基于本体和加权朴素贝叶斯的网络舆情主题分类
2018-10-30丁晟春王小英刘梦露
丁晟春 王小英 刘梦露


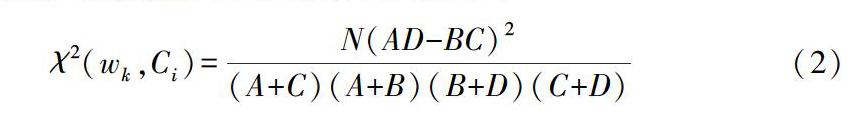
〔摘 要〕及时准确地对舆情信息进行主题分类,不仅能实时了解舆情动态变化,还能为预判舆情发展趋势、舆论引导建立基础。本文提出一种基于本体和加权朴素贝叶斯的网络舆情主题分类方法,通过使用本体将领域知识和领域文本特征融入分类过程中。将该方法应用到动物卫生领域舆情主题分类中,分类结果精确度为0.9402,Marco_F1达到0.9339。通过与朴素贝叶斯(NB)和THUCTC两种方法的对比实验,证明本文提出的基于本体和加权朴素贝叶斯的分类方法有效且具有可行性,但是领域本体的概念、关系的完备程度会影响分类的效率。
〔关键词〕网络舆情;主题分类;本体;加权朴素贝叶斯
DOI:10.3969/j.issn.1008-0821.2018.08.002
〔中图分类号〕G254.1 〔文献标识码〕A 〔文章編号〕1008-0821(2018)08-0012-06
〔Abstract〕Timely and accurate classification of public opinions can not only understand the dynamic changes of public opinions in real time,but also can establish the foundation for the development trend of public opinions and the guidance of public opinions.In this paper,a topic classification method based on ontology and Weighted Naive Bayes was proposed,which integrated domain knowledge and domain text features into the classification process by using ontology.Applying this method to the topic classification for animal health-related public opinions,and the accuracy and Marco_F1 of experiment were respectively 0.9402 and 0.9339.Compared with the two methods of Naive Bayes and THUCTC,it was proved that the proposed classification method based on ontology and weighted naive Bayes was effective and feasible.The completeness of concepts and relationships in domain ontology could affect the efficiency of classification.
〔Key words〕network public opinion;topic classification;ontology;Weighted Naive Bayes
随着信息技术的发展,网络已经成为人们交流和获取信息的主要途径,越来越多的人习惯于在网络上发表自己的观点和看法。从“表哥”到“柴静苍穹之下”,从“天津大爆炸”到“青岛大虾”,从“山东疫苗事件”到“魏则西事件”,一起起网络舆情事件,掀起了网络议论高潮。舆论的此起彼伏,引导着网民的左右摇摆,在一定程度促进“相关部门”迅速解决问题的同时,也消耗着了大量的社会资源和管理成本。为了使相关部门能够在海量网络舆情信息中更好地引导舆情发展方向和及时作出有效预警,需要对网络舆情主题进行分类。
现有研究大都以文本分类方法进行全领域舆情信息的分类,而针对某个具体领域内的舆情信息细分类研究很少。领域内舆情信息分类是一个二次分类问题,文本的类间内容相似度极高,而且训练集数据分布和媒体关注度都可能造成类共用特征词的分布不均。传统的文本分类方法通常是基于特征词的词频进行分类,没有考虑到没有考虑到词语间的语义关系和待分类文本所在的具体领域。所以在特定领域中,仅使用传统的文本分类算法不能取得较好的分类结果。因此,本文针对领域内舆情提出一种基于本体和加权朴素贝叶斯的分类方法,将领域内知识和领域文本特征加入到分类过程中,以提高领域内舆情信息的分类效果。
1 相关工作
1.1 舆情主题分类研究现状
