基于指令级冗余的密码流处理器并发错误检测方法
2018-10-24戴紫彬王寿成李功丽
戴 强 戴紫彬 王寿成 李功丽 李 伟
(中国人民解放军信息工程大学 河南 郑州 450001)
0 引 言
可重构分组密码流处理器RBCSP(Reconfigurable Block Cipher Stream Processor)[1]是一种新型的高效能分组密码处理器,可在资源受限条件下实现多种分组密码算法。然而,由环境因素引起的自然故障[2]与故障攻击注入的恶意故障[3],将极大降低RBCSP的可靠性,并可能导致密钥泄露[4]。并发错误检测能够有效检测自然故障[5],也是抵抗故障攻击的主要手段之一[4],但错误检测机制的引入不可避免会带来硬件开销增大、算法实现性能下降等消极影响。如何为RBCSP设计低开销的并发错误检测机制,使处理器具有较高的故障检测能力,是亟待解决的问题。
RBCSP 基于流体系架构实现,其核心级运算簇采用VLIW(Very Large Instruction Word)结构。目前面向VLIW处理器的软错误检测方法多采用指令级冗余技术[6-10]实现。指令级冗余依靠软件技术、以较少或零硬件开销实现冗余执行,其核心思想是以复制指令填充空闲槽(NOP指令),可有效减少错误检测带来的性能损失。文献[6]在指令执行的当前时钟周期,利用VLIW处理器中空闲功能单元实现冗余操作,其性能开销为0,但错误检测能力较弱。文献[7]在文献[6]的基础上提出通过降低指令级并行度实现自适应的指令复制方法。相比文献[6],该方法可实现性能与错误检测能力的折中。文献[8]提出的指令复制算法,根据指令序列中指令出现的先后顺序依次复制指令。文献[9]通过修改译码级电路、调整指令格式,实现了指令的动态复制,有效减少了代码规模。然而该方法的指令复制范围仅限于指令当前所在时钟周期与下一时钟周期,导致其性能开销较文献[9]有所增加。文献[10]采用纯软件技术,在空闲槽插入复制指令与检查指令实现错误检测,其硬件开销为0,但性能开销较大。
上述针对VLIW处理器的指令复制方法,无法适配或者高效适配于RBCSP。因此,本文面向RBCSP,依据其架构特征与代码实现指令序列特点,提出了指令级冗余的并发错误检测方法,并设计了脆弱性感知的指令复制算法,可在满足性能约束条件下有效提高处理器对随机故障与恶意故障的检测能力。实验证明,相比于同类型方法,在相同性能开销条件下,采用本文方法后RBCSP对随机故障与恶意故障的检测率更高,且全指令复制后密码算法实现性能开销最低、面积能效比最高。
