基于大数据的分布式隐私保护聚类挖掘算法研究
2018-10-31左国才
左国才
(湖南软件职业学院 软件与信息工程学院, 湖南 湘潭 411100)
引言
面对网络产生的海量数据,大数据的分析和处理即已成为后续研究关键。此时,需要用到各种典型的数据挖掘技术。在大数据背景下备受关注的数据挖掘是指从网络产生的NB级别的、带有较多噪声的、存储格式多样化的、分布式存储的大型数据库中利用数据挖掘技术去发现隐含的、有价值的信息[1]。数据挖掘抽取的相关信息有可能使得某些敏感信息泄露,因此,数据挖掘的前提就是必须要保证用户的隐私安全。在大数据时代,数据往往是存储在分散的站点中,在各站点协调一致进行大数据挖掘的过程中,需要传输数据以及共享数据挖掘的中间结果,这就将可能导致数据安全隐患及用户隐私泄露,针对这一数据安全保护问题,专家们提出了基于隐私保护的数据挖掘技术。该技术是指在保护用户数据隐私的同时能够提取出有价值的信息,从而有效解决数据泄露与隐私保护的问题[2]。在当今数据高速递增的情况下,保护数据隐私安全已经尤显其高度迫切与重要性。相应地,分布式数据挖掘既可以得到和集中式数据挖掘同样的效果,又可以保护分布式站点的数据隐私。因此,隐私保护分布式数据挖掘(PPDDM)已经成为近年来数据挖掘领域的研究热点。PPDDM旨在设计基于隐私保护技术的多方协同数据挖掘算法[3],该算法能够实现多个站点有序协同执行处理数据挖掘操作,也能够保护各个站点自身的私有信息,兼顾数据挖掘的准确性和隐私保护的有效性。基于此,本文拟将同态加密技术应用于典型的K-means聚类挖掘算法,设计提出一种基于大数据的分布式隐私保护的PP-kmeans算法,在满足大数据挖掘的安全性和隐私保护的目的要求情况下,开展大数据挖掘,并且能够得到较为精确的数据挖掘效果。
1 相关技术
1.1 大数据挖掘安全技术
大数据挖掘是从海量、不规则的多样化数据中提取和挖掘知识,在各个站点协同承载大数据挖掘任务时,首先需要考虑的是如何在实现数据挖掘的同时,防止各站点数据隐私泄露的问题。基于隐私保护的数据挖掘算法主要可分为如下研究类别:基于隐私保护的关联规则数据挖掘算法、基于隐私保护的分类数据挖掘算法和基于隐私保护的聚类数据挖掘算法、基于隐私保护的序列模式数据挖掘算法等[1]。其次,还需要采取有针对性的约束措施加强各站点自我约束管理,以确保在大数据挖掘顺利推进的同时能够最大限度避免数据隐私泄露情况的发生[4]。近年来,也已陆续涌现了一定数量的学术研究成果。文献[5]就探讨了在半诚实模型和恶意模型的基础条件下,基于隐私保护的数据挖掘算法的执行效率和数据挖掘隐私保护安全性;文献[6]又继而探究了基于数据安全和隐私保护的序列模式数据挖掘技术,设计了一种基于重要序列属性隐藏的数据挖掘算法,实现了有效的数据挖掘隐私保护;文献[7]则研究了在分布式环境中,设计隐私保护的数据挖掘算法,有效地解决了数据挖掘过程中的隐私泄露和数据安全等相关问题。
1.2 隐私数据保护技术
