基于词性合并的浅层句法分析方法研究
2018-11-09刘利
刘利
(泸州职业技术学院信息工程系,四川 泸州 646005)
1 引言
互联网作为开放式的知识库,信息具有海量、多样、散乱等特点,网页作为信息的载体,利用互联网构建知识库,则演变为对海量网页文本信息的抽取及结构化的研究。当前,文本信息抽取的对象有结构化、半结构化或非结构化信息,而抽取文本信息方式主要分为两类[1],一类是机器学习方式[2],从结构化和半结构化信息抽取数据;一类是自然语言处理[3],从非结构化的文本信息中抽取有价值的数据,就网页自由文本信息特点而言更加适用。
在利用浅层句法分析方法上,钱伟中等人[4]提出了融合浅层句法分析的蛋白质互作用信息抽取方法,在生物学方面的文本抽取效果较好;周顺先等人[5]提出基于规则和统计抽取模型的主动学习算法,需要先标记训练集才能达到抽取同类信息的较好效果,不能很好地适应多样式的文本;庞文斌等人[6]进行基于规则和统计的汉语浅层句法分析的研究,利用统计的方式通过先识别谓词实现信息抽取,但缺乏考虑句式和代词带来的问题。
吕叔湘[7]早在多年前在其《中国文法要略》中提出“主-谓-宾”为句子的主干部分,它能反映句子的主要信息,而“句子的中心是一个动词”,对句子动词成分的确定有助于句子成分的整体分析。基于此,本文提出基于词性合并的浅层句法分析方法,在文本信息抽取比同类方法效果较好。
2 算法描述
文本信息抽取模块主要实现的功能是抽取文本信息的主旨内容,为进一步的信息结构化提供保障。本文算法从句子词性合并和句式分析两个方面着手,结合中枢论的观点分析句子的成分,抽取文本信息。
2.1 词性合并规则
汉语中可把复杂的句子转变为多个简单句,便于提高在句法分析中识别句子成分的准确率。对句子进行分词,将分词根据词性进行合并,共同组成句子成分,合并规则如下:
规则1:相邻并词性相同的词语进行合并,词性和末尾词词性一致。如:“法新社/nt记者/n经/p调查/vn后/f证实/v”经过转化后变为“法新社记者/n调查/vn后/f证实/v”。
规则2:对连词、“比/p”、顿号左右词性的合并,因为左右两边词性为并列关系,最后词性为末尾词词性。如:“北京/ns、/w天津/ns和/cc重庆/ns都/d是/vshi直辖市/n”转变为“北京、天津和重庆/ns都/d是/vshi直辖市/n”。
规则3:合并数词到距离它最近的名词,最后合并词词性为末尾词词性。如“一/m本/q书/n”经过转化后为“一本书/n”。
规则4:合并时间词,若其后为主语或谓语词词性则合并;若其后为助词,先判断助词后面是否有词,有则合并时间词到助词后面的词,没有则合并时间词及其前面的词。两种方式合并后的词性为末尾词词性,如“我/rr是/vshi 1995年5月/t的/ude1生日/n”转化后变为“我/rr是/vshi 1995年5月的生日/n”。
规则5:合并名词短语,具体为合并“的”字前后词,合并词性为末尾词的词性。“的”字短如“今天/t的/ude1天气/n”转化后变为“今天的天气/n”。
2.2 简化句式规则
按汉语句式可分为一般句式和特殊句式,前者由主谓宾构成,句子成分顺序容易判断;后者是将句子成分顺序进行变换,如倒装、前置等结构。
一般句式成分分析采用谓词中枢论观点,先确定谓语成分,谓语可由动词和形容词担任,通过对“知网-中文信息结构库”的词频统计可知动词作为谓语的概率比形容词大,故若在一个句子中同时出现动词和形容词时,则优先选用动词做谓语,其次是选用形容词。确定谓语后,再分析主语、状语、补语、宾语成分。复杂句拆分为简单句处理,处理后的结果合并为复杂句。如:主1谓1宾1和主2谓2宾2,如果宾1与主2相同,则合并为主1谓1宾1谓2宾2。
