基于深度学习的脊柱CT图像分割
2018-10-24刘忠利单志勇蒋学芹
刘忠利 陈 光 单志勇 蒋学芹
(东华大学信息科学与技术学院 上海 201620)
0 引 言
脊柱是人体生命大厦不可或缺的重要组成部分,它上联颅骨、中附肋骨,下联髋骨,是人体的后壁,具有支持躯干,保护脊髓、内脏等重要功能。但现代社会中,由于人们生活节奏加快、工作压力繁重等原因,脊椎病的患者不断呈现出年轻化的趋势,据统计在40岁以下人群中患有相关疾病的人数占到40%以上[1]。而在众多诊断与脊柱疾病有关的方法中,CT图像因其成像快、分辨率高,能够较好地显示组织结构,而广泛地用于脊柱疾病诊断中。
在诊断过程中,通常需要在计算机的辅助下,将脊柱CT成像中感兴趣的脊柱区域分割出来,再结合三维重建、可视化等技术,使医生更加直观、清晰地对病人病变区进行观察与剖析,这对提高疾病治疗的效率和成功率具有重要地推动作用。但由于脊柱CT图像在成像过程中,图像易受设备噪声影响,使图像中存在一定的噪声,且脊柱边界和其他组织边界存在无明显的界限现象,再加上脊柱形态变化无规则、结构复杂等,这些都给脊柱图像分割带来一定的挑战。
针对以上问题,研究者们提出了许多实现脊柱图像分割的算法。如文献[2]等提出利用超像素法来分割脊柱图像,整个算法主要包括去除图像噪声和确定感兴趣候选区(ROI)的预处理,应用超像素法对ROI的目标和背景进行聚类进而得到结果的分割过程及运用形态学的闭运算和开运算操作进一步提高精度的后处理。和人工手动法分割椎骨图像相比,此法很大程度地提高了分割速度。文献[3]利用统计形状模型法生成的脊柱形状的均值信息来实现半自动分割,在分割过程中,首先需人工手动地确定脊柱在图像中的位置,然后将引入的多种模型的形状、梯度等先验信息作为约束条件来实现分割。文献[4]提出了基于改进的水平集(LSM)分割方法,在实际实现中,为了解决水平集函数(LSF)对图像噪声较为敏感而导致对脊柱不规则的边界分割效果不佳的问题,其采取利用图像的梯度信息对LSF进行演化的方法进一步提高精度。文献[6]则引入脊柱图像统计形状作为先验信息对LSF进行初始化,但此法在提高分割精度的同时却增加了LSM的计算复杂度。尽管以上这些方法在脊柱图像的分割中取得了一定的效果,但总结起来它们一定程度存在以下共性:(1) 相关算法较为复杂,分割过程繁琐,导致分割实时性有限而限制了其在临床中的应用;(2) 分割过程中需人工干预,引入一定的先验信息,往往只能实现半自动分割且分割的好坏过分的依赖于手工设计的特征;(3) 各算法的分割精度有限,有待进一步提高。
最近,深度学习算法因其拥有强大的特征提取、非线性映射等能力,在图像的语义分割、分类及目标检测等应用方面取得了很大的突破而被广泛地关注。在医学图像分割方面,研究者们引入深度学习的相关算法,利用深度卷积神经网络学习到的抽象表达可以更加准确地描述图像深层次信息的优势,实现一些常见的医学图像的分割,并取得了很好的效果。如郭树旭等[5]利用全卷积神经网络,提取图像特征,实现肝脏CT影像的自动分割,和其他方法相比,此法在实时性和精确度方面均有所提高。