大数据挖掘过程中涉及的隐私数据主要包括与个人相关的私密信息,比如:个人基本资料、工作相关资料、个人财产与病历信息资料、个人社交的动态资料等,大数据挖掘隐私保护既要做到各个站点在数据挖掘过程中保护相关隐私数据,而不窃取其它站点隐私数据,又能保证达成数据挖掘的整体预期效果。综上分析可知,研究通常是在数据挖掘典型算法中采用数据加密的隐私保护技术,利用全同态加密技术对原始数据进行加密,在数据挖掘时就直接对加密密文来予以处理,如此既能保障隐私数据的安全,又不会影响数据挖掘的效果。同态加密技术不解密原始数据,而是直接对加密数据利用大数据挖掘算法等进行复杂计算操作,并且能够得到与数据加密前原始数据操作相同的结果。与此主题相关的重点研究成果有:文献[8]探索解析了全同态加密技术,并研发设计了基于全同态加密算法运行效率的改进方案,取得了较好的效果;文献[9]研究了全同态加密技术,并创新提出一种全同态加密方法-理想格加密方法,使得全同态加密技术能够应用到流行的云计算与外包计算中。该文认为对于加法和乘法,如果一种加密算法都能找到其对应的同态操作,即:
E(d)⊗E(d′)=E(d⊕d′)
(1)
这样,可以将其称为全同态加密算法。
2 保护隐私的分布式K-means聚类挖掘算法
2.1 算法思想
在分布式环境下,基于大数据进行数据挖掘,需要各站点联合计算聚类结果,这就将导致数据安全及隐私泄露的问题。本文即采取以主站点为中心,从站点独立计算各自聚类结果,协助主站点联合构建大数据挖掘的运行格局。在聚类计算和结果共享与传输的过程中数据隐私可能遭到侵犯,因此,需要保护各站点本身的数据和隐私安全,避免本站点提取得到了其它站点的相关聚类挖掘所使用的隐私数据,还需要注重在大数据聚类挖掘过程中的数据安全,以及在合作进行聚类分析计算和求得聚类分析结果在共享及相互发送时的数据安全及数据隐私的保护。
由分布式的环境设计支持的大数据挖掘具有多个站点参与,多个站点与主站点相互通信、并互动传输最终结果及中间结果的特点,合作进行聚类分析计算和中间聚类分析结果共享、传输是数据隐私最容易泄露的环节,因此,本文采用同态加密对原始数据进行加密操作,选取数据A,数据A必须满足如下等式要求:
A=D1×D2
(2)
其中,数据D1和数据D2均为素数。
设置Z为需要加密设置的明文,则整个加密过程的数学公式可表示如下:
Z′=Ek(Z)=(Z+D1×S)modA
(3)
其中,S为(1,D2)数据集合中满足均匀分布的随机数据。
将经过加密后的密文Z′传输到目标站点后,则使用加密密钥k进行相应的解密操作,就会得到解密后对应的明文X,即:
X=E-1(Z')=Dk(Z')=(Z')modk
(4)
本文将同态加密技术应用于典型的K-means聚类挖掘算法,设计提出一种基于大数据的分布式隐私保护的PP-kmeans算法。算法思想可概述如下。
(1)从站点计算本地站点的聚类分析结果,计算各数据点到主站点发送的初始聚类中心的距离,展开初始分类处理,并将计算得到的聚类分析结果进行同态加密操作后,再发送回主站点。
(2)主站点将从站点发送过来的聚类数据挖掘结果进行全局欧几里德距离计算,重新计算全局的聚类中心点,然后发送给从站点,进行解密操作后将得到聚类分析数据挖掘结果并再次发回。
