如何利用REDCap实现临床试验的随机化操作
2018-11-07贺海蓉田国祥任晓东冀彬曾宪涛吕军
贺海蓉,田国祥,任晓东,冀彬,曾宪涛,吕军
随机分组是进行随机对照试验(RCT)的重要环节,是指每个受试对象被分配到各组的机会相等。其作用主要体现在能够避免主观因素对实验结果造成的影响;平衡实验组和对照组已知和未知的混杂因素,从而提高两组的可比性,避免造成偏倚,使研究结论更加可靠[1]。随机分组的原则是医生和患者不能事先知道或决定患者将分配到哪一组接受治疗;医生和患者都不能从一个患者已经进入的组别推测出下一个患者将分配到哪一组。即做到随机隐匿[2]。随机隐匿就要求产生随机分配序列和确定受试对象合格性的研究人员不是一个人;产生和保存随机分配序列的人员最好不是参与试验的人员[3]。
常用的随机分组的方法有简单随机法、区组随机法和分层随机法。简单随机化是真正的随机化,样本量很大时可保证比较组间除处理因素外其他非处理因素的均衡,但是当样本量较小时,会出现组间总例数和组间影响预后因素分布的不均衡。区组随机化是指将所有受试者按进入试验的时间顺序划为N个区组,在每个区组内进行完全随机化。区组长度一般是组数的偶数倍。分层随机化是将总体按某种特征划分为N个层,在每层内进行完全随机分组[4]。多中心临床试验通常将中心作为分层因素。随机化常借助计算机产生,利用EXCEL或SPSS产生随机化的操作简单,应用较多。
REDCap中置入了随机化模块,可以实现三种常用的随机分组的方法。其独有的权限分配功能有助于分配隐匿的实施。本研究主要介绍REDCap联合EXCEL实现随机化的操作方法。
1 项目和材料简介
1.1 建立项目一般随机对照试验需要进行随机化操作,所以在建立项目时,项目类型应选择“Clinical research study or trial”。建立项目的具体方法和注意事项参考本研究团队已发表的REDCap系列文献“如何利用REDCap数据采集系统实现病例报告表的设计”[5]。建立好的项目见图1。
1.2 建立CRF表随机对照研究CRF表的数据采集工具中应该有随机化的信息。如进行某药物与安慰剂的疗效比较时,随机化信息应包括药物名称和剂量(图2)。其他的建立方法与一般研究的方法相同,可参考本研究团队已发表的REDCap系列文献“如何利用REDCap数据采集系统实现病例报告表的设计”[5]。
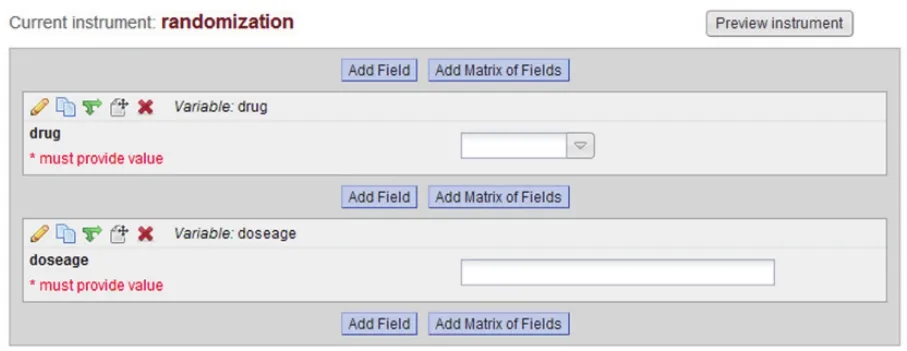
图2 CRF表中的随机化信息