当前舆情主题分类研究主要是使用文本分类算法对舆情信息内容进行分类。常用的文本分类算法有:支持向量机(Support Vector Machine,SVM)、k最近邻(k-Nearest Neighbor,KNN)、朴素贝叶斯(Native Bayes,NB)、决策树(Decision Tree)和Rocchio等。Jian Xu等研究了一种在Hadoop平台中基于朴素贝叶斯算法的网络舆情分类方法[1]。张宸等利用Hadoop平台可并行处理分布式数据存储的优良特性,提出了HSVM_WNB分类算法,通过MapReduce进程完成并行网络舆情信息的分类处理[2]。马海兵等利用KNN和SVM两种方法对网络舆情安全应用中主题分类问题展开研究[3]。吴坚等利用随机森林分类算法构建文档决策树对网络舆情信息进行了分类研究[4]。马海群等使用神经网络方法建立微博数据安全相关话题的分类系统,以及时有效地掌握公众对于数据安全话题的动态[5]。
还有部分研究将文本分类算法和其他方法相结合,以此加入特定领域舆情特征和弥补传统文本分类方法缺乏语义信息的缺点。林伟结合微博书写时口语化、时代化、含表情等特点,提出基于改进N-Gram的微博的多特征项提取算法,并提出基于聚类的KNN分类模型实现微博信息的分类[6]。B Sriram等通过对用户的个人资料和帖子中特定领域特征的提取,有效地将文本预定义为一组泛型类,实现了Twitter上的信息分类[7]。夏华林等提出一种基于规则与统计相结合的Web突发事件新闻多层次自动分类方法,首先提取类别关键词形成规则库,然后利用分类规则将突发事件分成4大类,再使用朴素贝叶斯分类方法将各大类突发事件新闻进行细分,形成了基于规则与统计的两层分类模型[8]。崔争艳结合《知网》本体库,将关键词映射到语义概念,并用语义KNN分类算法实现对微博信息的分类[9]。朱平等针对SVM分类方法缺乏对概念语义的处理这一缺点,提出一种集成本体和SVM的文本分类方法[10]。
1.2 加权朴素贝叶斯分类器
朴素贝叶斯算法是已知先验概率,计算待分类文本X属于各个类别Ci的条件概率,根据先验概率P(Ci)和条件概率P(X|Ci)计算后验概率P(Ci|X),选择后验概率最大的类别作为X的最终所属类别。朴素贝叶斯算法由于运算时间快、简单易行而广泛运用在文本分类中,但其所依赖的特征独立假设往往不成立。为了降低特征独立假设对份分类器性能的影响,学者们提出将各种特征加权算法与朴素贝叶斯分类器相结合,对不同的特征根据其分类重要性赋予不同的权值,将朴素贝叶斯扩展为加权朴素贝叶斯(Weighted Naive Bayes,WNB)[11-13]。加权朴素贝叶斯计算公式如下:
朴素贝叶斯分类算法是一种統计学的分类方法,没有考虑到没有考虑到词语间的语义关系和待分类文本所在的具体领域。而本体是对于“概念化”的明确表达,可以描述或表达某一领域知识的一组概念或术语。本体在文本分类中可以作为背景知识提供语义信息,也可以用来添加主题词扩充特征向量,提高分类效率。目前,已有很多学者使用本体进行了文本分类研究[14-16]。因此,本文通过本体为加权朴素贝叶斯分类算法提供领域知识,同时降低类共用特征词的分布不均造成的影响,实现领域内舆情的高效分类。
2 方 法
2.1 方法框架
基于本体和加权朴素贝叶斯的分类方法主要分为本体构建、文本预处理、特征提取和文本分类几个部分,方法框架如图1所示。
1)本体构建:依据领域舆情信息形成领域本体的基本框架,提取出框架内所有的概念,并定义概念与概念间的关系,选择合适的本体构建方法对领域本体进行编码和形式化。目前大部分的本体构建都需要领域专家的参与,本体在使用过程中也需要不断完善和优化。
2)文本预处理:包括分词、词性标注和去除停用词,以去除对分类不起作用的噪音词语。对于特定领域文本,使用通用的分词系统进行分词,其准确率较低。因此,将领域本体实例加入到分词工具中以提高分词的准确率。
3)特征提取:文本预处理后得到的是高维稀疏的特征向量,选择合适的特征提取算法来降低向量空间维数,从而简化计算提高文本处理的速度和效率。
4)文本分类:使用朴素贝叶斯对训练集数据进行训练,得出类先验概率P(Ci)和特征项的类条件概率P(X|Ci),将领域本体加入到分类器分类过程中对测试集进行分类,最后对分类结果进行评测和分析。
2.2 特征提取
特征抽取是在不破坏文本内容的情况下尽量减少所需处理的单词,以此来降低向量空间维数,从而简化计算提高文本处理的速度和效率,特征选择准确与否对文本分类至关重要。常用的文本特征选择方法有:文档频率(Document Frequency,DF)、互信息(Mutual Informal,MI)、信息增益(Information Gain,IG)和卡方检验(Chi-square Test)。这些方法的基本思想都是对每一个特征计算某种统计度量值,然后设定一个阈值y,把度量值小于y的特征过滤掉,剩下的即认为是有效特征[16]。