1 功能单元利用率分析
指令级冗余技术的核心思想是以冗余指令填充空闲槽,其实质是利用空闲状态功能单元实现冗余计算。为评估指令级冗余方法在RBCSP上的可行性与高效性,需对不同分组密码算法实现时处理器功能单元,即可重构并行处理单元RPU(Reconfigurable Parallel processing Unit)的利用率进行统计。RBCSP上RPU包括多种类型,如S盒运算单元、置换单元等,需分别进行统计。RBCSP上实现分组密码算法,采用软件流水技术挖掘轮函数中不同操作间的指令级并行度[5],可使相邻迭代的加密操作尽可能地重叠执行。以CBC(Cipher Block Chaining)模式下AES-128算法实现为例,其软件流水实现如图1所示。
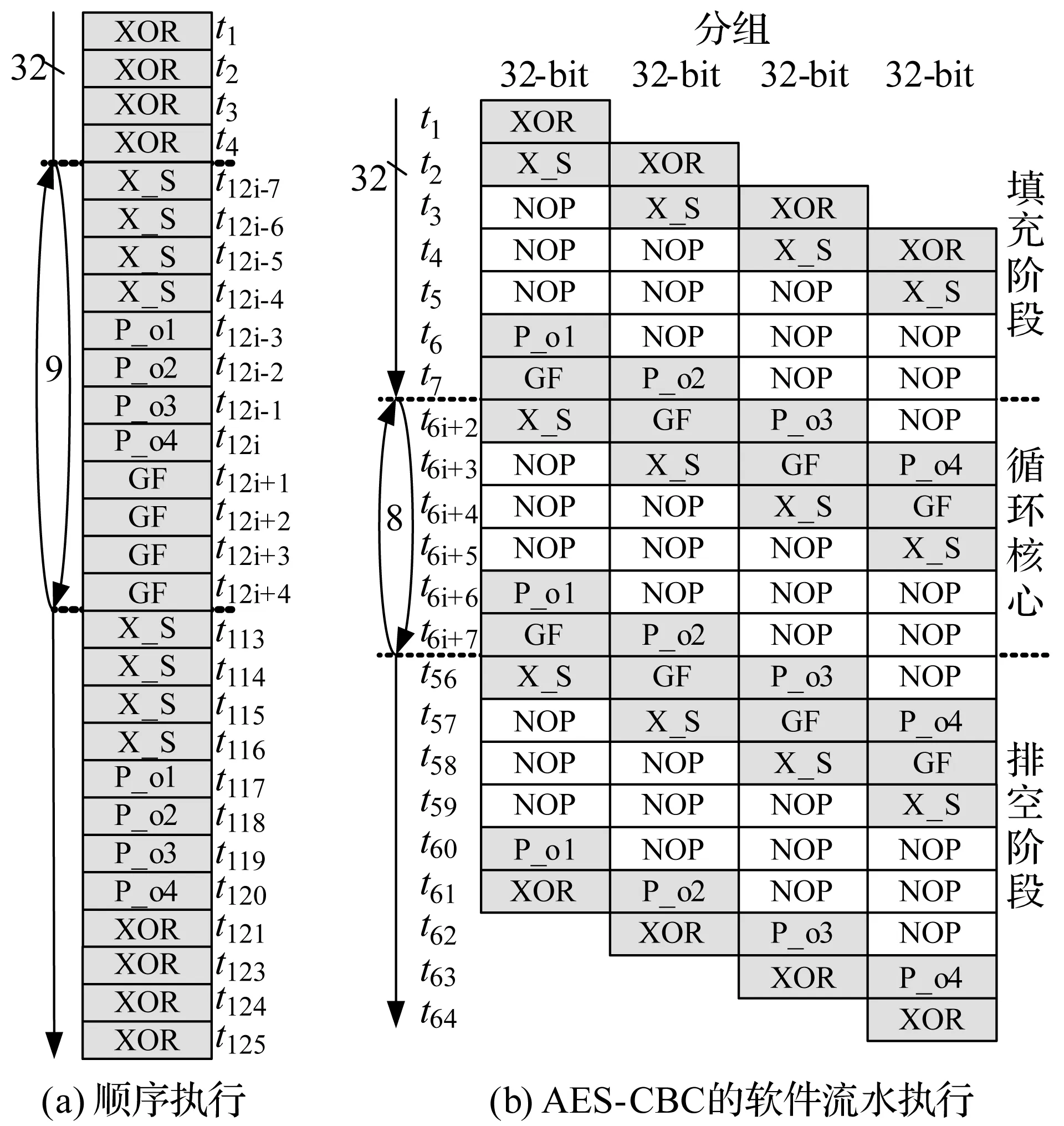
图1 RBCSP上CBC模式AES算法实现
图1中AES算法轮函数操作映射为4个32-bit数据分块依次进行绑定前异或的S盒操作(X_S)、有限域乘法操作与四字置换选字输出操作。整个软件流水共分为3个阶段:填充阶段、循环核心阶段和排空阶段。通过软件流水调度,单个数据分块的轮函数操作仍是依次执行,而分组内不同数据分块的轮函数操作能够并行执行,相比于图1(a)所示顺序执行的实现方式,软件流水方式大大缩短了加密周期。
通过观察图1(b)所示指令序列可知,指令中存在大量可利用的空闲域。设RPU利用率为rRPU,其等于算法程序运行过程中占用该RPU的时钟周期数NusedRPU与总时钟周期数Ntotal的比率,如公式所示:
(1)
分析软件流水方式下不同算法实现代码,各算法rRPU统计结果如图2所示。
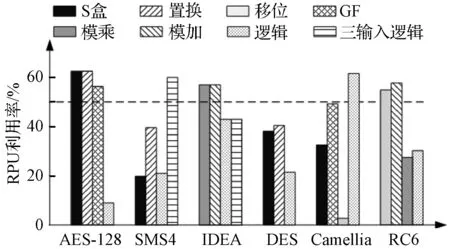
图2 软件流水工作模式下各算法RPU利用率
图2中,除DES外,AES-128、SMS4、IDEA、Camellia和RC6算法的最大RPU利用率超过50%,但RPU平均利用率仍在40%左右。统计分析后可知RPU利用率仍有足够大的提升空间,这意味着在各算法程序运行过程的多数时钟周期中仍存在可利用的空闲RPU。通过有效利用这些空闲RPU执行复制指令操作,可减少错误检测带来的性能开销。
2 指令复制算法
2.1 复制指令调度范围
