面向问答的数值信息抽取
2018-11-08张桂平
张桂平, 张 宁, 白 宇
(沈阳航空航天大学 人机智能研究中心 辽宁 沈阳 110136)
0 引言
数值信息是数据中直观的表达方式之一.对于企业和其他组织来说,数值信息是生产、经营和战略等几乎所有活动所依赖的、不可或缺的信息.在这种背景下,从文本中准确地获取数值信息已变得越来越重要.问答系统允许用户以自然语言方式进行提问,系统返回准确、简洁的答案[1].我们把关于数值的问答分成两个步骤:第1步通过数值信息抽取来构建候选答案库;第2步针对具体数值问题从候选答案库中获取答案.本文所做的工作为第1步,为搭建问答系统做准备.
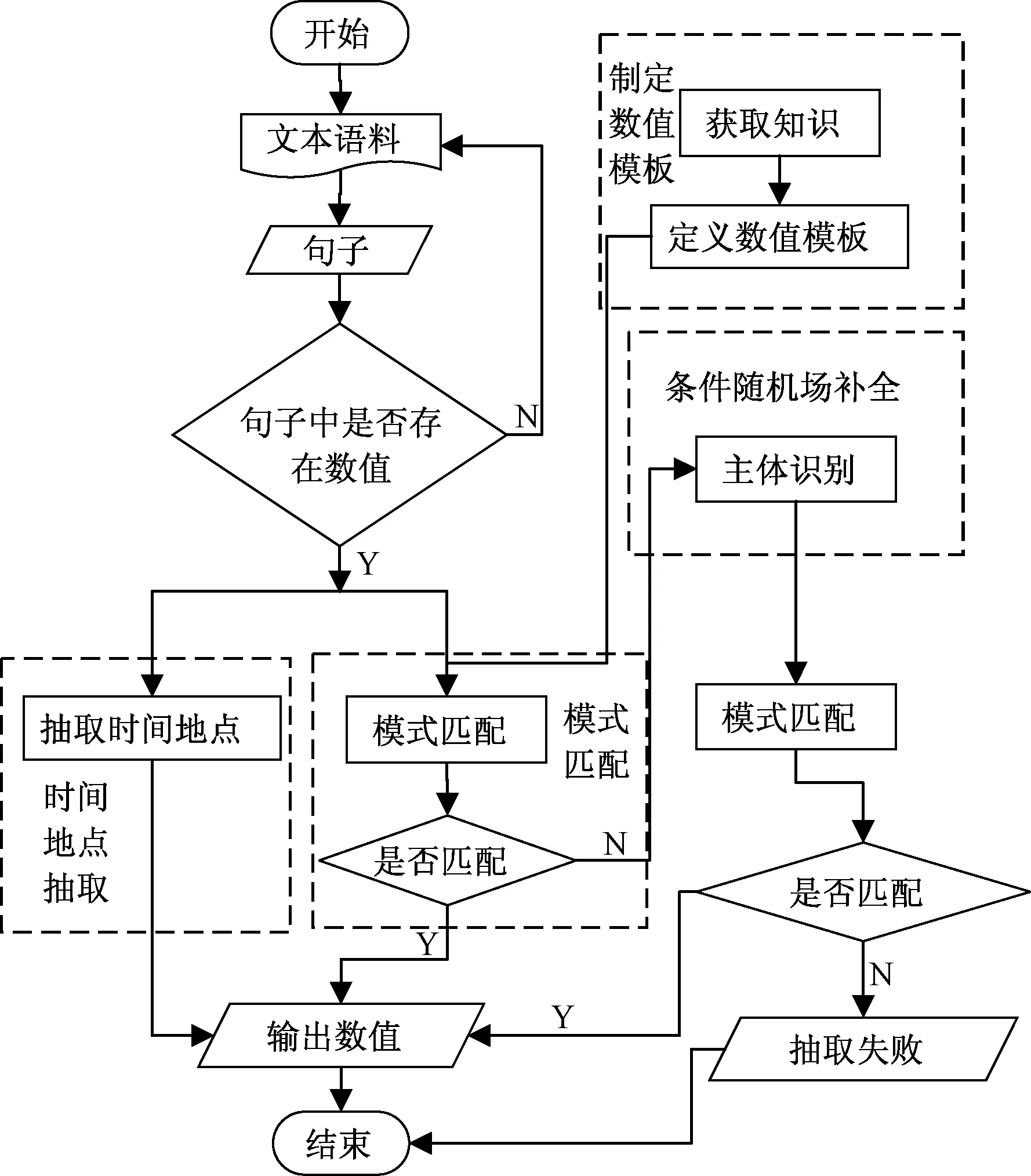
图1 数值信息抽取结构图Fig.1 Numerical information extraction structure diagram
本文的数值信息抽取结构如图1所示,将数值信息抽取分为4个模块:制定模板模块、模式匹配模块、条件随机场补全模块、时间地点抽取模块.