本文使用卡方检验方法进行文本特征提取,卡方检验是用来度量特征项wk与类Ci之间的相关程度,若wk对于Ci类的CHI值越高,则表示wk与Ci类的相关性越大,携带的类别信息更多,计算公式如下:
2.3 方法流程描述
输入:训练集、测试集
输出:文本类别
Step 1:将领域本体实例信息加入到分词工具中对训练集和测试集文本进行分词,并为领域内不同顶层概念下的专用词语自定义词性对分词后的文本进行词性标注,根据具体领域信息使用停用词表、正则表达式和词性标注去除噪音数据;
Step 2:使用特征提取方法对经过文本预处理的训练集文本进行特征降维,对测试集文本使用特征提取后的特征词进行表示,并筛选出特征词中类相关性大且在各类中均有出现的词语;
Step 3:依据待分类文本特性选择多变量伯努利模型或多项式模型对训练集文本进行训练,得出类先验概率P(Ci)和特征项的类条件概率P(X|Ci);
Step 4:通过词性标注判断测试集文本中是否包含类特有概念的词语,如果包含则输出该类的类别,进入Step 9,否则进入Step 5;
Step 5:判断测试集文本中包含多类共用概念的词性标注,包含进入Step 7,不包含进入Step 6;
Step 6:对测试数据执行加权朴素贝叶斯分类,以输出结果作为该文本类别,进入Step 9;
Step 7:通过概念的属性值判断测试集数据的所属类别,进入Step 9,不能使用概念属性判断类别的文本进入Step 8;
Step 8:对测试数据执行加权朴素贝叶斯分类,以输出结果作为该文本类别,进入Step 9;
Step 9:输出文本类别。
方法的Step 6和Step 8都进行了加权朴素贝叶斯计算,权重的计算公式(4)所示。但是两个加权朴素贝叶斯分类面向的词语是不同的。Step 6是对文本中所有词语进行加权朴素贝叶斯计算,而Step 8使用排除Step 2中筛选出的特征词后的词语进行计算。这是因为进入Step 8的文本在内容上具有极高的相似度,使用类相关性大且在各类中均有出现的词语进行加权计算会因训练集文本和媒体关注度导致的特征词分布不均对分类结果产生影响。
TF(wk|Ci)+1∑ni=1TF(wk|Ci)+2(4)
其中,TF(wk|Ci)表示特征词wk在类Ci中出现的次数,∑ni=1TF(wk|Ci)表示在所有类中特征词wk出现的总数,为了避免TF(wk|Ci)的值为0对该值进行估计。
3 实验与结果分析
目前,动物卫生领域舆情信息多集中在新闻和论坛中,林纲指出新闻标题担负引导读者进一步阅读的责任,是对新闻事件的高度概括,是新闻文本主题的精华体现[18]。因此,本部分选取新闻标题数据进行动物卫生领域舆情主题分类实验。
3.1 动物卫生领域舆情信息分析
3.1.1 动物卫生领域舆情信息类别定义
本课题组多次参与动物卫生和流行病学的调研,在充分了解中国动物卫生与流行病学中心对动物卫生领域舆情监测的实际需求及防控关注点的基础上,将动物卫生领域舆情信息分为动物卫生安全、公共卫生安全和动物源性食品安全3个类别。
1)动物卫生安全指只涉及动物自身的卫生事件,如:“台湾云林再传禽流感,近3万只肉雞被扑杀”,“新疆巴州轮台县发生一起小反刍兽疫疫情”,“死亡畜禽处理刻不容缓:宁波动物无害化处理厂已收运处理死亡畜禽近90吨”;
2)公共卫生安全则是指由动物源性病原体导致的人感染病例、非正常死亡和环境污染的卫生事件,如:“江西今年以来报告H7N9病例37例,死亡13人”、“湖北宜昌约百头死猪抛尸长江岸边,恶臭熏天”;
3)动物源性食品安全是指以动物为原料的食品安全事件,如肉品非法加工、冻品走私和瘦肉精使用等,“黑心摊贩牛血中添加福尔马林保鲜,两年售出60吨”。
3.1.2 动物卫生领域新闻舆情信息特征分析
本文对动物卫生领域新闻标题进行文本特征分析发现:①不同新闻网站对该领域新闻的描述方式相对统一;②动物卫生安全和公共卫生安全两类新闻标题的描述方式基本相同,标题中都会指出发生安全事件的地点和疫病名称,例如:“深圳龙岗两活禽市场检出H7N9禽流感病毒”、“上海确诊1例人感染H7N9”,由此也可以看出这两类的新闻内容相似度极高;③动物源性食品安全类新闻标题则会描述食品安全事件发生的地点和事件内容,如:“东莞市动监所查处一批伪造检疫证明冻肉”、“北京:四季风味猪头肉,检出瘦肉精”,动物源性食品安全类新闻标题的描述统一性不高,但是与前两类内容差异较大。
3.1.3 动物卫生领域新闻舆情自动分类的难点分析
