基于多辅助分支深度网络的行人再识别*
2018-11-07夏开国
夏开国,田 畅
(陆军工程大学 通信工程学院,江苏 南京 210007)
0 引 言
行人再识别先对行人进行检测识别,再去场景中寻找,故而将针对特定行人的监控视频检索问题称为行人再识别。该技术主要用于安防领域,可以用机器代替人眼找到感兴趣的目标,甚至多摄像机联合,将目标运动路径大致描绘出来。行人再识别的基本过程是先对目标图片进行预处理,然后提取图片特征,利用度量学习方法和场景图库中的样本进行测度匹配,找出场景中感兴趣的目标。
行人再识别的发展大致经历了由传统手工设计特征提取到目前利用深度神经网络提取特征。传统的再识别技术主要依靠手工设计的特征描述子去进行目标的特征描述,如颜色、纹理、姿态等。同一个目标在不同的摄像机下,由于拍摄角度、光照、姿态、背景噪声、遮挡等,都在影响人体的外观,而颜色和纹理特征相对来说对环境的变化更加鲁棒,也更容易提取,所以被广泛研究和使用。近年来,随着深度学习技术的研究和深入,卷积神经网络发展迅速,在图像分类、目标检测等领域取得了巨大成功。卷积神经网络与传统神经网络相比,通过卷积核的卷积学习,能很好地得到图片的颜色、纹理信息。从 AlexNet、VGGNet、GoogleNet再到 ResNet、DenseNet,不仅在网络深度上不断加深,识别的精度也在不断提高。网络性能上的提升给行人再识别的研究提供了巨大动力。利用深度卷积神经网络提取目标图片特征,鲁棒性更强,深层特征语义性更强,更加适合测度匹配。当前,一般的做法是利用卷积神经网络进行特征提取,再辅以不同的度量学习工具,经过深度卷积后,高度抽象的特征保留了大量的语义信息,同时损失了很多信息。本文从网络本身入手,挖掘并利用网络中间层的特征,结合三元组损失函数,进一步提升行人再识别精度。
1 深层卷积神经网络
1.1 卷积神经网络介绍
卷积神经网络(CNN)[1]由多层感知机发展而来,通过稀疏连接、权值共享以及池化特点来改进,从而学习出更有表现力的特征。图1是由LeCun提出的LeNet[2],是一个典型的卷积网络,由卷积层、池化层和全连接层组成。其中,卷积层和池化层配合组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。卷积层通过卷积核的水平滑动过滤图像的各个小区域,形成局部感受野。池化层主要用来降低数据维度。