文献[7]则利用深度学习算法分割含有肿瘤的脑部图像,实验证明该方法分割的平均精确度达到了近80%,超越了很多传统算法。本文受当前流行的相关深度学习算法在图像分割方面取得突破性进展的启发,结合其在医学图像分割方面的一些实际应用,提出了基于卷积—反卷积神经网络的脊柱CT图像分割方法。该方法将全卷积网络和反卷积网络融合成一个整体的深度网络,在网络训练过程中,不断迭代学习,自动调整网络参数,卷积网络用于提取图像的一系列特征,反卷积网络将所提取深层次特征映射到输入图像尺寸上,从而实现像素到像素的脊柱图像全自动分割。
1 分割方法与原理
深度学习的动机是效仿人类大脑内部的神经连接,模仿并建立类似的结构模型。该模型能通过多个阶段的分层变换,对图像、语音等信号由低级到高级逐层进行特征提取与描述,进一步给予数据解释,从而挖掘数据中所蕴含的深层次的有效信息。以图像为例,通过构建深度神经网络模型,学习并提取图像深层次特征,得到特征的抽象表达,进而能够更加准确地描述图像的变化。
1.1 全卷积神经网络
受生物视觉局部感知的启发,文献[8]在传统的神经网络中融入权值共享、局部连接、池化等思想,提出了卷积神经网络CNN(Convolutional Neural Network)的概念,这些思想的融入在使网络具有更强地特征提取能力的同时,能够明显地降低网络参数的含量,避免在训练网络时,过拟合的发生。一个典型卷积神经网络主要由若干个卷积层、池化层、非线性变换层、全连接层组成。其中,卷积层是核心层,用来提取图像的局部特征,池化的作用是将所得到的特征进行降维,非线性变换则对特征进行非线性映射,全连接层的目的是将矩阵形式的特征变换为列向量的形式,用于连接最后的分类器。传统的CNN由于在池化的过程中,对特征图进行降维处理的同时丢失了特征的空间信息,所以一般适用于处理图像的分类问题,最终得到对一整幅图像的分类预测。而图像分割任务,对像素的位置要求很高,图像的每个像素都是分类预测的对象,单一地使用传统的CNN将不再合适。
对于一些基于深度学习的医学图像分割任务,研究者们通常会提出基于patch法和CNN相结合的方法进行解决。所谓patch法就是将图像预先分成若干个小图像块,每个图像块的中心像素点所属的类别即为该图像块的类别,然后根据所判定的类别给予该图像块标签,最后将图像块和标签共同作为网络的输入信息。这种方法的缺点在于只是输入了图像的局部区域,无法充分利用小区域以外的上下文信息且前处理过程复杂,耗时过长以致分割效率低下。
针对CNN用于图像分割所存在的问题,文献[9]在已有的用于识别的典型网络VGG16[11]等CNN基础上提出了全卷积神经网FCN(Fully Convolutional Networks)的概念,该网络能实现端到端,像素到像素的图像语义分割,直接得到每个像素所属类别的语义信息。FCN和CNN的区别在于FCN将CNN的全连接层换成了感受野大小为输出大小的卷积层,使得网络可以接受任意尺寸大小的图像。在实际实现过程中,由于池化操作,特征图分辨率被依次缩小了2、4、8、16、32倍,FCN通过简单的双线性插值法对特征图进行上采样,将特征图依次扩大2、4、8、16、32倍,使得中间层的特征图尺寸和输出图像尺寸保持一致,从而对每个像素点进行概率预测并分类,得到最终的分割结果。为了提高分割的精度,FCN将不同阶段的特征图进行放大融合来强化结果。通常根据融合的阶段和放大倍数的不同,可演化出FCN8s、FCN16s、FCN32s三种类型。图1所示为FCN8s基本结构。