由上述分析可以看出动物卫生领域新闻自动分类存在3个难点:1)本文研究的是动物卫生领域新闻文本的二次分类问题,也就是待分类文本都属于动物卫生领域,文本内容的相似度高;2)动物卫生安全类和公共卫生安全类的描述方式基本相同,差异仅在于患病群体,内容区分度小;3)同时由于训练集数据内容分布不均和媒体对部分动物疫病的高度关注导致某些词语在某个类别特别集中,例如在前两类作为类别关键词的“禽流感”、“H7N9”等。
3.2 数据集
动物卫生领域的新闻报道多出现在我国农业部、兽医局和各地畜牧兽医局等政府官方网站,或是人民网、新华网、中新网等影响力大受众多的新闻网站,还有像国际畜牧网、食品伙伴网(论坛)、食品论坛、食品科技网等动物卫生领域从业人员比较关注的网站。
本文从新华网、环球网、中国新闻网等网站抓取了2017年1月至2017年6月期间国内外动物卫生领域新闻,共计5 578条。将抓取的新闻标题数据进行人工分类标注,训练集和测试集数据分布如表1所示。
3.3 动物卫生领域本体构建
根据动物卫生领域舆情信息的分类类别,本文所构建的领域本体主要涉及动物疫病、食品添加剂、兽药(饲料)3部分,下面以动物疫病本体为例进行描述。
首先通过对《一二三类动物疫病释义》、百度百科、新闻报道对动物疫病的信息描述,总结归纳出动物疫病本体的顶层概念:病原学、流行病学、临床表现、防治。但仅依靠顶层概念不能提供足够的信息来描述动物疫病知识,所以在动物卫生领域专业人员的指导下描述顶层概念的内部结构,抽象出相关的扩展概念。经过以上两个步骤所得动物疫病本体中的部分等级、非等级关系及部分属性如下:
1)病原:包含病毒、原虫、真菌、细菌……;
2)流行病学:包含地理分布、多发时间、传播途径、感染群体……;
3)临床表现:包含潜伏期、体温、病程、发病率、死亡率、患病症状、并发症……;
4)防治:防疫级别、切断传播途径、控制传染源、保护易感群体……。
本文根据2016年世界动物卫生组织(Office International Des Epizooties,OIE)公布的动物疫病名录、我国农业部2008年修订的《一、二、三类动物疫病病种名录》和中国动物卫生与流行病学中心较为关注的疫病,以及常用食品添加剂和兽药(饲料)创建了317个动物卫生领域本体实例。
与全领域的新闻文本不同,动物卫生领域新闻舆情作为特定领域,使用通用的分词系统进行分词,其准确率较低。因此,本文将动物卫生领域本体实例和动物卫生领域常用固定词语加入到中科院ICTCLAS分词工具中以提高分词的准确率。对动物卫生领域本体实例,如动物疫病名称、疫病病毒名称、食品添加剂名称等建立两种自定义词性,如表2所示。
3.4 实验结果及分析
本文使用朴素贝叶斯(NB)、清华大学自然语言处理实验室推出的基于支持向量机的中文文本分类工具包THUCTC[19]和基于本体和加权朴素贝叶斯(OWNB)3种方法进行分类实验,并使用精确度(Accuracy)和宏平均(Macro-Averaging)来衡量其的性能,总体实验结果、分类实验结果如表3、表4、图3和图4所示。
由表3可以看出,本文提出的基于本体加权朴素贝叶斯分类算法在动物卫生领域舆情分类实验中取得了不错的分类效果,精确率达到0.9402,Marco_F1达到了0.9339,较NB和THUCTC分类结果有较大的提升,由此可以说本文提出的分类方法是有效的。
之所以能取得较好的实验结果,主要包含以下原因:
1)3类文本中都可能出现标注为“/disease”的词语,而且“禽流感”、“H7N9”等动物疫病名称的分布不均导致前两类很多文本被错分。使用所有词语进行加权计算不能很好地的区分动物卫生安全和公共卫生安全类,仅使用名词进行分类计算可以更好地判断卫生事件的受众是人还是动物,也排除共用动词(例如:“感染”、“扩散”、“出现”等)的干扰,以此提高了动物卫生安全类的准确率和公共卫生安全类的召回率。在动物卫生领域分类流程的基础上加入权重,突出了各类特征词在每一类的重要程度,使分类效果得到进一步提升。
2)由于动物源性食品安全分类新闻内容与前两类差距较大,通过使用该类特有概念的词语,将该类文本与其他两类区分开,同时OWNB方法减少了前两类错分到该类的数据,提高了其准确率。
对未分类正确的文本进行分析后发现:本文提出的方法对动物卫生领域本体及其属性值的完备性有较大的依赖。本文引入的动物卫生知识本体中仅包含OIE公布的动物疫病名录和《一、二、三类动物疫病病种名录》中的疫病,在未分类正确的文本中就出现了不包含在上述两个名录中的疫病。这不仅对文本分词造成影响,也弱化了本文分类方法的作用。
4 总 结
本文利用领域本体将领域知识和领域文本特征加入到分类过程中,结合加权朴素贝叶斯分类算法提出了适合于领域舆情信息的分类方法。通过与朴素贝叶斯和THUCTC的对比实验可以看出本文提出的分类算法较其他算法有了明显提升。但是,本研究仅将领域本体的概念加入到分类中,没有对本体概念间的关系进行使用。后续笔者还将就还将就上述不足对对分类方法进行不断的完善,并选择其他领域舆情信息进行实证分析,提高分类的准确性,为更好地引导网络舆情发展方向和及时做出有效预警奠定基础。
