油田生产大数据分析应用研究
2018-11-01耿玉广耿英杰薛良玉张战敏顾龚杰
耿玉广 张 萌 耿英杰 薛良玉 张战敏 顾龚杰
1.中国石油华北油田公司工程技术研究院;2.中国石油华北油田公司储气库管理处;3.中国石油勘探开发研究院计划财务处;4.中国石油华北油田公司二连分公司
“十二五”以来,我国在“互联网+”“两化融合”“绿色矿山”行动计划指引下,相继建成一批具有石油行业特色的数字油气田[1],对基本生产单元和设施实现了高效管控,成为控投资、降成本、提效率、保安全的有力支撑[2-3]。在以物联网为基础的数字油田,遍布单井、管道、站库的传感器不断采集各种生产数据,汇集成大数据资源,挖掘和用好这一宝贵资源对于充分发挥数字油田的作用至关重要。油田生产主要业务包括油藏动态、采油采气、油田注水、地面集输、井下作业、项目施工、QHSE管理及经济效益分析等多方面,产生的数据类型复杂多样、时效性强、数据量大、价值密度高、保密性强。虽然目前大数据分析在金融、保险、交通、电商等行业开展得有声有色,但在石油上游生产领域的分析与应用尚处于起步探索阶段,鲜有成熟案例可供借鉴。怎样挖掘和用好油田生产大数据,使“数字油田”迈向“智能油田”,进一步发展成“智慧油田”[4],成为各油田争相解决的热点难点问题。
H油田正从传统的能源企业向数字化、信息化企业转型,在实践中逐步认识到大数据潜藏的“能量”和“效益”,把大数据分析看作是充分体现数字油田建设价值的关键所在,是提升油田管理水平的重要抓手,不失时机地在油田生产领域开展大数据分析应用研究。
1 油田生产大数据研究目的与技术思路
基于现有生产大数据,以油田生产单位最关心的产量、能耗、效率、效益、安全、环保等指标的提升为分析目标,在油藏、采油(气)、注水、集输、修井及生产管理等方面,深入开展大数据预处理、数据建模、可视化展示、因果分析、方案优化、现场实施等一系列研究,开发油田生产大数据分析平台及网络版软件,为油田生产高效管控和优化运行提供决策依据。
