和评价所构建的本体。
3.1.3 本体映射
本体映射是基于已有本体的一种本体学习技术,即对已经存在的本体进行集合、提取、删减等操作构建出一个新本体,或对原来本体进行优化。[9]本体构建所具备的主观性和分散性特征,造成了在同一领域内保存有多数相互关联但又不完全一样本体的现象。由于这些本体间在语言层次、模型层次上存在不匹配的本体异构现象,从而造成了关联数据信息交互的障碍,引起相互关联的数据集在本体层上关联度降低甚至缺乏。本体映射的核心是寻找不同本体中元素的对应关系,从而实现不同本体之间的互相操作,形式上比较灵活,能更好地适应动态交互的、跨平台的、分布式的环境。本文借鉴领域本体概念并结合各种数据挖掘技术,构建了Web环境下基于本体映射的语义挖掘模型。在整个本体映射阶段:① 标准化所有目标本体,即将所有目标本体用同一形式来表示;② 解析本体的文档,从本体中提取出核心特征用于计算概念相似度;③ 开始相似性值的计算,并将计算得到的每对相似性值组合在一起形成一个多维的概念相似度矩阵;④ 依据相似度矩阵发现对应的映射规则和元素间的对应关系,一般包含进行映射的前提和对应的转化法则。
3.2 语义挖掘模型设计
本文构建的Web环境下语义挖掘模型的运行机理是先实施Web数据资源的挖掘,然后利用语义Web本体映射技术为语义修正和扩充提供指导,以便获取基于语义的高质量的知识规则(见图1)。具体过程是,先对Web数据源进行处理,通过各种数据挖掘工具给出的算法将Web数据源有目的地分成Web文本数据、Web链接数据、Web使用数据,然后分别从中抽取一些有价值的、潜在的信息组合成网络文件。由于网络文件中除了含有结构化数据外,还含有大量半结构化乃至非结构化数据,所以需要对这些半结构化和非结构化数据实施预处理操作,以完成非结构化数据的删除以及数据形式由半结构化向结构化的变换。目标数据库是对经过上述过程提取到的高质量的信息资源的集成。Web挖掘主要是借助各种数据分析工具提供的算法,从目标数据库中获取隐藏在其中的知识模式的过程。在检验和评价知识模式阶段,首先结合领域本体的概念体系及其领域属性,发现知识模式中的概念簇和相关实例,计算知识模式中每对概念的相似性值,组合成相似度矩阵,进而产生相应的映射规则并发现不同本体间元素的对应关系。然后将获取的知识模式和领域本体进行对照,并参照领域本体对知识模式进行语义修正和扩充,最终形成语义知识模型。这样不仅强调本体映射技术对于提升Web数据挖掘最终获取的知识模式的质量具有重要的作用,还创新性地将本体映射技术与数据挖掘算法相结合,发现知识模式中概念间的关系,提高知识模式的质量。
