“内容-交互”双维度产品信息处理方法及应用
2018-11-09王海朔郑红梅汪园园
王海朔 陈 科 郑红梅 汪园园
合肥工业大学机械工程学院,合肥,230009
0 引言
产品信息是指产品在全生命周期中产生的信息资料,它为设计者和生产者提供技术支持,是企业重要的信息资源。有分析报告[1]指出,构建新型的产品信息技术交付模式和实现全环节的数字化是释放企业业务能力的新的关键环节。在“中国制造2025”的背景下,产品信息的处理是促进企业内两化融合[2⁃3]的关键环节。因此,人们通过探寻各类产品信息的处理模式来改善产品信息的使用。
在工艺设计信息方面,HELGOSON等[4]提出了面向加工工艺规划的知识集成概念模型;CHEN等[5]提出了一种基于参数流程图(parame⁃ter flow chart,PFC)的知识表示方法,将参数信息、流程图技术和可视化技术有机地结合起来;HUANG等[6]针对数控加工过程中工艺计划的重用,建立基于特征的参数驱动模型,并论述了几何形状和加工策略之间的联系,建立了数控加工过程可重用性评估方法;郭鑫等[7]以“功能+流+案例”为规则构建本体,提出了面向创新设计目标的工艺知识检索模型,并建立了原型系统。
在产品的其他技术信息方面,刘畅[8]通过对维修服务方法的研究,结合其隐形知识的特性,开发了基于知识资源的复杂产品维修服务系统;白洁等[9]依托物料清单(bill of material,BOM)信息,提出面向典型行业产品的标准制造服务清单(bill of standard manufacturing service,BOSS)的概念。
在应用端方面,以提供大数据服务为支撑的“互联网+智能制造”的产品信息服务体系已初现规模。航天云网(http://www.casicloud.com)现已注册企业140多万家,发布需求信息10万余条,它构建了一个可以进行“双向选择”的信息展示平台。
综上所述,为改善各类产品技术信息在相应领域的应用,研究大多采取了对产品信息所存在的“生态环境”进行改造的方式,即让固化在原有组织结构中的信息,在新的环境下被重新表达。但由于制造类产品信息具有数据类型和格式的多样化,其信息内容包含要素繁多,导致现有的研究大多针对某一特定应用领域的产品的局部信息;同时,在工业数据大平台的构建中,目前主要实现的是产品信息的浅层交互。如何实现产品信息在广度与深度上的再表达,是需要解决的问题。