1.3 创建数据访问组在多中心临床研究中,往往需要在每个中心实现随机,这时需建立好数据访问组。建立方法参考本研究团队已发表的REDCap系列文献“REDCap实现多中心研究数据管理的方法”[6]。本文假定贺海蓉为牵头单位数据统计人员、刘哲为牵头单位(First Affiliated Hospital)的数据录入人员、高凡、吕军为别分中心医院(Second Affiliated Hospital 、Third Affiliated Hospital)的数据录入人员,建立好的数据访问组如图3所示。
2 REDCap实现随机化的流程
REDCap中的随机化功能允许用户创建个性化分配列表,该列表将来可查找随机分组的信息。随机化设置分为3个步骤,在步骤1中,用户将设置随机化模块及其所有参数,步骤2将提供示例,说明如何设置随机分配表,步骤3为上传随机分配表。需要注意的是,随机化模块不会自动创建随机分配表,随机分配表必须应用其他软件(例如SAS,Stata,R,Excel)产生,且一般由项目组的统计师产生。上传的随机分配表可用作查询患者随机入组的信息。应用Excel进行随机化的操作方法较简单,本文以此为例。
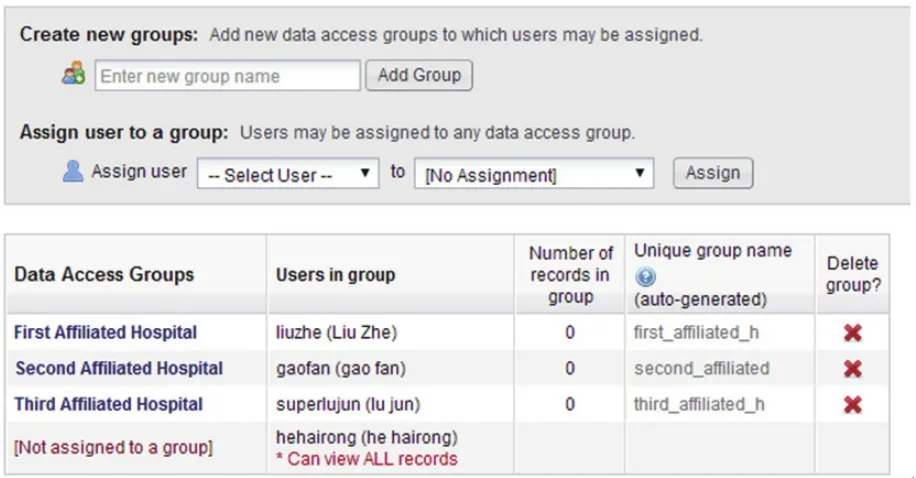
图3 数据访问组的创建页面
2.1 进入随机化模块随机化模块将帮助用户在项目中实施已定义好的随机化模型,使用户可以对项目中的受试者实施随机化分配。具体操作方法:点击项目主页“Enable optional modules and customizations”下“Randomization module”前的“Enable”,允许该项目使用随机化模块。随后点击“Set up a randomization model”下的“Set up randomization”前往生成随机序列的页面。
2.2 设置随机化模块这一步将允许用户定义将要实施的随机化模型及其所有参数,其中包括定义分层(如果实行分层随机)以及每个中心(多中心研究使用)。例如,本研究根据每个中心进行分层实现随机分组,将患者分配不同的药物,则具体操作为“B)Randomize by group/site”下选择第一个“Use Data Access Groups to designate each group/site”。“C)Choose your randomization field”下拉框选择“drug”。注意,分中心信息应在“Data Access Group”中设置好;干预方式应是CRF表中的分类变量。如果根据其他因素分层,如年龄,则分层因素也应是CRF表的分类变量。最后点击“Save randomization model”保存随机化模块。设置好的随机化模块如图4所示。