本文RBCSP上分组密码算法实现的指令序列视作一个二维调度表,行表示各RPU,列表示指令调度的时钟周期。表中圆圈表示指令,箭头表示指令间的数据相关性,空格表示该时钟周期对应的RPU空闲。指令i的复制范围是指其冗余指令在调度表中可调度的时钟周期范围。指令复制范围可简单设置为指令i所在时钟周期的下一个时钟周期。若下一时钟周期中无可利用的空闲RPU,则增加一个新的时钟周期用以调度冗余指令。通过这种复制方法,可快速完成原始指令序列至复制后指令序列的转变。
对于图3(a)中的原始调度表,按该方法进行指令复制后,调度表变为图3(b)所示。图3(b)中指令D需等待指令C的复制指令完成后才能执行,而指令E与指令D存在数据相关,这导致指令E也需等待指令C的复制指令完成才可执行。此时指令D的复制指令在时钟周期4调度,而调度完所有复制指令所需的时钟周期数为7。若等待占据同一RPU的连续指令完成后,再调度复制指令,此时完成所有指令复制所需时钟周期数为6,如图3(c)所示。由于调度表中存在多个连续占用某个RPU的指令,且后续指令与这些连续指令存在数据相关,导致图3(b)所示的复制方法相比于图3(c),消耗时钟周期数更多。

图3 指令调度表
常见分组密码算法的分组长度大多为64、128、256 bit,而RBCSP中RPC的数据位宽为32,这使得RBCSP上密码算法实现的指令序列中,一个分组操作需要多个使用某类型RPU的连续指令实现。且分组密码算法实现的指令序列中,前后指令的数据相关性较强,若采用图3(b)所示的指令复制方法,则存在许多原始指令操作须等待之前指令的复制指令完成后才能执行,这将极大降低算法实现性能。因此,本文选择图3(c)所示的指令复制方法。该方法中指令i的复制范围由指令i所依赖的指令以及重写指令i所读取寄存器的指令确定。复制指令调度范围如下:
• 最早调度时钟周期:指令i的源操作数准备完毕且指令i所使用RPU处于空闲的第一个时钟周期。
• 最晚调度时钟周期:指令i所需任何源操作数被重写之前的最后一个时钟周期。
2.2 指令复制算法描述
为在满足性能约束条件下提高处理器的故障检测能力,可优先选择复制脆弱性更高的指令。目前已有文献中指令脆弱性主要包括指令的时间脆弱性、物理脆弱性[10]。指令的时间脆弱性ITV(Instruction Temporal Vulnerability),可由该指令的总执行次数表示。一般认为循环内指令比其他指令执行次数更多,因此具有更多机会发生软错误[11]。指令的物理脆弱性IPV(Instruction Physical Vulnerability),可由该指令所使用单元面积表示。这是因为单元面积越大,包含的晶体管数量越多,则它更多的暴露于高能粒子从而易于诱发软错误[12]。与通用处理器不同,分组密码流处理器专用于实现分组密码算法,易受到恶意故障攻击。因此在选择指令复制时,本文将恶意故障注入位置、轮数纳入考虑,提出指令的攻击脆弱性IVV(Instruction Vulnerable Vulnerability)概念。