本文在现有研究的基础上,通过分析得出:面向更为广阔的数据类型并提供一定的交互性是产品信息数据处理的发展趋势。在此基础上,结合相关分析,提出了“内容-交互”双维度产品信息处理方法,以实现同质化资源的横向整合和差异化资源的扩充,从而挖掘资源的利用潜力,提高信息资源的有效性和信息重用的效率,通过预设场景描述了信息处理方法的运行机制。
1 产品信息处理的需求分析
产品信息的处理实际上是架构产品信息在数据端和人之间的流通体系,其处理过程同时面向上游的数据源和下游的人员。因此,这两方面在约束着信息处理方式的同时也对其提出了要求。
1.1 产品数据类型分析及需求提出
二十多年来,企业在实现资源信息化的过程中,侧重于发展应用集成,这给其现在的数据集成带来了一些负面影响。这些杂乱无章和相互混淆的各种应用程序集成技术,致使企业在信息处理的过程中问题不断[10]。在“万物互联”的背景下,各种非关系型数据大量进入企业的存储库,致使原有的关系数据在存储库中不再是主体。非关系型数据的整理和调用并不便捷,其蕴含的价值一直得不到有效应用。
从数据结构上可将数据划分为结构化数据、非结构化数据和介于结构化数据和非结构化数据之间的半结构化数据。
(1)结构化数据(structured data)一般存储在关系数据库中,具有相应的逻辑结构,比如存储在企业ERP和财务系统软件等核心数据库中的数据。
(2)非结构化数据(unstructured data)结构不固定,无法直接使用关系数据库储存,只能用各种类型的文件形式存放,比如文本文件、图片、图像、音频、视频、CAD图纸和模型文件等。非结构化数据通常无法直接知道其内容,必须通过对应的软件才能打开浏览。数据库通常将非结构化数据保存在一个BLOB字段中,以和原文件形成映射[11]。由于无法从数据本身直接获取其表达的含义,因此无法实现对文件本体内容的直接检索,比如企业的PDM系统。
(3)半结构化数据(semi⁃structured data)没有明确的模式定义,模式信息通常包含在数据之中,即模式与数据间没有明显的界限,这样的数据被称作自描述型数据。某些自描述信息存在着不明显的结构,如XML文件;某些自描述信息的结构可见但不规则,一个数据集合可能由异构的元素组成,同样的信息可能由不同类型的数据表示[12⁃13],如邮件、HTML等。因此,面向信息内容的产品信息处理需要解决如下问题:①如何排除不同类型的数据在格式上的异构性,并通过何种机制处理这些数据,获取信息内容;②如何架构并规范数据的表达方式;③如何使信息资源之间存在更加紧密和多样的联系。
