基于变量分组的大规模多目标优化算法
2018-11-08霍丽娜
林 涛, 霍丽娜
(河北工业大学 计算机科学与软件学院 天津 300400)
0 引言
MOEA/D[1]、NSGA-III[2]、GHEA2、IBEA等这些多目标进化算法在解决多目标优化问题时,大多关注目标数量增多时的性能,没有考虑含有大规模变量的情况,将决策变量当作整体优化,因此比较适合低维决策变量的多目标优化问题.文献[3-4]提出了一些大规模变量的单目标优化方法,但与多目标问题之间相互冲突,解决大规模变量的多目标优化问题更为复杂.文献[5]与文献[6]类似,采用决策变量随机分解策略,将大规模变量随机分组,然后融合合作协同框架[7]与粒子群算法[8],进行优化,此算法易陷入局部最优,也没有提供一种降低分组变量之间依赖性的明确方法.在国外的文献中,2016年提出的MOEA/DVA[9]算法,根据变量的控制属性将变量分为3类:多样性相关变量;收敛性相关变量;混合变量(两者都相关的变量).从而将大规模变量的多目标优化问题分解为多个简单的子多目标优化问题.但该算法不能处理混合变量过多的问题,并且算法只研究了目标数为2或3时的算法性能,对高维目标优化问题并不适用.受MOEA/DVA算法启发,文献[10]提出了LMEA算法,经过奇异值分解.计算角度、误差平方和等,基于聚类分析,首先将变量分为收敛性变量和多样性变量,然后再应用不同的优化策略分别优化.经实验验证,LMEA算法处理大规模变量多目标优化问题时,性能优于NSGA-III等主流优化算法.但LMEA算法变量分组效果并不稳定且分解过程过于复杂.本文基于LMEA算法框架,首先提出了一种变量分解方法,不仅简化变量分解过程,并且提高变量分组准确率,然后在优化阶段采用levy变异策略产生子代,提高算法的全局寻优能力.
1 相关理论
1.1 变量相关性分析
相互独立的变量可以分开优化,各自的优化结果不会相互影响,相关变量因为它们之间的相关性,整体优化的结果可能与它们分开优化的结果不同,所以不能分开优化.设多目标优化问题minf(x)=(f1(x),f2(x),…,fn(x)),如果存在决策向量x,实数a1,a2,b1,b2和至少一个目标函数fk,1≤k≤n,使得fk(x)|xi=a2,xj=b1
1.2 levy变异策略
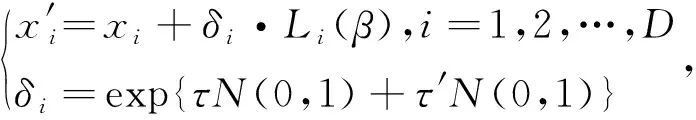
2 基于变量分组的多目标优化算法(GLEA)
2.1 基于随机采样与非支配排序的大规模变量分组策略
根据变量的控制属性,MOEA/DVA算法将大规模变量分为了3类:多样性变量;收敛性变量;混合变量.基于此,LMEA更细致地将变量分为收敛性变量和多样性变量.本文优化了LMEA算法的变量分解过程,通过对变量随机采样,根据对应目标空间的非支配排序结果,更简单精确地将变量分为收敛性变量和多样性变量.
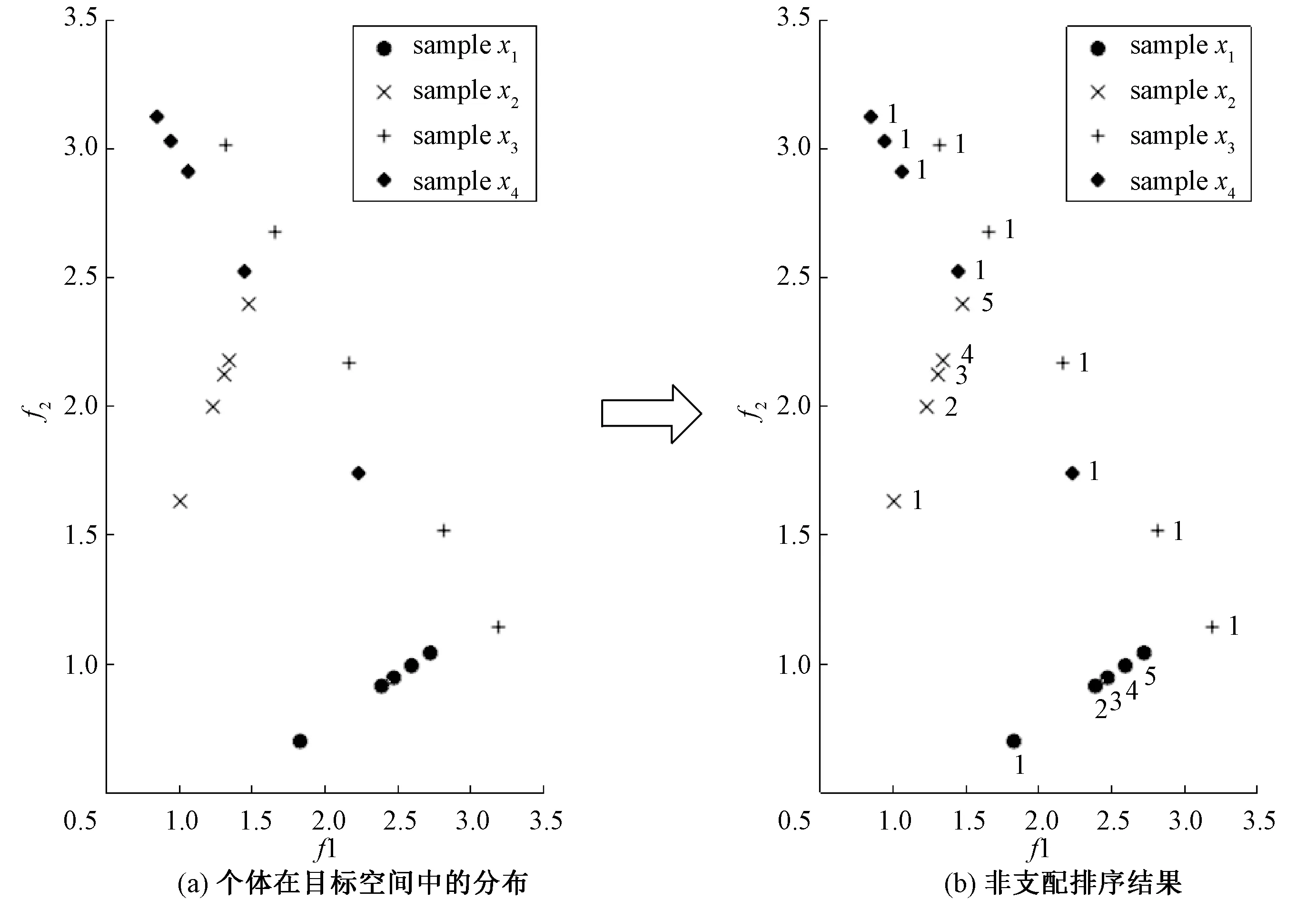
图1 变量分组过程Fig.1 The process of variable grouping