定义1指令易受到恶意故障攻击的可能性,称之为指令的攻击脆弱性。
攻击脆弱性越高的指令,越容易成为恶意攻击的对象。恶意故障注入的位置、时间取决于具体的分组密码算法及攻击所采用的故障模型,因此不同算法实现的指令序列中,即使是相同指令,其攻击脆弱性也可能不同。如针对AES-128算法的故障攻击,多选择在第7、8、9轮操作中注入恶意故障[13],故相比于其他轮,算法实现指令序列中第7、8、9轮运算指令的攻击脆弱性更高。
为了量化评估调度表中指令的脆弱性,本文分别对指令的时间脆弱性、物理脆弱性、相关脆弱性设置了如下量化规则。
规则1设指令序列中不循环执行指令的时间脆弱性因子ITVF(Instruction Temporal Vulnerability Factor)为1;指令序列中循环执行指令的ITVF为10。目前算法实现指令序列采用循环展开方式实现,则所有指令的ITVF均为1。
规则2设最小RPU单元面积为Amin,且使用该RPU指令的物理脆弱性因子IPVF(Instruction Physical Vulnerability Factor)为1,则对于指令i,若其使用RPU面积为Ai,则其IPVF=Ai/Amin。
规则3由所实现算法确定算法易受故障攻击的轮数,选择指令序列中对应轮的指令,其指令攻击脆弱性因子IVVF(Instruction Vulnerable Vulnerability Factor)设为1 000,其他指令的IVVF设为1。
按上述规则,计算得到调度表中各指令的ITVF、IPVF、IVVF,则指令的脆弱性因子IVF(Instruction Vulnerability Factor)可由式(2)计算得到:
IVF=ITVF×IPVF×IVVF
(2)
将所有指令按其IVF进行降序排列(IVF相同的指令按指令先后逆序排列),可得到指令优先级列表L。指令优先级列表L中靠前的指令,脆弱性越高,将优先选择复制。根据复制指令优先级列表L,设置时钟周期增长上限,在计算得到的指令复制范围内调度复制指令。本文的脆弱性感知指令复制算法伪代码如下:
输入:VLIW代码;时钟周期增长上限cycle_increase_margin。