1.2 组织社群化分析及需求提出
不断发展的信息技术使信息经过网络媒介的传递,突破原有时间和空间的约束。各类信息在产生、传输、接收、反馈和再生产的过程中,体量不断增加,并与参与的人员联结,形成不同的应用场景。在此过程中,网络空间的无边界性扩大了人们的认知空间和交互范围,催生出更多的需求和满足需求的应用场景。在各应用场景中,人们或因需求或因兴趣聚合在一起,彼此之间交流互动后建立了一定的社会联系,构成了网络知识社群的关系网。通过对成熟社群的分析,可以发现不同的个体以相同的兴趣为依托进行多层次的传播互动和关系建构。在知识共享过程中,知识社群成员既能实现个体性表达愿望,又能和社群其他成员产生情感共鸣[14]。这样,社群在信息生产和保障上比以往的组织形式更加具有生命力。
在工业领域,传统企业的组织模式已不能适应用户主导和灵活多变的市场需求。围绕产品的开发与生产过程,用户与各类服务供应商组成社群,通过大规模协作,将个性化需求转化为实际产品或方案,实现开放创新和价值共创[15]。为适应未来的制造环境,江平宇等[16]通过分析对社群化制造进行了定义。在产品的开发和生产各环节中存在、产生和流通的信息,也面临着组织社群化的影响。从主动性来说,组织社群化可以提供更加优质的信息内容,而且良好的交互体验会促进信息丰富化、表达专业化和要点分类精准化。从被动的角度来说,这是制造社群化倒逼着产品信息的处理方式与之相配套。
社群化的发展,本质上是为了满足参与主体在内容和交互两个维度上不断提升的高质量的需求。这种高质量体现在:信息内容的准确性、完备性、时效性、信息交互时响应的及时性、传播模式的便捷性。因此,面向组织社群化的产品信息处理需要解决如下问题:①采用何种信息处理方式,让人们更容易进行表达;②如何规范人们的表达,使得计算机更容易处理;③如何将人员的社群属性介入到产品信息中去,以改善产品信息的组织和表达;④如何让更多的人员参与进来,实现价值共创;⑤能否建立一个统一的数据视图,以满足用户对于数据的统一访问需求。
面向更广阔的内容和面向更深层的交互是相辅相成的。信息的内容为交互提供了连接节点,信息也在交互的过程中对其内容不断充实完善。
2 “内容-交互”双维度产品信息处理方法