技术思路上,一是要强化前期技术调研,创新分析应用思维,探索适合油田企业大数据分析应用的基本方法和流程;二是要围绕具体分析目标,构建与油田生产参数优化、管理提升相适应的数据分析模型、挖掘方法与展示方式,指导生产优化运行;三是要强化信息技术人员与油田专业人员对接,建立以“拖、拉、拽”为操作特点的云计算大数据分析平台,满足不同岗位人员需要;四是要坚持“贴近生产,研用结合,以用促建”原则,在实践中不断修订完善数据分析模型,提高大数据分析预测结果的准确性和可靠性。
2 构建以应用为导向的油田生产大数据 分析流程
计算机界的“诺贝尔奖”——图灵奖1998年得主詹姆士·格雷(James Gray)认为,未来的数据密集型科研仅基于数学模型的海量数据即可对数据进行分析,将海量数据输入庞大的计算机集群,只要数据中存在相关关系,通过计算分析便可挖掘出过去关注因果的科学方法很难发掘出来的新模式、新知识甚至是新规律[5]。杰出的大数据预言家、畅销书《大数据时代》的作者维克托·迈尔-舍恩伯格、肯尼思·库克耶[6]认为,大数据时代“相关关系比因果关系更重要”。我国新疆油田段泽英等[7]提出,大数据处理的主要步骤仅限于数据处理阶段,且认为大数据挖掘功能有两类,即展现数据一般性的描述和用于推算处理的预测。大港油田刘志忠等[2]认为,大数据分析重在发现事物变化趋势,不追求精确性,不再探求事物的因果关系。
然而,这些理念导致大数据分析在油田企业较难落地和应用,原因有两点:一是大油田的数据量虽然足够大,但区块多、类型杂、差异大,具体到某一类型区块,数据量并不一定巨大,因而无法开展“大数据”分析;二是油田生产数据带有明确的物理意义,单纯考虑不同数据之间的关联而撇开其属性和确定的因果关系,其分析结果的实用价值将无法得到保证。
为此,针对油田生产大数据的特点,运用大数据理念,研究构建了以应用为导向的油田生产大数据分析流程(图1)。其中,数据准备是根据分析目标从数据库中调取和迁移所需全部数据,而非数据样本,并由专业人员结合实际对数据进行过滤清理,去除其中不合理、重复和无效部分。数据挖掘则结合数据类型、格式和具体问题,对挖掘方法进行综合比较,选出最佳方法,以便数据处理更为快捷,揭示数据内涵,得到潜在的规律性和认识。