3.2.1 数据预处理
网络文件中的数据作为形成知识模式的数据源,数据预处理的效率直接影响到最终获取的知识模式的质量。其大致包括以下四个主要环节。
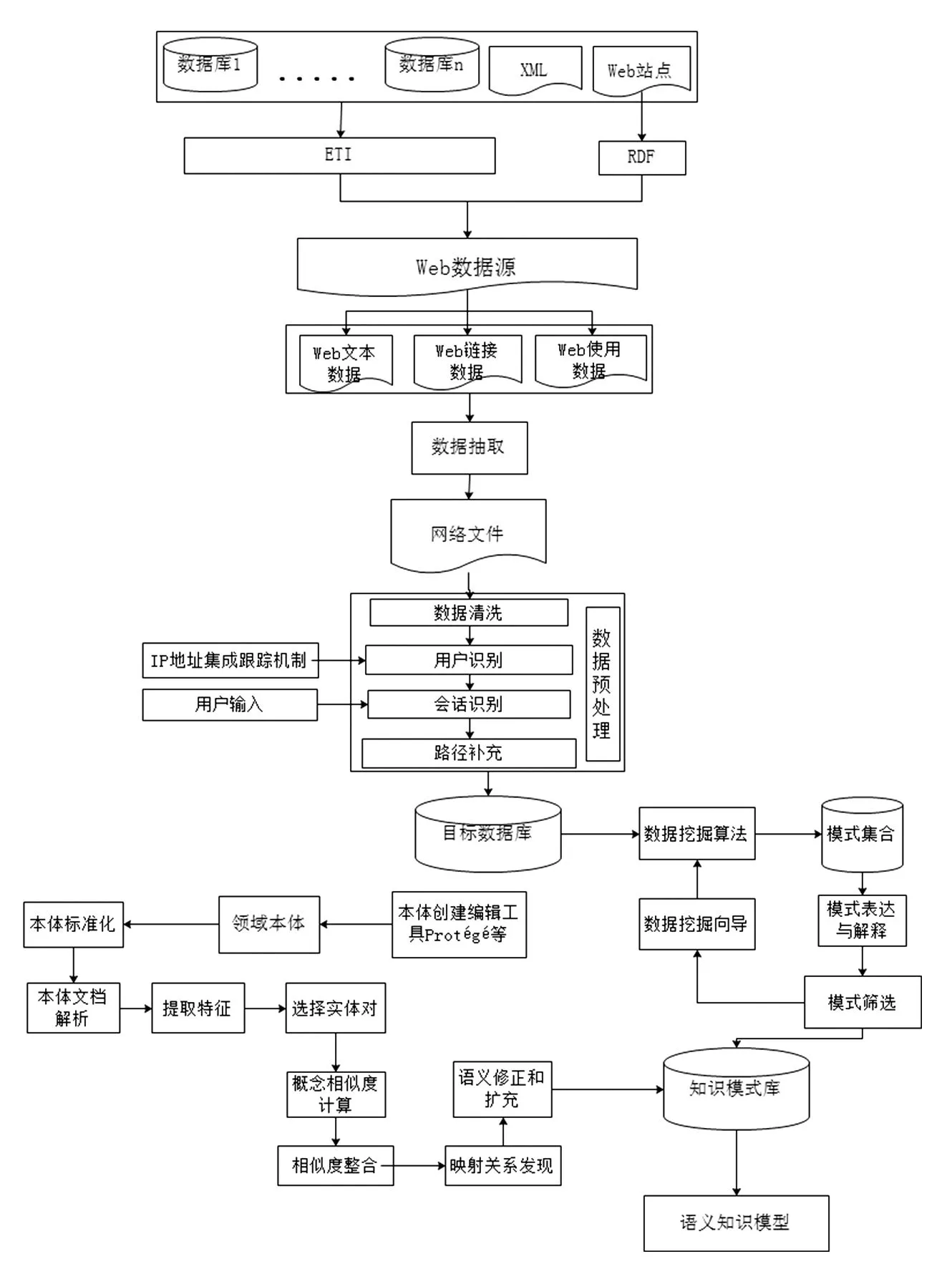
图1 语义挖掘模型
(1)数据清理。数据清理作为数据预处理的首要任务,一般包含偏差检验及数据形式转换两个步骤。其基本原理是借助相关技术,如数理统计方法、数据挖掘技术、预设模式规则法等,清除与挖掘过程无关或冗余的日志项,删除重复记录,纠正错误请求等。在数据清理环节要注意以下几个因素:区分不同用户需要的信息;通过哪些信息有效识别用户会话;与知识模式表达及解释的数据项有哪些;如何筛选通过用户会话识别的WebRoot浏览记录。通常HTML页面中与Web挖掘无关的日志记录、WebRood的历史浏览日志记录以及有误的访问记录需要清洗。HTML页面中与Web挖掘无关的记录主要包括一些多媒体文件、文本文件、CSS样式表等。其中多媒体文件主要是HTML页面中的图像(*.gif、*.jpeg、*.jpg)、声音(*.mp3、*.midi、*.cd)、动画等被引用的资源。在进行数据清洗时,这些无关的记录可以通过查看URL的后缀来清除,如,所有后缀名为*.gif、*.jpeg、*.jpg、*.mp3、*.midi、*.cd、*.avi、*.swf、*.js、*.css的文件都要被清除。WebRood历史浏览日志记录主要通过检查请求页面的URL后缀来识别,清除所有后缀为Robots.txt的文件。有误的访问记录中通常含有“Error”或“Failure”的状态码,服务器可以通过寻找Web日志中的状态码来清理有误的访问记录。
(2)用户识别。用户识别是从浏览器历史访问记录中区别出对应的用户,建立用户与所浏览页面之间联系的过程。数据预处理阶段比较常用的用户识别方法是通过解析Web日志中的IP地址和UserAgent类型等信息,来区别同一Web站点上的用户。一般采用以下规则识别用户:① 一个IP地址只能唯一标识一个用户,也就是说,IP地址不同代表的用户也不同;②如果IP地址一致,但是UserAgent信息(如操作系统或浏览器类型)只要有一个存在差异,就可以假定不是同一用户在访问该Web站点;③ 假如IP地址与UserAgent信息全部一致,则需要确定每个被请求的页面与历史访问页面间是否存在直接的链接,如果不存在,则假定同时有多个用户在访问该Web站点,如果存在,就默认被访问的Web站点上只有一个用户。