设个体为x=(x1,…,xD),决策变量分组算法流程如下.
Step1: 输入当前种群Pop,随机采样的次数nSample,初始化收敛性变量集合CV=∅,多样性变量集合DV=∅,i=1;
Step2: 当i≤D时,执行以下步骤,否则算法结束,输出变量分组后的结果CV和DV集合;
Step3: 从Pop中随机选择一个个体p1;
Step4: 对p1中的变量xi随机采样nSample次,形成一个种群SP;
Step5: 对种群SP进行非支配排序,排序后的非支配序集合为{1,2,…,maxRankNo};
Step6: 如果maxRankNo>nSample/2,那么判定决策变量xi是收敛性变量CV∪{xi},否则为多样性变量DV∪{xi};
Step7:i++,转到Step2.
其中,本文都采用T-ENS[10]进行非支配排序.
2.2 基于levy变异的优化算法
将大规模变量分组后,对于收敛性变量和多样性变量两类变量,分别采用不同的优化策略.多样性变量集合中的变量同时优化,收敛性变量集合中的变量经过相关性分析后划分为多个子组,每个子组中的变量同时优化.
在多样性变量的优化策略中,对当前种群P通过levy变异操作得到第1代子种群,从第2代开始,将父代种群与子代种群合并,进行非支配排序分级,若前k个非支配层中的个体数量和大于P种群大小,那么前k-1非支配排序分级层中的个体直接作为下1代种群的一部分,另一部分从第k非支配层中选取,选取过程基于角度,首先计算第k非支配层中和已选中的个体在目标空间中的两两角度,记录每个第k非支配层中的个体与其他个体所成角度的最小角度,相继选择其中值最大的个体进入下1代种群.直到新的父代种群大小与原种群P大小相同.多样性变量的优化过程如下.
Step1: 输入当前种群P,多样性变量集合DV,初始化下1代种群Q为空;
Step2: 从种群P中随机选择|P|个个体{P1,…,Pm,…,P|p|},对每个个体Pm(m=1,2,…,|P|)中的与多样性相关的变量值(即DV集合中指示的决策变量),都通过levy分布产生一个新值,如此便得到|P|个新的个体,组成种群O;
Step3: 将种群O与种群P合并,并进行非支配排序,得到f个非支配层,Fi表示第i个非支配层;
Step4: 从非支配层的第1层开始累加,若第1层中的个体数量超过了P种群的个体数量,即|Fi|>|P|,那么首先选出F1中的极值放入Q,Fk=F1Q; 若加到第k(k>1)层时,个体数量便超过了P种群数量,即 |F1|+…+|Fk|>|P|,|F1|+…+|Fk-1|≤|P|,那么将前k-1层的个体都放入种群Q;
Step5: 在目标空间中计算Q∪Fk中的任何两个解的角度;
Step6: 如果|Q| < |P|,执行Step7,否则输出新种群Q,优化结束;
Step7: 记录Fk中每个个体与Q中个体所成角度的最小角,并将Fk中的个体按照角度从大到小排序,从中选择最大角度的个体放入Q中,转到Step6.