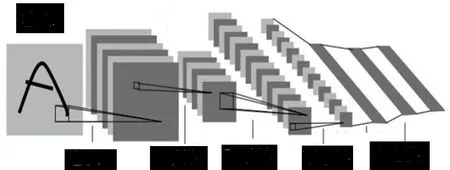
图1 卷积神经网络
1.2 深层卷积神经网络
从2012年在ImageNet竞赛上取得巨大突破的的AlexNet开始,网络的层数逐年加深。如表1所示,一直到2015年的Resnet[3],由原来的22层飞跃到152层,性能也有了巨大突破。
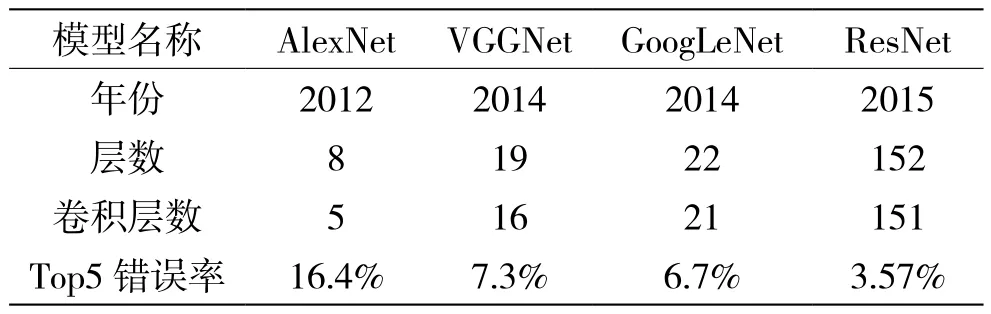
表1 主流卷积网络模型参数对比
随着卷积神经网络的加深,网络对数据模型的学习拟合能力不断提升,但提升到一定深度时,性能在训练集上会出现下降现象,因为梯度弥散造成训练中反向传播时将无法有效将梯度更新到前面的网络层,导致网络损失函数无法收敛。
ResNet采用残差块的方式解决了这一问题。如图2所示,利用旁路直线将输入直接连接到网络后面的层,让后面的层直接学习残差。这样原本优化目标H(x)=F(x)+x(x为该结构输入)通过该残差块把优化的目标由H(x)转化为H(x)-x,从而解决了网络太深难以训练的问题。当然,网络越深,训练参数越多,训练时间也会越长。本文考虑到网络性能、参数量的大小以及训练难易程度,选用ResNet50作为基本网络骨架。它的基本结构如表2所示,其中con2_x、conv3_x、conv4_x、conv5_x分别由对应模块数量3、4、6、3组成。
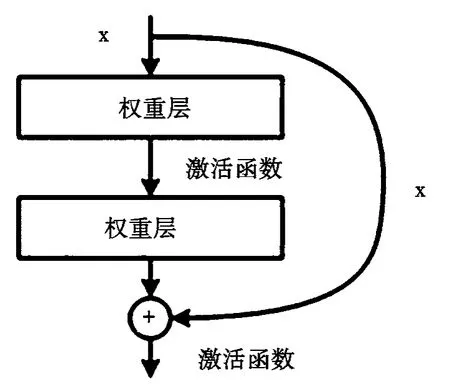
图2 ResNet残差块结构
2 网络结构
通过卷积神经网络的可视化[4]可以发现,随着卷积层数的不断加深,每一层的卷积输出都更向着高语义化的方向发展。在最初的几层卷积,网络学习的是底层的图片特征,类似于传统手工设计特征中的颜色、纹理等。越往深层,图片中的目标轮廓越明显,包含的语义信息越多。深层的卷积后,特征维度越来越小,势必在卷积和池化中丢失很多信息。所以,本文考虑利用网络中间层的输出特征,采用维度较高的特征弥补一部分的信息丢失来达到提高识别精度的效果。