在制造企业里,产品信息的内容被固化在格式文件里,而格式文件又被单一或为数不多的几种逻辑模式固化在信息系统内。以当前企业常用的PDM系统为例,项目各阶段产生的技术文件通常归属于该项目的基线之中,文件之间的逻辑关系同时也被固化下来。如图1所示,技术文件Ⅰ和技术文件Ⅱ、Ⅲ,分别产生于2个不同的项目。技术文件Ⅱ、Ⅲ产生于同一个项目的不同阶段,所以在文件归档后,2个文件之间形成了关联。即使技术文件Ⅰ和技术文件Ⅲ存在着内容上的某些联系,它们也不能产生直接关联,这是因为它们分属于不同项目下的产品基线。有的企业会制定文件的命名规则,比如图号的分类命名,这样文件之间也会产生一些其他的连接方式。这些固化的连接方式导致信息的重新调用逻辑单一,给信息的重用设置了门槛。
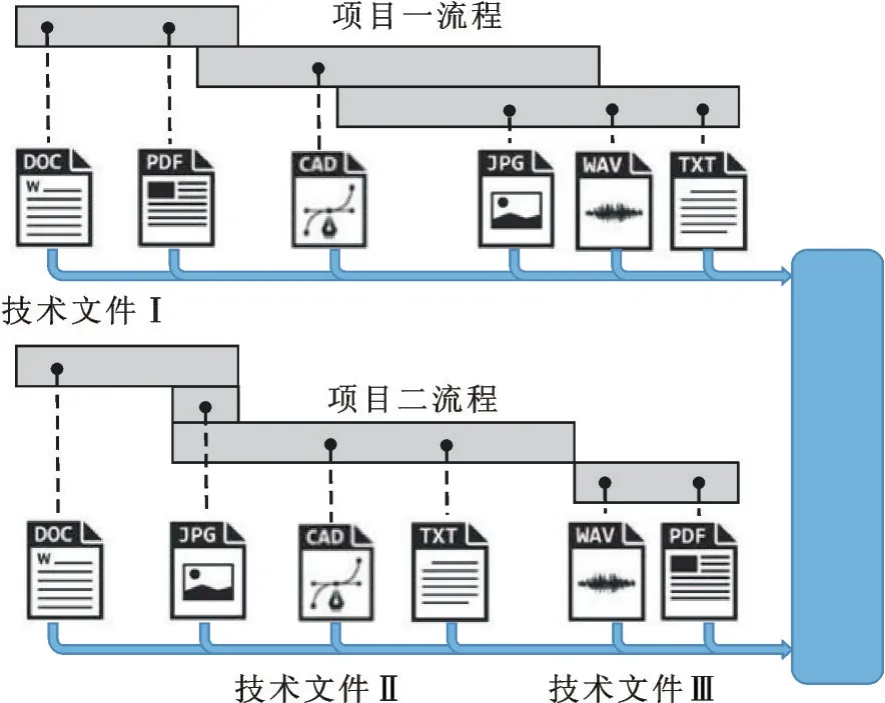
图1 固化在项目基线中的产品信息Fig.1 Product information solidified in the project baseline
2.1 产品信息的重塑
通过人工定义的抽取方法提取文档中的描述区域,并用一定格式的文本对其进行描述。描述信息除了包含对内容的语义化表达,还记录着路径、地址、获取的方式及其中的关键词语等信息。数据集成部分通过对描述信息的解析,对数据进行二次加工和处理,通过语义分析及元数据处理过程,去除数据背景中的冗余成分和不规则术语,对数据修正后进行存储。
由于对全文本信息的处理技术已经相对成熟,所以对产品信息中其他格式类型的资源进行区域切割,通过对域块的语义描述,将多类型信息的表达问题转换成语义问题。这个过程也可以看成是信息的离散化。如图2a所示,参与人员A、B、C分别在项目一、二中参与了项目的不同阶段,但其项目角色没有限制其对技术文件的信息处理。如图2b~图2d所示,参与人员分别对产生于不同项目、不同阶段的技术文件中的局部区域进行描述。以图2b为例,过程b⁃1表示参与人员A对word文档的灰色区域进行语义描述;过程b⁃2表示参与人员B和A分别对文档的同一区域进行语义描述;过程b⁃3表示参与人员C对参与人员A的描述结果进行再描述(评价、修正、补充等)。图2c、图2d所示分别为参与人员对图纸和测试资料的信息重塑。
随着时间的推移,项目周期中各阶段的参与者不断地对产品进行语义描述,或是开辟新的描述区域,或是对原有区域的再描述,或是对之前描述的再描述。描述信息不断丰富,对原始资料的表达也会越来越完整,从而完成了对原有信息的重塑。
在此过程中,人工描述可能会出现下列情形(图3):
(1)一对一。一个描述区域只对应一条描述信息,如区域的类型与描述的类型一致,则直接映射。