(1) 制定模板模块. 分析数值信息的表达模式并且获取数值相关的知识来制定抽取模式,最终形成模板库.
(2) 模式匹配模块. 利用模板库提供的模板来对文本进行模式匹配.
(3) 条件随机场补全模块. 在模式匹配模块中没有成功匹配的文本,条件随机场进行“主体”识别,识别之后再用模板进行匹配.
(4) 时间地点抽取模块. 抽取时间和地点,结合模式匹配模块的输出或条件随机场补全模块的输出,最后输出数值信息.
定义1绝对数值信息. 无比较的数值信息.
定义2相对数值信息. 比较之后产生的数值信息.
定义3第1时间. 相对数值信息中的被比较时间.
定义4第2时间. 相对数值信息中的比较时间.
本文以篇章中的句子为单位,见表1,用标题“2016年10月全国国民经济延续稳中有进发展态势”作为输入,输出是元组.产生的绝对数值信息如表2所示,产生的相对数值信息如表3所示.

表1 输入例子
例如:“2016年全国棉花总产量534.3万吨”是无比较数值信息,为绝对数值.绝对数值信息由七元组(见表2)构成,分别为:主体、属性、数字、单位、时间、地点、确定度.

表2 输出例子(绝对数值)Tab.2 Output example (absolute value)
例如“2015年棉花产量比2014年减产38.0万吨”是有比较的信息,是“2015年”和“2014年”进行比较产生的数值信息,所以为相对数值信息.“2015年”是被比较时间,所以为第1时间,“2014年”是比较时间,所以为第2时间.相对数值由九元组(见表3)构成,分别为:主体、属性、数字、单位、第1时间、第2时间、地点、趋势、确定度.

表3 输出例子(相对数值)
目前,国内外对信息抽取[2-3]领域的研究主要有3种方法:基于规则、基于统计机器学习和规则统计相结合的方法.早期,研究人员对信息抽取的探索主要是基于规则的.其中,朱文琰等人[4]采用一种基于正则表达式状态转换的算法,通过模型学习来抽取网页中的信息.使用规则的方法都具有较差的移植性.基于统计机器学习方法有:使用条件随机场[5-7],利用序列标注的思想对命名实体进行抽取,然而该方法需要足够多的训练语料.严倩等人[8]使用最大熵分类模型分别实现触发词的识别和分类.基于规则和统计相结合的方法进行信息抽取[9-10]依据规则和统计两种方法的先后顺序,分别存在两种形式.具体选择哪种方法,需要根据具体的问题来选择.文献[11]采用基于规则的方法:从海量年鉴文本中抽取宏观数值信息,为了使数值信息含义更加明确,使用了由六元组结构表示数值信息的方法,但没有对数值信息的表达模式做具体的分类,只定义了3种抽取模式.温有奎等人[12]利用人工抽取数值的经验,开发了数值型知识元抽取软件,用于抽取《年鉴》中的数值信息.Murata 等人[13]开发了1个可以从大量的日文文档中半自动抽取数值信息的系统,并能够根据抽取到的数值信息自动绘制多种图形.