图3是本文提出的网络模型,基于ResNet-50网络进行分支扩展。图3中conv1~conv5_x是ResNet-50的主体结构,添加的4个辅助分支的输入分别连接到conv4_x的第5模块、conv4_x的第6模块、conv5_x的第1模块和conv5_x的第2模块组的输出。随后,利用conv5_x最后一层的输出得到的图片特征向量,用于难样本学习挖掘。最后,计算三元组损失。图4为辅助分支结构,输入通过两层卷积层后,经过全局池化层,计算分类损失。

表2 ResNet50结构
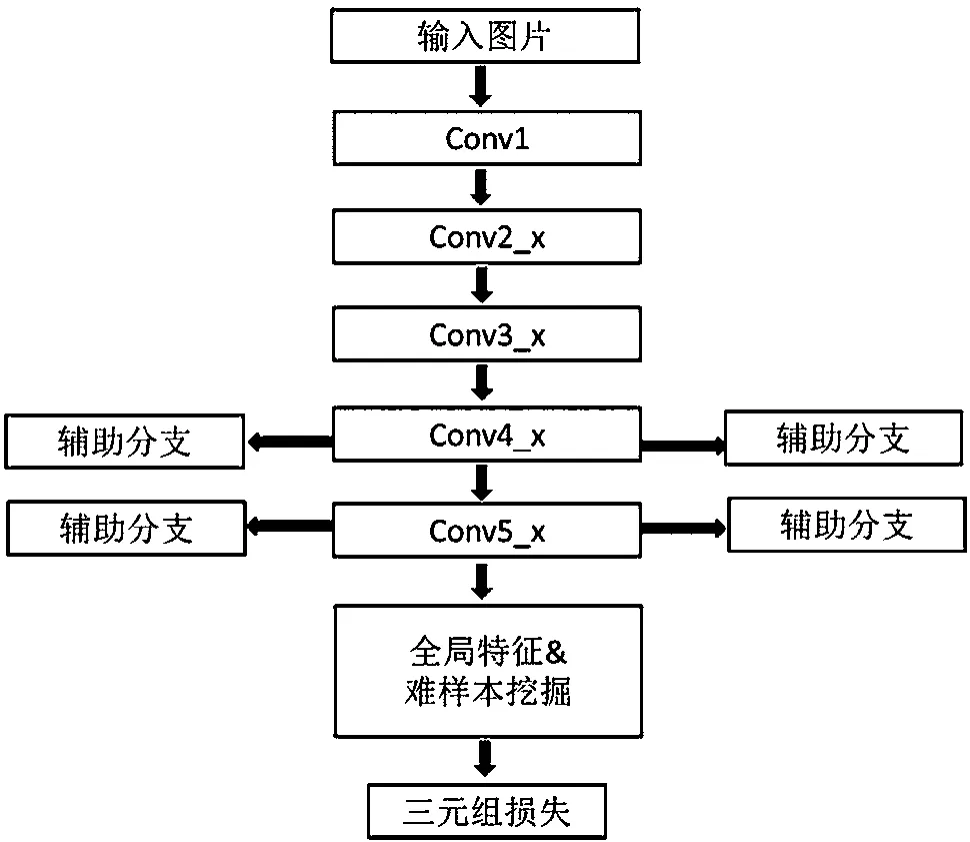
图3 带辅助分支的网络结构
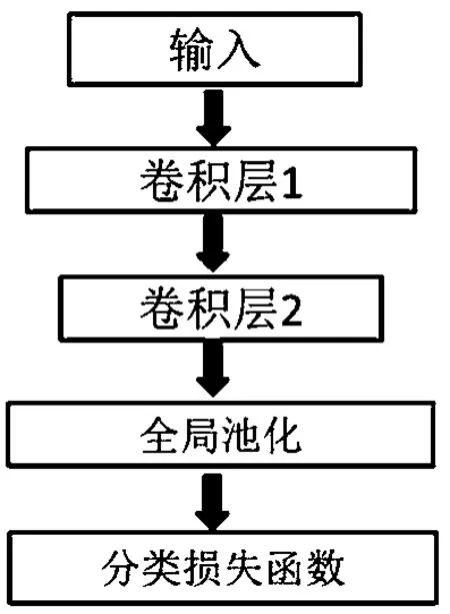
图4 辅助分支结构
3 三元组损失函数
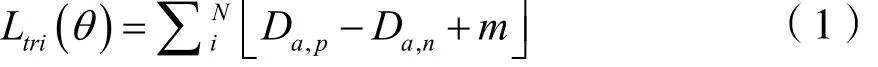
式中a代表锚样本(anchor),p代表正样本(positive point),n代表负样本(negative point),m为间隙(margin),D为计算的欧氏距离。三元组损失函数的核心就是锚样本、正样本、负样本共享模型,通过优化该损失函数,将锚样本与正样本聚类,远离负样本,实现样本的相似性计算。然而,随着数据集的增大,三元组的数量也在迅速增长,其中很大一部分是无用的元组,如负样本和锚样本本身就差距很大。此时,挖掘出困难的三元组显得十分必要。为了解决正负样本数量差距过大,会从大量负样本中随机抽取一定数量的负样本,与锚样本和正样本组成三元组,而困难样本挖掘则充分利用全部数据集筛选出符合要求的样本元组。如此训练的模型对于图片特征变化更加敏感,匹配精度也会更高。
三元组损失函数[5]是深度学习中的一种损失函数,用于训练差异性较小的样本,由FaceNet[6]根据LMNN(Large Margin Nearest Neighbor)分类算法改进而来。它的损失函数可表示为:
4 实验
4.1 行人再识别数据集