(2)一对多。一个描述区域对应多条描述信息,这可能是不同人员对该区域的不同描述,也可能是同一人员在不同时间对该区域的不同描述。
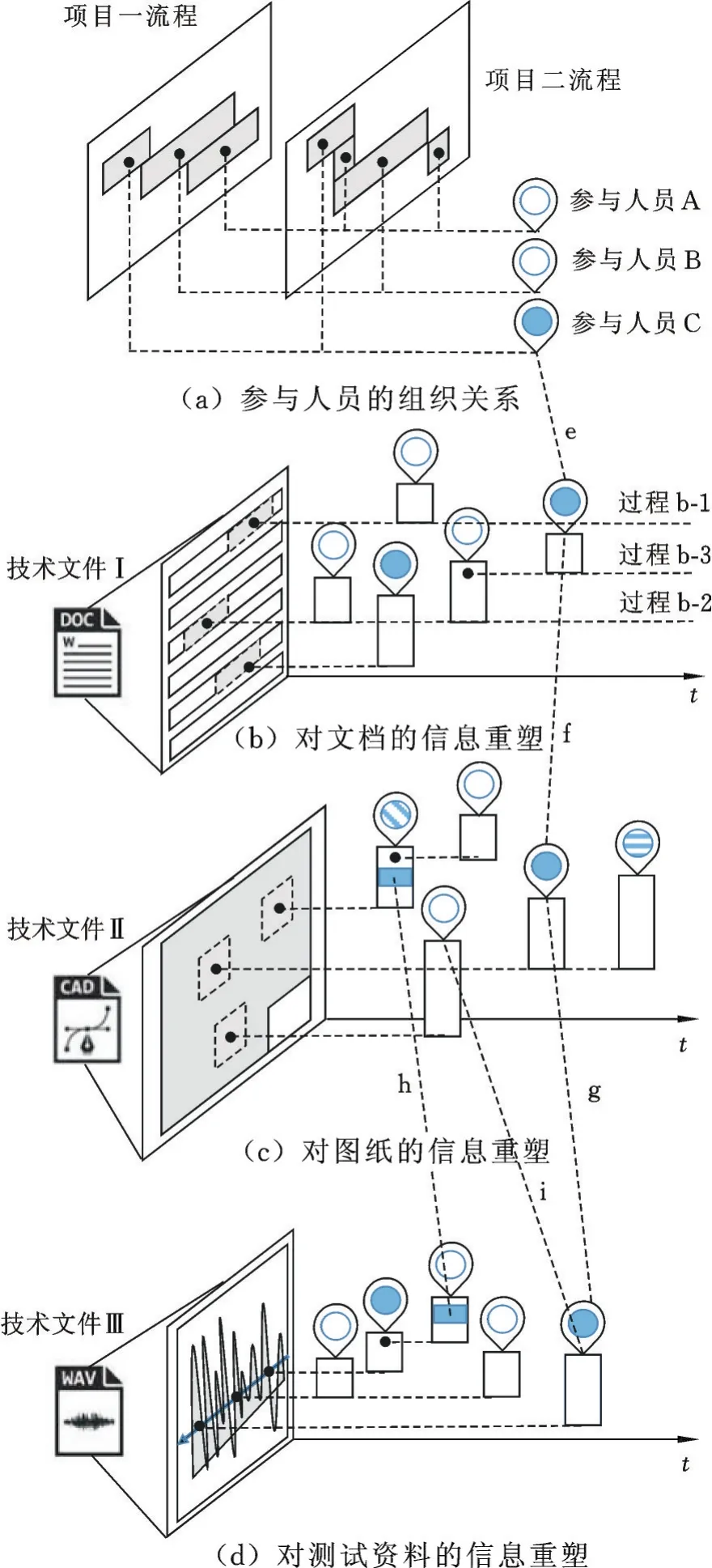
图2 三类产品技术信息的重塑过程Fig.2 Information to reshape for three types of product technical information
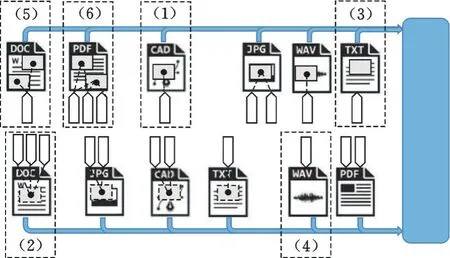
图3 描述信息的形成Fig.3 Generation of description information
(3)一对零。有描述区域但没有对应的描述信息,这可能是有描述信息,但并没有指向描述区域。(4)零对一。一个文件没有被提取描述区域。(5)多对一。多个描述区域对应同一条描述信息,比如共享的标签信息。
(6)多对多。多个描述区域对应多条描述信息,通常情况下,多对多的映射都可以分解为多对一的映射类型。
2.2 动态数据关系的产生
利用语义匹配算法识别数据之间的关联性,动态建立起企业的数据字典,维护元数据及其关联性。动态数据结构利用数据来探索和发现数据之间的多维关系,如图4所示。此外,动态数据结构还将这些关系通过交互技术及空间、时间和社交网络显示出来,其过程参见图1、图2。技术文件Ⅰ和技术文件Ⅱ、Ⅲ分别产生于2个不同的项目,分属不同的基线,因而它们之间不存在直接的连接,如图1所示。在图2展现了产生连接的3种情况。
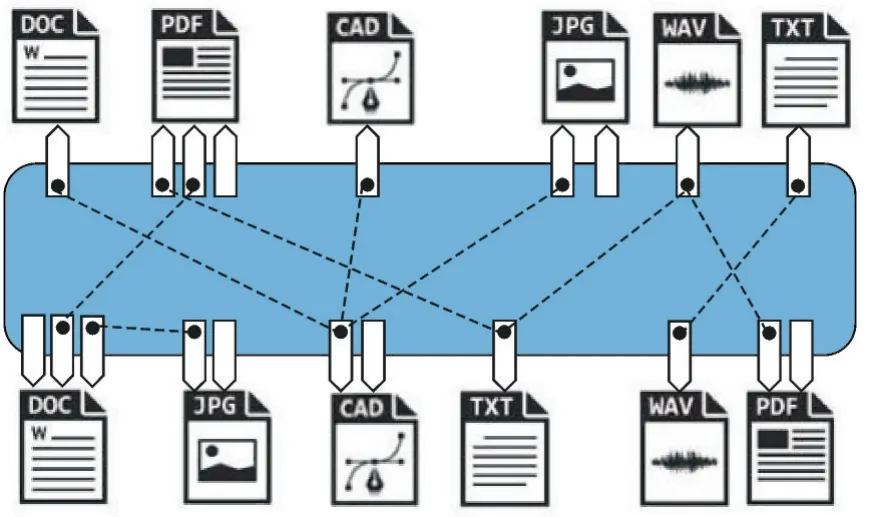
图4 产品信息间形成动态连接Fig.4 Dynamic connection between product information
(1)连线e⁃f⁃g。同一人对不同的技术文件进行区域描述,各文件因人而产生了关联。
(2)连线h。不同技术文档上,相同的语义描述片段(如关键词)让各文件产生关联。
(3)连线i。标注信息会因标注人之间的组织关系而产生关联。
2.3 交互性的赋予
社群组织架构里的人员加工产品信息时,也将自身的属性(包括自身在组织架构中的角色、自身所关注的信息和在信息处理系统中的历史记录等)赋予给了描述信息,这就形成了产品信息与人之间的互联。当人员的社交属性被数据化时,作为载体的产品信息也就被赋予了一定的人格化,具备交互性。
2.4 产品信息处理平台的功能架构