本文与以上数值信息抽取方法不同点在于:(1) 为了让数值信息的含义更加明确,在数值信息类别上将数值信息分成绝对数值和相对数值两大类;(2) 为了提高可扩展性,提出了一种数值模板结合条件随机场的方法.
1 规则和统计相结合的方法
1.1 制定数值模板模块
制定数值模板模块是本任务的第1个模块,也是最重要的1个模块.该模块由两部分组成:获取知识;定义数值模板.获取知识是为了建立数值信息相关的各种知识库/表,为后续制定数值模板做准备.定义数值模板是为了制定各种抽取模式来抽取数值信息.
1.1.1获取知识 统计和记录都体现了数值的作用,例如“棉花产量534.3万吨”、“全国商品房的待售面积为69 522万m2”、“第一产业投资15 366亿元”.这些用来统计和记录的数值信息的主体分别为“棉花”、“商品房”、“第一产业”.我们发现数值信息的主体通常是行业、生活中的产品或者商品,所以用国家统计局网站上“国民经济行业分类”和“统计用产品分类”两种资源作为主体库.为了更好地制定数值模板,本文还获取了除主体库以外的其他知识.为了识别数值,从知网中获取到单位知识,形成单位库;为了识别地点信息,从知网中获取地点知识,形成地点库;为了识别相对数值信息中的趋势信息,添加了一些关于增长和减少的词,形成趋势词表;为了识别数值信息的确定度,添加了一些描述数值信息确定度的词,形成确定度词表.
(1) 国民经济行业分类. 国家统计局网站提供的国民经济行业分类(GB/4754—2011)共分成1 358个行业类别,作为主体库的一部分.
(2) 统计用产品分类. 国家统计局网站中提供的统计用产品分类目录一共包含16 138个统计用产品,作为主体库的一部分.
(3) 单位. 从知网和外部知识中获取483个单位.将数值单位的类型分成14大类:长度,质量,体积,温度,压力,功率,功能,热量,力,速度,光照度,角度,密度,其他.并建立相同类别中单位之间的联系(除了其他类).
(4) 地点. 从知网中一共获取了1 075个地点信息,其根节点为国家,叶子节点为城市.用从知网中获取的地点库来获取数值信息中的地点信息.
(5) 趋势词. 本文将相对数值信息中的趋势分为两类,分别为增长和减少,并添加了一些描述增长的词如:增加,增长,上升,回升,高出,多出,高于,增多,增高,上涨,倍增,暴涨,蹿升,递增,飞涨,激增,劲升,剧增,狂飙,狂升,猛增,猛涨,攀升,飙升;减少趋势的词如:下降,降低,回落,下跌,暴跌,减产,回跌,低于,减弱,递减,锐减,衰减,缩减,削减,缩短,收缩,减少.
(6) 确定度表. 本文将数值信息中的确定度分为两类,分别为确定和不确定,并添加了一些描述数值确定度的词如:大约,不超过,不低于,不小于,不高于,大概,约,不到,不满,不少于,不足.用来判断数值信息中数值的确定度.
1.1.2定义数值抽取模式组成模板库 数值信息抽取模板是由数值信息匹配特征词,并结合数值表达的特点而制定的,数值信息匹配的特征词和数值模板如表4所示.