特殊句式为了突出句子某个成分通过特殊词语将句子成分之间进行交换。通常有把字句、被动句、判断句、连动句、兼语句和存现句。
(1)把字句是通过“把”字将宾语提前,并同宾语构成状语。识别方式为查找“把”前面的主语,后面的宾语和谓语。
(2)被动句是通过“被”关键字,将宾语提前到关键字之前,主语置于关键字之后。识别方式为查找“被”关键字,向前查找宾语,向后查找主语和谓语。
(3)判断句同普通句式一致,故处理方式按简单句处理。
(4)连动句是存在某种联系(如目的、因果、先后等联系)的多个谓语一起组成连动短语充当句子的谓语。处理方式为将多个相邻的谓语合并成一个,成分识别按简单句的方式处理。
(5)兼语句是句子某个词或短语句子多个成分,如:“老师让小明坐最后一个位置”,其中小明为兼语词。处理方式为将复杂句式拆解为多个简单句,然后按谓语中枢论观点识别句子成分,最后将简单句进行合并。
(6)存现句是表示某个事物或某个人的出现、产生、存在和消失的状态,如:“办公室坐着个人”。处理方式同一般句式处理方式一致。
2.3 信息抽取算法
对网页文本信息经过网页信息抽取、指代消解、词性合并、特殊句式识别、简单句式识别、句子信息提取和筛选过程。本文利用网页信息标题的特点,提取标题信息中出现词频最高的两个词(下面统称F词和S词),对文本信息筛选有很大帮助。句法分析具体算法实现如下:
输入:抽取的网页文本信息
输出:文本信息的抽取结果
步骤:
(1)利用交大分词对网页标题和正文信息进行分词,并统计出标题的F词和S词。
(2)指代消解文本信息,还原代词指代内容。
(3)按词性合并规则简化文本信息中句子结构。
(4)以“。”号和“;”号对文本信息分句,舍弃没有识别主谓宾的句子,再按上述句式处理规则先处理特殊句式,后处理一般句式,词性出现频率大小查找谓语位置,向前查找主语,向后查找宾语,统计知网后得出主、宾语查找的顺序是名词、数词、代词。若句子中包含时间词则保留时间词的位置。
(5)由于以段为单位进行文本信息抽取,如果经过句法分析的段落没有包含F词和S词,最后存储某段主旨信息时格式为“F词##S词##标题##某段主旨内容”。
(6)将所有段落文本主旨信息分析完成后,返回的结果即为整个文本的主旨信息。
3 句法分析实验结果
本文方法在谓语识别过程与庞文斌等人[7]都结合中枢论的观点,但使用算法不同,实验上将同他们的方法效果进行比较,文本信息抽取常用评价标准查全率(也叫召回率,Recall)和查准率(Precision)进行评价,计算公式如下:

其中,C1表示待提取的信息个数,C2表示已提取的信息个数,C3表示提取信息中的正确个数。查全率是在网页总数的基础上计算的,而查准率则是在已提取信息个数基础上计算的。
实验文本集选自1998年1月《人民日报》标注语料库,随机选取里面的文章,以句子为单位统计其查全率,用公式1。
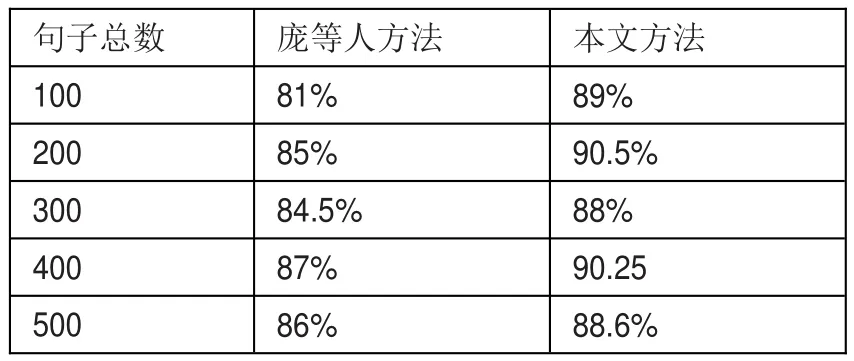
表1 谓语识别实验对比
通过表1对比可知,本文在谓语识别查全率较高,通过词性合并能简化句子成分,有助于谓语的识别。
通过词性合并和句式分析提取句子的主旨信息,并能达到阅读信息效果,本文对网页信息抽取的文本集为基准,利用词性合并的浅层句法分析方法抽取文本主旨信息,分别随机抽取100-500个句子,用公式1和2对最后结果进行评价。
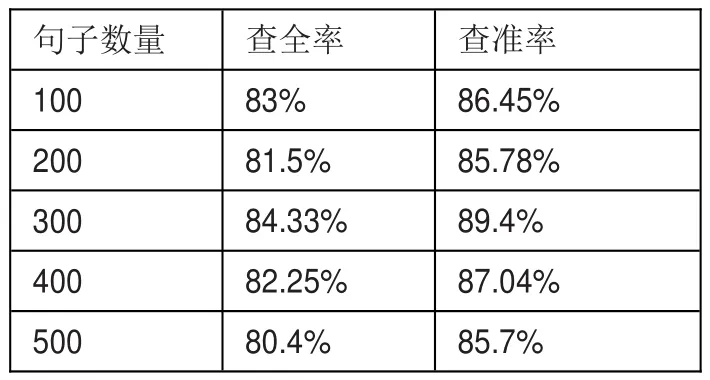
表2 句子识别结果实验
由实验结果可知,利用本文方法对句子主谓宾识别效果较好,查全率和查准率都保持在80%以上,能识别文本信息的主旨信息。同时,也发现有很多不常见句式和短语对识别效果产生干扰,后期可对这些问题更加深入研究,这将提升句子识别的准确性。