2.3 创建随机分配表随机化主页的“STEP 2:Download template allocation tables (as Excel/CSV files)”是要求用户创建随机分配表。该步骤下方列出了一些模板,用户可以下载这些文件以获得关于如何构建自己的随机表的一般知识。但建议用户不必使用这些模板,而是将其作为示例或基准来创建自己的随机分配表,本次我们下载“Example#1(basic)”作为模板。模板中给出了随机化模型中使用的字段的所有原始编码值,注意,不要修改模板中的说明信息。
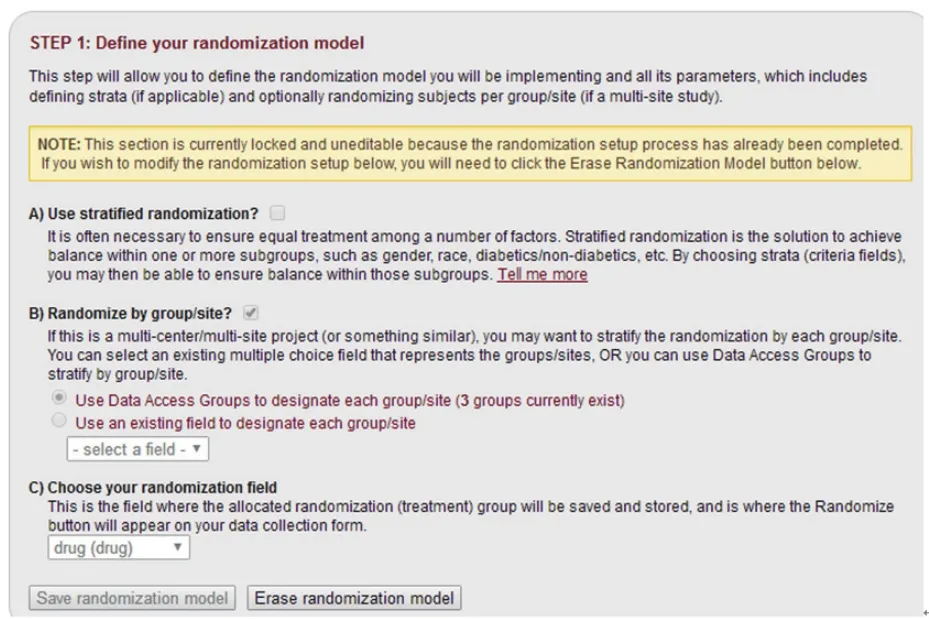
图4 随机化模块的设置界面
在多中心临床试验中,一般要计算样本量,且会根据每个中心的实际情况计划拟录入的受试者人数。在使用EXCEL进行随机分组时,考虑到受试者失访和退出的情况,应建立足够的随机数字(一般要比每个中心的计划样本量多25%以上)。在本例中,计划从每个分中心收集8个受试者,从主中心收集10个受试者,则在建立EXCEL随机分配表时,计划每个分中心产生12个随机数字,主中心产生16个随机数字,共40个随机数字。
利用EXCEL建立随机分配表的操作方法是:建立四列,第一列为“Record ID”,输入1-40,第二列为“Group”(中心),输入12行1(第一个分中心),12行2(第二个分中心),16行3(主中心),第三列为“random number”,通过“RAND()”公式产生随机数字,将第三列产生的随机数字粘贴到第四列(只复制数字)并命名为“random number2”。然后,先用第二列排序,再用第四列随机数字排序。随后建立第五列“random drug”,即随机分组。由于本例是根据中心分层,且为1:1随机,所以,在第五列中,以A、B代表不同的干预方式,每个中心1:1输入A,B(即每个分中心分别输入6个A,6个B;主中心输入8个A,8个B),最后根据第一列“record”排序即可完成随机分组,生成的随机分组信息(图5)。
利用外部的软件生成随机分组信息后,需要将随机分组的信息粘贴到下载好的模板中。在本例中,随机分组的信息包括两列(Example#1(basic)中可见),即“drug”和“redcap_data_access_group”。因此,我们将图4中的“random drug”和“group”列的信息分别粘贴到模板1中的“drug”列和 “redcap_data_access_group”列,注意不要修改模板中的列名,也不要随意增删列。随后将A、B分别替换为1、2(REDCap中对药物的赋值),将“redcap_data_access_group”中的1、2、3分别替换为9、12、13(模板中对相应分中心的赋值)。基于模板建立的随机分组的信息见图6。