诊断剖析是专业人员根据数据分析结果结合生产实际,透过现象探究本质,从而找准优化方案的途径。优化方案则要突出针对性、个性化和预测效果。实施评价是强化方案的实施跟踪与效果评价,并将实施前后结果进行对比分析后再反馈到生产数据库中,作为知识库的一部分,不断扩充大数据分析的数据资源。
需要指出,油田生产大数据分析是一个不断优化、相互验证的过程。一方面,图1中每一步如果没有达到预期目标,都需要回到前面的步骤重新调整并继续进行,直到满足分析目标需要为止;另一方面,随着数据积累,特别是生产状态的变化,需要不断地进行大数据分析和优化生产运行参数,促使生产保持在最佳运行状态。
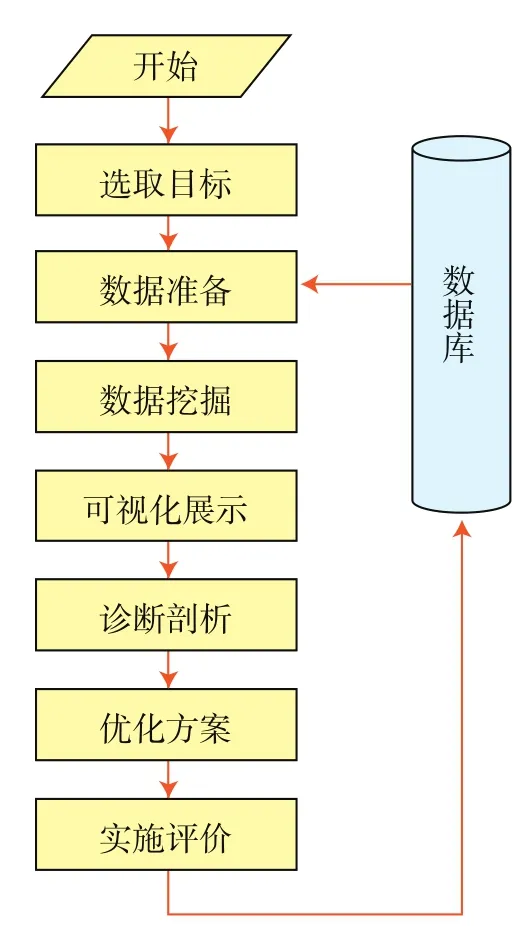
图1 油田生产大数据分析流程
3 建立油田生产主营业务大数据分析模型
建立数据分析模型是大数据分析应用的核心,本研究从油田生产主要专业[油藏、采油(气)、注水、集输、修井]到生产管理(预警报警、能耗管控、QHSE管理、ERP运行),灵活运用聚类统计、神经网络、决策树、时间序列等数据处理方法,构建了一系列大数据分析模型,并通过在实践中反复检验与修订,最终固化下来,为计算机编程做好准备。各专业数据分析模型包括油藏1个、采油(气)13个、注水4个、集输7个、修井3个、管理7个,合计35个(表1)。
例1:以降低抽油机井吨液举升百米耗电为目标的大数据分析[8]。选取影响抽油机井举升系统效率的影响因素(表2),收集和迁移H油田2014—2016年与抽油机井系统效率、吨液举升百米耗电影响因素相关的数据,结合中国石油天然气行业标准对不同类型油藏系统效率的指标划分[9],作聚类统计回归,发现系统效率与吨液举升百米耗电之间呈现幂函数关系(图2)。可以看出,左侧区域系统效率低而能耗高,是节能挖潜的重点区。对比3段曲线对应拟合直线的斜率发现,y1/y3=48.2,y2/y3=8.6。所以y1区井的潜力是y3区的48.2倍,y2区井的潜力是y3区的8.6倍。y3区井的系统效率高而能耗低,属于合理区,应当保持下去。