输出:带复制指令信息的VLIW代码。
定义:代码序列的区域图G={N,E},其中N={ni/ni表示一个代码区域,通常为一个基本指令块},E={ei,j/ei,j表示存在控制流ni→nj};
Nattack={nk/nk表示易受攻击的指令块};优先级指令列表L:按照脆弱性降序排列存储的指令列表;max_sched_cycle:最大调度时钟周期。
01:for(each instruction inst∈L)
02: dup_inst=create_dupl(inst);
//创建冗余指令
03: inst_cycle= get_sched_cycle(inst);
//获得原始指令所在时钟周期
04: etime=get_earliest_sched_time(inst);
//指令调度的最早时钟周期
05: ltime = get_earliest_sched_time(inst);
//指令调度的最晚时钟周期
06: stime=etime;
07:while!schedule(dup_inst, stime)do
//尝试调度冗余指令
08: stime++;
09:if(stime>ltime)then
10:if(cycle_inc_margin>0)&&(check_dupl_dependence())then
11: shift_point=get_shift_start_point(inst,ltime,stime);
12: shift_down_sched_table(shift_point,max_sched_cycle);
13: update stime;
14: update ltime;
15: cycle_increase_margin--;
16: max_sched_cycle++;
17:else
18: delete dupl_inst;
19: break;
20:endif
21:endif
22:endwhile
23:endfor
表中循环(行01-23)按照已构建的指令优先级复制列表L中指令优先级顺序调度复制指令。对于列表L中每条指令,算法首先获取指令复制所需信息(行02-06),并在获取的指令复制范围stime至ltime中,尝试调度复制指令。算法中schedule()尝试调度冗余指令失败的情况主要是指当前时刻已存在超过RBCSP可支持的RPU并行执行数。若调度失败,而时钟周期增加上限大于0且调度冗余指令不会导致指令间相关性违背,则尝试向下移动调度表,以提供有效空间实现冗余指令调度(行09-16)。