参考文献
[1]Jian Xu,Bin Ma.Study of Network Public Opinion Classification Method Based on Naive Bayesian Algorithm in Hadoop Environment[J].Applied Mechanics and Materials,2014,3009(519).
[2]张宸,韩夏.大数据环境下基于SVM-WNB的网络舆情分类研究[J].统计与决策,2017,(14):45-48.
[3]马海兵,毕久阳,邱君瑞.网络舆情安全应用中主题分类方法的研究与实现[J].现代情报,2012,32(4):8-13.
[4]吴坚,沙晶.基于随机森林算法的网络舆情文本信息分类方法研究[J].信息网络安全,2014,(11):36-40.
[5]马海群,王今.基于神经网络的数据安全话题文本分类研究——以新浪微博为例[J].图书馆,2017,(5):36-39.
[6]林伟.基于多特征提取的中文微博舆情分类研究[J].中国人民公安大学学报:自然科学版,2016,22(4):53-56.
[7]Sriram B,Fuhry D,Demir E,et al.Short Text Classification in Twitter to Improve Information Filtering[C]// International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2010:841-842.
[8]崔爭艳.基于语义的微博短信息分类[J].现代计算机:专业版,2010,(8):18-20.
[9]夏华林,张仰森.基于规则与统计的Web突发事件新闻多层次分类[J].计算机应用,2012,32(2):392-394.
[10]朱平,范少辉,岳永德.一种集成本体和SVM的文本分类方法[J].江西理工大学学报,2012,33(1):68-72.
[11]Webb G I,Pazzan MJ.Adjusted Probability Naive Bayesian Induction[C]//Proceedings of the 11th Australian Joint Conference on Artificial Intelligence.1998:285-295.
[12]Kim S B,Rim H C,Yook D,et al.Effective Methods for Improving Naive Bayes Text Classifiers[C]// PRICAI 2002:Trends in Artificial Intelligence,Pacific Rim International Conference on Artificial Intelligence,Tokyo,Japan,August 18-22,2002,Proceedings.DBLP,2002:414-423.
[13]Zhang H,Sheng S.Learning Weighted Naive Bayes with Accurate Ranking[C]//Proceedings of the 4th IEEE International Conference on Data Mining,2004:567-570.
[14]Song M H,Lim S Y,Kang D J,et al.Automatic Classification of Web Pages based on the Concept of Domain Ontology[C]// Asia-Pacific Software Engineering Conference.IEEE Computer Society,2005:645-651.
[15]张颖,王文杰,史忠植.基于本体的文本分类方法[J].计算机仿真,2009,26(5):103-106,178.
[16]韦婷婷,聂登国,王驹,等.基于领域本体的文本分类方法[J].计算机工程,2012,38(15):62-65.
[17]代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究[J].中文信息学报,2004,(1):26-32.
[18]林纲.网络新闻文本结构的语法特征[J].社会科学家,2010,(7):155-157.
[19]孙茂松,李景阳,郭志芃,等.THUCTC:一个高效的中文文本分类工具包.2016.
(责任编辑:马 卓)