本文选取行人再识别中两个常用的数据集进行模型的性能测试。第一种,Market-1501数据集,包括6个摄像头拍摄到的1 501个行人,32 668个检测行人框。训练集有751人,包含12 936张图片,平均每个人有17.2张训练数据;测试集有750人,包含19 732张图像,平均每人有26.3张测试数据。第二种,DukeMTCT数据集采集来自8个不同摄像头的高分辨率视频,通过每120帧采样得到36 411张图像,随机采样702个人作为训练集,包含16 522张图像,另采样702个人作为测试集,包含16 522张图像。
4.2 实验评价指标
行人再识别的评价指标一般使用累计匹配曲线(CMC曲线),即累加首次正确匹配的百分比作为反映分类器的性能指标。其中,rank1表示在验证集上首次正确匹配的百分比,也以此作为直观反映模型再识别性能的重要指标。另一项指标为平均精度均值(mAP),即所有类在系统下准确率和召回率曲线同坐标轴所围面积平均值,以此来衡量算法的精确度。
4.3 实验设置
本实验网络采用Resnet50在ImageNet上的预训练权重作为初始权重,每张输入网络的图片的尺寸调整大小为256×128,三元组损失函数的间隙m的值设为0.3。每个训练批次128张图片(32类,每类4张)使用Adam优化器,初始学习率10-3,一共训练300个epoch,在第120和第240个epoch时将学习率分别减小到10-4和10-5。
4.4 实验结果与分析
表3给出了方法在Market-1501图库上的性能表现和当前一些优秀方法的比较。在该图库上,本文方法获得了89.82%的rank1的值,mAP达到72.56%。表4给出了本文方法在Duke图库上的测试结果,rank1的值达到了84.23%,也取得了较好的精度,基本达到了预期目的。
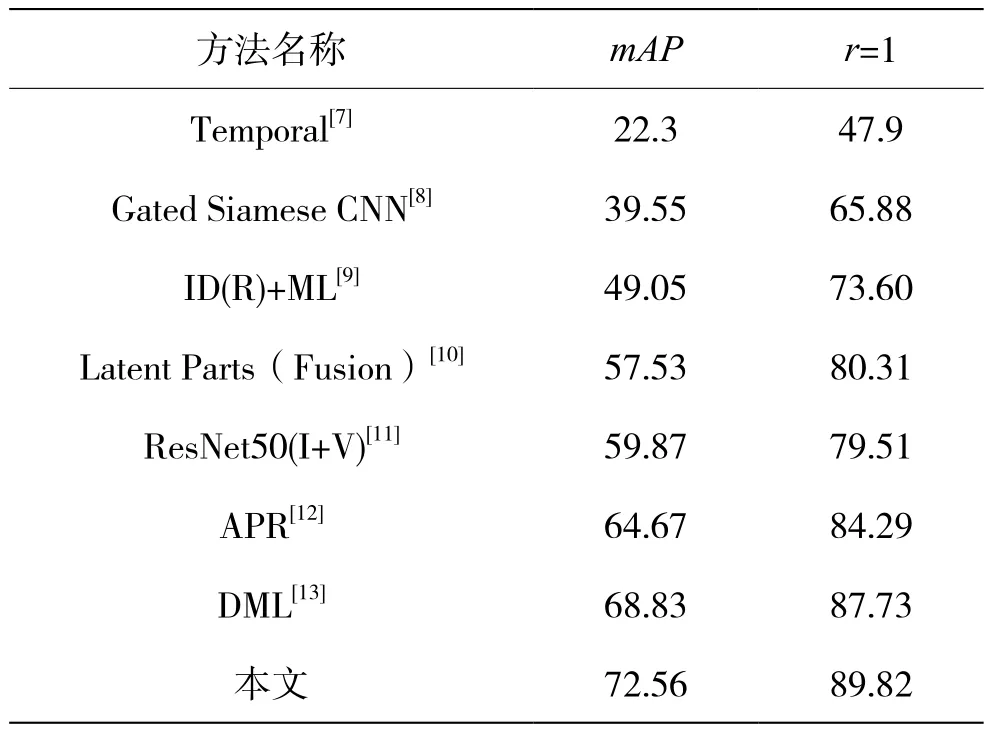
表3 Market-1501数据集上性能对比
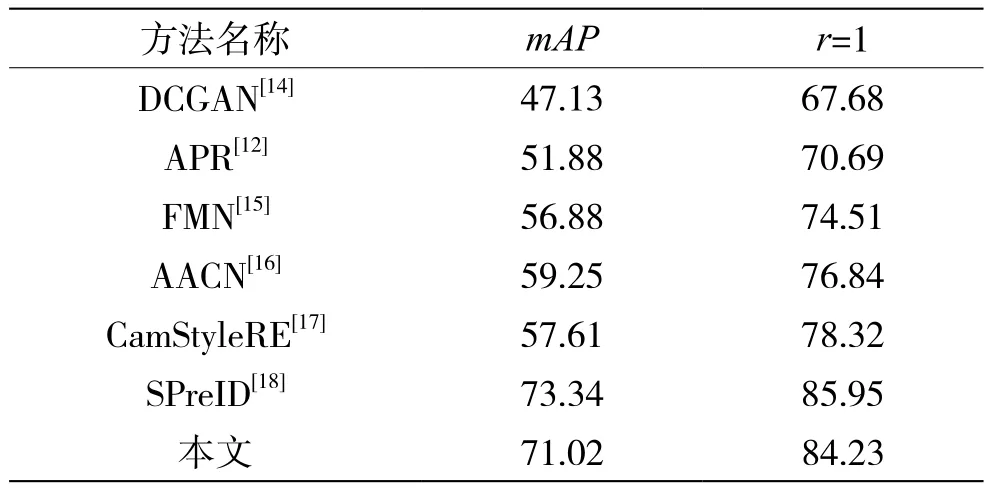
表4 Duke数据集上性能对比
5 结 语
针对深度卷积神经网络高层特征信息丢失多、中间层特征信息利用不充分的问题,提出了一种基于添加中间辅助分支的网络结构,用来充分利用中间层特征信息。此外,本文改变了以往单纯利用分类损失训练网络的方法,利用三元组损失函数和挖掘难样本去训练网络,取得了良好效果。