函数check_dupl_dependecne()判断移动调度表放置复制指令是否会导致各指令间相关性违背。若不存在相关性违背,则存在一个合理方式移动调度表以放置冗余指令。函数get_shift_start_point()负责计算调度表移动起点。函数shift_down_sched_table()将部分调度表往下移动一个时钟周期。若存在相关性违背或时钟周期增加上限小于或等于0,则放弃复制该指令(行14-20)。重复上述过程对列表L中指令依次进行复制,直至所有指令复制调度结束或者时钟周期增长上限为0,算法结束。
在不考虑性能约束时,采用该算法实现AES全指令复制时的指令序列如图4所示。图4中冗余指令充分利用了原始指令序列中的空闲槽,相比于原始指令序列,其增加的指令条数比约为25.6%。指令复制后处理器的故障检测能力将在下节展示。
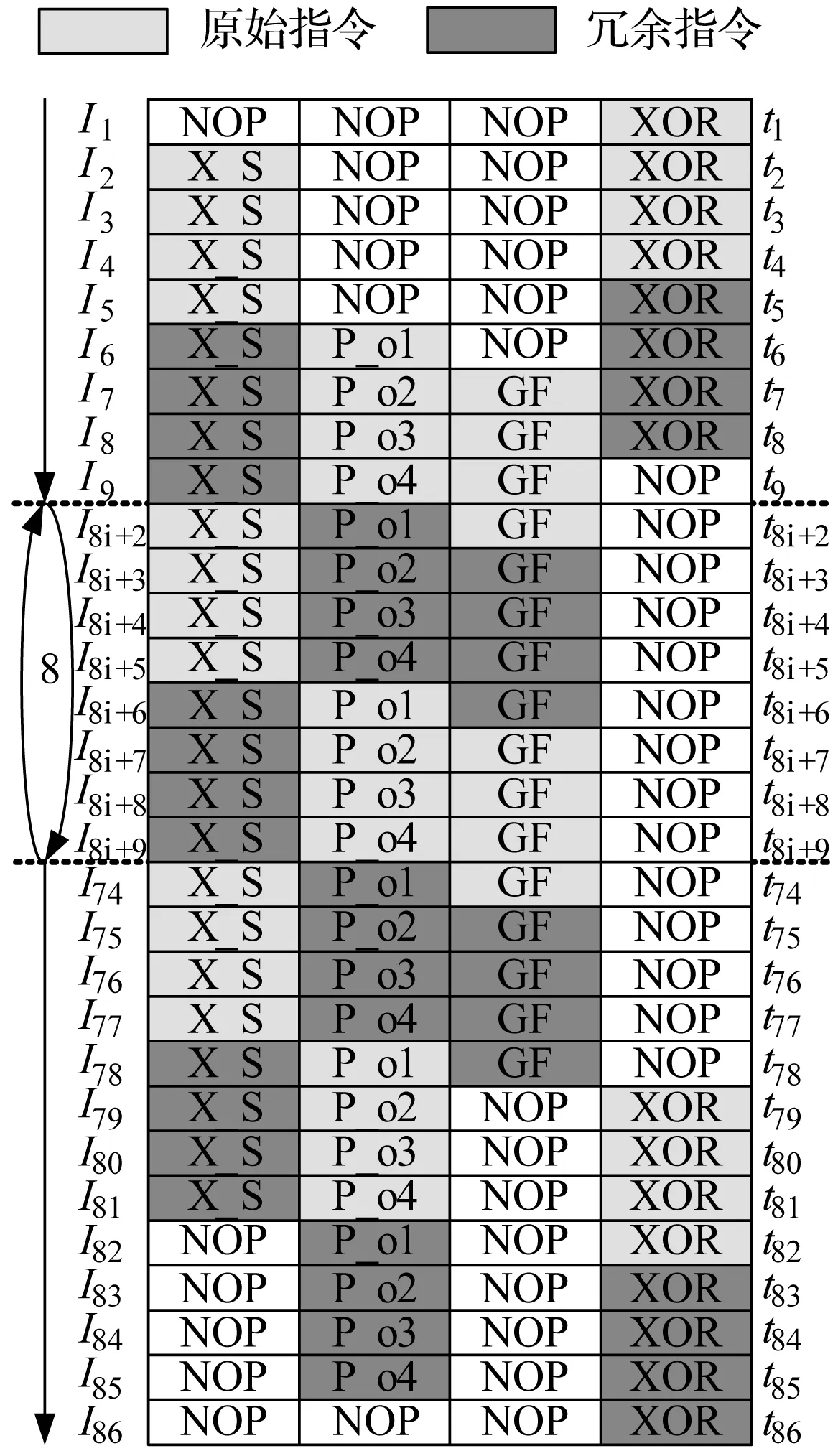
图4 AES-CBC算法的全指令复制实现
3 实验验证
为减少性能开销,对原RBCSP进行了部分硬件扩展与指令格式修改, 使原始指令与冗余指令的结果比较不需增加额外的比较指令。本文将扩展后的RBCSP称之为增强型可重构分组密码流处理器ERBCSP(Enhanced Reconfigurable Block Cipher Stream Processor)。利用综合工具基于65 nm CMOS工艺标准单元库综合获取了RBCSP与ERBCSP原型系统的硬件资源信息,综合结果如表1所示。根据综合结果,RBCSP与ERBCSP原型系统的关键路径长度均为2.0 ns(工作频率为500 MHz),而相比RBCSP,ERBCSP增加的硬件开销比约为1.5%。

表1 ASIC综合结果
3.1 故障检测能力
为验证错误检测方法的有效性,分别被执行了随机故障注入实验与恶意故障注入实验。测试目标RTL系统采用 ERBCSP的RTL设计与验证环境。故障注入目标模块选取RPU,注入故障类型为瞬态故障。仿真实验均以AES算法为测试基准,并以如下方式生成测试负载执行仿真:一是设定不同时钟周期增长上限(即性能开销约束),分别按本文、文献[9]、文献[10]的指令复制算法复制指令后得到相应代码,作为测试负载。
3.1.1 随机故障检测