对产品信息的处理需要依托相应的平台来实现。该平台的架构应该包含后台管理支持等8个模块,用户认证模块外的其他模块面向的是普通用户,相应功能如下。
(1)用户认证。体现社交性的第一步,确定人员角色,明确其权限。
(2)文件资料上传。该模块是平台初始资源的输入模块。
(3)语义标注系统。通过该模块,用户指定描述区域,并对其进行语义描述。视频弹幕是很好的借鉴对象。弹幕可被定义为,在视频时间轴的某一时间点上,用户对视频静态画面的语义描述。只是在视频网站上,这种表达更多的体现为社交性,而并不具备内容的再表达。但部分国外原版视频,有些用户会利用弹幕来进行翻译,即对内容信息进行处理。
(4)标签选择系统。对于已经被过描述的资源,系统通过分析分配相应的标签描述给该资源,以供用户选取。标签是一种更加简洁、精准和规范的语义描述,更加利于信息分类。
(5)在线聊天窗口。是用户进行实时交互的模块。
(6)留言板。用于发布不强调及时交互性的用户间信息的模块。
(7)检索引擎。用于精确检索或关键词匹配,便于用户搜索到相应信息。
3 应用场景
实现数据管理和架构信息处理的平台需要对其功能的实现预设场景,来考量模块的选取和模块间的配合,以及是否能从“内容-交互”两个维度对产品信息进行处理。下面将通过对产品信息内容标注场景的描述,来体现2.1节的产品信息重塑过程;通过对产品信息内容关联场景的描述,来体现2.2节的动态数据关系产生过程;通过对社群人员之间交互场景的描述,来体现2.3节的交互性赋予过程。
3.1 产品信息的内容标注
标注场景描述了项目社群人员对产品信息的内容标注。参与人员登录产品信息处理平台,通过用户认证获取相应的权限。获得权限的用户一方面可以通过平台的文件资料上传模块,将项目流程中产生的文件上传至系统;另一方面可以通过平台的语义标注系统,选取文件中的区域进行语义描述。如图5所示,在空气滤清器项目的产品认证阶段,分别在流场仿真和NVH测试环节产生了技术文件,技术人员提取了实验报告中的关键图片,并对应于语义描述。

图5 产品信息的内容标注场景Fig.5 The scene of content annotation for product information
3.2 产品信息的内容关联
该关联场景描述了产品信息内容之间的关联。在这里,平台的标签选择系统,根据文件的描述内容,统计出高频词或短语,并作为标签赋给相应的文件,以提供关联节点。同时,这些标签信息也有助于实现平台内的信息检索。如图6所示,在空气滤清器项目模态仿真阶段和实验模态测试阶段,分别产生了相应的实验报告和现场拍摄照片。通过3.1节描述的场景,完成了相应的内容标注。经过语义分析和词频分析,每个文档都被配给了多个关键词标签,而它们共同都具有一个“模态”的标签,因而这3个文档之间产生了关联。