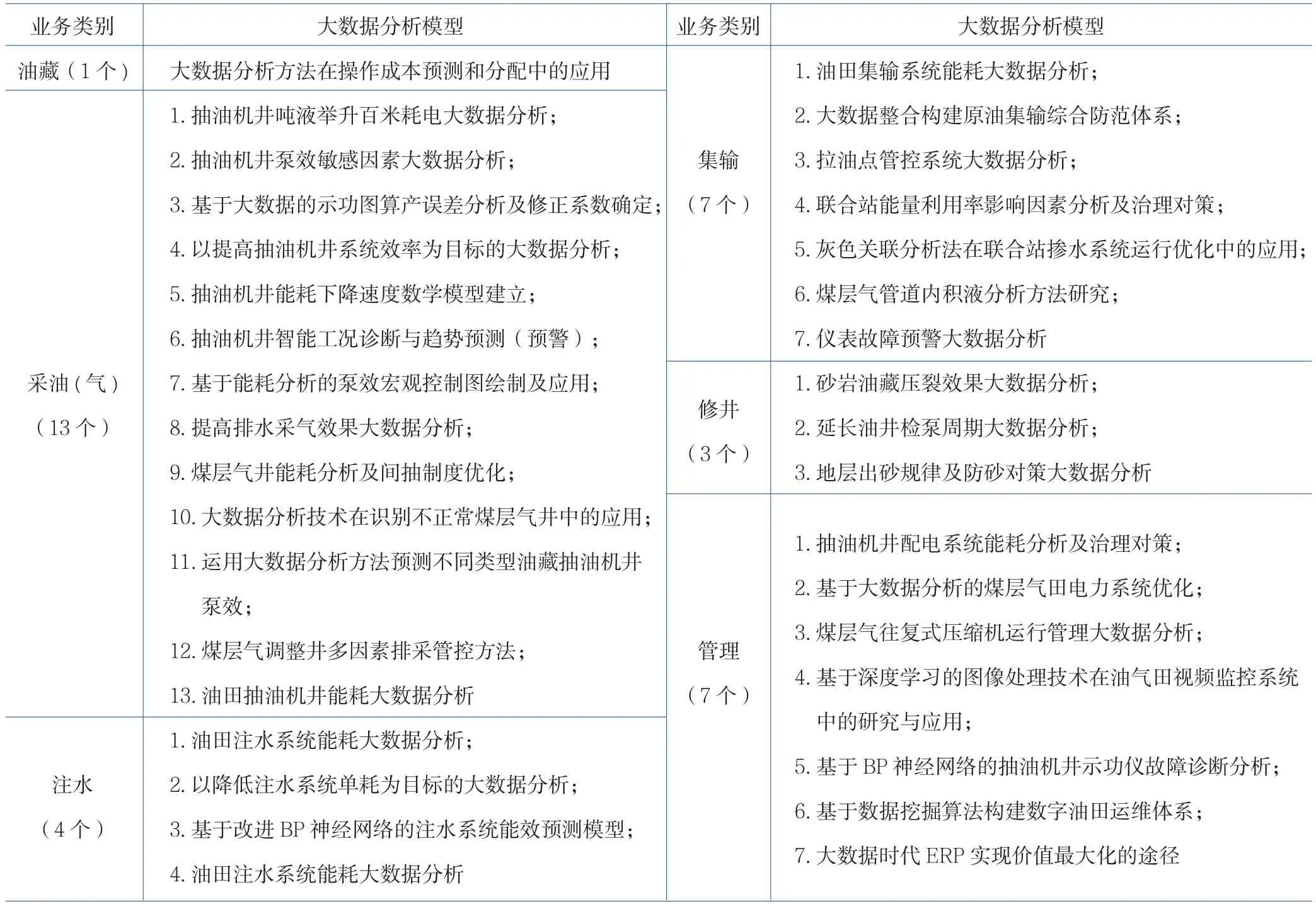
表1 油田生产主营业务大数据分析模型

表2 抽油机井吨液举升百米耗电大数据分析基础数据
由于影响系统效率和吨液举升百米耗电的因素很多,为找到关键因素,运用灰色关联法,将各影响因素对系统效率的影响程度进行关联度排序(表3)。再进一步对表中主要影响因素与系统效率、吨液举升百米耗电的关系进行单因素分析[10],确定每项参数的合理取值范围(表4),为制定单井节能降耗方案提供依据。统计对比大数据分析应用前后效果发现,抽油机井举升系统措施设计负荷率较以往提高了10%~15%,实施后在保持油井产液量不降的情况下,系统效率提高1.2%~2.0%,平均单井吨液举升百米耗电下降0.16kW·h。

表3 系统效率影响因素关联度排序
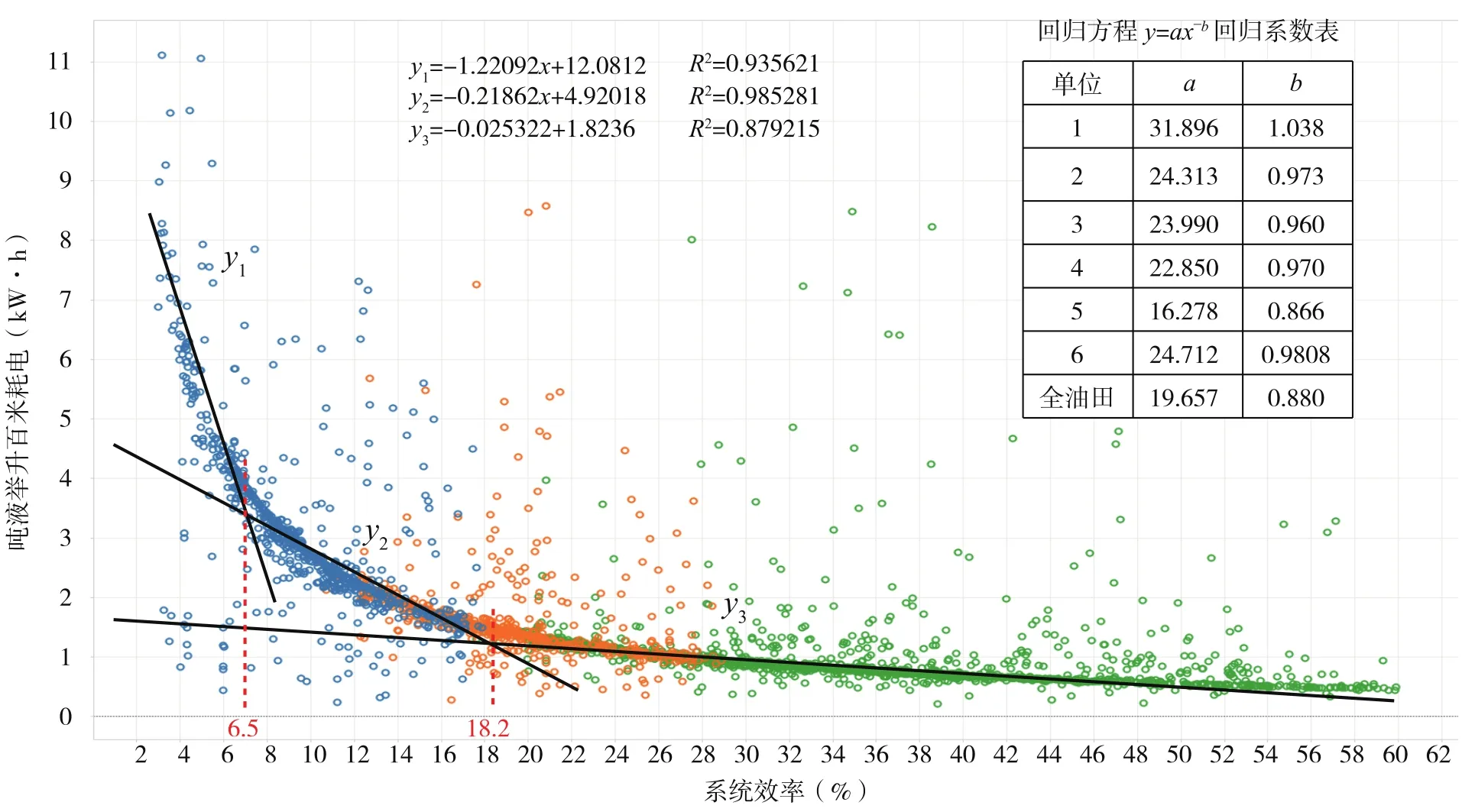
图2 H油田抽油机井系统效率与吨液举升百米耗电大数据关系曲线
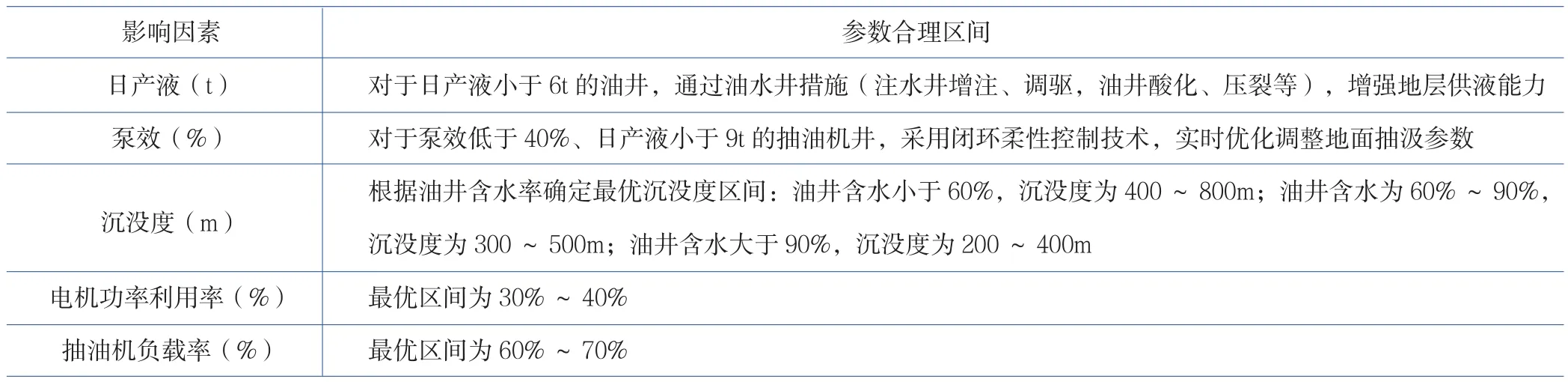
表4 H油田抽油机井系统效率部分主要影响因素取值范围
例2:抽油机井智能工况诊断预警[11]。基本思路是:对照单井标准示功图(样本),由计算机自动比较分析前后示功图形状变化,给出举升系统诊断结果,进而实现预警。主要步骤如下:
(1)示功图特征点提取。抽油机井的示功图形状复杂,提取特征参数难度较大,而特征参数的全面性、准确性对诊断结果有着决定性影响,如果所提取的工况特征未包含足够的识别信息,诊断结果误差很大。常用的提取方法有网格法、矩阵特征矢量法、灰度矩阵法、面积法、差分曲线法等[12-13]。本研究给出一种最优角度拟合算法,通过最优角度拟合,找到实测示功图的6个特征点(图3),然后在这些特征点的基础上经数据处理进一步形成25项特征参数,代表典型示功图特征。应用表明,这一方法在示功图形状识别上更加精准快速。
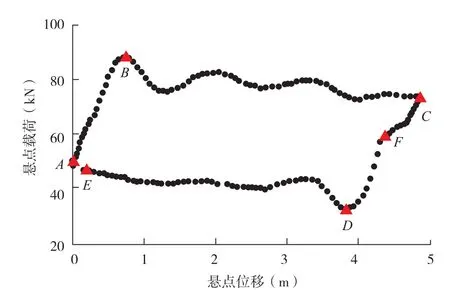
图3 示功图6个特征点示意图