图1 全卷积神经网络结构图(FCN8s)
1.2 特征提取
在卷积神经网络中,为了学习、提取图像的局部统计特征,一个可训练的滤波器(参数矩阵)θf=(w,b)需要和输入图像或网络前一层的输出作卷积运算,运算结果通过一个非线性激活函数得到相应的特征输出,将此输出经过空间池化操作后得到最终降维后的特征图,本文将这一过程称为特征提取。
假设网络f的输入图像为I,则经过网络f后的输出特征向量可表示为:
f(I,θ)=wlhl-1
(1)
hl=pool(relu(wlhl-1+bl)) ∀l∈{1,2,…,k,l-1}
(2)
式中:wl为第l层的权值,由卷积核的参数组成,bl为第l层的偏置,wl和bl两者组成可训练的滤波器θ;hl表示第l层单元的特征输出;relu为非线性变换的激活函数,相比利用其他的激活函数,此激活函数可加速网络收敛,其表达式为:
f(x)=max(0,x)
(3)
pool(·)表示池化运算,池化分为最大值池化和平均值池化,本文选取最大值池化。在网络中运用池化操作能在降低统计特征维度,减少网络参数的同时,实现统计特征的平移不变性。
1.3 反卷积网络
如前文所说,FCN通过对不同阶段特征图的放大合并解决了CNN输入图像大小与输出的预测图像尺寸不一致的问题,实现了图像的逐像素预测,但是在实验过程中发现FCN的分割结果会出现粗糙,易丢失边缘细节信息等现象,导致分割的精度不高。本文在FCN的基础上,进一步构建其镜像结构反卷积神经网络[10],两者共同组成深度的卷积—反卷积网络,实现脊柱CT图像的分割。网络结构如图2所示,左半部分为全卷积网络,右半部分为反卷积网络。反卷积网络的主要由池化和卷积相应的逆运算反池化和反卷积组成,其主要思想是循序渐进地对网络中间层提取的特征进行操作使其恢复到输入图像大小,而不是像FCN那样简单地进行插值操作放大输出特征。

图2 卷积—反卷积网络结构图
为了实现反池化操作,可在卷积网络阶段池化的过程中记录下每个池化域中最大池化的数值和坐标,在反池化的时候根据坐标将数值填补到原来位置,池化域中其他位置的数值用0替代,这样就可以将和卷积网络对应的特征图逐层扩大。然而,反池化得到的特征图往往是稀疏的,需通过反卷积操作进行致密。在卷积网络中,多个输入的特征数值和一个滤波器连接,映射成单个的特征值,而反卷积则是将单个特征值通过可训练的滤波器得到多个特征值。在实际中,还需将反卷积得到特征图进行适当地裁剪使其大小和反池化所得到特征图保持一致。和卷积网络类似,在反卷积网络中,较低层获取分割目标的大致的位置、形状等信息,较高层则获得相对复杂的细节信息。
1.4 网络训练