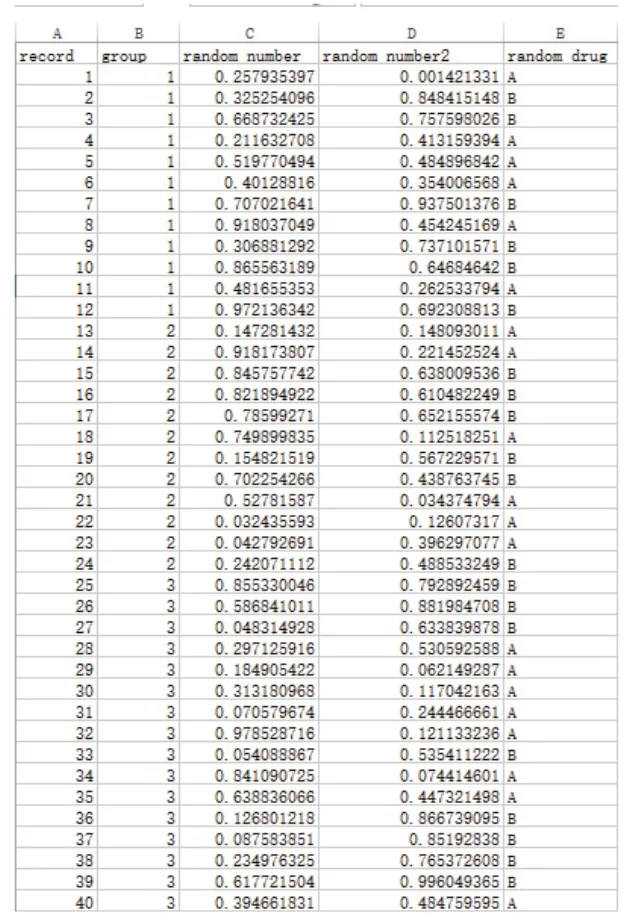
图5 利用EXCEL生成的随机分配信息
2.4 上传随机分配表根据模板中规定的格式制定好随机分配表后,即可上传CSV格式的随机分配表,即“STEP 3: Upload your allocation table(CSV file)”。上传前应注意该项目所处的状态,在对应的状态下上传文件,需要注意的是,在DEVELOPMENT状态下的项目,上传随机分配表后依然可以修改,一旦项目处于PRODUCTION状态,上传的分配表将被锁定且不可修改。
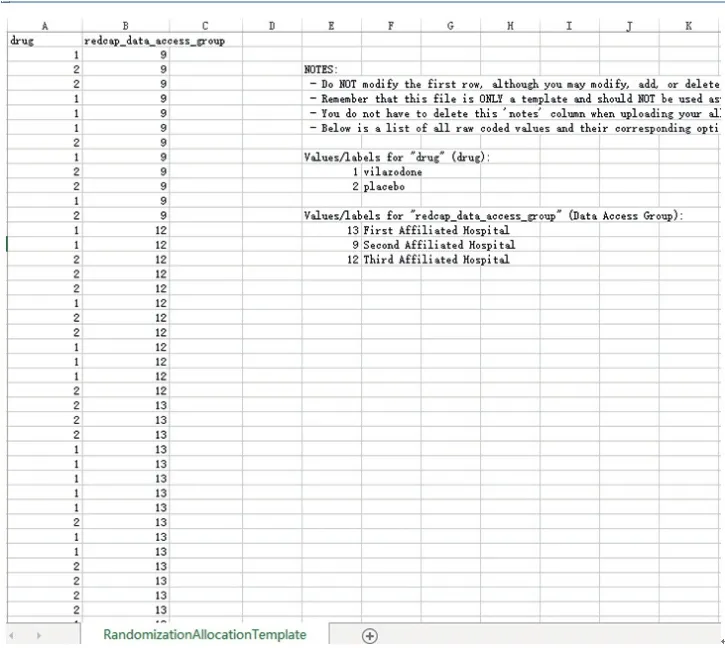
图6 根据模板设置好的随机分配信息
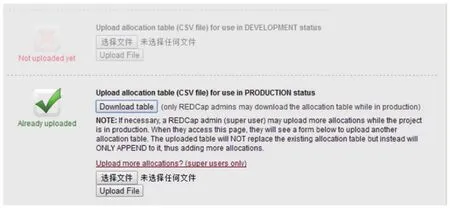
图7 随机分配表的上传界面
处于PRODUCTION状态的项目在执行过程中,如果遇到特殊情况,需要增加受试者时,REDCap管理员(超级用户)可在项目执行过程中上传更多的随机分配信息。具体操作是根据2.3描述的方法建立另外一个随机分配表,然后点击“Upload more allocations? (super users only)”,选择建立的第二个随机分配表,上传(图6)。此时,二次上传的随机分配信息不会替换原有的分配表格,而只会在第一个表格的基础上添加随机信息,从而增加更多的分配。用户可通过图7中的“Download table”查看随机分配表,此时分配表中不再有任何说明信息。
2.5 随机化的实施当上传完随机分配表之后,相当于已经将随机分组的信息嵌套入该课题中。使用REDCap录入受试者时,分组信息应为一个单独的数据采集工具,本例中此数据采集工具命名为“Randomization”(图2),这样便可通过编辑用户权限实现对随机分组的管理,也可实现随机隐匿。权限分配的操作方法可参考本研究团队已发表的REDCap系列文献“多中心临床数据采集系统REDCap权限设置与管理”[7]。
本文假定贺海蓉为牵头单位数据统计人员,由于其不是该课题租的成员,不参与研究对象的纳入,因此可以由其创建随机分配表并执行随机化。具体操作:在REDCap的“User Right”界面,对贺海蓉的权限进行分配,赋予其“Randomization”的权限,并赋予其进入“Data Entry Rights”下“Randomization”数据采集工具的权限。贺海蓉的权限分配如图8所示。