仿真时在测试负载执行过程的随机时间改变RPU的任意信号值,持续时间为一个时钟周期。测试程序每运行一次,仅注入一个随机故障,共运行300 000次。测试负载运行过程中,记录错误指示信号变化次数,获得异常检测数量Nexp,则故障检测率FDR(Fault Detection Rate)为(Nexp/300 000)×100%。图5展示了不同时钟周期增长上限下的随机故障检测率。
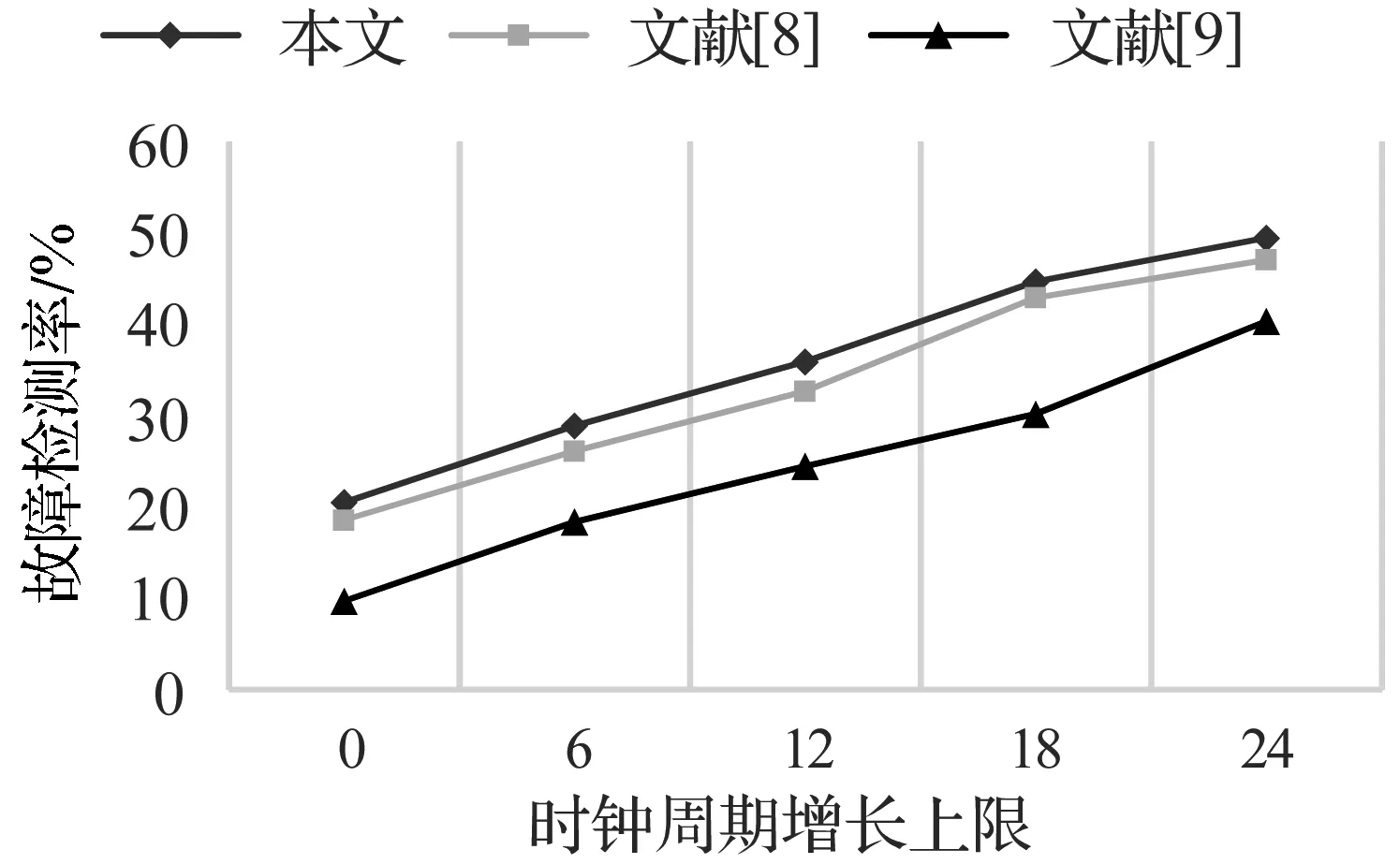
图5 随机故障检测率对比
由于许多注入的随机故障并不会影响密码运算结果,因而相比于故障注入总数,产生计算错误的次数并不高,故图5中全指令复制后各方案的故障检测率约为49%。但由图5可知,相同性能约束下,本文方法的随机故障检测率明显高于文献[9],略高于文献[8]。
3.1.2 恶意故障检测
为模拟故障攻击,选择经典的单字节故障模型[14],在AES算法第9轮列混淆输入处注入1字节恶意故障。实验时,在第9轮四字置换原始计算结束时刻,强制改变保存原始计算结果的DCR,程序每运行一次,随机改变1字节值,共运行4 096次。图6展示了不同时钟周期增长上限下各文献方案的恶意故障检测率。
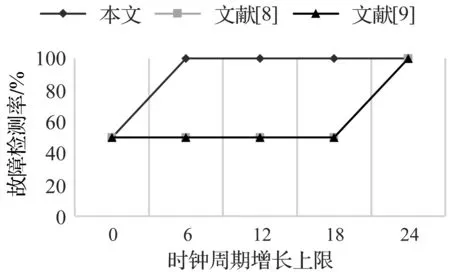
图6 恶意故障检测率对比
由图6可知,当时钟周期增长数量大于等于6时,本文方案的恶意故障检测率已为100%,而文献[8]、文献[9]方案的恶意故障检测率为50%或0。由图6可知,在相同性能约束下,相比于文献[8]、文献[9],采用本文方法后RBCSP对恶意故障具有更高的检测率。
3.2 性能开销对比
本文选取AES-128、SMS4和IDEA算法作为SP、Feistel和L-M三种结构的代表算法,以CBC模式作为算法工作模式,分别在ERBCSP上进行全指令复制的算法实现,算法实现性能结果如表2所示。

表2 密码算法实现性能
由表2可知复制全部指令后,AES-128、SMS4、IDEA的性能开销比分别为25.6%、17.9%、15.7%。为说明性能开销较低的原因,统计了复制全部指令前后各算法的RPU利用率。如图7(a)所示,复制指令前,AES-128、SMS4、IDEA算法的最大RPU利用率超过50 %,RPU平均利用率在40 %左右。如图7(b)所示,复制指令后,AES-128、SMS4、IDEA的RPU利用率得到了巨大提升,RPU最大利用率可达到90 %以上,平均利用率在70 %左右。这是因为一方面复制指令算法有效利用运行时刻处于空闲状态的RPU实现再计算,另一方面软件流水技术使原始指令与复制指令尽可能多的并行执行,在极大提高RPU利用率的同时,有效减少了性能开销。