本文将去掉全连接层的VGG16[11]作为全卷积网络,并在其后构建镜像(对称)的反卷积网络。输入的脊柱图像通过全卷积网络提取特征,反卷积网络将特征循序渐进地映射到原图大小,最后通过一个softmax分类器进行分类,得到每个像素点所属类别的概率,进而得到整幅图像各像素分类的概率预测图。为了避免网络训练时,出现局部最优的情况,在网络中增加了Batchnormalization[14]层,使网络尽可能地得到全局最优解。为了更加有效地避免网络的过拟合问题,进一步提高网络的泛化能力,本文采用的Dropout技术[15],以0.5左右的概率随机地忽略网络一些节点的响应。
本文在训练网络时采用预训练法对网络进行训练,即训练分为两个阶段。第一阶段在数据集中以人工主观选择的方式选取分割目标比较清晰,特征比较明显的600张图像作为网络的输入,训练网络,直至其收敛,保存此时网络模型参数。第二阶段将全部训练集样本作为输入,并利用第一阶段的模型参数来初始化网络,从而达到加快网络收敛的目的。整个训练(实验)的流程如图3所示。
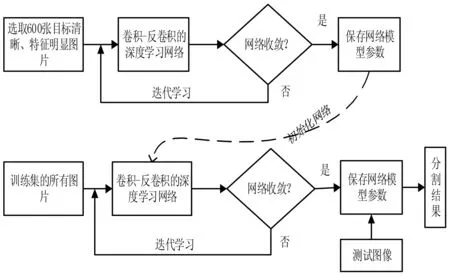
图3 网络训练(实验)流程
一般情况下,深度学习算法习惯采用随机梯度下降法[12]对网络参数进行跟新,但其缺点是需根据网络训练的实际,不断地手动设定学习率来确定最佳状态,这使得其灵活性差,难以应变网络的变化。本文结合改进的随机梯度下降法AdaGrad算法[13]对网络参数进行更新,它能使网络的学习率随网络的梯度变化自适应地进行跟新,这样可达到提高训练效率的目的。其表达式为:
(4)
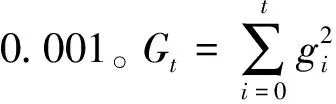
2 实验描述
2.1 实验数据及配置
本文实验采用来自Medical Image Computing and Computer Assisted Intervention 2016(MICCAI 2016)的数据集。数据包含15个人的样本图像及对应的手工分割真实图像,将其进行横向切片后去除不包含脊柱的图像,并通过几何变换对数据集进行适当地扩张。从数据集中随机抽取得到训练集CT图像2 073张,测试集图像1 000张,尺寸512像素×512像素。
本文实验使用深度学习中的Caffe框架,并参看了该框架上相关网络的一些层次结构,相关实验配置见表1。

表1 实验配置
2.2 实验评价指标
为了能够定量地评价算法分割的效果,本文采用两种常见的评价指标,分别是Dice相似性系数(DSC)、平均绝对距离(MAD)。DSC表示两个图像轮廓区域的相似程度,其值越大意味着分割效果越好。MAD测量的是分割结果和人工分割的真实结果(ground truth)之间边界的平均绝对距离,单位为像素,其值越小表示分割准确率越高。表达式分别如下:
(5)
式中:R,S分别为ground truth和分割结果轮廓区域所包含的点集。
(6)
式中:n为图像中分割目标边界的总像素,di为分割结果边界的第i个像素到ground truth之间的最近距离。
2.3 实验结果及分析