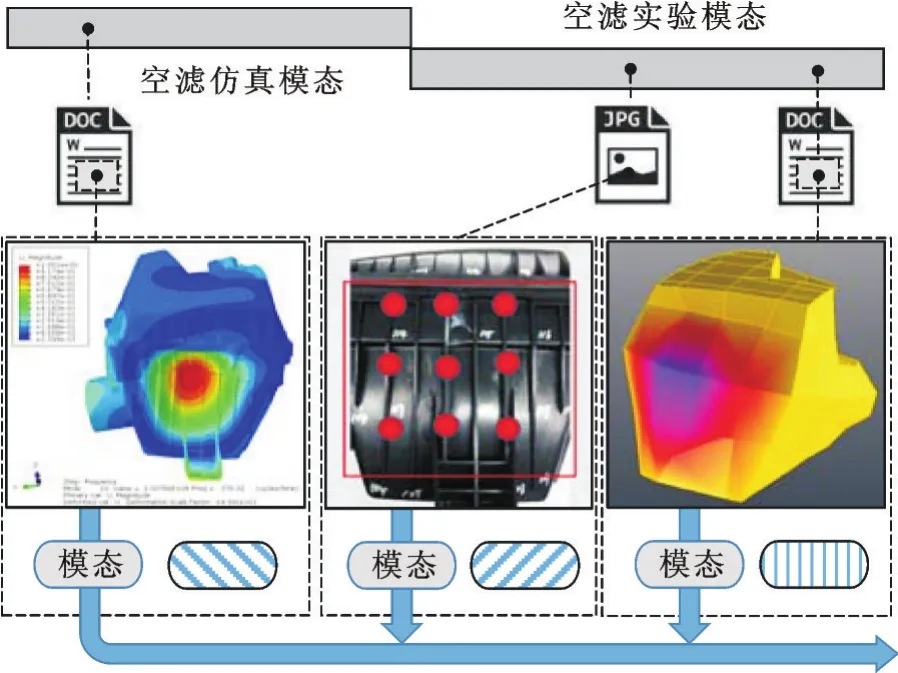
图6 产品信息的内容关联场景Fig.6 The scene of content association for product information
3.3 社群人员之间的交互
该交互场景描述了产品社群中人员之间的交互场景,用户可以通过平台的在线聊天窗口进行实时的沟通,也可以通过留言板模块发布信息。如图7所示,在空气滤清器项目实验报告制定和后续实验环节,处于项目流程第三项——老化后密封实验的人员对相应的工作提出了疑问,但第一时间回答他的并不是他期望的回答者——实验大纲的制定者,而是共同关注了关键词标签“真空试验台”的第二阶段抗负压能力实验人员。该场景也体现了信息内容间的动态联系对项目的进行具有正面的影响。
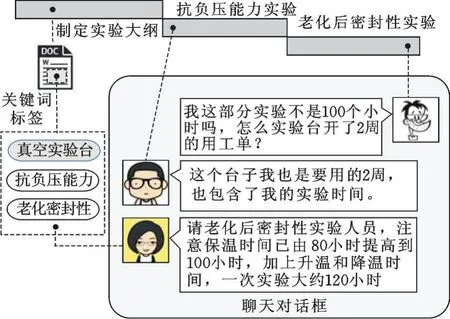
图7 社群人员的交互场景Fig.7 The interaction scene of social community members
4 结语
本文结合产品技术信息处理方法的研究和应用的现状,分别阐述产品数据现有的类型和制造社群化背景下组织形式的改变,并从这两个方向讨论了相应的需求。在此基础上,提出了“内容-交互”双维度产品信息处理的方法,通过预设应用场景,探寻了社交媒介和新兴信息技术与产品开发流程的结合方式。
研究表明,面向“内容-交互”的双维度产品信息处理方法在机械设计制造领域内可行。用户可以通过对设计信息的语义描述,避开数据类型和文件格式的限制,可以对更为广阔的数据内容进行处理。信息内容间的多重关联和社交模块的介入,让产品信息之间、用户之间以及用户与产品信息之间形成多重网络,使面向更为深层的交互成为了可能。
针对产品信息处理问题的后续研究可以从三个阶段展开:①借助产品信息平台的搭建,实现逻辑规则的完善、信息内容的语义特征及实体对齐,并将成熟的社交模式集成到系统中;②在产品信息平台的运行过程中,考察交互机制,使其更加适用于工业领域,可以对整体系统的动态稳定性和自组织性展开研究;③在数据累积到一定体量时,可以展开工业设计大数据集成和工业社群用户画像的研究等。