(3)会话识别。用户会话是指用户使用特别指定的IP地址在一个具体的时间范围内访问一个站点的一连串活动。会话识别主要指把相同用户在一次浏览过程中的连续请求聚类形成有价值的Web页面序列。用户会话识别常用以下规则:① 新用户和新会话同时产生;② 在某个用户会话中,若出现引用页面为空或者不存在的情况,则假设该用户又进行了新的会话;③ 若两个被请求的页面在时间上的跨度超出规定的上限(一般为30min),则假设新的会话又启动了。
(4)路径补充。用户的历史浏览记录都被存储在本地缓存存储区中,Web服务器在发送访问请求之前会检验本地缓存区中是否存在和被访问的URL相匹配的URL。假如存在,那么访问请求不再被发送,直接从本地缓存中抽取目标页面提供给用户。通常,一些点击率高的信息都会被存储在本地缓存区中。当HTML页面中Meta标志设定过期时,本地缓存就会失效,很多重要的访问记录被遗失。路径补充是用来填充遗失的页面引用,改善能够被区别出的用户会话,正确地描述用户的访问请求。假如用户目前请求页面与最后一次请求页面之间存在直接链接,则说明用户也许利用“Back”按钮进行后退来缓存网页读取;反之就认为本次用户会话没有调取本地缓存中的资源,且历史请求页面中,时间上最接近现时被请求页的页面即为现时访问请求的起源。
3.2.2 概念相似度计算
概念相似度作为领域本体中概念相似性的度量标准,能够表示概念间语义路径距离的远近程度。其值的获得是整个本体映射阶段非常关键的一步,影响着映射规则的产生和元素间关系的发现。目前,要想获得领域本体概念相似度矩阵,首先要算出领域本体中两两概念之间体现出的相似性的值。计算之前,要判断这对概念是不是同义,若同义,就可以判定它们全部相同,相似性值记作1。否则,得到该相似性值需要经历两个阶段:语义初始相似度阶段和非上下位关系相似度阶段。语义初始相似性值是根据每对概念之间的语义路径距离求得的,还可以认为是每对概念语义相似性的约定值,通常用ISim(Ci,Cj)表示概念的语义初始相似度。非上下位关系相似度可以理解为是基于语义初始相似度,经过分析每对概念的非上下位关系得到的,用Simfss(Ci,Cj)表示。计算非上下位相似性值之前,需要判断概念的关系类型是概念型还是Datatype型:Datatype型的关系与数值型数据对应,与概念无关;概念型的关系与概念对应,与数值型数据无关。通过对以上两种相似性值分别分配权重,算出它们的加权和即为每对概念的实际相似度Sim(Ci,Cj)的值。