每个示功图由大约200个点组成,上行程数据较密,110~120个点;下行程数据较稀,80~90个点。采用等位移插点法,使示功图成为标准点数的闭合图形。其中A、C、E点取值容易,A点为起始点(最接近零位移的点),C点为最大位移点,E点为采集的最后一点,B、D、F点需通过最优角度拟合计算。B点为游动凡尔完全关闭点,前一条拟合直线与下一条直线进行对比,θ角最小。D点为固定凡尔完全关闭点,前一条直线角θ1小于90°,后一条直线角θ2在180°附近。若D点之后又找出类似夹角,以第1个夹角为准,且后者的夹角法线大多在90°左右,而D点法线在第二象限,角度更大。F点为二次卸载起点,具体方法和D点取点法相似,但前一条直线角θ1在0°左右,后一条直线角θ2为90°~170°。示功图上任意一点载荷Pi都可以根据与之相邻的n个数据点之间的几何关系计算。经多次模拟训练,认为5~8个点拟合最为准确(图4)。
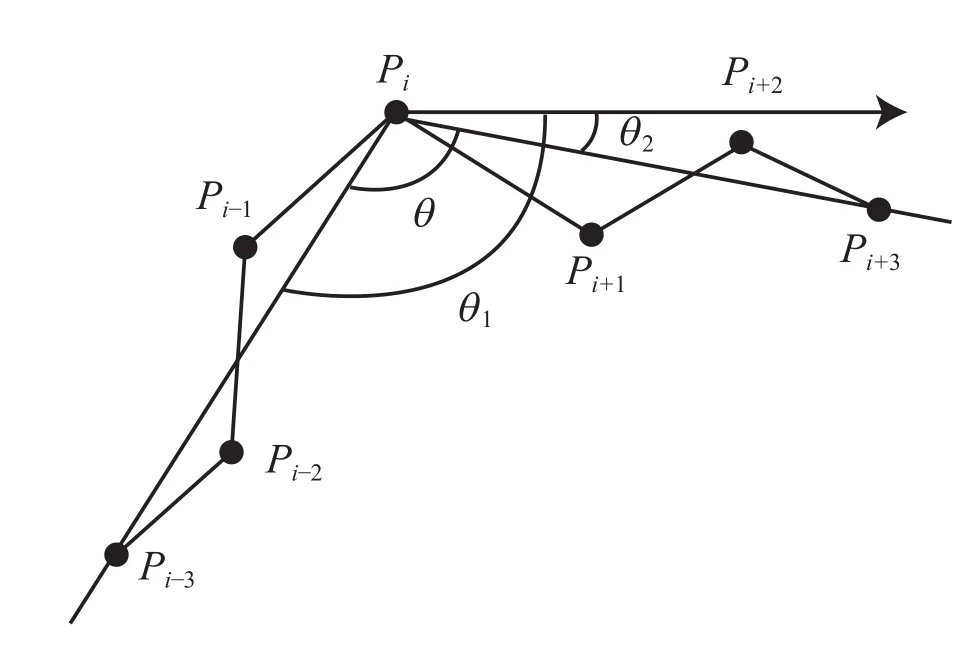
图4 角度拟合算法示意图
(2)特征值预处理。工况特征信息需要同时反映出图形形状特征和数值的变化才能准确诊断工况。若只考虑图形形状,当示功图出现缩放、旋转、移动等情况时,会出现误判。例如:抽油杆断脱和连抽带喷的示功图形状都为窄条状,图形特征相似,只有综合考虑形状特征和载荷值才能做出正确诊断。通过最优角度拟合算法计算的6个特征点的载荷、位移、角度,涵盖了示功图的基本轮廓,通过进一步计算,可以得到示功图最大载荷、最小载荷、有效冲程、充满系数、加卸载冲程损失、示功图面积等特征参数,综合考虑以上信息才能全面反映示功图形状和数值变化特征。
另外,对于停机、皮带异常等与地面设备相关的工况,仅靠示功图不能准确诊断,需结合其他数据进行分析。数字油田连续采集的电流信息可辅助进行此类工况诊断,当三相电流同时为0时(数据传输错误除外),电机停止运转,抽油机井处于停机状态;当电流值波动幅度变小,且抽油机悬点最大、最小载荷相差不大时,皮带出现故障。