优化收敛性变量,以相关性分析后生成的收敛性变量子组为单位,应用二元联赛法从当前种群中循环选择较优个体,以非支配序和目标空间个体到原点的距离分别作为第1和第2选择依据.通过levy变异策略产生子代,后代种群与父代种群合并,以距离和非支配序作为选择依据,从中选取较优个体生成下1代种群.收敛性变量的优化过程如下.
Step1: 输入当前种群P、收敛性变量集合CV,经过相关性分析过程后生成的子组集合subCVs={group1,group2,…,groupn},n表示子组的个数;
Step2: 对种群P进行非支配排序;
Step3: 在目标空间中计算种群P中每个个体到原点的距离;
Step4: i=1;
Step5: 判断i是否小于n,如果i Step7: 将两个种群O与P合并,进行非支配排序; Step8: 计算两个种群中所有个体到原点的距离; Step9: 根据非支配排序等级和距离,用O中的解代替P中的解; Step10: i++,转到Step5. GLEA算法主要分为4步:首先随机初始化规模为N的初始种群;然后将变量分组;再对收敛性变量集合进行相关性分析;最后分别优化多样性变量和收敛性变量,总流程如下. Step1: 输入种群规模N,随机采样次数nSample,相关性分析时选取的解的次数nCor,初始化种群P(N); Step2: 执行变量分组过程,[DV,CV] ←VariableGroup(P,nSample); Step3: 对Step2中输出的收敛性变量集合进行相关性分析,subCVs←InteractionAnalysis(P,CV,nCor); Step4: 当不满足结束条件时,执行Step5,否则输出最终种群P; Step5: 执行多样性变量的优化过程,P←DiversityOptimization(P,DV)和收敛性变量的优化过程,P←ConvergenceOptimization(P,subCVs). 模拟二项式交叉、多项式变异的分布指数设为20,交叉与变异概率分别设为Pc=1.0,Pm=1/D,D表示变量维度;在目标数为5时,种群规模设为126,NSGA-III算法中帕累托前沿的边界层和内层参考点的数量分别设为5和0;目标数为10时,种群规模设为275,NSGA-III算法中帕累托前沿的边界层和内层参考点的数量分别设为3和2;算法的终止为,100维决策变量时,最大评价次数设为1.0e+6;500维决策变量时,最大评价次数设为6.8e+6;1 000维决策变量时,最大评价次数设为1.7e+7;在KnEA算法中控制Kneepoints比率的参数T,5个目标时,DTLZ1、DTLZ3设置为0.3,10个目标时设置为0.1.5个目标时,DTLZ5、DTLZ6设置为0.4,10个目标时设置为0.3.DTLZ2、DTLZ4、DTLZ7在5个、10个目标时都设置为0.5.MOEA/DVA算法相关性分析的数量和控制属性分析的数量分别设置为NIA=6、NCA=50.LMEA算法在变量分组过程选择的解的数量nSel=2,随机采样的次数nPer=4;相关性分析过程选择解的数量nCor=6. 如表1所示,表中加粗的数据是每个测试实例最好的结果.总体来看,LMEA与GLEA算法相对于NSGA-III与KnEA、MOEA/DVA算法在大规模多目标问题上性能良好,并且IGD结果相近,LMEA与GLEA随着变量维度增大,性能表现一致,具有良好的伸缩性.GLEA在DTLZ1到DTLZ6测试函数为10个目标时,在几个算法中都是较优的;在DTLZ4、DTLZ5、DTLZ6测试函数上,GLEA不论5个目标还是10个目标时,表现较优;对于DTLZ7测试函数,10个目标时LMEA与GLEA算法结果基本相等,GLEA算法稍逊于LMEA.从IGD测试指标可以看出,对比其他几个多目标算法,GLEA在解决大规模多目标问题时是有效的. 本文提出的GLEA算法,在变量分解过程中,根据变量的控制属性,通过扰动变量和非支配排序,将大规模决策变量简单精确地分为两类,在进化过程中,采用levy变异策略产生子代,提高算法的全局寻优能力.在标准测试函数DTLZ系列进行仿真实验,用IGD指标进行性能评价,实验结果表明:GLEA比NSGA-III、KnEA、MOEA/DVA性能提升显著.当目标数分别增加到5个、10个超多目标,决策变量分别增加到100维、500维、1 000维大规模的决策变量时,GLEA能够更好地保持解的多样性与收敛性.对比LMEA算法,GLEA整体稍好于LMEA.GLEA能够较好地解决大规模决策变量的多目标优化问题. 表1 IGD值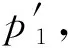
2.3 算法总体框架
3 实验
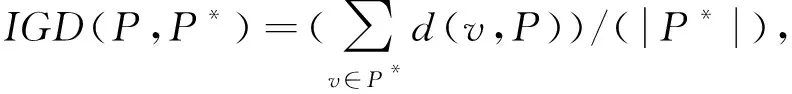
3.1 参数设置
3.2 实验结果
4 总结