定义1:如果领域本体中一对概念C1与C2同义,则它们的实际相似度Sim(C1,C2)=1。
定义2:一对不是同义的概念Ci和Cj之间上下位关系表现出的语义初始相似度为
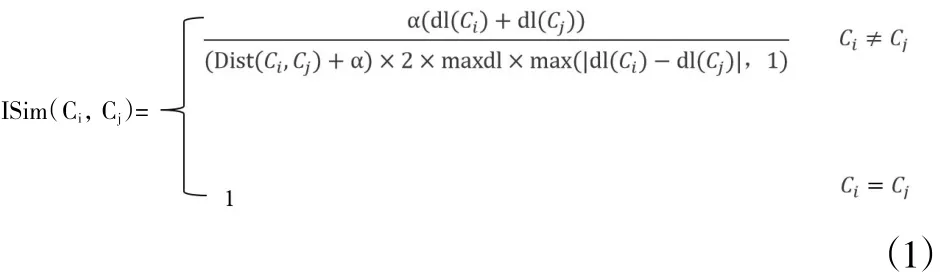
其中,ISim(C1,C2)表示概念C1和C2的语义初始相似度,dl(C1)和 dl(C2)分别代表 C1和C2所处的层次,Dist(C1,C2)是概念C1和C2的语义路径距离,maxdl是概念在本体中所处的最高层次。α是参数,可以改变,由领域专家确定,一般≥0。此处,为了方便,将计算结果归一化,需要乘以该参数。
定义3:若Rdt1和Rdt2是一对Datatype型概念关系的关系名,则它们的相似度是
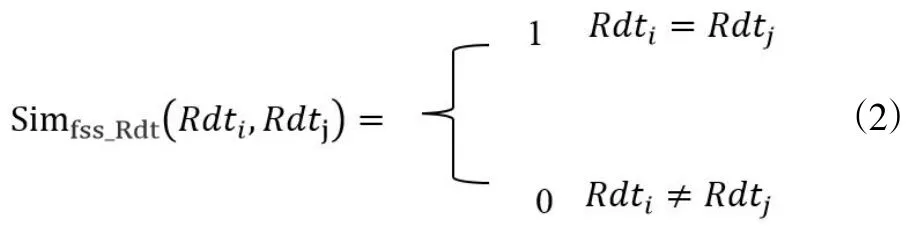
定义4:一对不是同义的概念Ci和Cj之间非上下位关系表现出的相似度Simfss(Ci,Cj)为
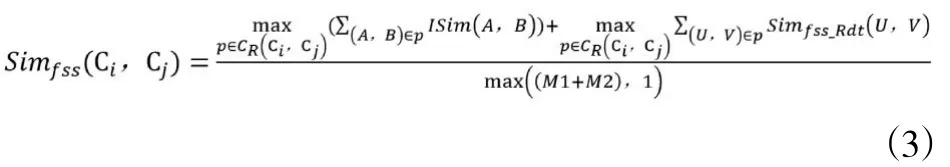
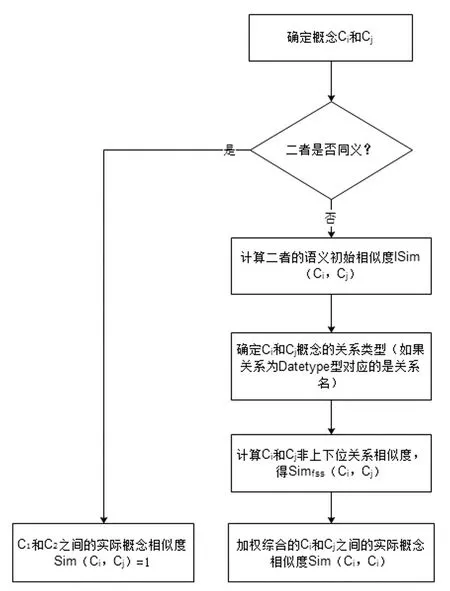
图2 算法流程
定义5:领域本体中,一对不是同义的概念Ci,Cj的实际相似度为
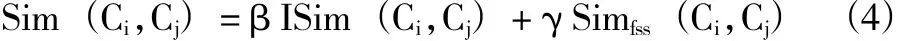
其中β、γ分别表示分配给两种相似度的权重(一般假设 β=γ=0.5),0<β<1,0<γ<1,β+γ=1,一般β≥γ。
3.2.3 知识模式的语义修正和扩充
知识模式的语义修正和扩充以概念相似度算法为基础,通过知识模式进行本体推理,主动寻找知识模式中与领域本体概念不一致的词汇,依据相应的规则删除词汇间关联度相对低的知识模式,并对词汇进行概念的全方位逻辑推理扩展。进行知识模式的语义修正和扩充能够提高特定学科领域的核心知识体系所体现的概念间的关联度,从而使数据挖掘最后提取到的知识模式更加准确、有用和全面。知识模式的语义修正和扩充的大致过程如下。
(1)使用概念相似度计算公式求得知识模式各个词汇节点之间的相似性值A。
(2)依据领域本体概念体系,使用概念相似度计算公式交叉求解知识模式中具有上下位关系的词汇节点间的概念相似性值B。如果B≥A,就把变换过的概念模式集合保存到知识模式库中。
(3)依据领域本体概念体系,使用概念相似度计算公式交叉求解知识模式中具有非上下位关系的词汇节点间的概念相似性值C,如果C≥A,就把变换过的概念模式集合保存到知识模式库中。