(3)工况样本建立。为方便对比,首先,需建立理论示功图,每口井至少有1个理论示功图,可通过计算得到或选取某一正常工况下的标准示功图代之;其次,对实测示功图进行预处理,建立示功图标准化数据集,过程包括格式转换、等位移插点、特征提取等,特征参数包括6个控制点的载荷、位移、角度、最大载荷、最小载荷、有效冲程、充满系数、加载卸载冲程损失、示功图面积、三相电流等25项特征参数;最后,通过示功图标准化数据集与该井理论示功图进行对比,确定每种工况对应特征,形成典型工况特征样本库。
(4)决策树建模。抽油机井生产过程中,工况类型多达20余种。根据现场各种故障的概率大小,从中选择故障率较高的抽油杆断脱、供液不足、泵漏失、结蜡、上挂下碰、气体影响、错误示功图、停机、皮带异常9种常见故障进行预警报警研究。
(5)预警。以油井结蜡为例,油井结蜡时,杆管间的流道变小,井筒内液流阻力增大,杆、管壁上的蜡接触增加了摩阻。因此上行时负荷增加,悬点最大载荷增大;下行时阻力增加,悬点最小载荷减小。由此建立最大、最小载荷在线监测曲线(图5),并以理论最大、最小载荷线作为参考,设立预警线,当载荷触及预警线时,及时采取洗井、加药等措施,避免蜡卡事故的发生。该曲线可实时监测油井结蜡趋势,同时根据载荷曲线动态变化,指导单井热洗周期及加药制度优化。
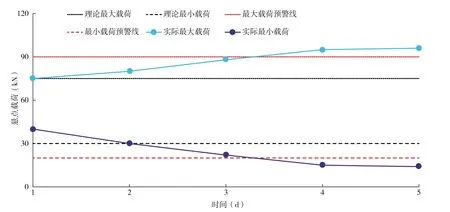
图5 结蜡井载荷变化趋势线
4 开发油田生产大数据分析平台
4.1 平台架构
油田生产大数据分析平台总体架构分为数据源层、数据平台层、应用服务层。其中,数据源层包括油田生产管理相关的地质、工程、生产、经营、成果、设备资产等多种类型数据。数据平台层以Hadoop为核心,包含了HDFS分布式文件系统、Spark内存计算、YARN资源管理、ElasticSearch引擎、Hbase核心数据库等。在数据存储方面,将价值密度高的结构化数据存储在关系型数据库中,供业务人员进行数据查询、分析、统计和挖掘;而非结构化的数据价值密度相对较低,将其存储在HBase集群中,以提高数据处理速度和利用效率。应用服务层以油田生产业务为导向,包括油藏、采油(气)、注水、集输、修井、管理及辅助等模块[14],封装多种数据分析方法(方法库)和多种专用数据分析模型(知识库),以组件形式存在,业务人员在图形界面下,通过拖拉拽、链接等操作构建分析流程并得出分析结果。平台利用可视化展示工具将分析成果直观呈现出来,帮助专业或管理人员进行决策[15]。