图7 指令复制前后RPU利用率
文献[6-10]均采用指令复制实现错误检测,但各文献基于的处理器架构存在差异且选用的测试基准不同,因此无法直接使用文献内数据进行对比。由图5与图6可知全指令复制时不同文献方案的故障检测能力相似,为有效对比不同文献方法在RBCSP上实现所带来开销,本文将各文献方法在RBCSP上进行适配后,得到处理器面积与全指令复制实现的性能开销结果,如表3所示。表3中增加了带错误检测后AES算法实现的面积能效比,更直观地对比各方法在RBCSP上实现的优劣。
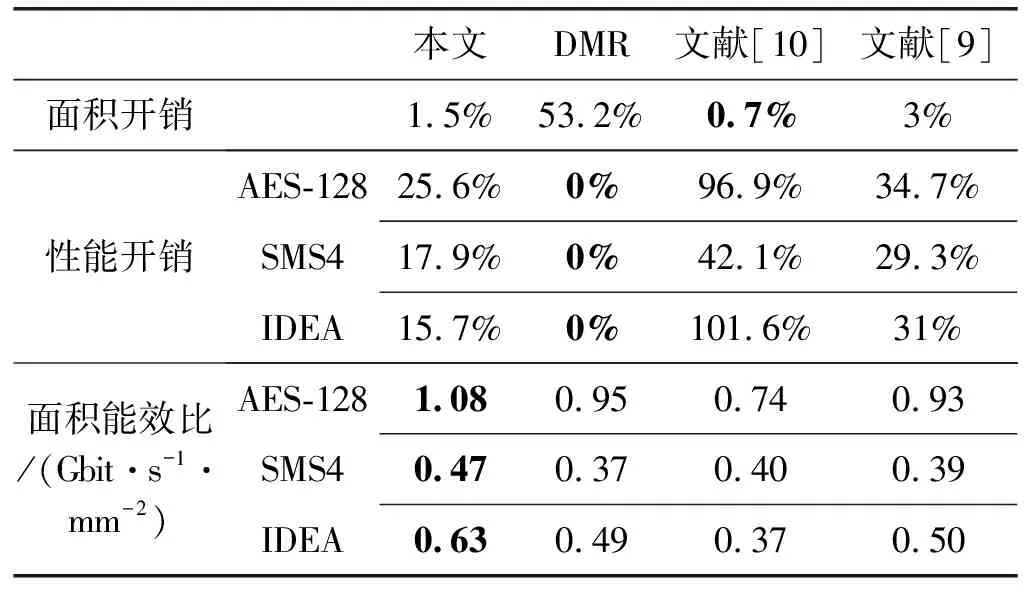
表3 开销对比
表3中DMR(Dual Modular Redundancy)并非复制整个RBCSP,而仅复制其核心部件(可重构并行处理簇),因此面积开销小于100%,仅为53.2%。文献[6]与文献[7]方法无法适配于ERBCSP,因此表中未列出其数据。由表4中数据可知,DMR的性能开销为0,但面积开销最大。文献[9]的面积开销最小,但性能开销最大。而由本文方法复制全部指令后,相比于文献[9]、文献[10],各密码算法实现性能开销最低;相比于DMR、文献[9]、文献[10],各密码算法实现的面积能效比最高。由文献[8]指令复制算法实现全指令复制时,其性能开销与本文相等,因此表中未列出,但由图5可知,在相同性能开销约束下,文献[8]的故障检测能力低于本文方法。因此,综合考虑故障检测能力、性能开销等因素,本文方法优于DMR、文献[8]、文献[9]、文献[10]。
4 结 语
本文面向分组密码流处理器,提出了基于指令复制的低开销并发错误检测方法。考虑恶意故障注入时间、位置的倾向性,提出了指令攻击脆弱性概念,并结合指令的时间脆弱性、物理脆弱性,设计了脆弱性感知的指令复制算法,可在性能开销约束下,有效提高处理器对随机故障与恶意故障的检测能力。实验证明,本文方法增加的面积开销仅占原处理器面积的1.5%;在错误检测能力上,相比于同类方法,采用本文方法后处理器可更有效地检测随机故障与恶意故障;在性能开销上,采用本文指令复制算法实现全部指令复制后,典型SP(AES-128)、Feistel(SMS4)、LM(IDEA)结构算法实现性能开销分别为25.6%、17.9%、15.7%,相比于同类型方法,采用本文方法实现全指令复制后密码算法实现性能开销最低,面积能效比最高。由于实现指令复制后代码规模增大,下一步将考虑通过动态复制指令以减小代码规模、降低存储开销。