由于本例是根据分中心进行分层随机,因此在实际REDCap应用中,每个分中心应设立单独的随机分组的人员,具体操作是赋予此人进入“Data Entry Rights”下“Randomization”数据采集工具的权限。由于分中心的REDCap用户只能查看本中心的受试者,因此每个分中心可以根据主中心生成的随机分配表在本单位执行随机化。
拥有进入数据采集工具“Randomization”(图2)权限的用户在进行随机分组时的操作是:进入受试者的数据录入界面,点击图9中的Randomize即可显示该受试者所在的分组。
3 讨论
随机化是随机对照试验的基本原则。随机对照试验报告的强化标准声明CONSORT要求对临床试验随机化详细描述随机方法[8]。而随机化实施需做到随即隐匿,有研究发现未隐藏分配方案或分配方案隐藏不完善的试验,常夸大治疗效果的30%~41%[9]。REDCap作为免费的非商业化的数据管理系统,在进行临床试验随机化方面也有自己的优势,通过将外部产生的随机分组信息置入到REDCap系统,帮助用户轻松实现随机分组,其权限分配功能又能帮助临床试验课题实现分配隐匿,操作方便,可控性强。

图8 实施随机化的人员的权限分配界面
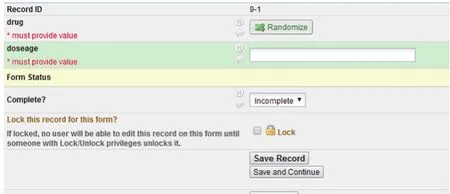
图9 实施随机化的人员执行随机分组操作的界面
本文主要介绍了使用REDCap实现随机化的具体操作。实际应用中需要注意以下几点:①随机化模块的设置可根据课题的实际情况进行,若只进行简单的随机分组,则随机化模块设置界面下的“A)Use stratified rendomization”和“B)Randomize by Group/site?”可均不选择,直接在“C)Choose your randomization field”下选择随机项目即可,其中A)和B)的选择项均是数据采集工具中的分类变量,应在CRF表中提前设置好。②外部随机分配表的生成不受软件的限制,用户可根据自身情况选择合适的软件生成,需要注意的是,REDCap系统只识别CSV格式的随机分配表;随机分配表中的分层变量、干预方式的赋值应与CRF表中的赋值一致;与随机化相关的变量在随机分配表中的列名应与模板文件中一致。最好的操作方法是按照本文中所举的例子进行实施,在外部建好随机分配表后,将模板文件中所需的随机分组信息粘贴入模板文件,随后根据模板文件中关于赋值的说明进行数值的替换。③基于模板文件建立的随机分配表应妥善保存,以便后续对随机分配信息的查证。④项目负责人应妥善分配项目组成员的权限,实施随机化和随机分组的权限只能分配给与课题无关的单个人员。⑤由于只有超级用户(一般是单位的REDCap管理员)有二次添加随机信息表的权限,我们建议课题成员创建随机分配表时应创建足够多的随机数字,避免二次添加。