4.2 平台特点
为满足油田生产企业不同岗位人员尤其一线人员分析需要,推出大数据分析“基层版”“分析版”和“研究版”3种版本。其中,基层版为定制版,适用于采油厂作业区地质组、工程组人员开展所管辖区域内的油水井生产大数据分析;分析版为半开放版,适用于采油厂管理人员、“两所”(地质所、工程所)人员开展本厂范围内的油田生产大数据分析;研究版为全开放版,适用于油田企业职能部门管理人员、研究单位技术人员开展全油田范围内的生产大数据分析,并负责为基层提供定制的基层版和分析版,以及分析方法的不断优化和平台升级。随着企业间数据资源的共享,还可以进行跨油田、跨专业的大数据分析应用。
使用人员授权在个人电脑终端登陆平台后,进入所需适合版本的分析模块,只需轻点鼠标即可实现人机互动,快速完成所选目标的大数据分析。根据分析结果制定节能降耗、提高效率效益及安全生产的措施方案,结合本单位的生产计划安排实施。
5 现场应用情况及效果
油田生产大数据分析在H油田应用后获得显著成效,2015—2017年依据大数据分析成果优化各类增产增注、节能降耗、安全环保措施并实施,累计增油15.48×104t, 节电 1.09×108kW·h, 节水16.78×104m3,节约燃料油5138t,节约天然气539.3×104m3,节约药剂551.3t, 减少CO2排放量7.1×104t;新增销售额(增油)3.4亿元,新增利润(增油及节支)2.8亿元。
6 结束语
大数据分析助推“数字油田”向“智慧油田”发展,为油田企业提高精细管理水平提供了解决方案,在节能降耗、降本增效以及提高产量和效益等方面见到了实效。研究目前限于油田生产大数据分析领域,下一步将在此基础上向勘探、油藏、综合管理等专业拓展,攻克非结构化大数据分析难题,开展以企业综合经济效益最大化为目标的勘探开发一体化、地面地下一体化大数据分析应用研究。