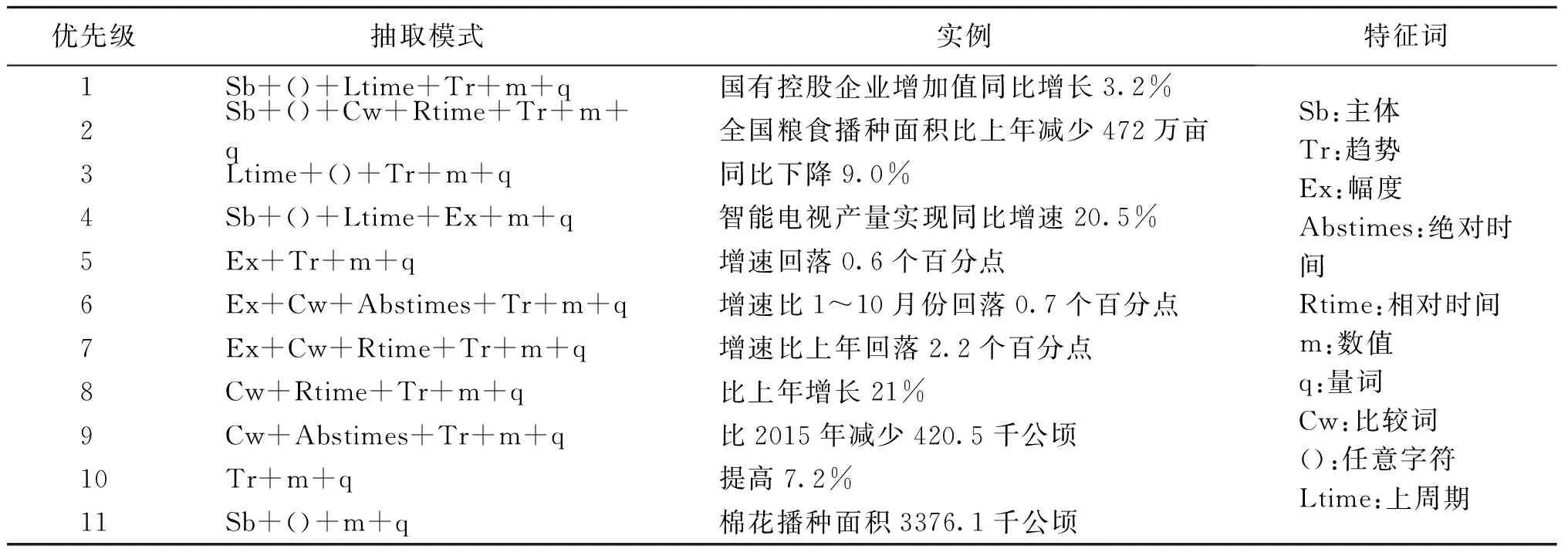
表4 数值信息抽取模板
1.2 时间和地点的抽取模块
定义5时间. 必须有年份信息,月份信息不是必要条件.
定义6地点. 最大的地点为国家,最小的地点为城市.
大多数数值信息都和时间、地点相关.例如:“房地产开发投资87 702亿元”、“棉花总产量534.3万吨”.如果这样的数值信息不给定时间和地点,那么就变得毫无意义.本模块输入文章的标题和篇章中的句子,输出时间和地点信息.
具体的抽取方法为:(1) 在当前句中检索时间地点.(2) 若当前句中不存在时间地点,则在标题中检索时间地点.例如文章的标题为“国家统计局关于2016年棉花产量的公告来源”,正文中当前句为“全国棉花总产量534.3万吨,比上年减产26.0万吨”.先在当前句中用正则表达式判断是否存在第1时间,如未发现,回退到标题中检索,匹配到第1时间为“2016年”,本文设定,第2时间必须在当前句中检索,不能回退到标题中检索.
1.3 模式匹配模块
按照表4中抽取模式的优先级顺序分别与输入文本进行匹配,不同的抽取模式下有不同的制定数值信息(元组)的规则.例如抽取模式“Cw+Rtime+Tr+m+q”,其规则为:(1) 补全“主体”、“属性”.(2) 把相对时间换成绝对时间.更具体来说,对于实例“比上年减产26.0万吨”,借上一个数值信息“全国2016年棉花总产量534.3万吨”中的主体和属性来进行补全.也就是用“棉花”和“总产量”补全;之后结合时间和地点模块,获得第1时间为“2016年”,其中第2时间“上年”为“2015年”,把相对时间“上年”换成绝对时间“2015年”.最终得到相对数值信息为:棉花,总产量,26.0万,吨,2016年,2015年,全国,增长,确定.
1.4 条件随机场补全模块
条件随机场(conditional random fields,CRFs)是有监督的机器学习模型,很多人将其看成一种判别式概率模型,其主要是根据观测序列预测目标序列,条件随机场结合了产生式模型的性质,它不但规避了隐马尔科夫模型的强独立性假设,而且能够有效地避免最大熵模型中的标记偏置问题,在序列标注方面有很好的效果,在图像领域和自然语言处理中都有很多的应用.