本文的实验流程如图3所示。本文处理的是图像像素级的二分类问题,即将图像中分别所属前景和背景的像素进行分类。为了便于呈现,如图4,本文将网络输出的脊柱图像概率预测图变换成灰度图,通过颜色深浅表征图像中每个像素所属类别的概率。图4(c)可知脊柱的边界及前景灰度颜色偏浅,其说明该位置的像素属于脊柱类别的可能性较大,背景的灰度颜色偏深表明其为非脊柱部分的可能性较大。另从(c)中可看出利用本文方法所得到结果,脊柱和非脊柱的组织区分度很高。图4(b)为人工分割的真实结果(ground truth),(b)和(c)相比较可知,本文自动分割的结果和ground truth之间具有很高的接近度。
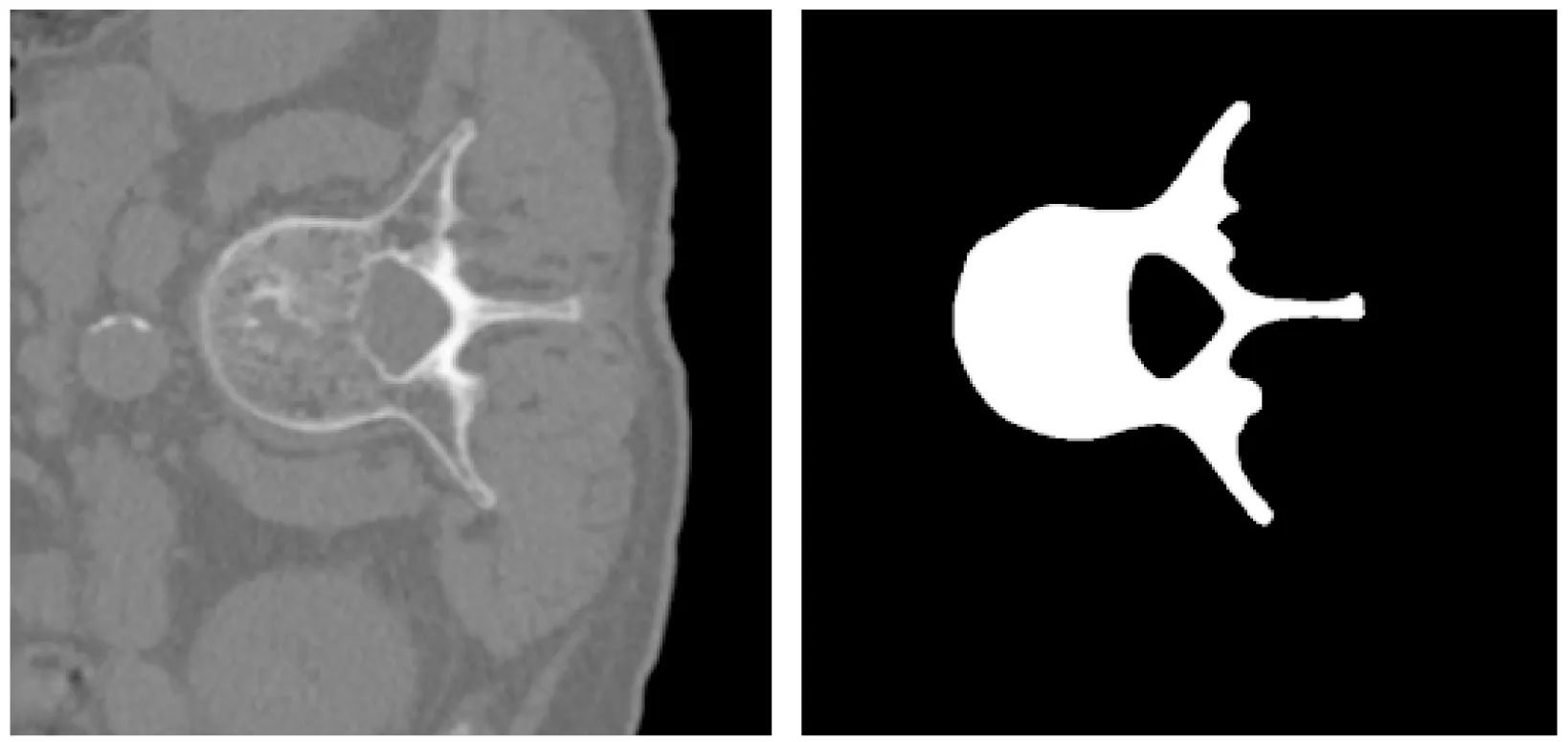
(a) 输入图像 (b) 真实分割图像(ground truth)

(c) 概率预测图图4 网络输出的脊柱图像概率预测灰度图
表2给出了利用不同方法对脊柱图像进行分割得到的定量评价结果,主要从Dice相似性系数(DSC)、平均绝对距离(MAD),单位为像素,以及分割一幅图像所耗费的时间等三个方面进行评价。
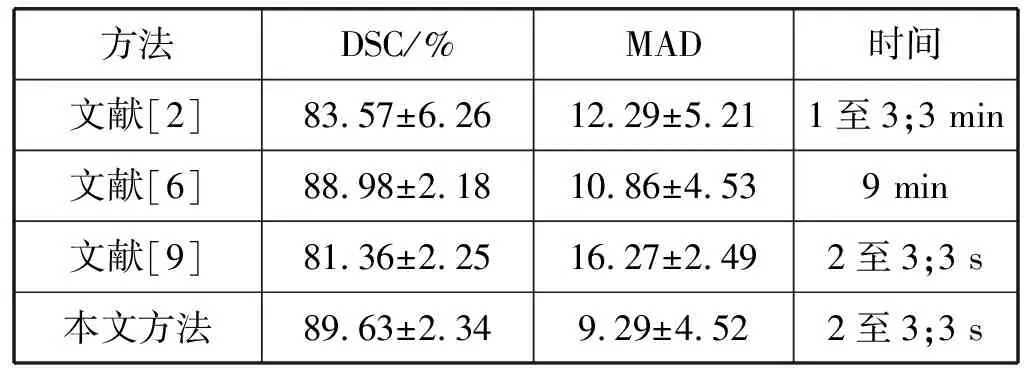
表2 不同方法分割结果比较
如表2所示,利用本文方法所得到的分割结果和文献[2]所获结果相比,在DSC、MAD及分割速度三个指标上均有所提高。与文献[6]相比,尽管本文方法所获精度在DSC和MAD两个指标上提高幅度不大,但在分割速度上,由于本文只需将待分割的原始图像直接输入到训练好的参数模型中,分割每幅图像只需2~3 s,因此和文献[6]中约9 min每幅图像相比,本文分割速度明显提高,实时性较好。本文还和深度学习中同样用来进行图像分割的FCN[9]进行了比较,由于FCN在分割时对图像的细节之处分割的比较粗糙,因此此法的分割精度不尽如人意。
图5是从测试集中随机地选取具有典型结构和形态的脊柱CT图像,输入到本文训练好的网络模型后得到的分割结果。其中,(a)列为输入的原始图像,原始尺寸为512像素×512像素,(b)列为ground truth,(c)列为利用本文方法分割得到的结果。(b)、(c)两列比较可知本文分割结果和ground truth之间相似度较好,证明本文方法的有效性。但可以发现,本文方法对于图像中脊柱边缘的细节之处的分割效果略显粗糙,需进一步改进。
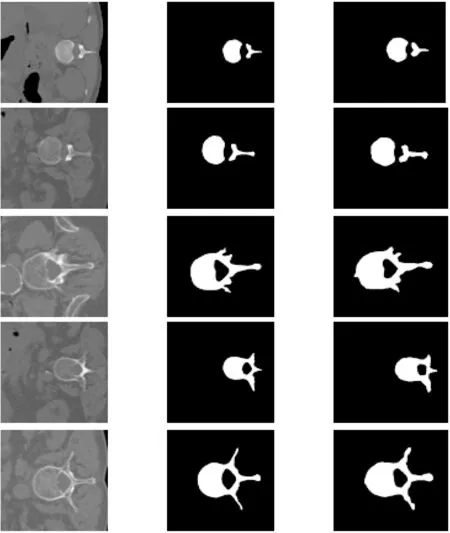
(a) 输入图像 (b) ground truth (c) 本文分割结果图5 脊柱CT图像分割结果
3 结 语
本文提出了一种基于卷积—反卷积神经网络的脊柱CT图像的全自动分割方法。卷积网络逐层地提取图像中脊柱的深层次特征,反卷积网络将所提取的特征映射到原图像的尺寸。在网络训练阶段,为了加快网络收敛速度及避免频繁地人工设定学习效率来确定网络最佳学习状态,本文采取预训练法和改进的随机梯度下降法训练网络。通过训练好的网络模型中的softmax分类器,能够对输入图像实现端到端地逐像素分类预测。实验表明本文方法在分割的过程中,无需像传统方法那样需人工提取特征或引进先验信息,而是自动地提取图像的特征,描述图像数据的内部深层变化,从而实现脊柱CT图像的全自动分割,且分割精度高于或达到一些传统分割方法的同时,由于其分割速度快,能够满足实时性的需求。但是利用本文方法得到的分割结果,有时对脊柱的边缘细节处的处理效果略显不佳,需进一步改进。