(3)主站点根据全局聚类分析算法的收敛条件,判断是否停止循环操作。如果满足条件,则由主站点进行解密操作后,输出最终的聚类数据挖掘结果;否则,继续循环直到满足循环退出条件。
基于大数据的分布式隐私保护的PP-kmeans算法的设计流程如图1所示。
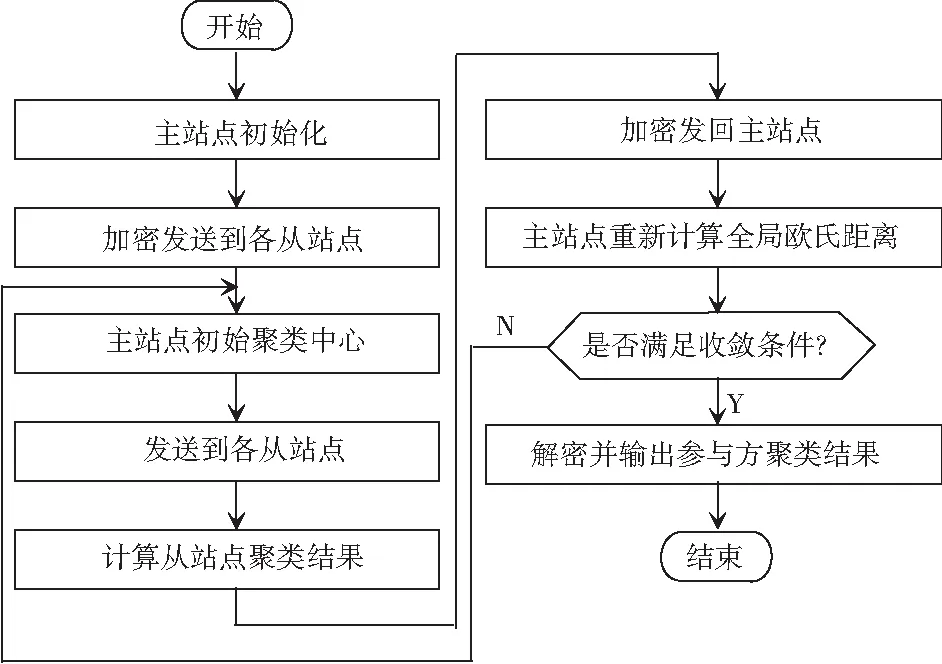
图1 PP-kmeans算法流程图
2.2 算法描述
输入:各从站点进行聚类分析的数据集Xi,每个数据集Xi对象个数xi(i=1,... ,n,n≥3) ,初始设置k个聚类中心点
输出:k个分类
Step1主站点利用加密算法,产生加密的密钥对 (ai,bi),并将ai与k个点值发送到各从站点Ci(i=1,... ,n,n≥3),从站点分别接收主站点发来的加密信息。
Step2循环开始
Step2.1根据主站点的初始k个点,计算从站点数据集Xi中包含的Ci个数据对象点与k个点之间的欧几里德距离,并根据距离大小确定将每个Ci加入附近k个中心点的所属分类中。
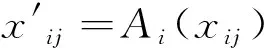

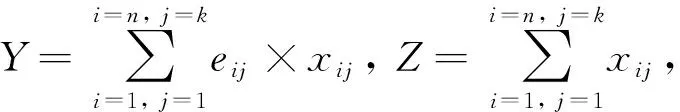

直到每个聚类中心点不再发生变化,结束循环,同时输出最终的全局聚类分析结果。
3 实验结果分析
实验环境配置如下:操作系统为Windows7、CPU为2.4 GHz、内存为4 G。实验数据采用机器学习数据集Adult,共有48 800条数据,每条数据含有14个属性。实验中,随机提取80%的数据记录来训练聚类分析模型,剩余的20%的数据记录用来测试聚类分析模型的精确率。本文设计的基于大数据的分布式隐私保护的PP-kmeans算法在数据分布式存储模式下,算法测试的分类准确率为86.2%,比传统的典型K-means算法聚类结果准确率要高3.2%。
经由分析可知,本文设计的分布式隐私保护的PP-kmeans算法由于在主站点与从站点之间,中间计算的聚类分析结果增加了加密、解密和相互发送结果的过程, 使得基于大数据的分布式隐私保护的PP-kmeans 算法的执行时间略大于传统典型的K-means算法,但是增加的加密、解密操作主要以线性运算为主,运行效率较高,运行时间消耗的增量并不大,因此,本文提出的基于大数据的分布式隐私保护的PP-kmeans聚类算法达到了既保护数据的安全、又不影响数据挖掘的实际效果。
4 结束语
本文在水平划分数据的分布式存储情况下,设计了一种基于大数据的分布式隐私保护的PP-kmeans算法。该算法将全同态加密技术应用于典型的K-means聚类挖掘算法中,来实现各站点自身数据及发送数据时的数据安全与隐私保护功能。各站点使用典型的K-means聚类挖掘算法计算从站点各自的聚类结果,利用全同态加密技术加密聚类分析计算的结果,主站点接收从站点加密之后的聚类分析计算结果再进行全局欧氏距离计算,不断调整全局聚类中心点,并完成全局的聚类数据挖掘工作。通过算法执行效率分析和实验测试表明,该算法能够在增加较少运算时间的情况下,提高最终聚类分析数据挖掘结果准确率,有效地保护各站点的数据安全。