利用本文制定模板的方法抽取到部分数值信息.然而,很多数值信息在模式匹配模块中没有匹配成功.例如对于数值信息“全国农民工总量27 747万人”,由于主体库(“国民经济行业”和“统计用产品分类”)中并没有“农民工”,因此在模式匹配模块中没有匹配成功.针对使用模板的方法进行数值信息抽取失败的情况,采用条件随机场的方法进行主体识别,再利用制定好的模板进行模式匹配.对于本文的例子“全国农民工总量27 747万人”,利用条件随机场将主体“农民工”识别出来,之后重新模式匹配,便能成功匹配“Sb+()+m+q”模式,继而产生绝对数值信息元组为:农民工,总量,27 747万,人,全国,2016年,确定.
2 实验结果与分析
2.1 实验数据
本文的实验数据来自国家统计局网站最新发布栏目,该实验数据具有包含数值信息多、表达方式多样性等特点,选取2015年8月9日—2016年12月20日的文本数据作为语料.训练数据集包含67篇语料,测试数据集是从6篇语料中提取带有数值的句子,共计158条有效数值信息.
2.2 评价标准
当抽取得到的元组中所有成员都正确,我们视为此次抽取的数值信息是正确的.即:绝对数值元组中的7个成员都正确,相对数值元组中的9个成员都正确.本文采用正确率(P)、召回率(R)和F值来评价数值信息抽取的效果.
2.3 实验结果
对于相对数值,本文只处理了时间上的相对.实验结果如表5所示.

表5 实验结果
表5中的“只使用CRF”的方法是指利用序列标注的方法,采用33种标签分别对时间、地点、数值、主体属性进行识别和抽取.从表5中可以看出该方法效果并不理想.“只使用模板”的方法是利用数值信息在文本中的表达方式和一些知识来制定数值模板,并对语料进行数值信息抽取.其效果比“只使用CRF”的方法有较大提升.由此可以得出以下结论:对于数值信息抽取任务,利用数值信息在语言中的表达模式相对固定的特点,并结合数值相关的知识,可以提高数值信息的抽取效果.“使用模板+CRF”的方法是在使用模板的基础上,对于模板不能解决的实例,采用CRF的序列标注的方法进行主体识别,然后重新利用模板抽取.该方法相对于“只使用模板”的方法,在F值上提升了3个百分点,一定程度上弥补了模板的不足.
经过分析,认为数值信息抽取失败的原因有以下几点.
(1) 一些数值信息的主体词没有收录在主体库中,同时这些词用条件随机场的方法无法识别,这种情况主要包括一些未登录词、省略词和缩写词.
(2) 形如“限定词+主体库中的词”的数值信息的主体,且该主体词没有收录在主体库中.对于例子“规模以上工业发电量同比增长7.0%”,因为主体库中只有“工业”,所以抽取到的数值信息元组中的主体是“工业”,而不是“规模以上工业”.该结果和原文表达的信息有所偏差.
(3) 数值模板抽取不准确.例如占消费品零售总额的比重为12.5%,按照“Sb+()+m+q”的匹配模式,主体、属性、数字、单位分别为“消费品”、“零售总额的比重为”、“12.5”、“%”.将原文的意思扭曲.
(4) 分词不准确的情况.
3 总结
为了抽取文本中数值信息来构建数值类型问答的候选答案库,本文提出一种“模板+CRF”相结合的方法来抽取数值信息,其中数值信息包括相对数值信息和绝对数值信息.该方法利用数值相关的知识来制定数值模板并对文本进行模式匹配,并结合时间和地点输出数值信息;对于未成功匹配的文本,使用条件随机场对未登录词进行主体识别,识别之后的结果再用模板重新匹配,并结合时间、地点输出数值信息.用国家统计局网站最新发布栏目中的语料进行实验,得到了不错的结果.
